 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FedJudge: Federated Legal Large Language Model
Sep 15, 2023

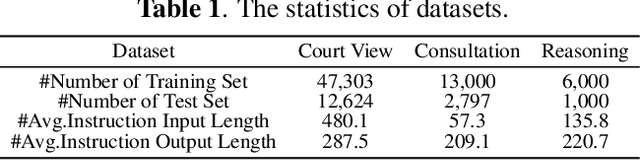
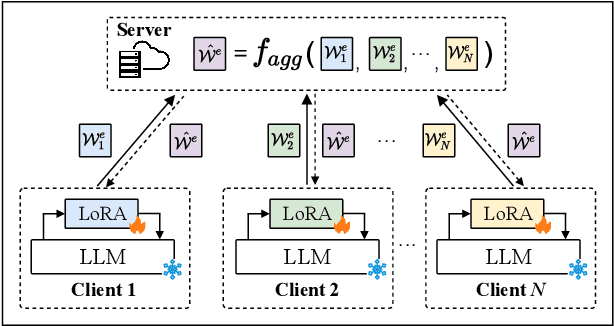
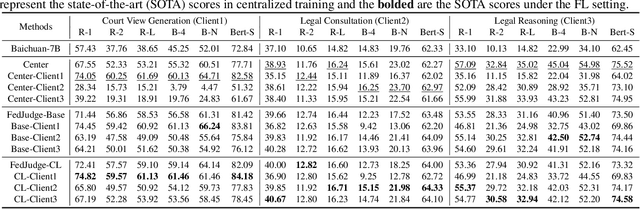
Large Language Models (LLMs) have gained prominence in the field of Legal Intelligence, offering potential applications in assisting legal professionals and laymen. However, the centralized training of these Legal LLMs raises data privacy concerns, as legal data is distributed among various institutions containing sensitive individual information. This paper addresses this challenge by exploring the integration of Legal LLMs with Federated Learning (FL) methodologies. By employing FL, Legal LLMs can be fine-tuned locally on devices or clients, and their parameters are aggregated and distributed on a central server, ensuring data privacy without directly sharing raw data. However, computation and communication overheads hinder the full fine-tuning of LLMs under the FL setting. Moreover, the distribution shift of legal data reduces the effectiveness of FL methods. To this end, in this paper, we propose the first Federated Legal Large Language Model (FedJudge) framework, which fine-tunes Legal LLMs efficiently and effectively. Specifically, FedJudge utilizes parameter-efficient fine-tuning methods to update only a few additional parameters during the FL training. Besides, we explore the continual learning methods to preserve the global model's important parameters when training local clients to mitigate the problem of data shifts. Extensive experimental results on three real-world datasets clearly validate the effectiveness of FedJudge. Code is released at https://github.com/yuelinan/FedJudge.
Efficient Polyp Segmentation Via Integrity Learning
Sep 15, 2023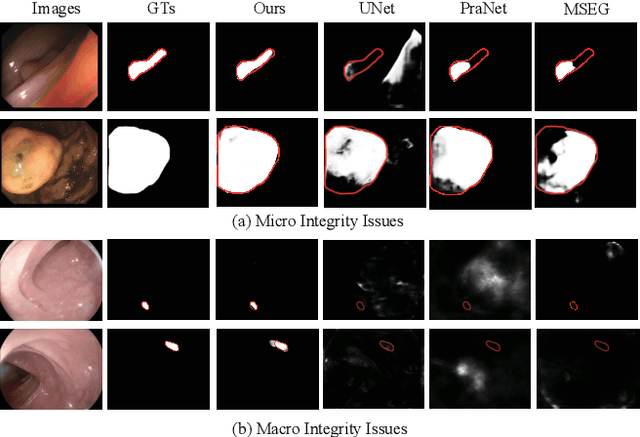
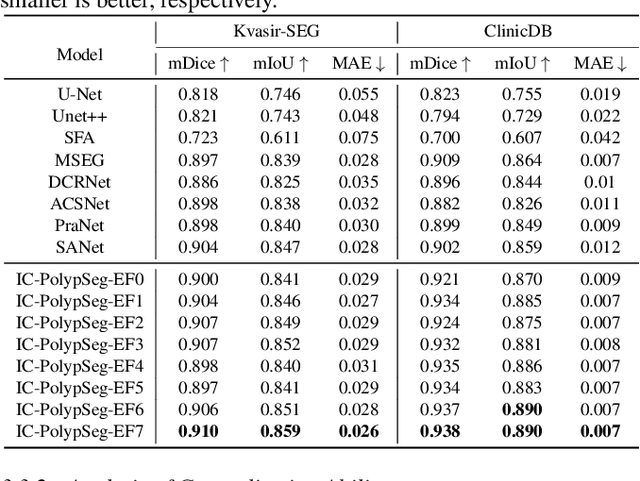

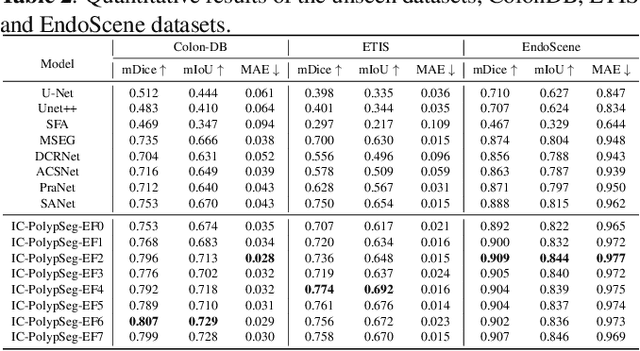
Accurate polyp delineation in colonoscopy is crucial for assisting in diagnosis, guiding interventions, and treatments. However, current deep-learning approaches fall short due to integrity deficiency, which often manifests as missing lesion parts. This paper introduces the integrity concept in polyp segmentation at both macro and micro levels, aiming to alleviate integrity