 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating Hierarchical Structures for Improved Time Series Classification Using Stochastic Splitting Functions
Sep 21, 2023
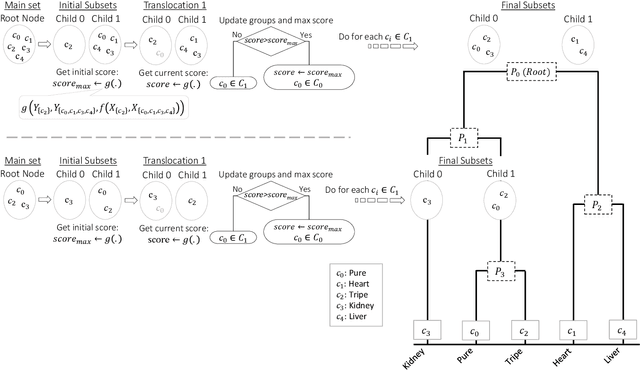

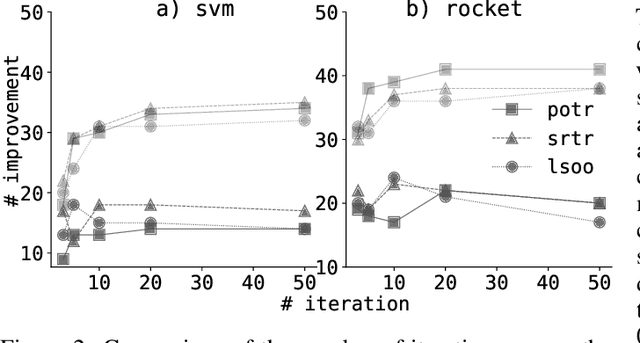
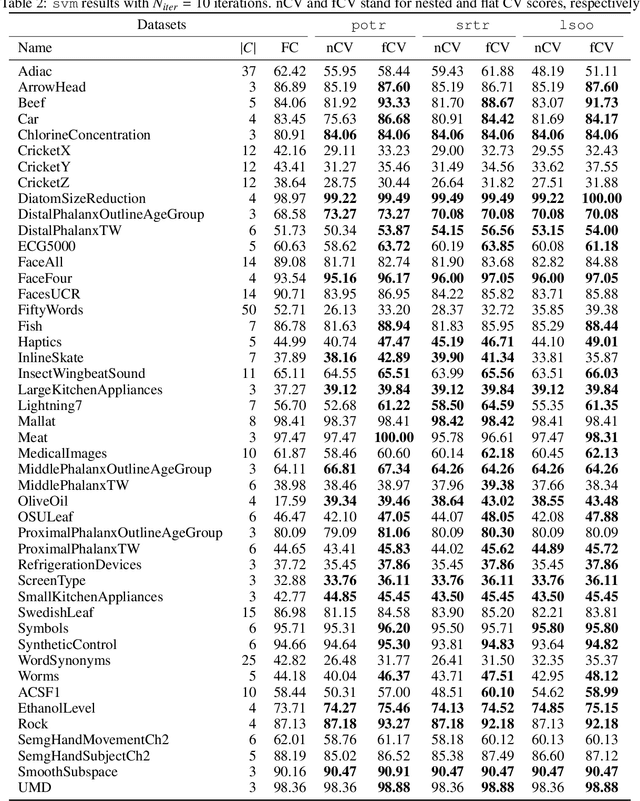
This study introduces a novel hierarchical divisive clustering approach with stochastic splitting functions (SSFs) to enhance classification performance in multi-class datasets through hierarchical classification (HC). The method has the unique capability of generating hierarchy without requiring explicit information, making it suitable for datasets lacking prior knowledge of hierarchy. By systematically dividing classes into two subsets based on their discriminability according to the classifier, the proposed approach constructs a binary tree representation of hierarchical classes. The approach is evaluated on 46 multi-class time series datasets using popular classifiers (svm and rocket) and SSFs (potr, srtr, and lsoo). The results reveal that the approach significantly improves classification performance in approximately half and a third of the datasets when using rocket and svm as the classifier, respectively. The study also explores the relationship between dataset features and HC performance. While the number of classes and flat classification (FC) score show consistent significance, variations are observed with different splitting functions. Overall, the proposed approach presents a promising strategy for enhancing classification by generating hierarchical structure in multi-class time series datasets. Future research directions involve exploring different splitting functions, classifiers, and hierarchy structures, as well as applying the approach to diverse domains beyond time series data. The source code is made openly available to facilitate reproducibility and further exploration of the method.
