 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Tutorial on Environment-Aware Communications via Channel Knowledge Map for 6G
Sep 14, 2023
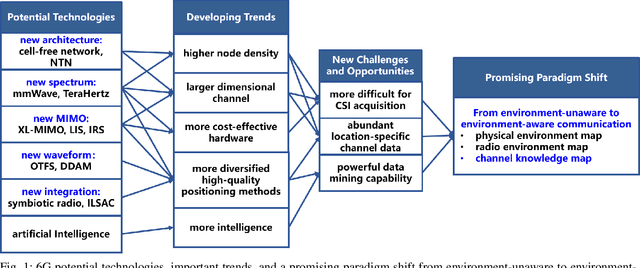
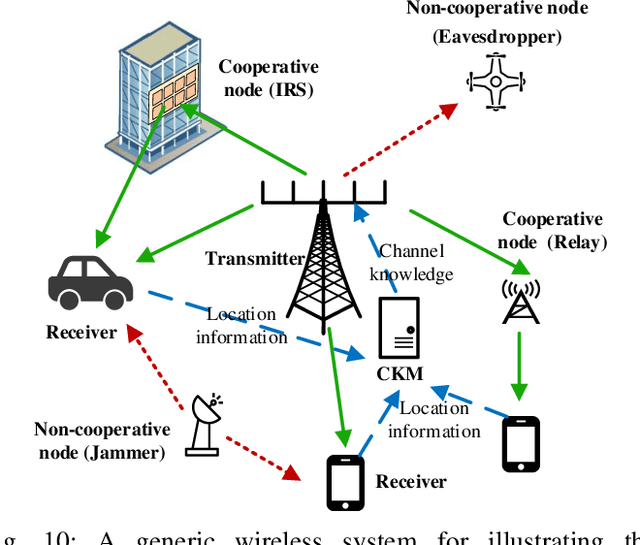
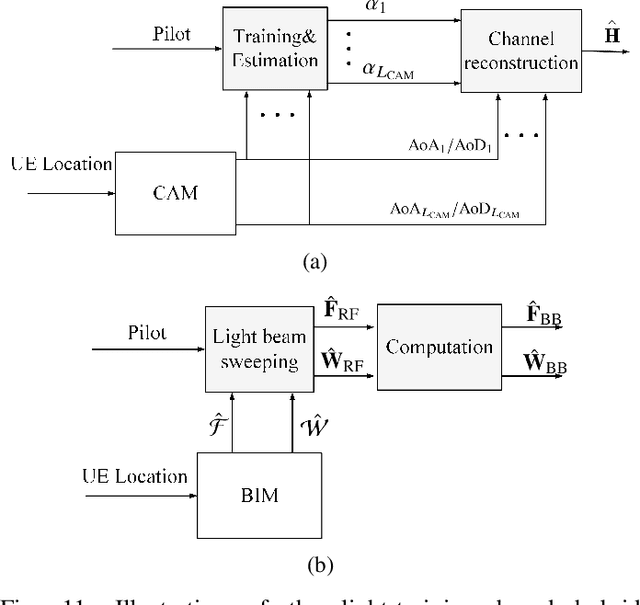
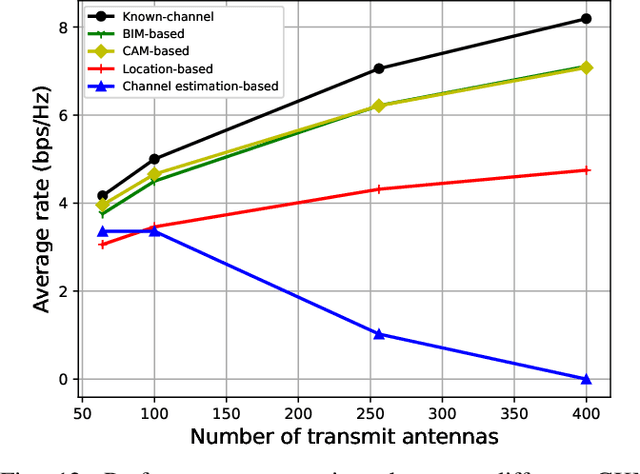
Sixth-generation (6G) mobile communication networks are expected to have dense infrastructures, large-dimensional channels, cost-effective hardware, diversified positioning methods, and enhanced intelligence. Such trends bring both new challenges and opportunities for the practical design of 6G. On one hand, acquiring channel state information (CSI) in real time for all wireless links becomes quite challenging in 6G. On the other hand, there would be numerous data sources in 6G containing high-quality location-tagged channel data, making it possible to better learn the local wireless environment. By exploiting such new opportunities and for tackling the CSI acquisition challenge, there is a promising paradigm shift from the conventional environment-unaware communications to the new environment-aware communications based on the novel approach of channel knowledge map (CKM). This article aims to provide a comprehensive tutorial overview on environment-aware communications enabled by CKM to fully harness its benefits for 6G. First, the basic concept of CKM is presented, and a comparison of CKM with various existing channel inference techniques is discussed. Next, the main techniques for CKM construction are discussed, including both the model-free and model-assisted approaches. Furthermore, a general framework is presented for the utilization of CKM to achieve environment-aware communications, followed by some typical CKM-aided communication scenarios. Finally, important open problems in CKM research are highlighted and potential solutions are discussed to inspire future work.
Curvature-based Pooling within Graph Neural Networks
Aug 31, 2023Over-squashing and over-smoothing are two critical issues, that limit the capabilities of graph neural networks (GNNs). While over-smoothing eliminates the differences between nodes making them indistinguishable, over-squashing refers to the inability of GNNs to propagate information over long distances, as exponentially many node states are squashed into