deficiency. Specifically, the model should distinguish entire polyps at the macro level and identify all components within polyps at the micro level. Our Integrity Capturing Polyp Segmentation (IC-PolypSeg) network utilizes lightweight backbones and 3 key components for integrity ameliorating: 1) Pixel-wise feature redistribution (PFR) module captures global spatial correlations across channels in the final semantic-rich encoder features. 2) Cross-stage pixel-wise feature redistribution (CPFR) module dynamically fuses high-level semantics and low-level spatial features to capture contextual information. 3) Coarse-to-fine calibration module combines PFR and CPFR modules to achieve precise boundary detection. Extensive experiments on 5 public datasets demonstrate that the proposed IC-PolypSeg outperforms 8 state-of-the-art methods in terms of higher precision and significantly improved computational efficiency with lower computational consumption. IC-PolypSeg-EF0 employs 300 times fewer parameters than PraNet while achieving a real-time processing speed of 235 FPS. Importantly, IC-PolypSeg reduces the false negative ratio on five datasets, meeting clinical requirements.
Beyond Domain Gap: Exploiting Subjectivity in Sketch-Based Person Retrieval
Sep 15, 2023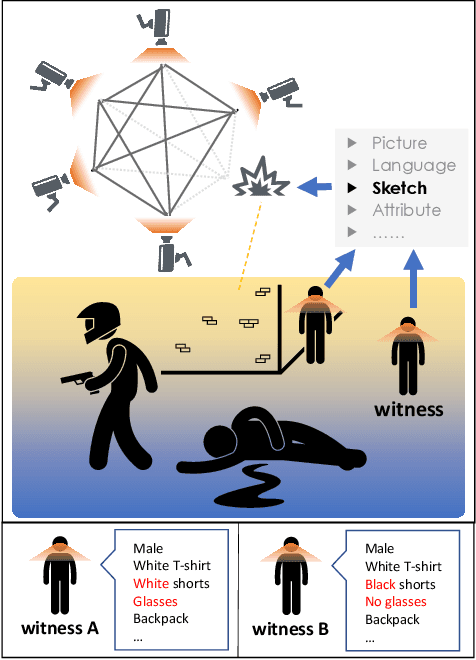

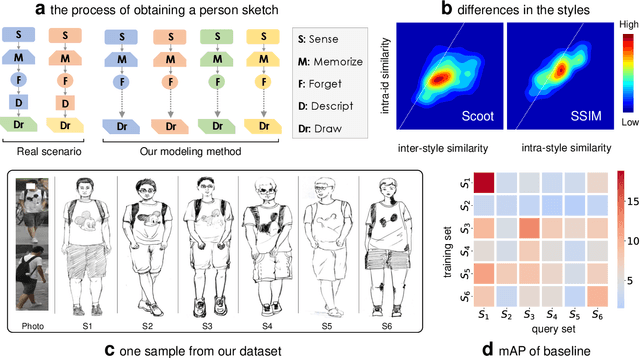
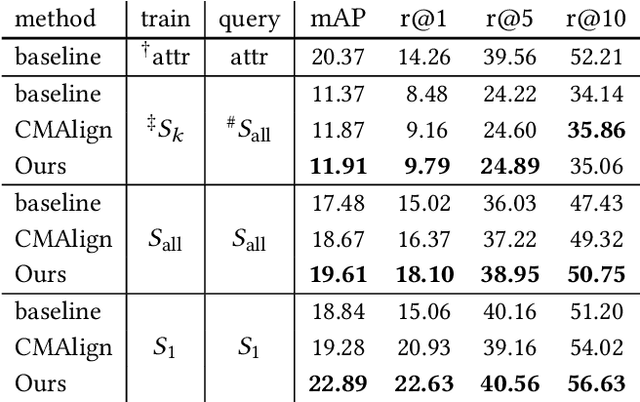
Person re-identification (re-ID) requires densely distributed cameras. In practice, the person of interest may not be captured by cameras and, therefore, needs to be retrieved using subjective information (e.g., sketches from witnesses). Previous research defines this case using the sketch as sketch re-identification (Sketch re-ID) and focuses on eliminating the domain gap. Actually, subjectivity is another significant challenge. We model and investigate it by posing a new dataset with multi-witness descriptions. It features two aspects. 1) Large-scale. It contains over 4,763 sketches and 32,668 photos, making it the largest Sketch re-ID dataset. 2) Multi-perspective and multi-style. Our dataset offers multiple sketches for each identity. Witnesses' subjective cognition provides multiple perspectives on the same individual, while different artists' drawing styles provide variation in sketch styles. We further have two novel designs to alleviate the challenge of subjectivity. 