 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Perception and Semantic Mapping Method for Robot Autonomy in Orchards
Sep 01, 2023
In this work, we propose a novel framework for achieving robotic autonomy in orchards. It consists of two key steps: perception and semantic mapping. In the perception step, we introduce a 3D detection method that accurately identifies objects directly on point cloud maps. In the semantic mapping step, we develop a mapping module that constructs a visibility graph map by incorporating object-level information and terrain analysis. By combining these two steps, our framework improves the autonomy of agricultural robots in orchard environments. The accurate detection of objects and the construction of a semantic map enable the robot to navigate autonomously, perform tasks such as fruit harvesting, and acquire actionable information for efficient agricultural production.
DiscoverPath: A Knowledge Refinement and Retrieval System for Interdisciplinarity on Biomedical Research
Sep 04, 2023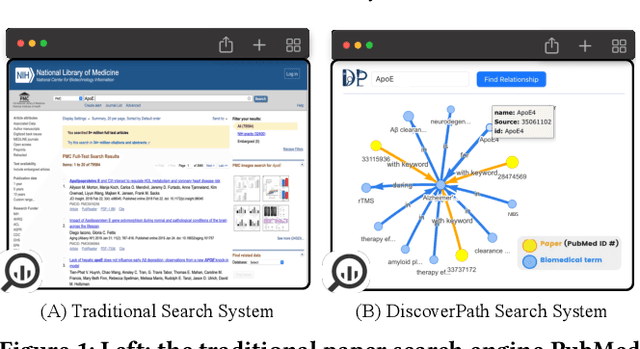
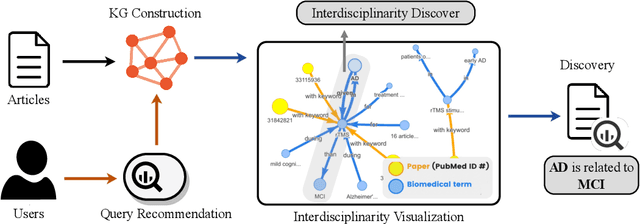
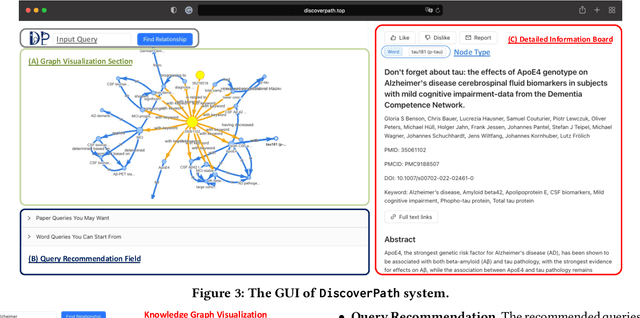
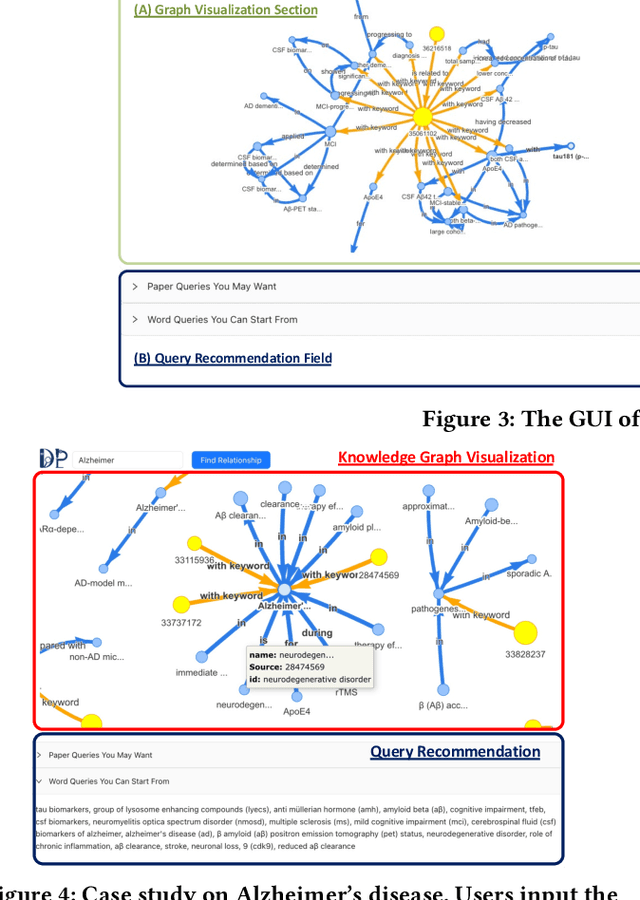
The exponential growth in scholarly publications necessitates advanced tools for efficient article retrieval, especially in interdisciplinary fields where diverse terminologies are used to describe similar research. Traditional keyword-based search engines often fall short in assisting users who may not be familiar with specific terminologies. To address this, we present a knowledge graph-based paper search engine for biomedical research to enhance the user experience in discovering relevant queries and articles. The system, dubbed DiscoverPath, employs Named Entity Recognition (NER) and part-of-speech (POS) tagging to extract terminologies and relationships from article abstracts to create a KG. To reduce information overload, DiscoverPath presents users with