fixed-size representations. Both phenomena share similar causes, as both are largely induced by the graph topology. To mitigate these problems in graph classification tasks, we propose CurvPool, a novel pooling method. CurvPool exploits the notion of curvature of a graph to adaptively identify structures responsible for both over-smoothing and over-squashing. By clustering nodes based on the Balanced Forman curvature, CurvPool constructs a graph with a more suitable structure, allowing deeper models and the combination of distant information. We compare it to other state-of-the-art pooling approaches and establish its competitiveness in terms of classification accuracy, computational complexity, and flexibility. CurvPool outperforms several comparable methods across all considered tasks. The most consistent results are achieved by pooling densely connected clusters using the sum aggregation, as this allows additional information about the size of each pool.
EditSum: A Retrieve-and-Edit Framework for Source Code Summarization
Sep 07, 2023
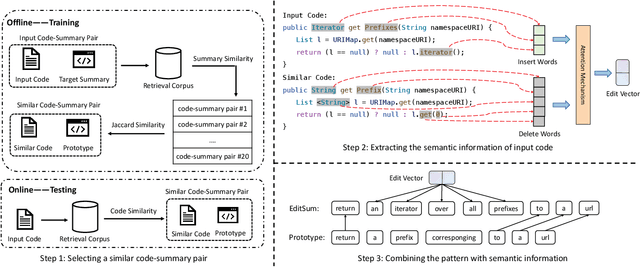
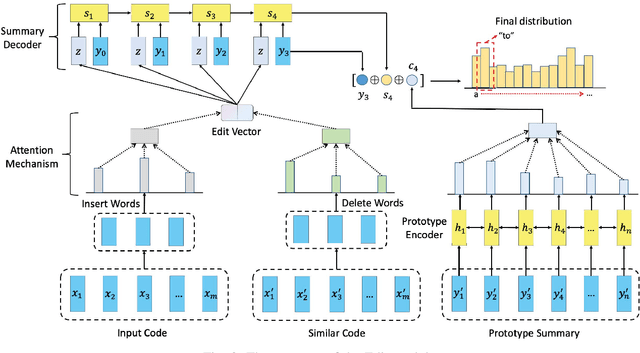
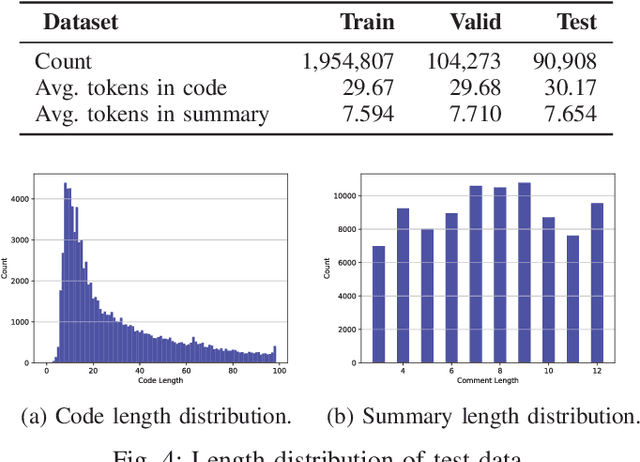
Existing studies show that code summaries help developers understand and maintain source code. Unfortunately, these summaries are often missing or outdated in software projects. Code summarization aims to generate natural language descriptions automatically for source code. Code summaries are highly structured and have repetitive patterns. Besides the patternized words, a code summary also contains important keywords, which are the key to reflecting the functionality of the code. However, the state-of-the-art approaches perform poorly on predicting the keywords, which leads to the generated summaries suffering a loss in informativeness. To alleviate this problem, this paper proposes a novel retrieve-and-edit approach named EditSum for code summarization. Specifically, EditSum first retrieves a similar code snippet from a pre-defined corpus and treats its summary as a prototype summary to learn the pattern. Then, EditSum edits the prototype automatically to combine the pattern in the prototype with the semantic information of input code. Our motivation is that the retrieved prototype provides a good start-point for post-generation because