1) Fusing subjectivity. We propose a non-local (NL) fusion module that gathers sketches from different witnesses for the same identity. 2) Introducing objectivity. An AttrAlign module utilizes attributes as an implicit mask to align cross-domain features. To push forward the advance of Sketch re-ID, we set three benchmarks (large-scale, multi-style, cross-style). Extensive experiments demonstrate our leading performance in these benchmarks. Dataset and Codes are publicly available at: https://github.com/Lin-Kayla/subjectivity-sketch-reid
TreeLearn: A Comprehensive Deep Learning Method for Segmenting Individual Trees from Forest Point Clouds
Sep 15, 2023
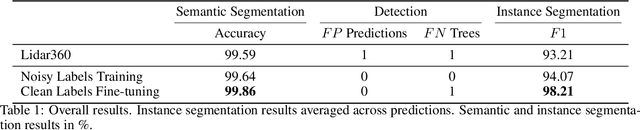
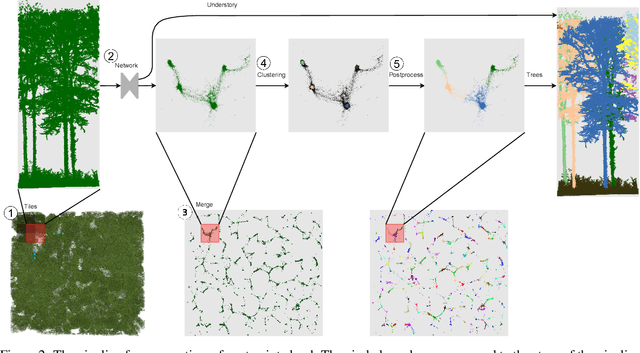

Laser-scanned point clouds of forests make it possible to extract valuable information for forest management. To consider single trees, a forest point cloud needs to be segmented into individual tree point clouds. Existing segmentation methods are usually based on hand-crafted algorithms, such as identifying trunks and growing trees from them, and face difficulties in dense forests with overlapping tree crowns. In this study, we propose \mbox{TreeLearn}, a deep learning-based approach for semantic and instance segmentation of forest point clouds. Unlike previous methods, TreeLearn is trained on already segmented point clouds in a data-driven manner, making it less reliant on predefined features and algorithms. Additionally, we introduce a new manually segmented benchmark forest dataset containing 156 full trees, and 79 partial trees, that have been cleanly segmented by hand. This enables the evaluation of instance segmentation performance going beyond just evaluating the detection of individual trees. We trained TreeLearn on forest point clouds of 6665 trees, labeled using the Lidar360 software. An evaluation on the benchmark dataset shows that TreeLearn performs equally well or better than the algorithm used to generate its training data. Furthermore, the method's performance can be vastly improved by fine-tuning on the cleanly labeled benchmark dataset. The TreeLearn code is availabe from https://github.com/ecker-lab/TreeLearn. The data as well as trained models can be found at https://doi.org/10.25625/VPMPID.
