 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hardening RGB-D Object Recognition Systems against Adversarial Patch Attacks
Sep 13, 2023
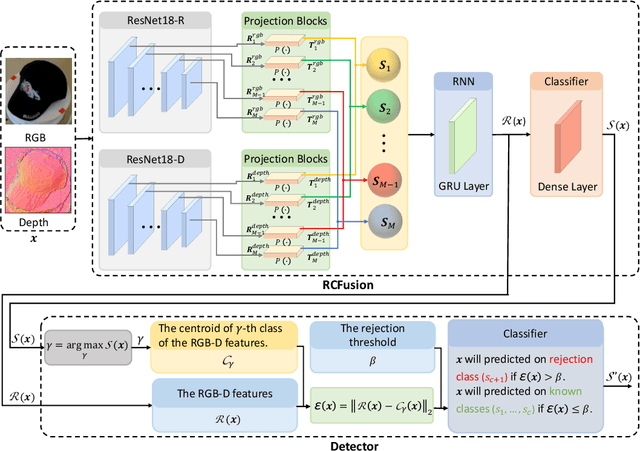
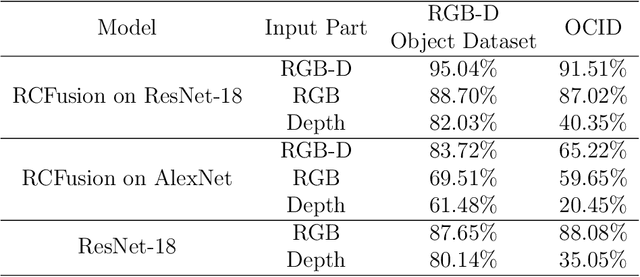
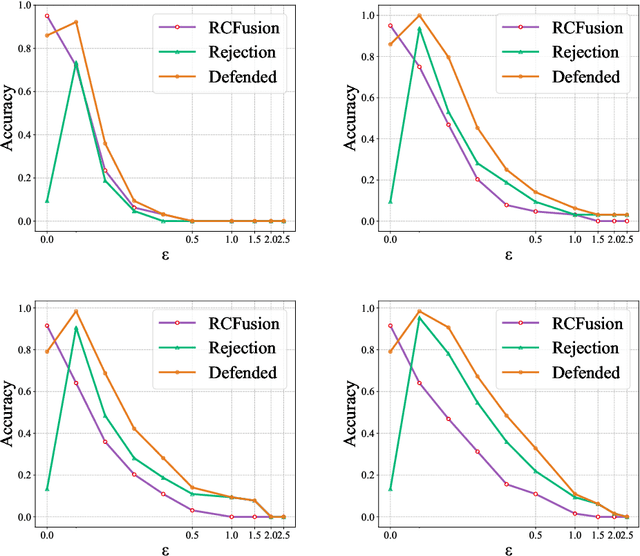
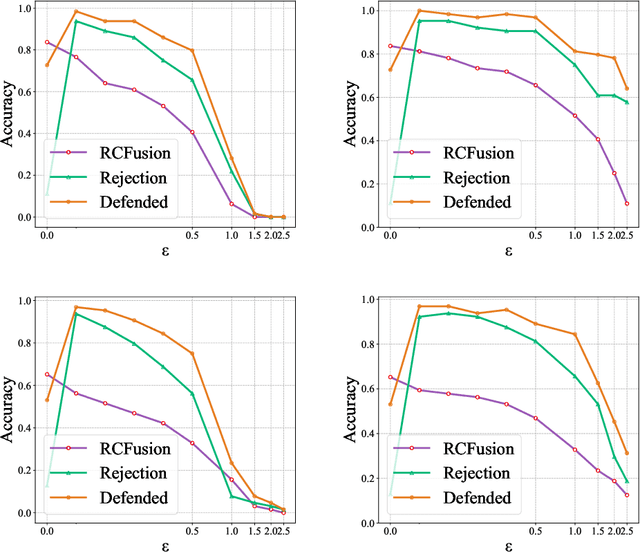
RGB-D object recognition systems improve their predictive performances by fusing color and depth information, outperforming neural network architectures that rely solely on colors. While RGB-D systems are expected to be more robust to adversarial examples than RGB-only systems, they have also been proven to be highly vulnerable. Their robustness is similar even when the adversarial examples are generated by altering only the original images' colors. Different works highlighted the vulnerability of RGB-D systems; however, there is a lacking of technical explanations for this weakness. Hence, in our work, we bridge this gap by investigating the learned deep representation of RGB-D systems, discovering that color features make the function learned by the network more complex and, thus, more sensitive to small perturbations. To mitigate this problem, we propose a defense based on a detection mechanism that makes RGB-D systems more robust against adversarial examples. We empirically show that this defense improves the performances of RGB-D systems against adversarial examples even when they are computed ad-hoc to circumvent this detection mechanism, and that is also more effective than adversarial training.