a focused subgraph containing the queried entity and its neighboring nodes and incorporates a query recommendation system, enabling users to iteratively refine their queries. The system is equipped with an accessible Graphical User Interface that provides an intuitive visualization of the KG, query recommendations, and detailed article information, enabling efficient article retrieval, thus fostering interdisciplinary knowledge exploration. DiscoverPath is open-sourced at https://github.com/ynchuang/DiscoverPath.
RGI-Net: 3D Room Geometry Inference from Room Impulse Responses in the Absence of First-order Echoes
Sep 04, 2023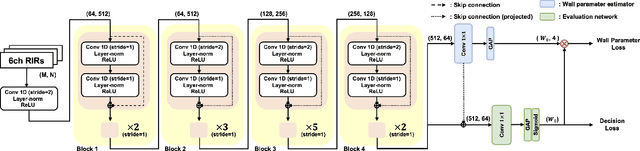

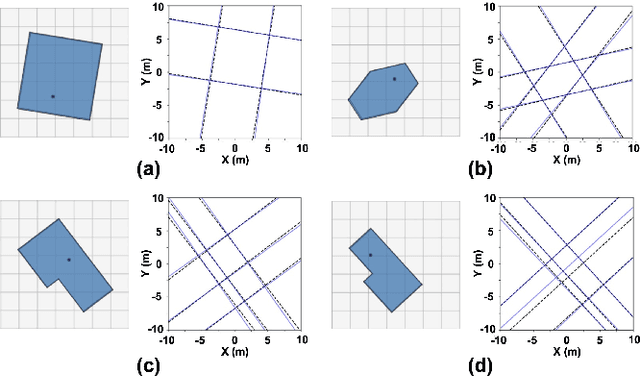
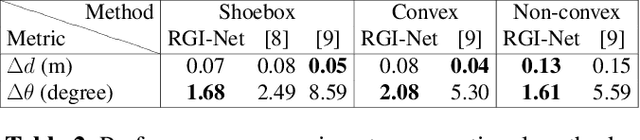
Room geometry is important prior information for implementing realistic 3D audio rendering. For this reason, various room geometry inference (RGI) methods have been developed by utilizing the time of arrival (TOA) or time difference of arrival (TDOA) information in room impulse responses. However, the conventional RGI technique poses several assumptions, such as convex room shapes, the number of walls known in priori, and the visibility of first-order reflections. In this work, we introduce the deep neural network (DNN), RGI-Net, which can estimate room geometries without the aforementioned assumptions. RGI-Net learns and exploits complex relationships between high-order reflections in room impulse responses (RIRs) and, thus, can estimate room shapes even when the shape is non-convex or first-order reflections are missing in the RIRs. The network takes RIRs measured from a compact audio device equipped with a circular microphone array and a single loudspeaker, which greatly improves its practical applicability. RGI-Net includes the evaluation network that separately evaluates the presence probability of walls, so the geometry inference is possible without prior knowledge of the number of walls.