Robust IRS-Element Activation for Energy Efficiency Optimization in IRS-Assisted Communication Systems With Imperfect CSI
Sep 15, 2023In this paper, we study an intelligent reflecting surface (IRS)-aided communication system with single-antenna transmitter and receiver, under imperfect channel state information (CSI). More specifically, we deal with the robust selection of binary (on/off) states of the IRS elements in order to maximize the worst-case energy efficiency (EE), given a bounded CSI uncertainty, while satisfying a minimum signal-to-noise ratio (SNR). In addition, we consider not only continuous but also discrete IRS phase shifts. First, we derive closed-form expressions of the worst-case SNRs, and then formulate the robust (discrete) optimization problems for each case. In the case of continuous phase shifts, we design a dynamic programming (DP) algorithm that is theoretically guaranteed to achieve the global maximum with polynomial complexity $O(L\,{\log L})$, where $L$ is the number of IRS elements. In the case of discrete phase shifts, we develop a convex-relaxation-based method (CRBM) to obtain a feasible (sub-optimal) solution in polynomial time $O(L^{3.5})$, with a posteriori performance guarantee. Furthermore, numerical simulations provide useful insights and confirm the theoretical results. In particular, the proposed algorithms are several orders of magnitude faster than the exhaustive search when $L$ is large, thus being highly scalable and suitable for practical applications. Moreover, both algorithms outperform a baseline scheme, namely, the activation of all IRS elements.
Automated CVE Analysis for Threat Prioritization and Impact Prediction
Sep 06, 2023

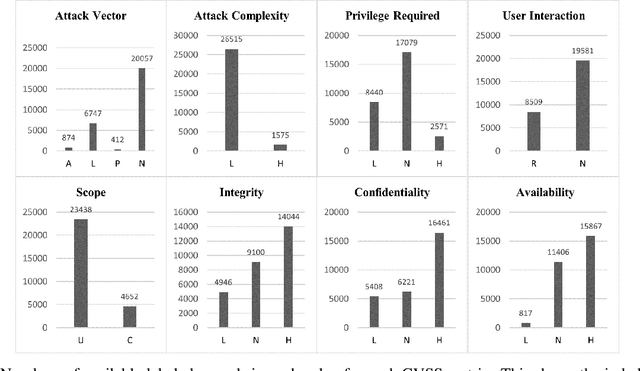
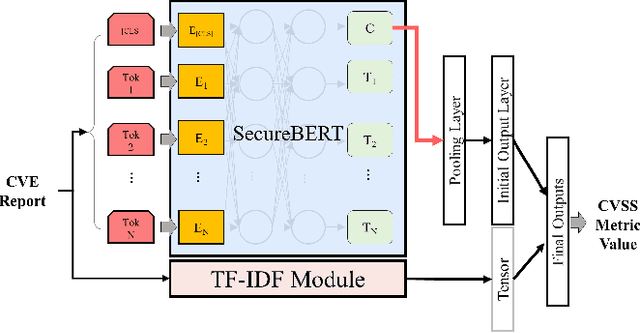
The Common Vulnerabilities and Exposures (CVE) are pivotal information for proactive cybersecurity measures, including service patching, security hardening, and more. However, CVEs typically offer low-level, product-oriented descriptions of publicly disclosed cybersecurity vulnerabilities, often lacking the essential attack semantic information required for comprehensive weakness