the summaries of similar code snippets often have the same pattern. The post-editing process further reuses the patternized words in the prototype and generates keywords based on the semantic information of input code. We conduct experiments on a large-scale Java corpus and experimental results demonstrate that EditSum outperforms the state-of-the-art approaches by a substantial margin. The human evaluation also proves the summaries generated by EditSum are more informative and useful. We also verify that EditSum performs well on predicting the patternized words and keywords.
AdSEE: Investigating the Impact of Image Style Editing on Advertisement Attractiveness
Sep 15, 2023Online advertisements are important elements in e-commerce sites, social media platforms, and search engines. With the increasing popularity of mobile browsing, many online ads are displayed with visual information in the form of a cover image in addition to text descriptions to grab the attention of users. Various recent studies have focused on predicting the click rates of online advertisements aware of visual features or composing optimal advertisement elements to enhance visibility. In this paper, we propose Advertisement Style Editing and Attractiveness Enhancement (AdSEE), which explores whether semantic editing to ads images can affect or alter the popularity of online advertisements. We introduce StyleGAN-based facial semantic editing and inversion to ads images and train a click rate predictor attributing GAN-based face latent representations in addition to traditional visual and textual features to click rates. Through a large collected dataset named QQ-AD, containing 20,527 online ads, we perform extensive offline tests to study how different semantic directions and their edit coefficients may impact click rates. We further design a Genetic Advertisement Editor to efficiently search for the optimal edit directions and intensity given an input ad cover image to enhance its projected click rates. Online A/B tests performed over a period of 5 days have verified the increased click-through rates of AdSEE-edited samples as compared to a control group of original ads, verifying the relation between image styles and ad popularity. We open source the code for AdSEE research at https://github.com/LiyaoJiang1998/adsee.