Multi-behavior Recommendation with SVD Graph Neural Networks
Sep 13, 2023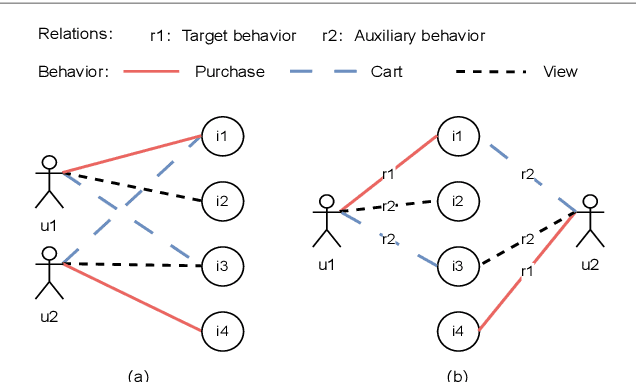
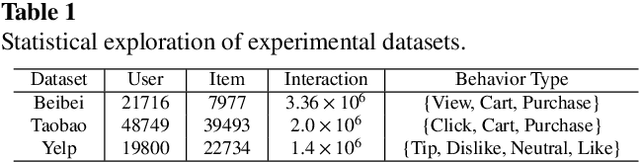
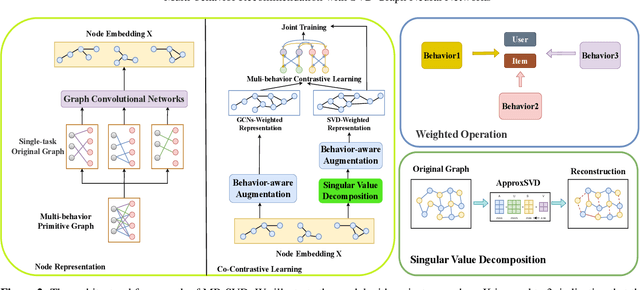
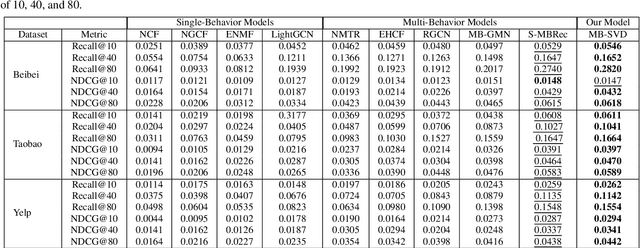
Graph Neural Networks (GNNs) has been extensively employed in the field of recommender systems, offering users personalized recommendations and yielding remarkable outcomes. Recently, GNNs incorporating contrastive learning have demonstrated promising performance in handling sparse data problem of recommendation system. However, existing contrastive learning methods still have limitations in addressing the cold-start problem and resisting noise interference especially for multi-behavior recommendation. To mitigate the aforementioned issues, the present research posits a GNNs based multi-behavior recommendation model MB-SVD that utilizes Singular Value Decomposition (SVD) graphs to enhance model performance. In particular, MB-SVD considers user preferences under different behaviors, improving recommendation effectiveness while better addressing the cold-start problem. Our model introduces an innovative methodology, which subsume multi-behavior contrastive learning paradigm to proficiently discern the intricate interconnections among heterogeneous manifestations of user behavior and generates SVD graphs to automate the distillation of crucial multi-behavior self-supervised information for robust graph augmentation. Furthermore, the SVD based framework reduces the embedding dimensions and computational load. Thorough experimentation showcases the remarkable performance of our proposed MB-SVD approach in multi-behavior recommendation endeavors across diverse real-world datasets.
