 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023
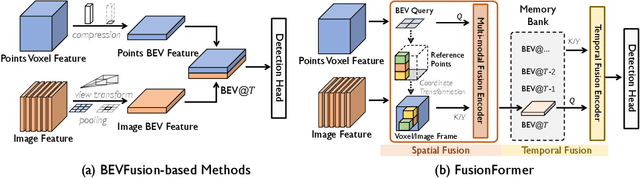

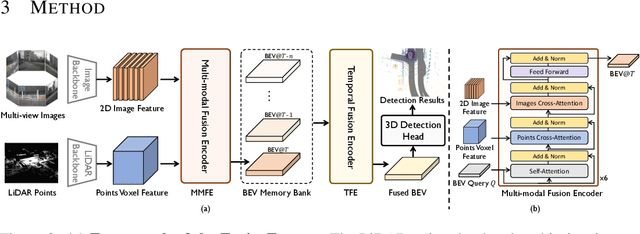
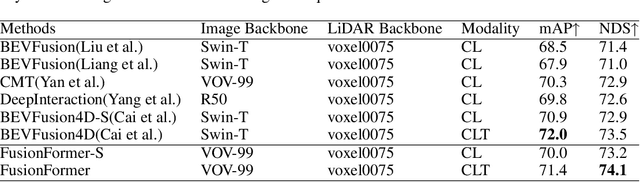
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
Formalizing Multimedia Recommendation through Multimodal Deep Learning
Sep 11, 2023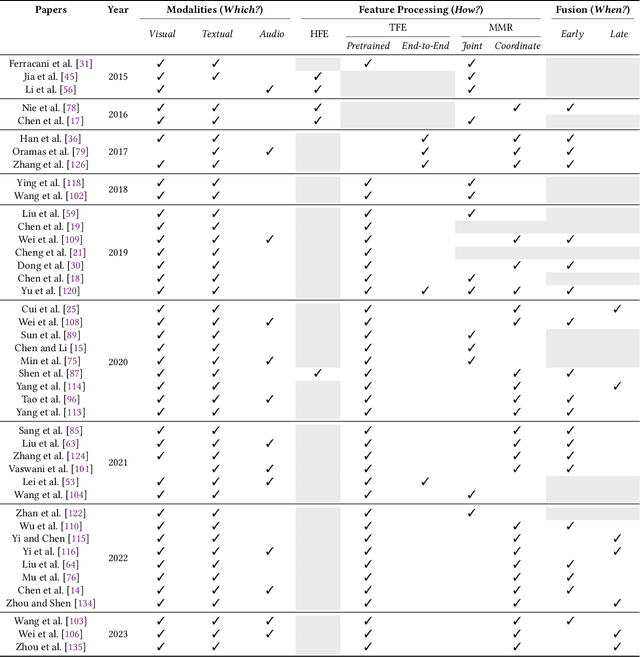
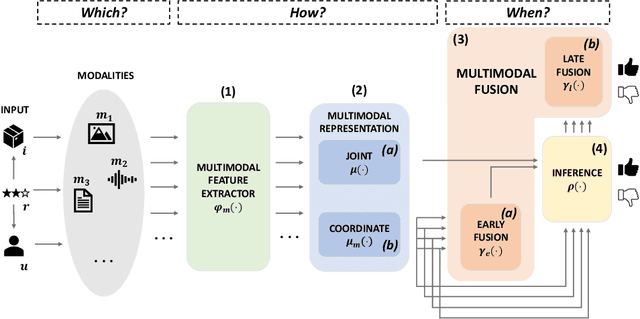
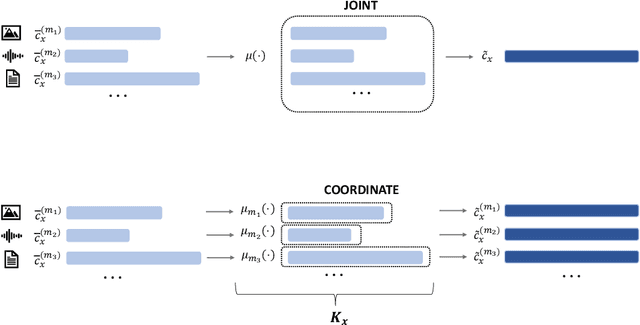
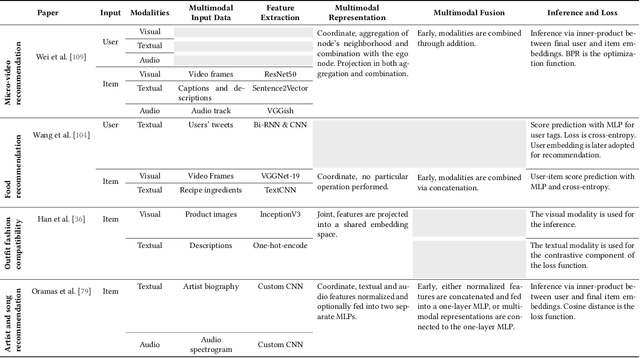
Recommender systems (RSs) offer personalized navigation experiences on online platforms, but recommendation remains a challenging task, particularly in specific scenarios and domains. Multimodality can help tap into richer information sources and construct more refined user/item profiles for recommendations. However, existing literature lacks a shared and universal schema for modeling and solving the recommendation problem through the lens of multimodality. This work aims to formalize a general multimodal schema for multimedia recommendation. It provides a comprehensive literature review of multimodal approaches for multimedia recommendation from the last eight years, outlines the theoretical foundations of a multimodal pipeline, and demonstrates its rationale by applying it to selected state-of-the-art approaches. The work also conducts a benchmarking analysis of recent algorithms for multimedia recommendation within Elliot, a rigorous framework for evaluating recommender systems. The main aim is to provide guidelines for designing and implementing the next generation of multimodal approaches in multimedia recommendation.