TCOVIS: Temporally Consistent Online Video Instance Segmentation
Sep 21, 2023
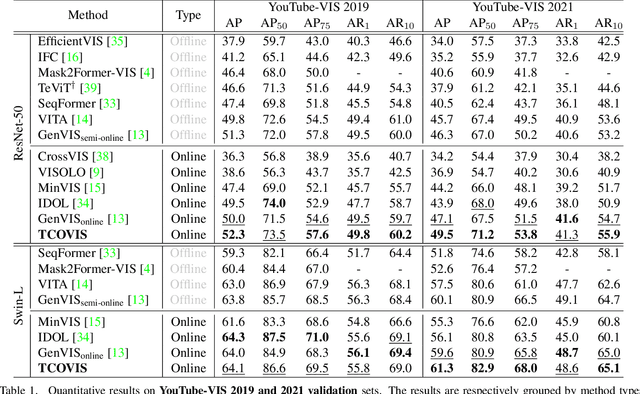
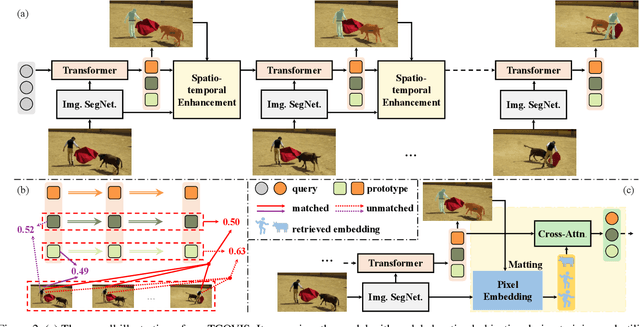
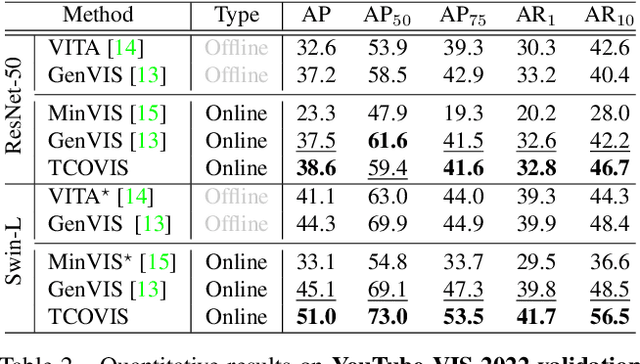
In recent years, significant progress has been made in video instance segmentation (VIS), with many offline and online methods achieving state-of-the-art performance. While offline methods have the advantage of producing temporally consistent predictions, they are not suitable for real-time scenarios. Conversely, online methods are more practical, but maintaining temporal consistency remains a challenging task. In this paper, we propose a novel online method for video instance segmentation, called TCOVIS, which fully exploits the temporal information in a video clip. The core of our method consists of a global instance assignment strategy and a spatio-temporal enhancement module, which improve the temporal consistency of the features from two aspects. Specifically, we perform global optimal matching between the predictions and ground truth across the whole video clip, and supervise the model with the global optimal objective. We also capture the spatial feature and aggregate it with the semantic feature between frames, thus realizing the spatio-temporal enhancement. We evaluate our method on four widely adopted VIS benchmarks, namely YouTube-VIS 2019/2021/2022 and OVIS, and achieve state-of-the-art performance on all benchmarks without bells-and-whistles. For instance, on YouTube-VIS 2021, TCOVIS achieves 49.5 AP and 61.3 AP with ResNet-50 and Swin-L backbones, respectively. Code is available at https://github.com/jun-long-li/TCOVIS.