A Simple Multiple-Access Design for Reconfigurable Intelligent Surface-Aided Systems
Sep 12, 2023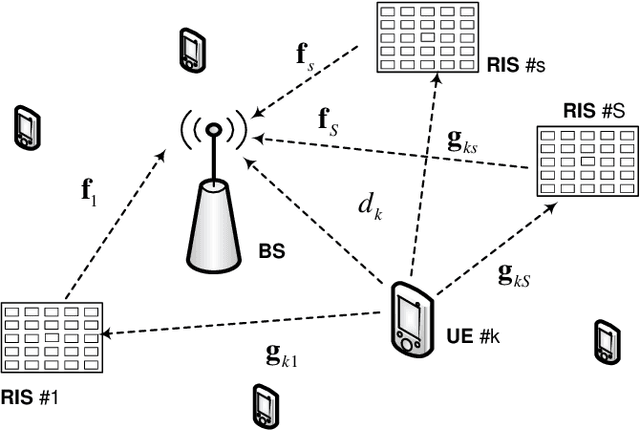
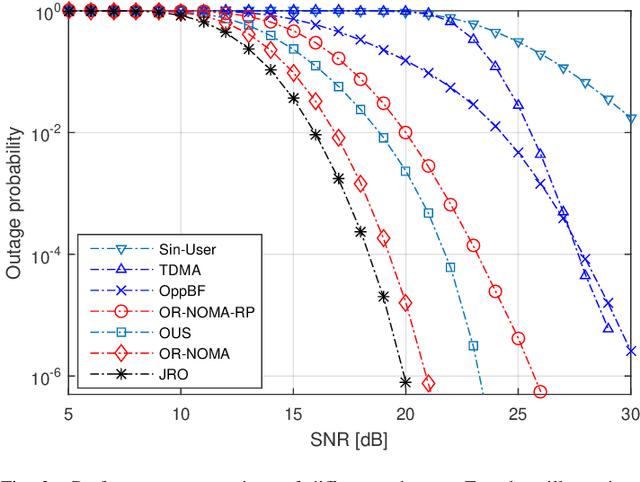
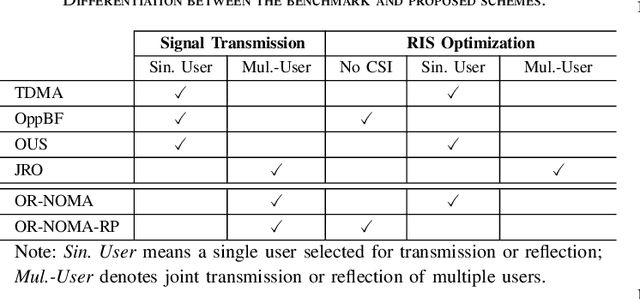
This paper focuses on the design of transmission methods and reflection optimization for a wireless system assisted by a single or multiple reconfigurable intelligent surfaces (RISs). The existing techniques are either too complex to implement in practical systems or too inefficient to achieve high performance. To overcome the shortcomings of the existing schemes, we propose a simple but efficient approach based on \textit{opportunistic reflection} and \textit{non-orthogonal transmission}. The key idea is opportunistically selecting the best user that can reap the maximal gain from the optimally reflected signals via RIS. That is to say, only the channel state information of the best user is used for RIS reflection optimization, which can in turn lower complexity substantially. In addition, the second user is selected to superpose its signal on that of the primary user, where the benefits of non-orthogonal transmission, i.e., high system capacity and improved user fairness, are obtained. Additionally, a simplified variant exploiting random phase shifts is proposed to avoid the high overhead of RIS channel estimation.