MOSAIC: Learning Unified Multi-Sensory Object Property Representations for Robot Perception
Sep 15, 2023A holistic understanding of object properties across diverse sensory modalities (e.g., visual, audio, and haptic) is essential for tasks ranging from object categorization to complex manipulation. Drawing inspiration from cognitive science studies that emphasize the significance of multi-sensory integration in human perception, we introduce MOSAIC (Multi-modal Object property learning with Self-Attention and Integrated Comprehension), a novel framework designed to facilitate the learning of unified multi-sensory object property representations. While it is undeniable that visual information plays a prominent role, we acknowledge that many fundamental object properties extend beyond the visual domain to encompass attributes like texture, mass distribution, or sounds, which significantly influence how we interact with objects. In MOSAIC, we leverage this profound insight by distilling knowledge from the extensive pre-trained Contrastive Language-Image Pre-training (CLIP) model, aligning these representations not only across vision but also haptic and auditory sensory modalities. Through extensive experiments on a dataset where a humanoid robot interacts with 100 objects across 10 exploratory behaviors, we demonstrate the versatility of MOSAIC in two task families: object categorization and object-fetching tasks. Our results underscore the efficacy of MOSAIC's unified representations, showing competitive performance in category recognition through a simple linear probe setup and excelling in the fetch object task under zero-shot transfer conditions. This work pioneers the application of CLIP-based sensory grounding in robotics, promising a significant leap in multi-sensory perception capabilities for autonomous systems. We have released the code, datasets, and additional results: https://github.com/gtatiya/MOSAIC.
Polygon Intersection-over-Union Loss for Viewpoint-Agnostic Monocular 3D Vehicle Detection
Sep 13, 2023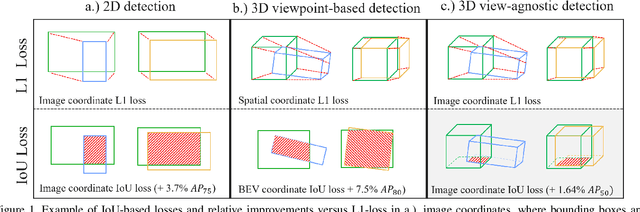
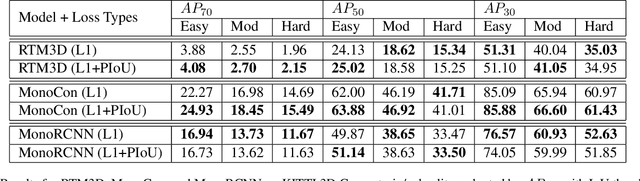
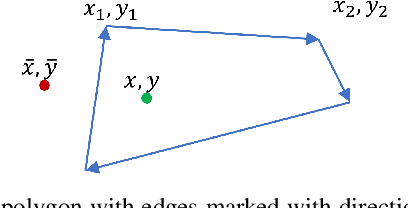
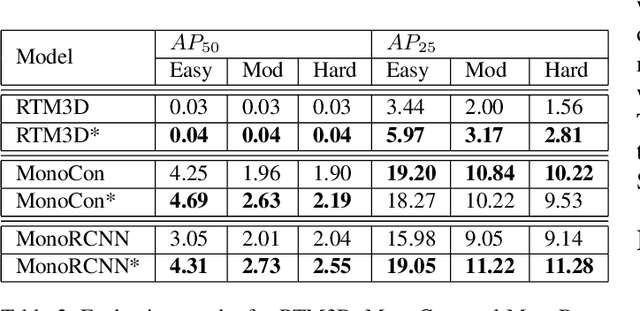
Monocular 3D object detection is a challenging task because depth information is difficult to obtain from 2D images. A subset of viewpoint-agnostic monocular 3D detection methods also do not explicitly leverage scene homography or geometry during training, meaning that a model trained thusly can detect objects in images from arbitrary viewpoints. Such works predict the projections of the 3D bounding boxes on the image plane to estimate the location of the 3D boxes, but these projections are not rectangular so the calculation of IoU between these projected polygons is not straightforward. This work proposes an efficient, fully differentiable algorithm for the calculation of IoU between two convex polygons, which can be utilized to compute the IoU between two 3D bounding box footprints viewed from an arbitrary angle. We test the performance of the proposed polygon IoU loss (PIoU loss) on three state-of-the-art viewpoint-agnostic 3D detection models. Experiments demonstrate that the proposed PIoU loss converges faster than L1 loss and that in 3D detection models, a combination of PIoU loss and L1 loss gives better results than L1 loss alone (+1.64% AP70 for MonoCon on cars, +0.18% AP70 for RTM3D on cars, and +0.83%/+2.46% AP50/AP25 for MonoRCNN on cyclists).