Black-Box Analysis: GPTs Across Time in Legal Textual Entailment Task
Sep 11, 2023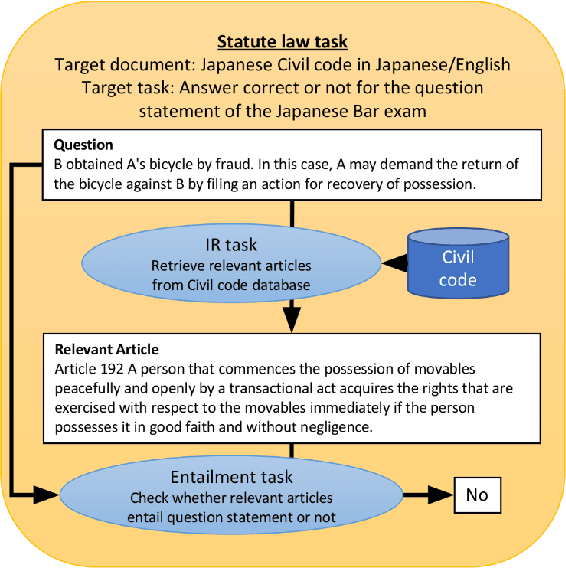
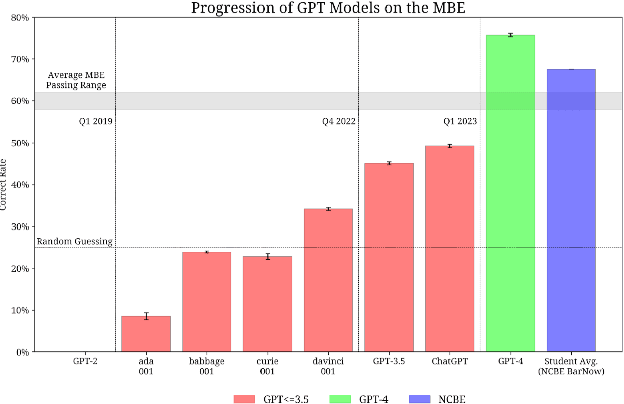
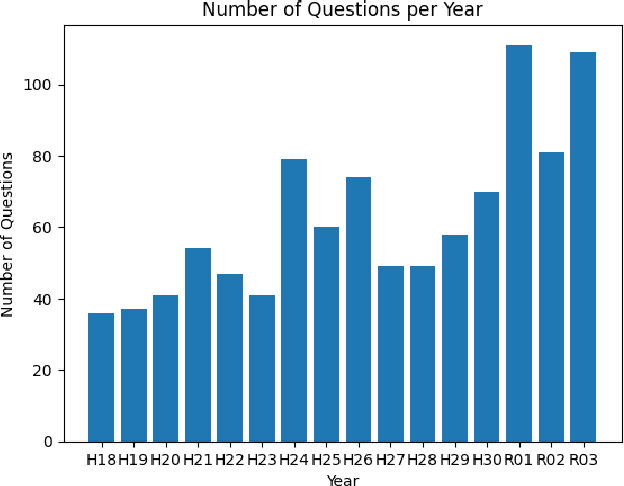
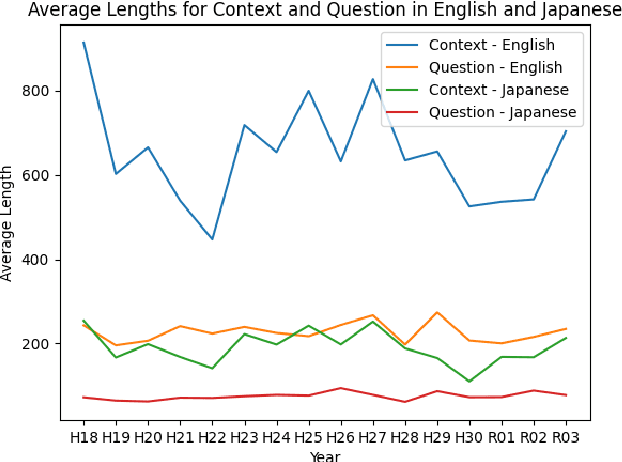
The evolution of Generative Pre-trained Transformer (GPT) models has led to significant advancements in various natural language processing applications, particularly in legal textual entailment. We present an analysis of GPT-3.5 (ChatGPT) and GPT-4 performances on COLIEE Task 4 dataset, a prominent benchmark in this domain. The study encompasses data from Heisei 18 (2006) to Reiwa 3 (2021), exploring the models' abilities to discern entailment relationships within Japanese statute law across different periods. Our preliminary experimental results unveil intriguing insights into the models' strengths and weaknesses in handling legal textual entailment tasks, as well as the patterns observed in model performance. In the context of proprietary models with undisclosed architectures and weights, black-box analysis becomes crucial for evaluating their capabilities. We discuss the influence of training data distribution and the implications on the models' generalizability. This analysis serves as a foundation for future research, aiming to optimize GPT-based models and enable their successful adoption in legal information extraction and entailment applications.
Neuromorphic Auditory Perception by Neural Spiketrum
Sep 11, 2023Neuromorphic computing holds the promise to achieve the energy efficiency and robust learning performance of biological neural systems. To realize the promised brain-like intelligence, it needs to solve the challenges of the neuromorphic hardware architecture design of biological neural substrate and the hardware amicable algorithms with spike-based encoding and learning. Here we introduce a neural spike coding model termed spiketrum, to characterize and transform the time-varying analog signals, typically auditory signals, into computationally efficient spatiotemporal spike patterns. It minimizes the information loss occurring at the analog-to-spike transformation and possesses informational robustness to neural fluctuations and spike losses. The model provides a sparse and efficient coding scheme with precisely controllable spike rate that facilitates training of spiking neural networks in various auditory perception tasks. We further investigate the algorithm-hardware co-designs through a neuromorphic cochlear prototype which demonstrates that our approach can provide a systematic solution for spike-based artificial intelligence by fully exploiting its advantages with spike-based computation.