Clustering-based Domain-Incremental Learning
Sep 21, 2023We consider the problem of learning multiple tasks in a continual learning setting in which data from different tasks is presented to the learner in a streaming fashion. A key challenge in this setting is the so-called "catastrophic forgetting problem", in which the performance of the learner in an "old task" decreases when subsequently trained on a "new task". Existing continual learning methods, such as Averaged Gradient Episodic Memory (A-GEM) and Orthogonal Gradient Descent (OGD), address catastrophic forgetting by minimizing the loss for the current task without increasing the loss for previous tasks. However, these methods assume the learner knows when the task changes, which is unrealistic in practice. In this paper, we alleviate the need to provide the algorithm with information about task changes by using an online clustering-based approach on a dynamically updated finite pool of samples or gradients. We thereby successfully counteract catastrophic forgetting in one of the hardest settings, namely: domain-incremental learning, a setting for which the problem was previously unsolved. We showcase the benefits of our approach by applying these ideas to projection-based methods, such as A-GEM and OGD, which lead to task-agnostic versions of them. Experiments on real datasets demonstrate the effectiveness of the proposed strategy and its promising performance compared to state-of-the-art methods.
JobRecoGPT -- Explainable job recommendations using LLMs
Sep 21, 2023In today's rapidly evolving job market, finding the right opportunity can be a daunting challenge. With advancements in the field of AI, computers can now recommend suitable jobs to candidates. However, the task of recommending jobs is not same as recommending movies to viewers. Apart from must-have criteria, like skills and experience, there are many subtle aspects to a job which can decide if it is a good fit or not for a given candidate. Traditional approaches can capture the quantifiable aspects of jobs and candidates, but a substantial portion of the data that is present in unstructured form in the job descriptions and resumes is lost in the process of conversion to structured format. As of late, Large Language Models (LLMs) have taken over the AI field by storm with extraordinary performance in fields where text-based data is available. Inspired by the superior performance of LLMs, we leverage their