MASTERKEY: Practical Backdoor Attack Against Speaker Verification Systems
Sep 13, 2023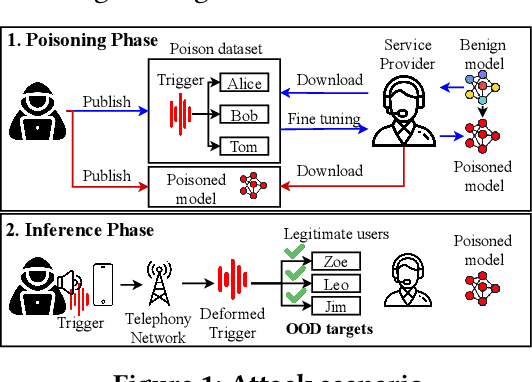
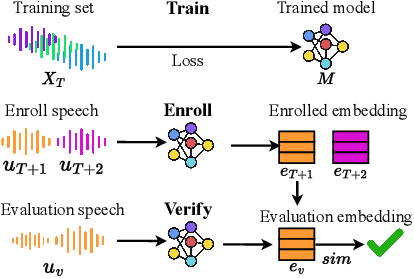
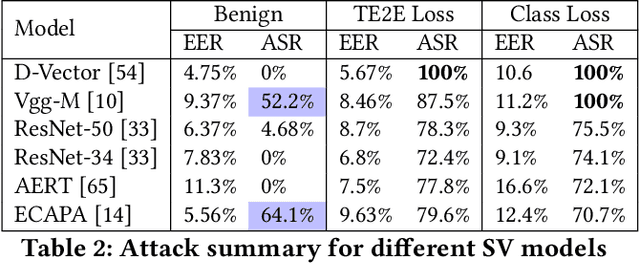
Speaker Verification (SV) is widely deployed in mobile systems to authenticate legitimate users by using their voice traits. In this work, we propose a backdoor attack MASTERKEY, to compromise the SV models. Different from previous attacks, we focus on a real-world practical setting where the attacker possesses no knowledge of the intended victim. To design MASTERKEY, we investigate the limitation of existing poisoning attacks against unseen targets. Then, we optimize a universal backdoor that is capable of attacking arbitrary targets. Next, we embed the speaker's characteristics and semantics information into the backdoor, making it imperceptible. Finally, we estimate the channel distortion and integrate it into the backdoor. We validate our attack on 6 popular SV models. Specifically, we poison a total of 53 models and use our trigger to attack 16,430 enrolled speakers, composed of 310 target speakers enrolled in 53 poisoned models. Our attack achieves 100% attack success rate with a 15% poison rate. By decreasing the poison rate to 3%, the attack success rate remains around 50%. We validate our attack in 3 real-world scenarios and successfully demonstrate the attack through both over-the-air and over-the-telephony-line scenarios.
Towards Connecting Control to Perception: High-Performance Whole-Body Collision Avoidance Using Control-Compatible Obstacles
Sep 13, 2023One of the most important aspects of autonomous systems is safety. This includes ensuring safe human-robot and safe robot-environment interaction when autonomously performing complex tasks or in collaborative scenarios. Although several methods have been introduced to tackle this, most are unsuitable for real-time applications and require carefully hand-crafted obstacle descriptions. In this work, we propose a method combining high-frequency and real-time self and environment collision avoidance of a robotic manipulator with low-frequency, multimodal, and high-resolution environmental perceptions accumulated in a digital twin system. Our method is based on geometric primitives, so-called primitive skeletons. These, in turn, are information-compressed and real-time compatible digital representations of the robot's body and environment, automatically generated from ultra-realistic virtual replicas of the real world provided by the digital twin. Our approach is a key enabler for closing the loop between environment perception and robot control by providing the millisecond real-time control stage with a current and accurate world description, empowering it to react to environmental changes. We evaluate our whole-body collision avoidance on a 9-DOFs robot system through five experiments, demonstrating the functionality and efficiency of our framework.
A Novel Perception and Semantic Mapping Method for Robot Autonomy in Orchards
Sep 01, 2023In this work, we propose a novel framework for achieving robotic autonomy in orchards. It consists of two key steps: perception and semantic mapping. In the perception step, we introduce a 3D detection method that accurately identifies objects directly on point cloud maps. In the semantic mapping step, we develop a mapping module that constructs a visibility graph map by incorporating object-level information and terrain analysis. By combining these two steps, our framework improves the autonomy of agricultural robots in orchard environments. The accurate detection of objects and the construction of a semantic map enable the robot to navigate autonomously, perform tasks such as fruit harvesting, and acquire actionable information for efficient agricultural production.