Semantic Latent Decomposition with Normalizing Flows for Face Editing
Sep 11, 2023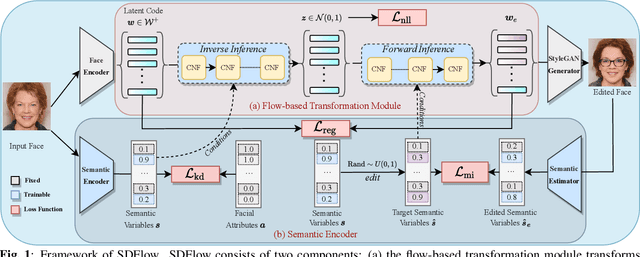
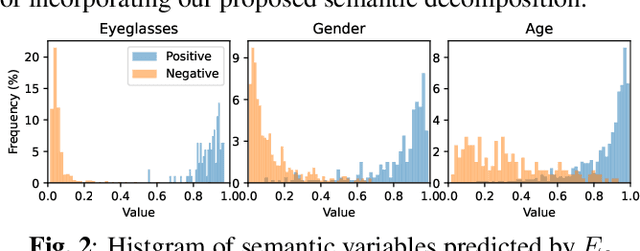

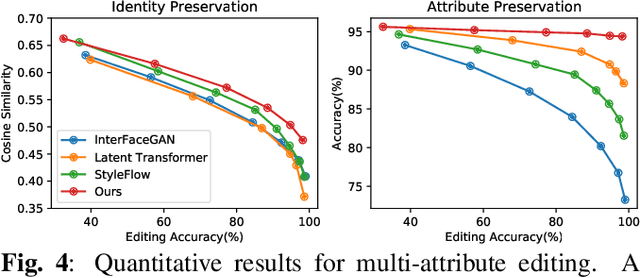
Navigating in the latent space of StyleGAN has shown effectiveness for face editing. However, the resulting methods usually encounter challenges in complicated navigation due to the entanglement among different attributes in the latent space. To address this issue, this paper proposes a novel framework, termed SDFlow, with a semantic decomposition in original latent space using continuous conditional normalizing flows. Specifically, SDFlow decomposes the original latent code into different irrelevant variables by jointly optimizing two components: (i) a semantic encoder to estimate semantic variables from input faces and (ii) a flow-based transformation module to map the latent code into a semantic-irrelevant variable in Gaussian distribution, conditioned on the learned semantic variables. To eliminate the entanglement between variables, we employ a disentangled learning strategy under a mutual information framework, thereby providing precise manipulation controls. Experimental results demonstrate that SDFlow outperforms existing state-of-the-art face editing methods both qualitatively and quantitatively. The source code is made available at https://github.com/phil329/SDFlow.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023
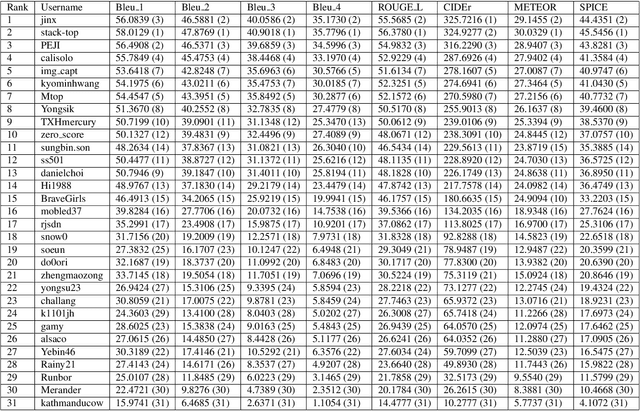
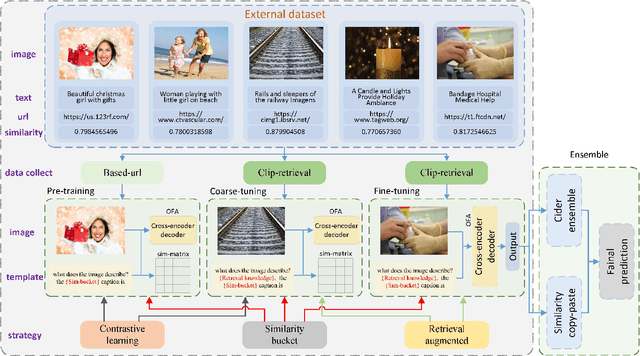
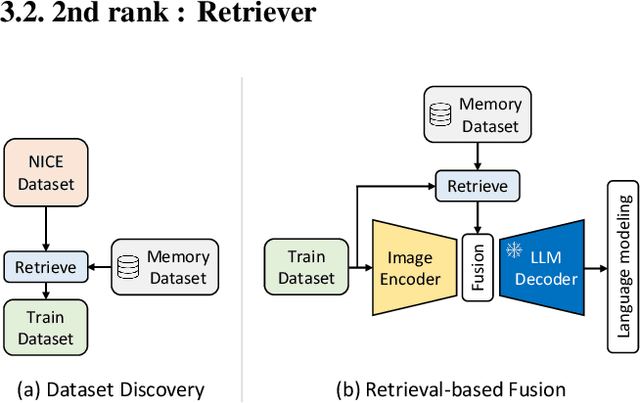
In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
A DRL-based Reflection Enhancement Method for RIS-assisted Multi-receiver Communications
Sep 11, 2023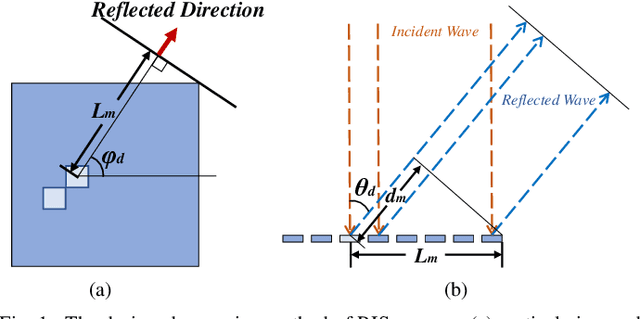

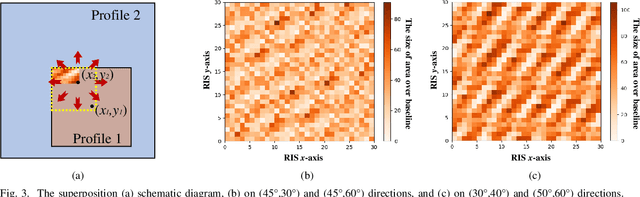
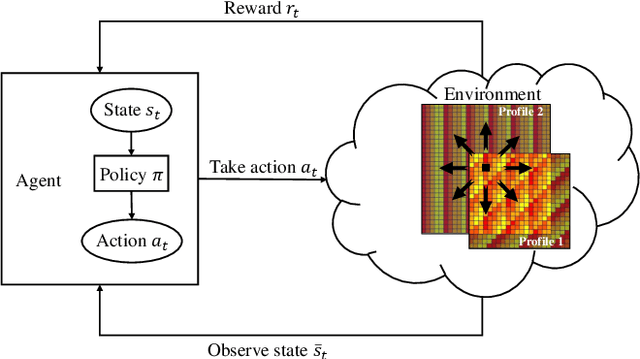
In reconfigurable intelligent surface (RIS)-assisted wireless communication systems, the pointing accuracy and intensity of reflections depend crucially on the 'profile,' representing the amplitude/phase state information of all elements in a RIS array. The superposition of multiple single-reflection profiles enables multi-reflection for distributed users. However, the optimization challenges from periodic element arrangements in single-reflection and