Utilizing Hybrid Trajectory Prediction Models to Recognize Highly Interactive Traffic Scenarios
Sep 13, 2023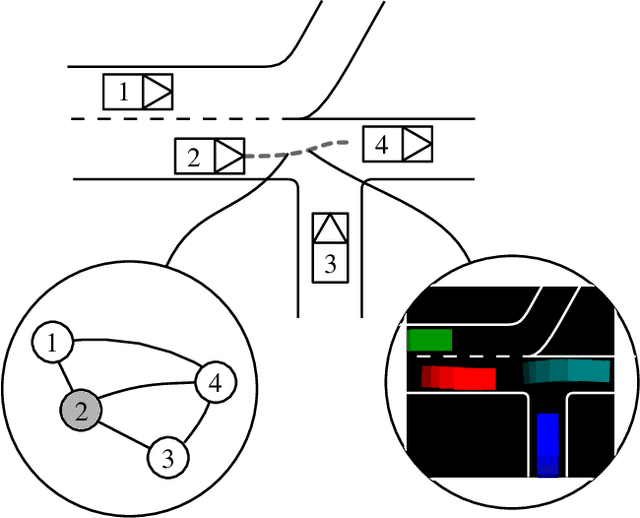
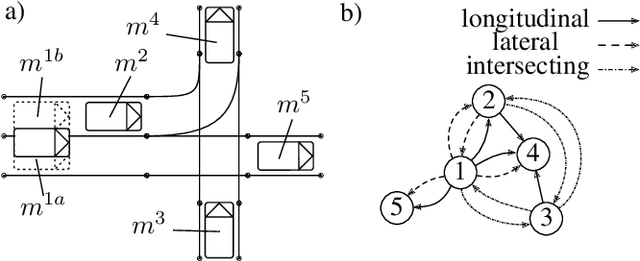
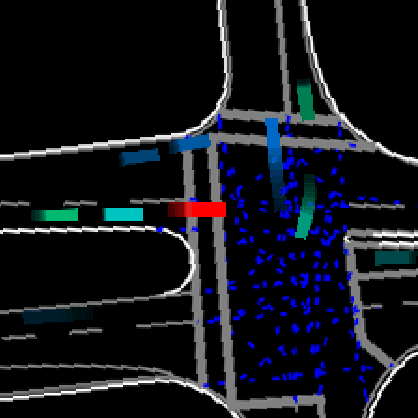
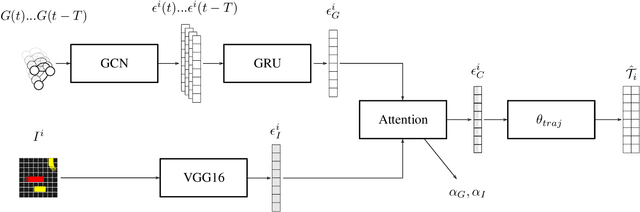
Autonomous vehicles hold great promise in improving the future of transportation. The driving models used in these vehicles are based on neural networks, which can be difficult to validate. However, ensuring the safety of these models is crucial. Traditional field tests can be costly, time-consuming, and dangerous. To address these issues, scenario-based closed-loop simulations can simulate many hours of vehicle operation in a shorter amount of time and allow for specific investigation of important situations. Nonetheless, the detection of relevant traffic scenarios that also offer substantial testing benefits remains a significant challenge. To address this need, in this paper we build an imitation learning based trajectory prediction for traffic participants. We combine an image-based (CNN) approach to represent spatial environmental factors and a graph-based (GNN) approach to specifically represent relations between traffic participants. In our understanding, traffic scenes that are highly interactive due to the network's significant utilization of the social component are more pertinent for a validation process. Therefore, we propose to use the activity of such sub networks as a measure of interactivity of a traffic scene. We evaluate our model using a motion dataset and discuss the value of the relationship information with respect to different traffic situations.