Double Domain Guided Real-Time Low-Light Image Enhancement for Ultra-High-Definition Transportation Surveillance
Sep 15, 2023Real-time transportation surveillance is an essential part of the intelligent transportation system (ITS). However, images captured under low-light conditions often suffer the poor visibility with types of degradation, such as noise interference and vague edge features, etc. With the development of imaging devices, the quality of the visual surveillance data is continually increasing, like 2K and 4K, which has more strict requirements on the efficiency of image processing. To satisfy the requirements on both enhancement quality and computational speed, this paper proposes a double domain guided real-time low-light image enhancement network (DDNet) for ultra-high-definition (UHD) transportation surveillance. Specifically, we design an encoder-decoder structure as the main architecture of the learning network. In particular, the enhancement processing is divided into two subtasks (i.e., color enhancement and gradient enhancement) via the proposed coarse enhancement module (CEM) and LoG-based gradient enhancement module (GEM), which are embedded in the encoder-decoder structure. It enables the network to enhance the color and edge features simultaneously. Through the decomposition and reconstruction on both color and gradient domains, our DDNet can restore the detailed feature information concealed by the darkness with better visual quality and efficiency. The evaluation experiments on standard and transportation-related datasets demonstrate that our DDNet provides superior enhancement quality and efficiency compared with the state-of-the-art methods. Besides, the object detection and scene segmentation experiments indicate the practical benefits for higher-level image analysis under low-light environments in ITS.
Uncertainty-bounded Active Monitoring of Unknown Dynamic Targets in Road-networks with Minimum Fleet
Sep 15, 2023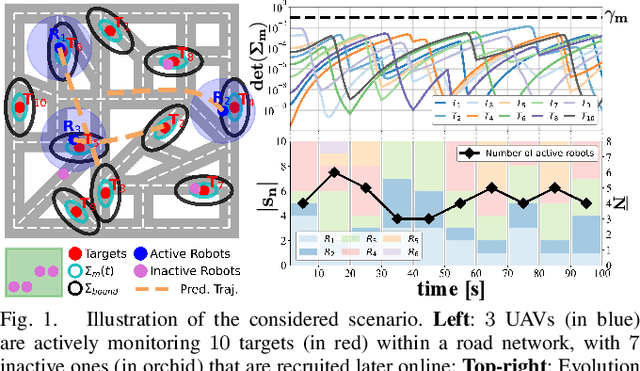
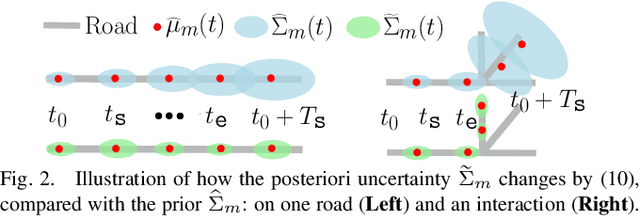
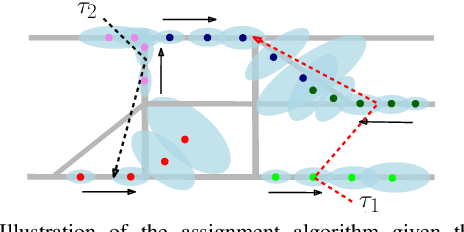
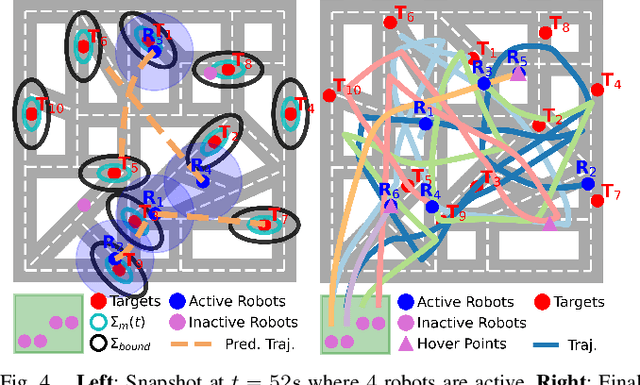
Fleets of unmanned robots can be beneficial for the long-term monitoring of large areas, e.g., to monitor wild flocks, detect intruders, search and rescue. Monitoring numerous dynamic targets in a collaborative and efficient way is a challenging problem that requires online coordination and information fusion. The majority of existing works either assume a passive all-to-all observation model to minimize the summed uncertainties over all targets by all robots, or optimize over the jointed discrete actions while neglecting the dynamic constraints of the robots and unknown behaviors of the targets. This work proposes an online task and motion coordination algorithm that ensures an explicitly-bounded estimation uncertainty for the target states, while minimizing the average number of active robots. The robots have a limited-range perception to actively track a limited number of targets simultaneously, of which their future control decisions are all unknown. It includes: (i) the assignment of monitoring tasks, modeled as a flexible size multiple vehicle routing problem with time windows (m-MVRPTW), given the predicted target trajectories with uncertainty measure in the road-networks; (ii) the nonlinear model predictive control (NMPC) for optimizing the robot trajectories under uncertainty and safety constraints. It is shown that the robots can switch between active and inactive roles dynamically online as required by the unknown monitoring task. The proposed methods are validated via large-scale simulations of up to $100$ robots and targets.