characterization and threat impact estimation. This critical insight is essential for CVE prioritization and the identification of potential countermeasures, particularly when dealing with a large number of CVEs. Current industry practices involve manual evaluation of CVEs to assess their attack severities using the Common Vulnerability Scoring System (CVSS) and mapping them to Common Weakness Enumeration (CWE) for potential mitigation identification. Unfortunately, this manual analysis presents a major bottleneck in the vulnerability analysis process, leading to slowdowns in proactive cybersecurity efforts and the potential for inaccuracies due to human errors. In this research, we introduce our novel predictive model and tool (called CVEDrill) which revolutionizes CVE analysis and threat prioritization. CVEDrill accurately estimates the CVSS vector for precise threat mitigation and priority ranking and seamlessly automates the classification of CVEs into the appropriate CWE hierarchy classes. By harnessing CVEDrill, organizations can now implement cybersecurity countermeasure mitigation with unparalleled accuracy and timeliness, surpassing in this domain the capabilities of state-of-the-art tools like ChaptGPT.
Investigating Online Financial Misinformation and Its Consequences: A Computational Perspective
Sep 06, 2023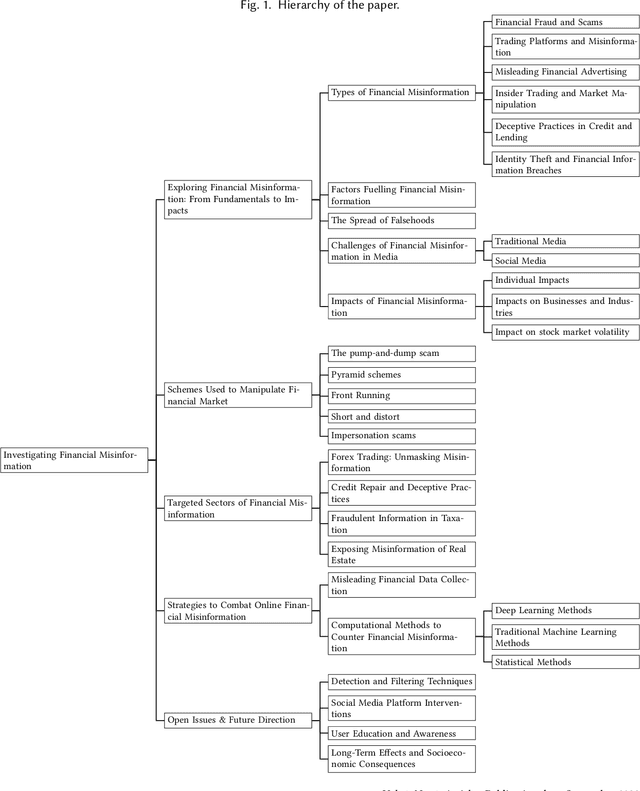
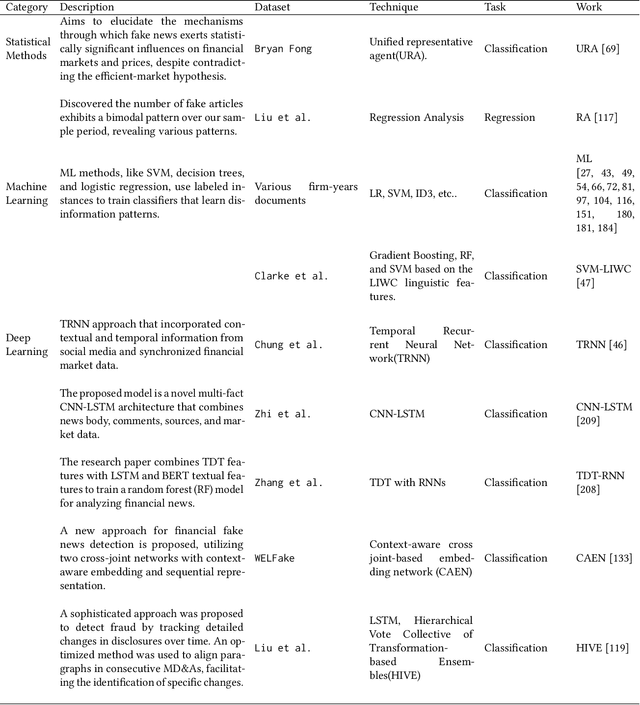
The rapid dissemination of information through digital platforms has revolutionized the way we access and consume news and information, particularly in the realm of finance. However, this digital age has also given rise to an alarming proliferation of financial misinformation, which can have detrimental effects on individuals, markets, and the overall economy. This research paper aims to provide a comprehensive survey of online financial misinformation, including its types, sources, and impacts. We first discuss the characteristics and manifestations of financial misinformation, encompassing false claims and misleading content. We explore various case studies that illustrate the detrimental consequences of financial misinformation on the