A Robust SINDy Approach by Combining Neural Networks and an Integral Form
Sep 13, 2023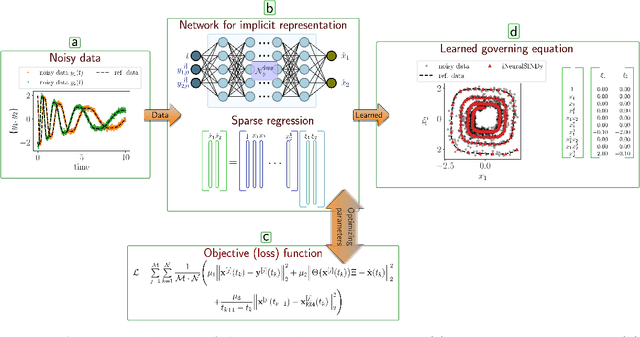
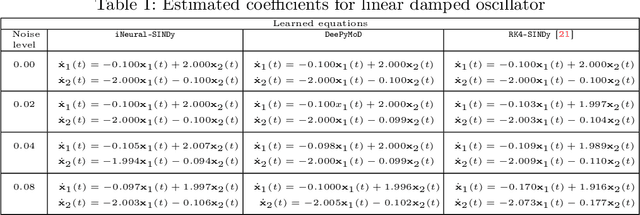
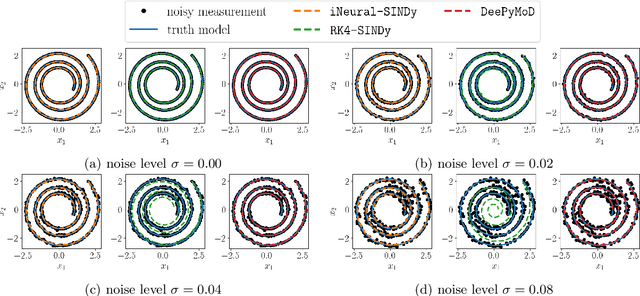
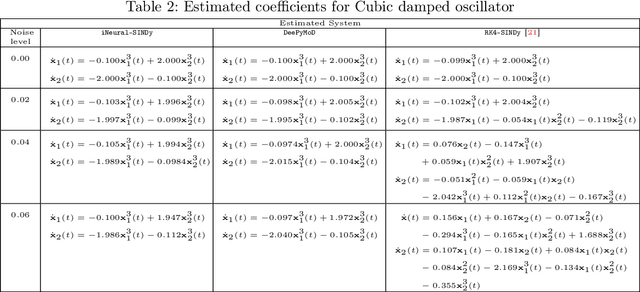
The discovery of governing equations from data has been an active field of research for decades. One widely used methodology for this purpose is sparse regression for nonlinear dynamics, known as SINDy. Despite several attempts, noisy and scarce data still pose a severe challenge to the success of the SINDy approach. In this work, we discuss a robust method to discover nonlinear governing equations from noisy and scarce data. To do this, we make use of neural networks to learn an implicit representation based on measurement data so that not only it produces the output in the vicinity of the measurements but also the time-evolution of output can be described by a dynamical system. Additionally, we learn such a dynamic system in the spirit of the SINDy framework. Leveraging the implicit representation using neural networks, we obtain the derivative information -- required for SINDy -- using an automatic differentiation tool. To enhance the robustness of our methodology, we further incorporate an integral condition on the output of the implicit networks. Furthermore, we extend our methodology to handle data collected from multiple initial conditions. We demonstrate the efficiency of the proposed methodology to discover governing equations under noisy and scarce data regimes by means of several examples and compare its performance with existing methods.