RGB-Guided Resolution Enhancement of IR Images
Sep 12, 2023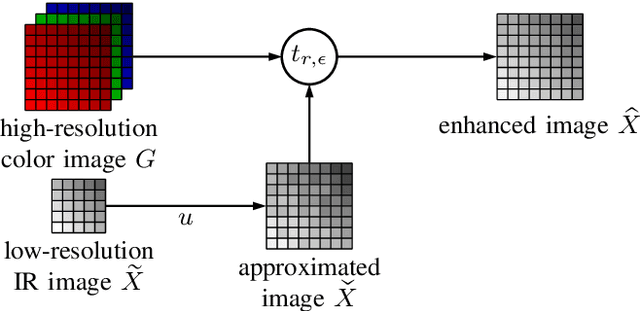



This paper introduces a novel method for RGB-Guided Resolution Enhancement of infrared (IR) images called Guided IR Resolution Enhancement (GIRRE). In the area of single image super resolution (SISR) there exists a wide variety of algorithms like interpolation methods or neural networks to improve the spatial resolution of images. In contrast to SISR, even more information can be gathered on the recorded scene when using multiple cameras. In our setup, we are dealing with multi image super resolution, especially with stereo super resolution. We consider a color camera and an IR camera. Current IR sensors have a very low resolution compared to color sensors so that recent color sensors take up 100 times more pixels than IR sensors. To this end, GIRRE increases the spatial resolution of the low-resolution IR image. After that, the upscaled image is filtered with the aid of the high-resolution color image. We show that our method achieves an average PSNR gain of 1.2 dB and at best up to 1.8 dB compared to state-of-the-art methods, which is visually noticeable.
LONER: LiDAR Only Neural Representations for Real-Time SLAM
Sep 12, 2023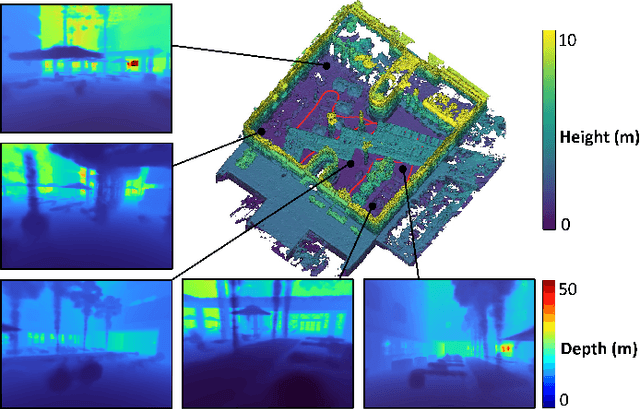