Mining Patents with Large Language Models Demonstrates Congruence of Functional Labels and Chemical Structures
Sep 15, 2023Predicting chemical function from structure is a major goal of the chemical sciences, from the discovery and repurposing of novel drugs to the creation of new materials. Recently, new machine learning algorithms are opening up the possibility of general predictive models spanning many different chemical functions. Here, we consider the challenge of applying large language models to chemical patents in order to consolidate and leverage the information about chemical functionality captured by these resources. Chemical patents contain vast knowledge on chemical function, but their usefulness as a dataset has historically been neglected due to the impracticality of extracting high-quality functional labels. Using a scalable ChatGPT-assisted patent summarization and word-embedding label cleaning pipeline, we derive a Chemical Function (CheF) dataset, containing 100K molecules and their patent-derived functional labels. The functional labels were validated to be of high quality, allowing us to detect a strong relationship between functional label and chemical structural spaces. Further, we find that the co-occurrence graph of the functional labels contains a robust semantic structure, which allowed us in turn to examine functional relatedness among the compounds. We then trained a model on the CheF dataset, allowing us to assign new functional labels to compounds. Using this model, we were able to retrodict approved Hepatitis C antivirals, uncover an antiviral mechanism undisclosed in the patent, and identify plausible serotonin-related drugs. The CheF dataset and associated model offers a promising new approach to predict chemical functionality.
Reproducible Domain-Specific Knowledge Graphs in the Life Sciences: a Systematic Literature Review
Sep 15, 2023Knowledge graphs (KGs) are widely used for representing and organizing structured knowledge in diverse domains. However, the creation and upkeep of KGs pose substantial challenges. Developing a KG demands extensive expertise in data modeling, ontology design, and data curation. Furthermore, KGs are dynamic, requiring continuous updates and quality control to ensure accuracy and relevance. These intricacies contribute to the considerable effort required for their development and maintenance. One critical dimension of KGs that warrants attention is reproducibility. The ability to replicate and validate KGs is fundamental for ensuring the trustworthiness and sustainability of the knowledge they represent. Reproducible KGs not only support open science by allowing others to build upon existing knowledge but also enhance transparency and reliability in disseminating information. Despite the growing number of domain-specific KGs, a comprehensive analysis concerning their reproducibility has been lacking. This paper addresses this gap by offering a general overview of domain-specific KGs and comparing them based on various reproducibility criteria. Our study over 19 different domains shows only eight out of 250 domain-specific KGs (3.2%) provide publicly available source code. Among these, only one system could successfully pass our reproducibility assessment (14.3%). These findings highlight the challenges and gaps in achieving reproducibility across domain-specific KGs. Our finding that only 0.4% of published domain-specific KGs are reproducible shows a clear need for further research and a shift in cultural practices.