economy. Finally, we highlight the potential impact and implications of detecting financial misinformation. Early detection and mitigation strategies can help protect investors, enhance market transparency, and preserve financial stability. We emphasize the importance of greater awareness, education, and regulation to address the issue of online financial misinformation and safeguard individuals and businesses from its harmful effects. In conclusion, this research paper sheds light on the pervasive issue of online financial misinformation and its wide-ranging consequences. By understanding the types, sources, and impacts of misinformation, stakeholders can work towards implementing effective detection and prevention measures to foster a more informed and resilient financial ecosystem.
SGLD-Based Information Criteria and the Over-Parameterized Regime
Jun 08, 2023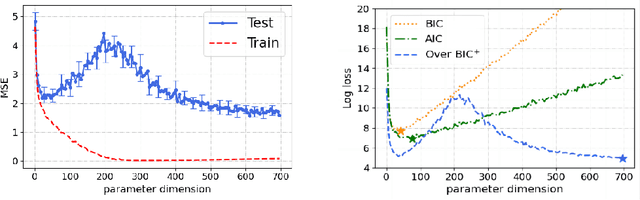
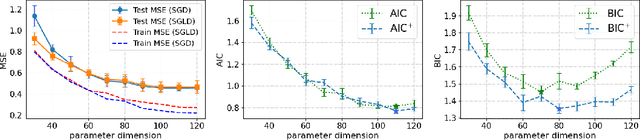
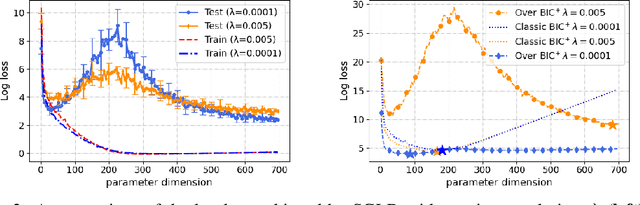
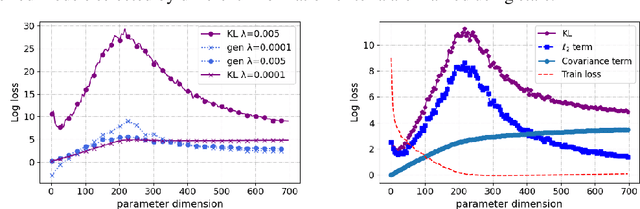
Double-descent refers to the unexpected drop in test loss of a learning algorithm beyond an interpolating threshold with over-parameterization, which is not predicted by information criteria in their classical forms due to the limitations in the standard asymptotic approach. We update these analyses using the information risk minimization framework and provide Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) for models learned by stochastic gradient Langevin dynamics (SGLD). Notably, the AIC and BIC penalty terms for SGLD correspond to specific information measures, i.e., symmetrized KL information and KL divergence. We extend this information-theoretic analysis to over-parameterized models by characterizing the SGLD-based BIC for the random feature model in the regime where the number of parameters $p$ and the number of samples $n$ tend to infinity, with $p/n$ fixed. Our experiments demonstrate that the refined SGLD-based BIC can track the double-descent curve, providing meaningful guidance for model selection and revealing new insights into the behavior of SGLD learning algorithms in the over-parameterized regime.