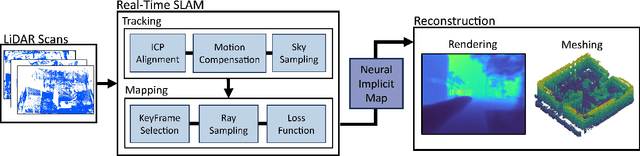
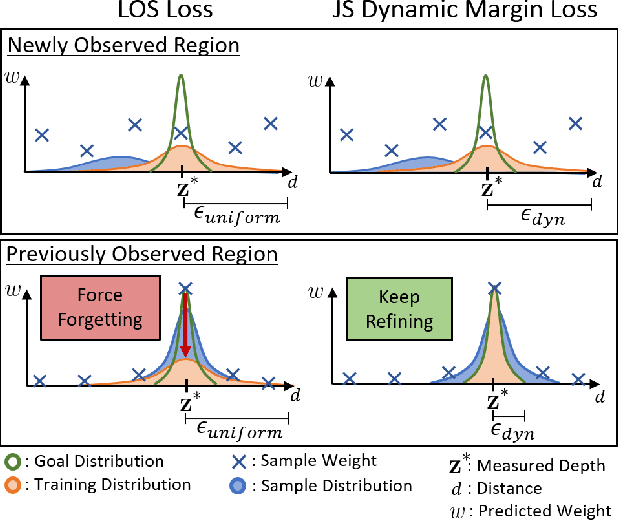
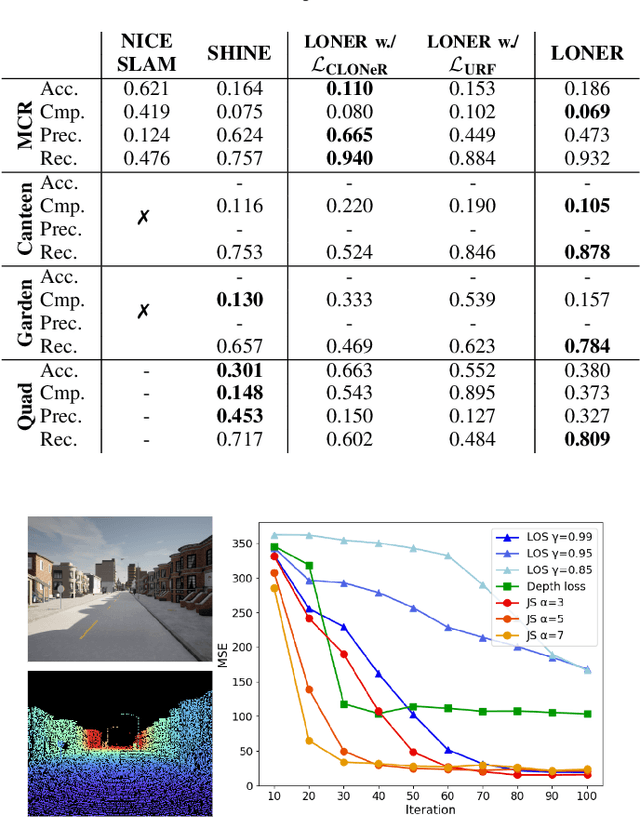
This paper proposes LONER, the first real-time LiDAR SLAM algorithm that uses a neural implicit scene representation. Existing implicit mapping methods for LiDAR show promising results in large-scale reconstruction, but either require groundtruth poses or run slower than real-time. In contrast, LONER uses LiDAR data to train an MLP to estimate a dense map in real-time, while simultaneously estimating the trajectory of the sensor. To achieve real-time performance, this paper proposes a novel information-theoretic loss function that accounts for the fact that different regions of the map may be learned to varying degrees throughout online training. The proposed method is evaluated qualitatively and quantitatively on two open-source datasets. This evaluation illustrates that the proposed loss function converges faster and leads to more accurate geometry reconstruction than other loss functions used in depth-supervised neural implicit frameworks. Finally, this paper shows that LONER estimates trajectories competitively with state-of-the-art LiDAR SLAM methods, while also producing dense maps competitive with existing real-time implicit mapping methods that use groundtruth poses.