capability to understand natural language for capturing the information that was previously getting lost during the conversion of unstructured data to structured form. To this end, we compare performance of four different approaches for job recommendations namely, (i) Content based deterministic, (ii) LLM guided, (iii) LLM unguided, and (iv) Hybrid. In this study, we present advantages and limitations of each method and evaluate their performance in terms of time requirements.
Beyond expectations: Residual Dynamic Mode Decomposition and Variance for Stochastic Dynamical Systems
Sep 09, 2023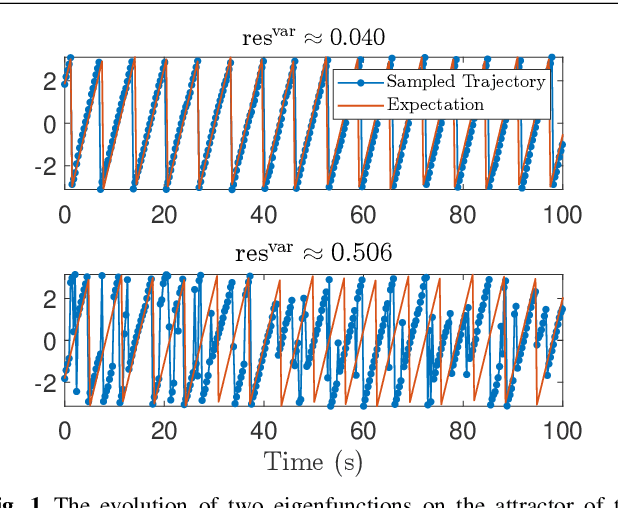
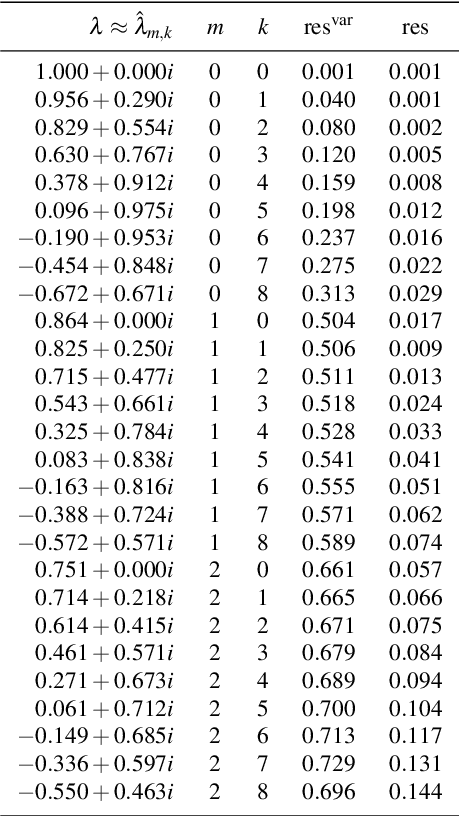
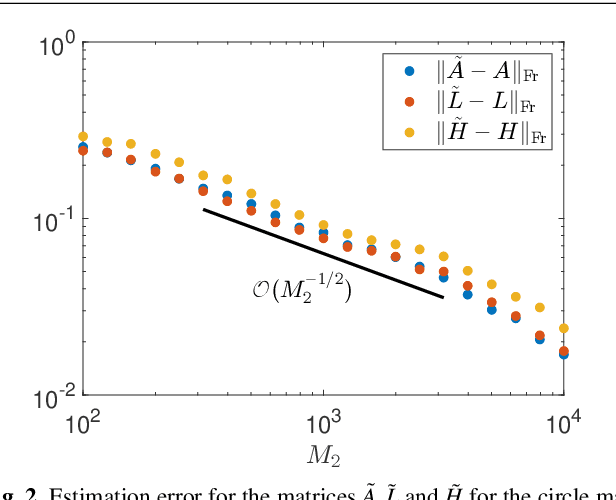
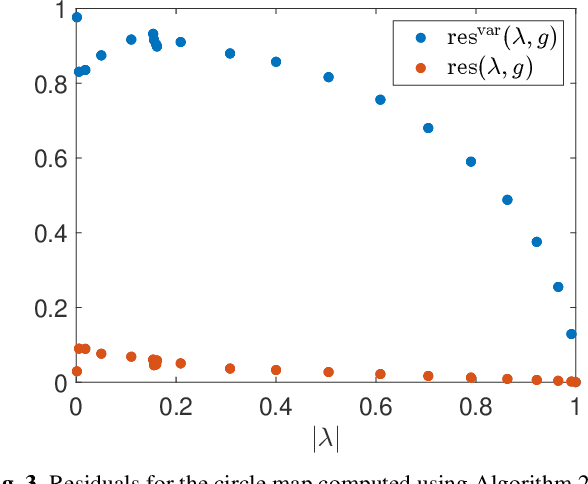
Koopman operators linearize nonlinear dynamical systems, making their spectral information of crucial interest. Numerous algorithms have been developed to approximate these spectral properties, and Dynamic Mode Decomposition (DMD) stands out as the poster child of projection-based methods. Although the Koopman operator itself is linear, the fact that it acts in an infinite-dimensional space of observables poses challenges. These include spurious modes, essential spectra, and the verification of Koopman mode decompositions. While recent work has addressed these challenges for deterministic systems, there remains a notable gap in verified DMD methods for stochastic systems, where the Koopman operator measures the expectation of observables. We show that it is necessary to go beyond expectations to address these issues. By incorporating variance into the Koopman framework, we address these challenges. Through an additional DMD-type matrix, we approximate the sum of a squared residual and a variance term, each of which can be approximated individually using batched snapshot data. This allows verified computation of the spectral properties of stochastic Koopman operators, controlling the projection error. We also introduce the concept of variance-pseudospectra to gauge statistical coherency. Finally, we present a suite of convergence results for the spectral information of stochastic Koopman operators. Our study concludes with practical applications using both simulated and experimental data. In neural recordings from awake mice, we demonstrate how variance-pseudospectra can reveal physiologically significant information unavailable to standard expectation-based dynamical models.