Prompting Segmentation with Sound is Generalizable Audio-Visual Source Localizer
Sep 13, 2023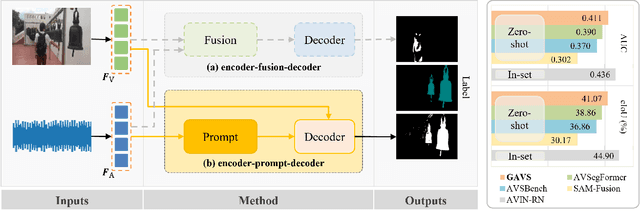
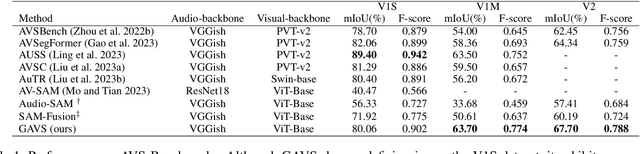
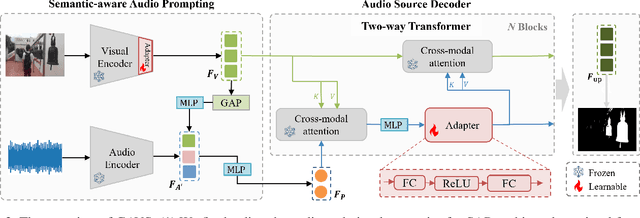

Never having seen an object and heard its sound simultaneously, can the model still accurately localize its visual position from the input audio? In this work, we concentrate on the Audio-Visual Localization and Segmentation tasks but under the demanding zero-shot and few-shot scenarios. To achieve this goal, different from existing approaches that mostly employ the encoder-fusion-decoder paradigm to decode localization information from the fused audio-visual feature, we introduce the encoder-prompt-decoder paradigm, aiming to better fit the data scarcity and varying data distribution dilemmas with the help of abundant knowledge from pre-trained models. Specifically, we first propose to construct Semantic-aware Audio Prompt (SAP) to help the visual foundation model focus on sounding objects, meanwhile, the semantic gap between the visual and audio modalities is also encouraged to shrink. Then, we develop a Correlation Adapter (ColA) to keep minimal training efforts as well as maintain adequate knowledge of the visual foundation model. By equipping with these means, extensive experiments demonstrate that this new paradigm outperforms other fusion-based methods in both the unseen class and cross-dataset settings. We hope that our work can further promote the generalization study of Audio-Visual Localization and Segmentation in practical application scenarios.