multi-reflection profiles are understudied. The combination of periodical single-reflection profiles leads to amplitude/phase counteractions, affecting the performance of each reflection beam. This paper focuses on a dual-reflection optimization scenario and investigates the far-field performance deterioration caused by the misalignment of overlapped profiles. To address this issue, we introduce a novel deep reinforcement learning (DRL)-based optimization method. Comparative experiments against random and exhaustive searches demonstrate that our proposed DRL method outperforms both alternatives, achieving the shortest optimization time. Remarkably, our approach achieves a 1.2 dB gain in the reflection peak gain and a broader beam without any hardware modifications.
IDVT: Interest-aware Denoising and View-guided Tuning for Social Recommendation
Aug 30, 2023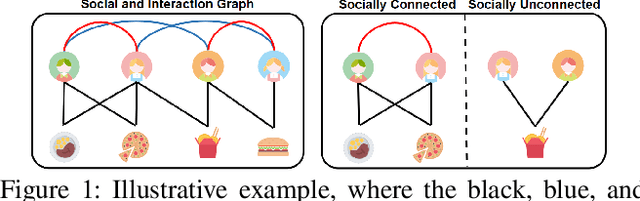
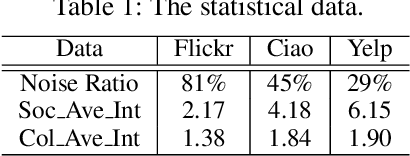
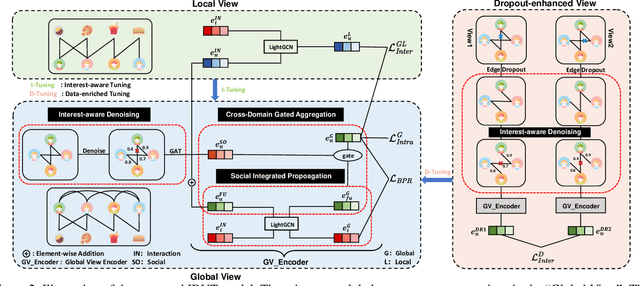
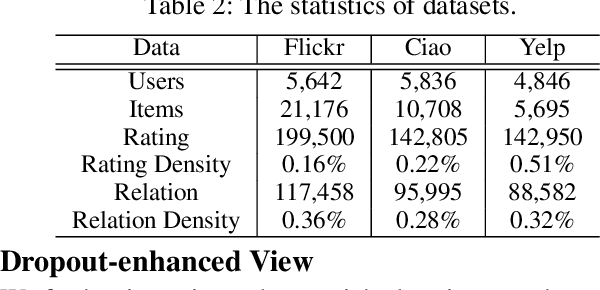
In the information age, recommendation systems are vital for efficiently filtering information and identifying user preferences. Online social platforms have enriched these systems by providing valuable auxiliary information. Socially connected users are assumed to share similar preferences, enhancing recommendation accuracy and addressing cold start issues. However, empirical findings challenge the assumption, revealing that certain social connections can actually harm system performance. Our statistical analysis indicates a significant amount of noise in the social network, where many socially connected users do not share common interests. To address this issue, we propose an innovative \underline{I}nterest-aware \underline{D}enoising and \underline{V}iew-guided \underline{T}uning (IDVT) method for the social recommendation. The first ID part effectively denoises social connections. Specifically, the denoising process considers both social network structure and user interaction interests in a global view. Moreover, in this global view, we also integrate denoised social information (social domain) into the propagation of the user-item interactions (collaborative domain) and aggregate user representations from two domains using a gating mechanism. To tackle potential