FrameRS: A Video Frame Compression Model Composed by Self supervised Video Frame Reconstructor and Key Frame Selector
Sep 16, 2023
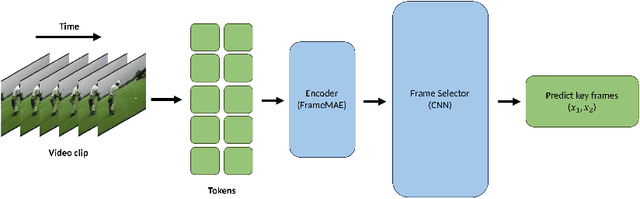

In this paper, we present frame reconstruction model: FrameRS. It consists self-supervised video frame reconstructor and key frame selector. The frame reconstructor, FrameMAE, is developed by adapting the principles of the Masked Autoencoder for Images (MAE) for video context. The key frame selector, Frame Selector, is built on CNN architecture. By taking the high-level semantic information from the encoder of FrameMAE as its input, it can predicted the key frames with low computation costs. Integrated with our bespoke Frame Selector, FrameMAE can effectively compress a video clip by retaining approximately 30% of its pivotal frames. Performance-wise, our model showcases computational efficiency and competitive accuracy, marking a notable improvement over traditional Key Frame Extract algorithms. The implementation is available on Github
An Automatic Tuning MPC with Application to Ecological Cruise Control
Sep 17, 2023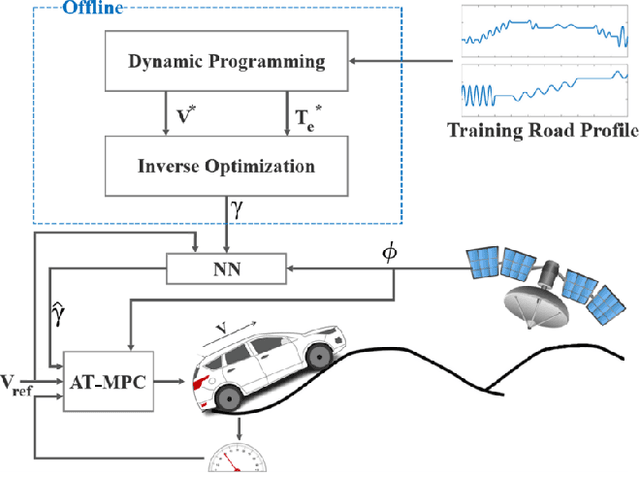
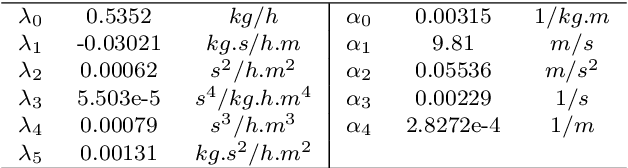

Model predictive control (MPC) is a powerful tool for planning and controlling dynamical systems due to its capacity for handling constraints and taking advantage of preview information. Nevertheless, MPC performance is highly dependent on the choice of cost function tuning parameters. In this work, we demonstrate an approach for online automatic tuning of an MPC controller with an example application to an ecological cruise control system that saves fuel by using a preview of road grade. We solve the global fuel consumption minimization problem offline using dynamic programming and find the corresponding MPC cost function by solving the inverse optimization problem. A neural network fitted to these offline results is used to generate the desired MPC cost function weight during online operation. The effectiveness of the proposed approach is verified in simulation for different road geometries.