Beyond CO2 Emissions: The Overlooked Impact of Water Consumption of Information Retrieval Models
Jun 29, 2023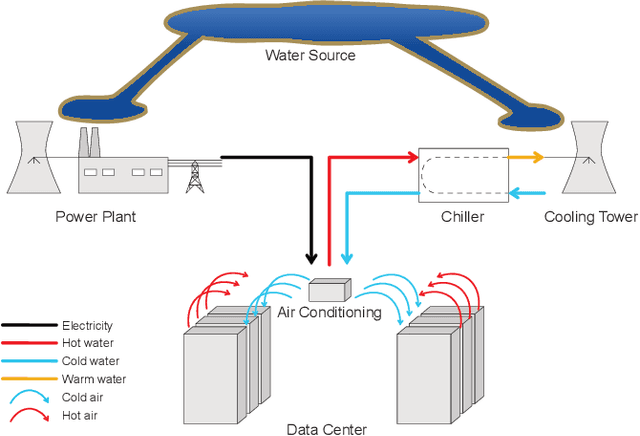
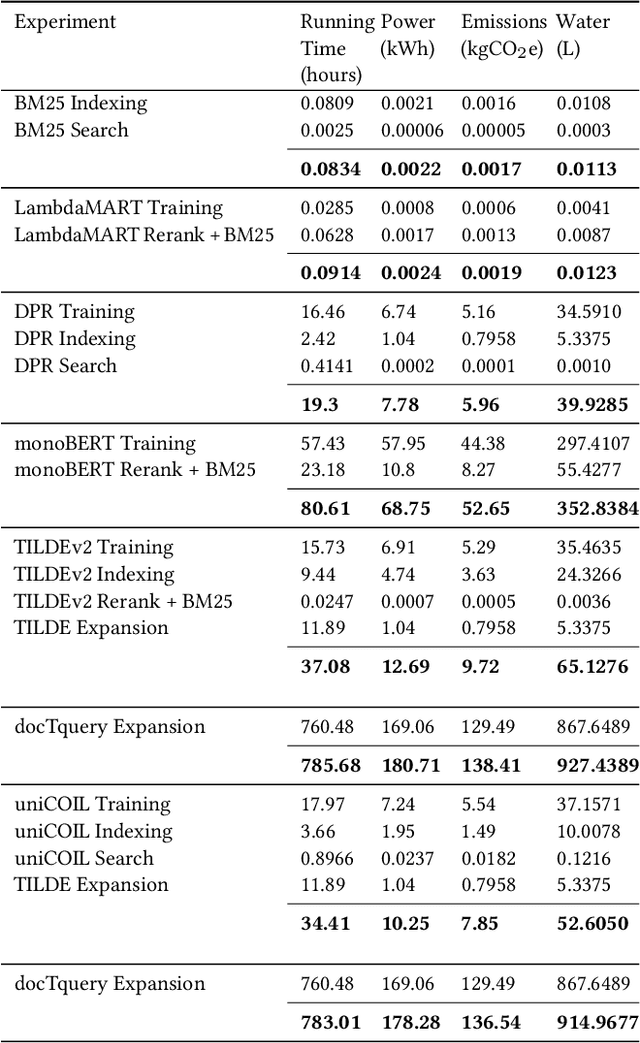
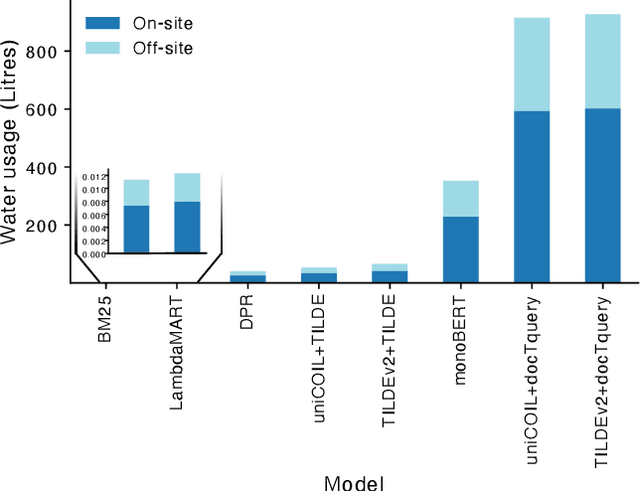
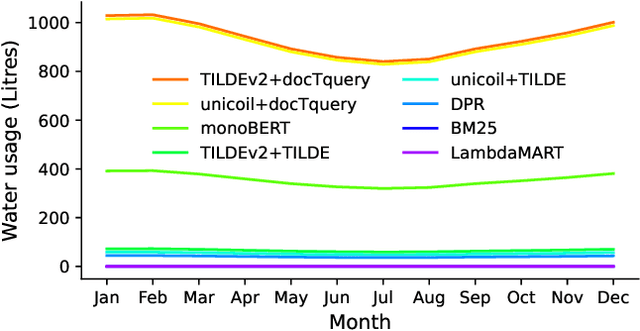
As in other fields of artificial intelligence, the information retrieval community has grown interested in investigating the power consumption associated with neural models, particularly models of search. This interest has become particularly relevant as the energy consumption of information retrieval models has risen with new neural models based on large language models, leading to an associated increase of CO2 emissions, albeit relatively low compared to fields such as natural language processing.