Long-Range Correlation Supervision for Land-Cover Classification from Remote Sensing Images
Sep 08, 2023
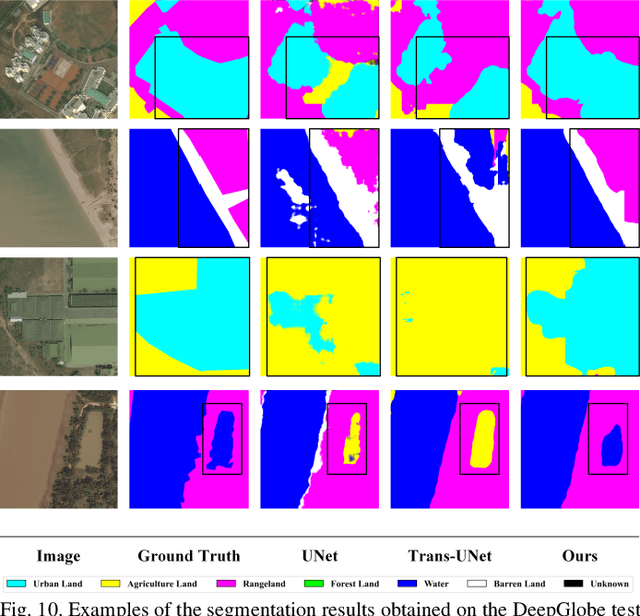
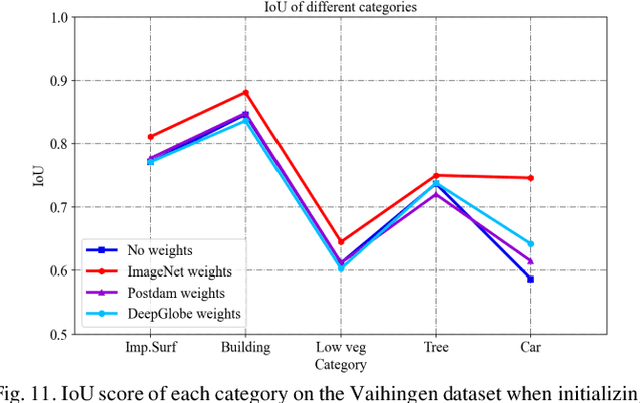
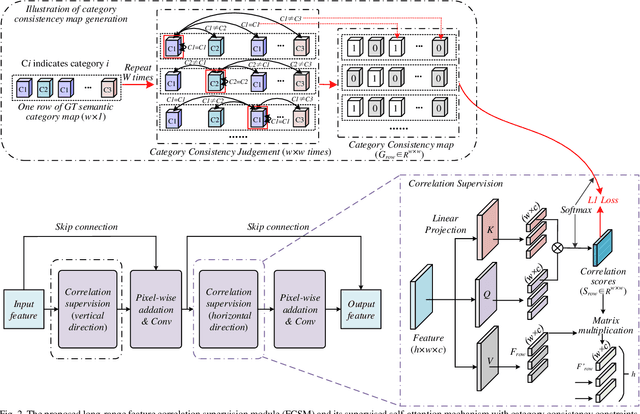
Long-range dependency modeling has been widely considered in modern deep learning based semantic segmentation methods, especially those designed for large-size remote sensing images, to compensate the intrinsic locality of standard convolutions. However, in previous studies, the long-range dependency, modeled with an attention mechanism or transformer model, has been based on unsupervised learning, instead of explicit supervision from the objective ground truth. In this paper, we propose a novel supervised long-range correlation method for land-cover classification, called the supervised long-range correlation network (SLCNet), which is shown to be superior to the currently used unsupervised strategies. In SLCNet, pixels sharing the same category are considered highly correlated and those having different categories are less relevant, which can be easily supervised by the category consistency information available in the ground truth semantic segmentation map. Under such supervision, the recalibrated features are more consistent for pixels of the same category and more discriminative for pixels of other categories, regardless of their proximity. To complement the detailed information lacking in the global long-range correlation, we introduce an auxiliary adaptive receptive field feature extraction module, parallel to the long-range correlation module in the encoder, to capture finely detailed feature representations for multi-size objects in multi-scale remote sensing images. In addition, we apply multi-scale side-output supervision and a hybrid loss function as local and global constraints to further boost the segmentation accuracy. Experiments were conducted on three remote sensing datasets. Compared with the advanced segmentation methods from the computer vision, medicine, and remote sensing communities, the SLCNet achieved a state-of-the-art performance on all the datasets.