Twofold Structured Features-Based Siamese Network for Infrared Target Tracking
Aug 31, 2023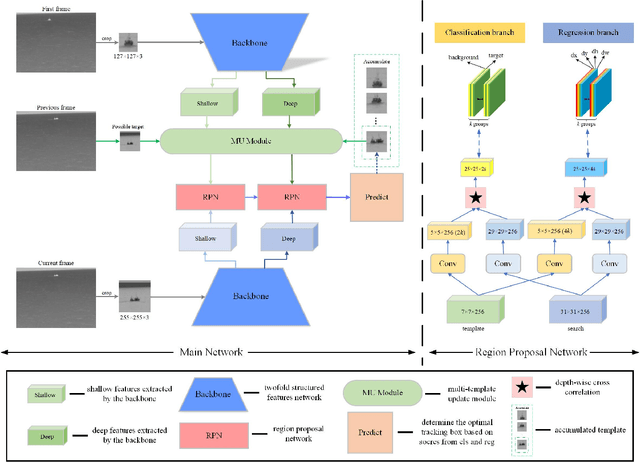
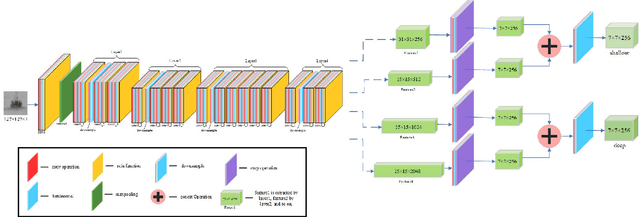

Nowadays, infrared target tracking has been a critical technology in the field of computer vision and has many applications, such as motion analysis, pedestrian surveillance, intelligent detection, and so forth. Unfortunately, due to the lack of color, texture and other detailed information, tracking drift often occurs when the tracker encounters infrared targets that vary in size or shape. To address this issue, we present a twofold structured features-based Siamese network for infrared target tracking. First of all, in order to improve the discriminative capacity for infrared targets, a novel feature fusion network is proposed to fuse both shallow spatial information and deep semantic information into the extracted features in a comprehensive manner. Then, a multi-template update module based on template update mechanism is designed to effectively deal with interferences from target appearance changes which are prone to cause early tracking failures. Finally, both qualitative and quantitative experiments are carried out on VOT-TIR 2016 dataset, which demonstrates that our method achieves the balance of promising tracking performance and real-time tracking speed against other out-of-the-art trackers.
PRISTA-Net: Deep Iterative Shrinkage Thresholding Network for Coded Diffraction Patterns Phase Retrieval
Sep 08, 2023


The problem of phase retrieval (PR) involves recovering an unknown image from limited amplitude measurement data and is a challenge nonlinear inverse problem in computational imaging and image processing. However, many of the PR methods are based on black-box network models that lack interpretability and plug-and-play (PnP) frameworks that are computationally complex and require careful parameter tuning. To address this, we have developed PRISTA-Net, a deep unfolding network (DUN) based on the first-order iterative shrinkage thresholding algorithm (ISTA). This network utilizes a learnable nonlinear transformation to address the proximal-point mapping sub-problem associated with the sparse priors, and an attention mechanism to focus on phase information containing image edges, textures, and structures. Additionally, the fast Fourier transform (FFT) is used to learn global features to enhance local information, and the designed logarithmic-based loss function leads to significant improvements when the noise level is low. All parameters in the proposed PRISTA-Net framework, including the nonlinear transformation, threshold parameters, and step size, are learned end-to-end instead of being manually set. This method combines the interpretability of traditional methods with the fast inference ability of deep learning and is able to handle noise at each iteration during the unfolding stage, thus improving recovery quality. Experiments on Coded Diffraction Patterns (CDPs) measurements demonstrate that our approach outperforms the existing state-of-the-art methods in terms of qualitative and quantitative evaluations. Our source codes are available at \emph{https://github.com/liuaxou/PRISTA-Net}.