Denoising Attention for Query-aware User Modeling in Personalized Search
Aug 30, 2023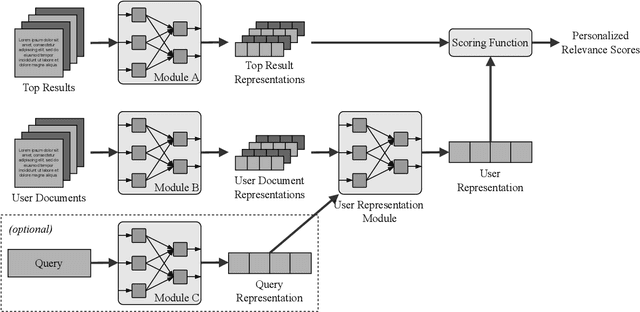
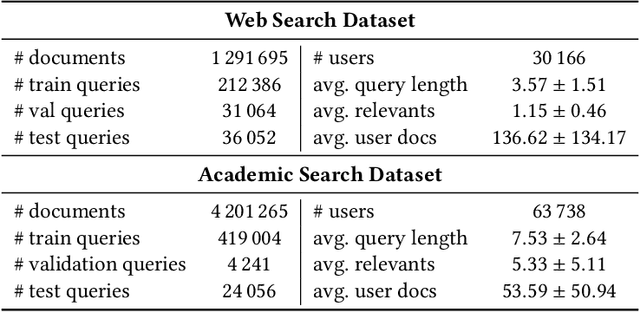
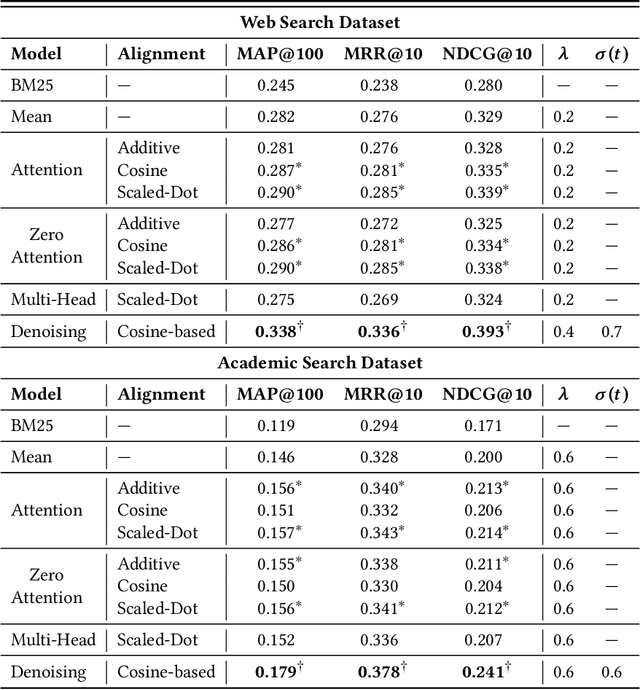
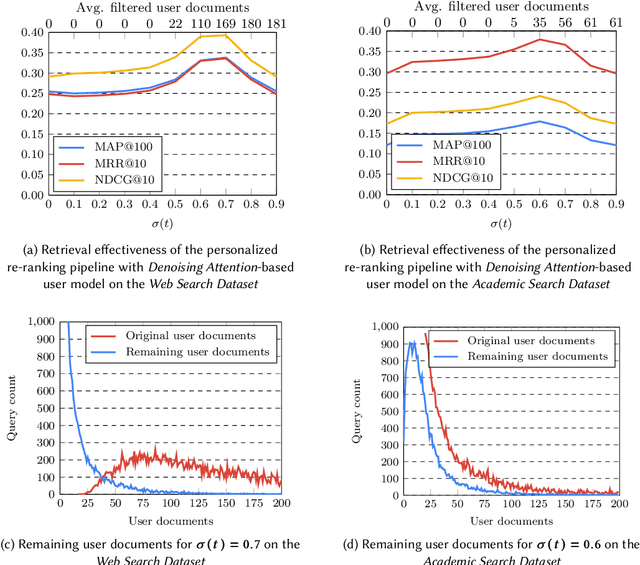
The personalization of search results has gained increasing attention in the past few years, thanks to the development of Neural Networks-based approaches for Information Retrieval and the importance of personalization in many search scenarios. Recent works have proposed to build user models at query time by leveraging the Attention mechanism, which allows weighing the contribution of the user-related information w.r.t. the current query. This approach allows taking into account the diversity of the user's interests by giving more importance to those related to the current search performed by the user. In this paper, we first discuss some shortcomings of the standard Attention formulation when employed for personalization. In particular, we focus on issues related to its normalization mechanism and its inability to entirely filter out noisy user-related information. Then, we introduce the Denoising Attention mechanism: an Attention variant that directly tackles the above shortcomings by adopting a robust normalization scheme and introducing a filtering mechanism. The reported experimental evaluation shows the benefits of the proposed approach over other Attention-based variants.