Probabilistic Dataset Reconstruction from Interpretable Models
Aug 29, 2023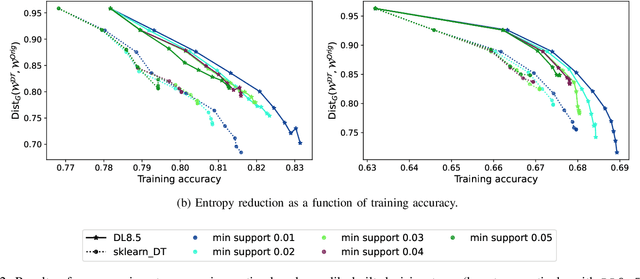
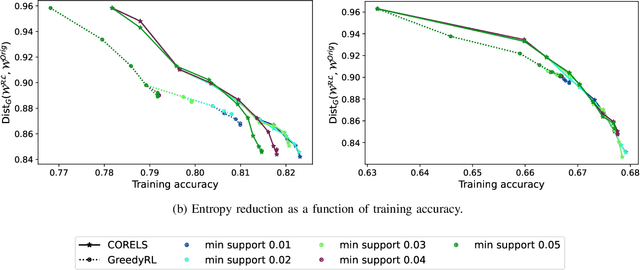
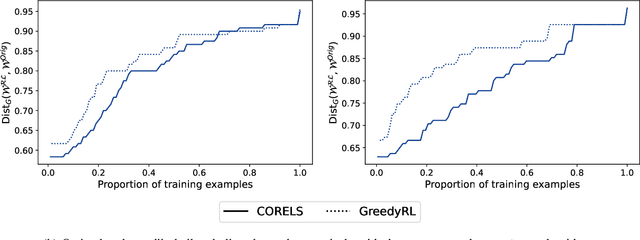
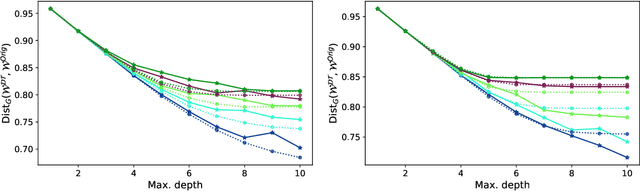
Interpretability is often pointed out as a key requirement for trustworthy machine learning. However, learning and releasing models that are inherently interpretable leaks information regarding the underlying training data. As such disclosure may directly conflict with privacy, a precise quantification of the privacy impact of such breach is a fundamental problem. For instance, previous work have shown that the structure of a decision tree can be leveraged to build a probabilistic reconstruction of its training dataset, with the uncertainty of the reconstruction being a relevant metric for the information leak. In this paper, we propose of a novel framework generalizing these probabilistic reconstructions in the sense that it can handle other forms of interpretable models and more generic types of knowledge. In addition, we demonstrate that under realistic assumptions regarding the interpretable models' structure, the uncertainty of the reconstruction can be computed efficiently. Finally, we illustrate the applicability of our approach on both decision trees and rule lists, by comparing the theoretical information leak associated to either exact or heuristic learning algorithms. Our results suggest that optimal interpretable models are often more compact and leak less information regarding their training data than greedily-built ones, for a given accuracy level.
Design of a Single-User RIS-Aided MISO System Based on Statistical Channel Knowledge
Sep 08, 2023Reconfigurable intelligent surface (RIS) is considered a prospective technology for beyond fifth-generation (5G) networks to improve the spectral and energy efficiency at a low cost. Prior works on the RIS mainly rely on perfect channel state information (CSI), which imposes a huge computational complexity. This work considers a single-user RIS-assisted communication system, where the second-order statistical knowledge of the channels is exploited to reduce the training overhead. We present algorithms that do not require estimation of the CSI and reconfiguration of the RIS in every channel coherence interval, which constitutes one of the most critical practical issues in an RIS-aided system.