user interest loss and enhance model robustness within the global view, our second VT part introduces two additional views (local view and dropout-enhanced view) for fine-tuning user representations in the global view through contrastive learning. Extensive evaluations on real-world datasets with varying noise ratios demonstrate the superiority of IDVT over state-of-the-art social recommendation methods.
Masked Diffusion with Task-awareness for Procedure Planning in Instructional Videos
Sep 14, 2023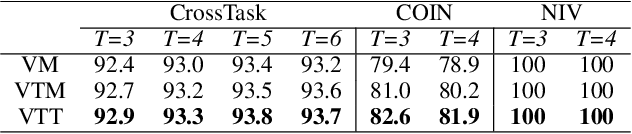
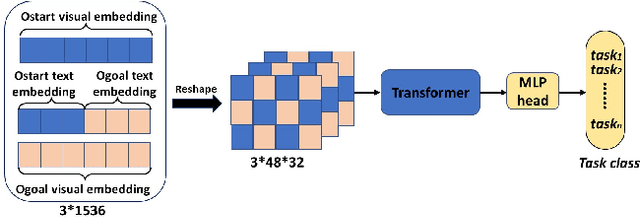
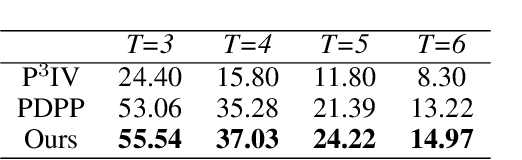
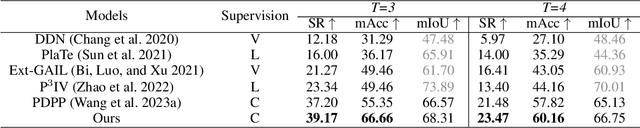
A key challenge with procedure planning in instructional videos lies in how to handle a large decision space consisting of a multitude of action types that belong to various tasks. To understand real-world video content, an AI agent must proficiently discern these action types (e.g., pour milk, pour water, open lid, close lid, etc.) based on brief visual observation. Moreover, it must adeptly capture the intricate semantic relation of the action types and task goals, along with the variable action sequences. Recently, notable progress has been made via the integration of diffusion models and visual representation learning to address the challenge. However, existing models employ rudimentary mechanisms to utilize task information to manage the decision space. To overcome this limitation, we introduce a simple yet effective enhancement - a masked diffusion model. The introduced mask acts akin to a task-oriented attention filter, enabling the diffusion/denoising process to concentrate on a subset of action types. Furthermore, to bolster the accuracy of task classification, we harness more potent visual representation learning techniques. In particular, we learn a joint visual-text embedding, where a text embedding is generated by prompting a pre-trained vision-language model to focus on human actions. We evaluate the method on three public datasets and achieve state-of-the-art performance on multiple metrics. Code is available at https://github.com/ffzzy840304/Masked-PDPP.
NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023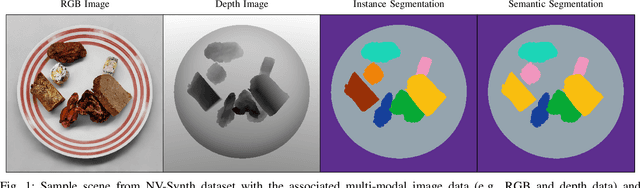



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.