Implicit Design Choices and Their Impact on Emotion Recognition Model Development and Evaluation
Sep 06, 2023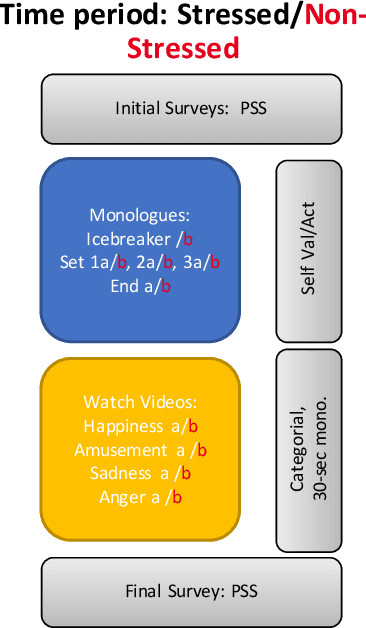
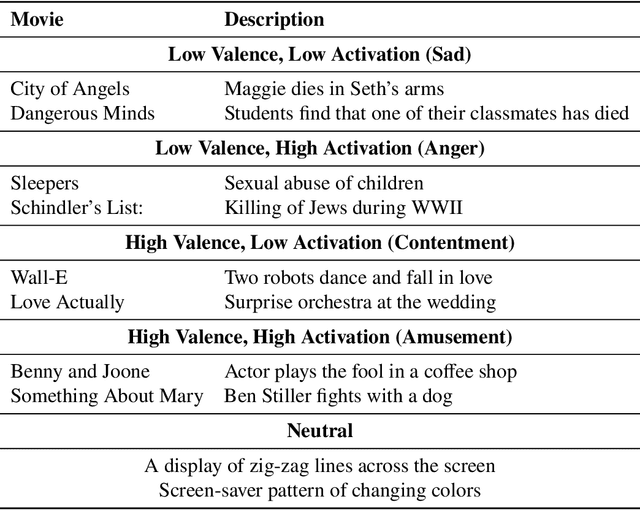

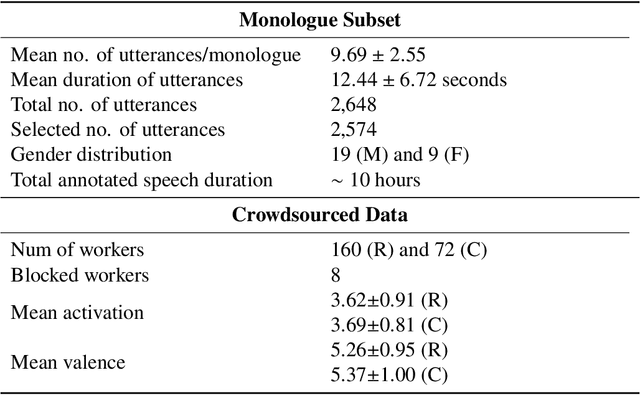
Emotion recognition is a complex task due to the inherent subjectivity in both the perception and production of emotions. The subjectivity of emotions poses significant challenges in developing accurate and robust computational models. This thesis examines critical facets of emotion recognition, beginning with the collection of diverse datasets that account for psychological factors in emotion production. To handle the challenge of non-representative training data, this work collects the Multimodal Stressed Emotion dataset, which introduces controlled stressors during data collection to better represent real-world influences on emotion production. To address issues with label subjectivity, this research comprehensively analyzes how data augmentation techniques and annotation schemes impact emotion perception and annotator labels. It further handles natural confounding variables and variations by employing adversarial networks to isolate key factors like stress from learned emotion representations during model training. For tackling concerns about leakage of sensitive demographic variables, this work leverages adversarial learning to strip sensitive demographic information from multimodal encodings. Additionally, it proposes optimized sociological evaluation metrics aligned with cost-effective, real-world needs for model testing. This research advances robust, practical emotion recognition through multifaceted studies of challenges in datasets, labels, modeling, demographic and membership variable encoding in representations, and evaluation. The groundwork has been laid for cost-effective, generalizable emotion recognition models that are less likely to encode sensitive demographic information.