CR-VAE: Contrastive Regularization on Variational Autoencoders for Preventing Posterior Collapse
Sep 09, 2023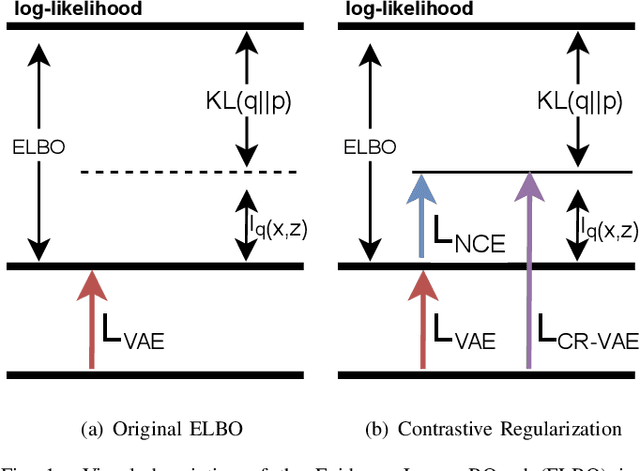
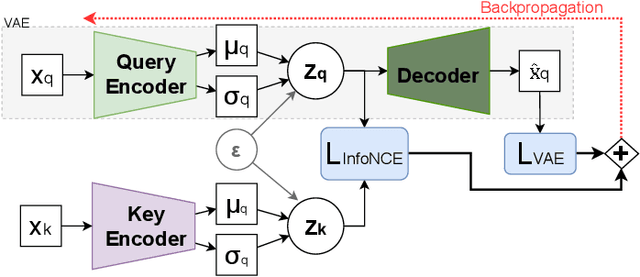
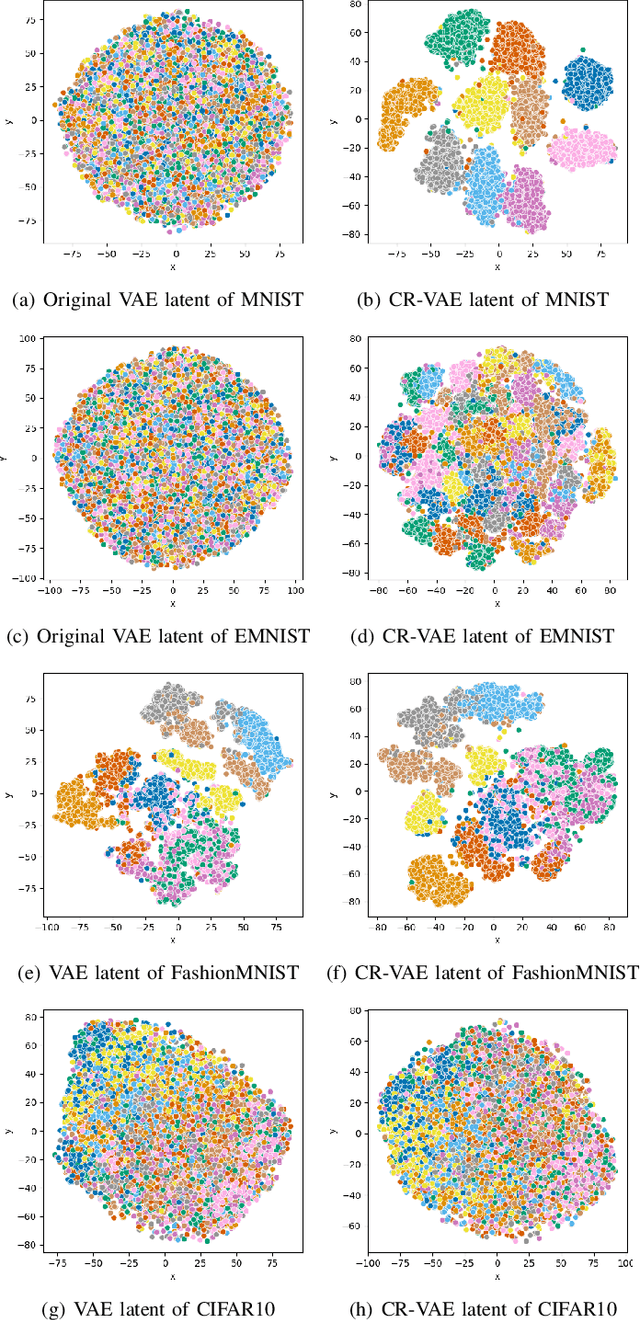
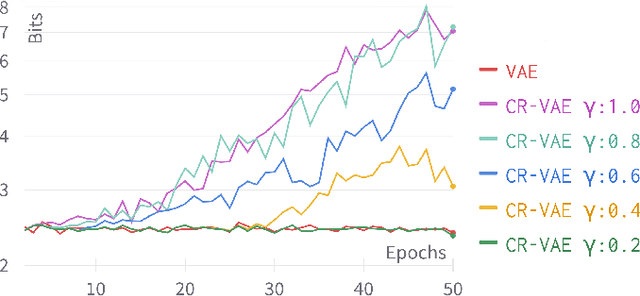
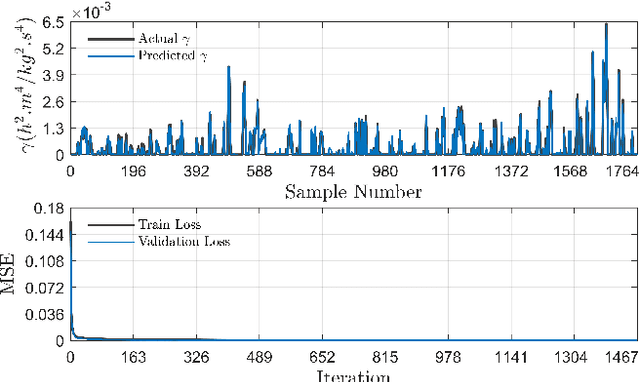
The Variational Autoencoder (VAE) is known to suffer from the phenomenon of \textit{posterior collapse}, where the latent representations generated by the model become independent of the inputs. This leads to degenerated representations of the input, which is attributed to the limitations of the VAE's objective function. In this work, we propose a novel solution to this issue, the Contrastive Regularization for Variational Autoencoders (CR-VAE). The core of our approach is to augment the original VAE with a contrastive objective that maximizes the mutual information between the representations of similar visual inputs. This strategy ensures that the information flow between the input and its latent representation is maximized, effectively avoiding posterior collapse. We evaluate our method on a series of visual datasets and demonstrate, that CR-VAE outperforms state-of-the-art approaches in preventing posterior collapse.
SememeASR: Boosting Performance of End-to-End Speech Recognition against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
Sep 04, 2023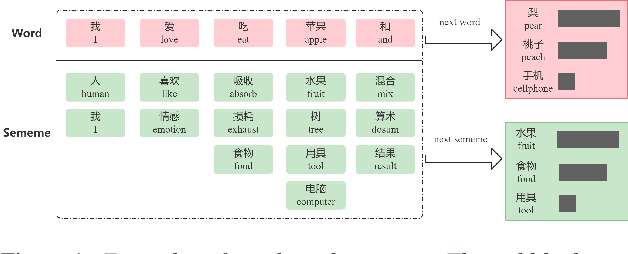
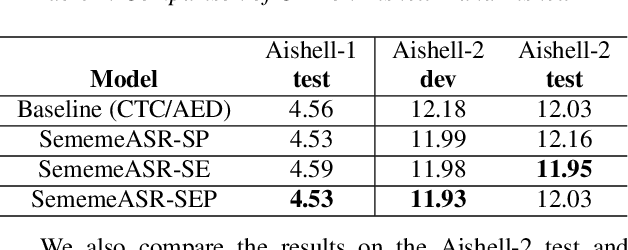
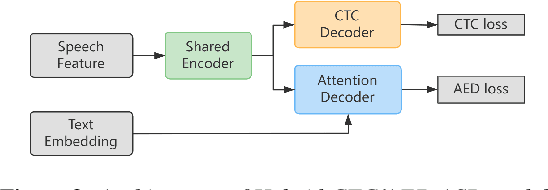
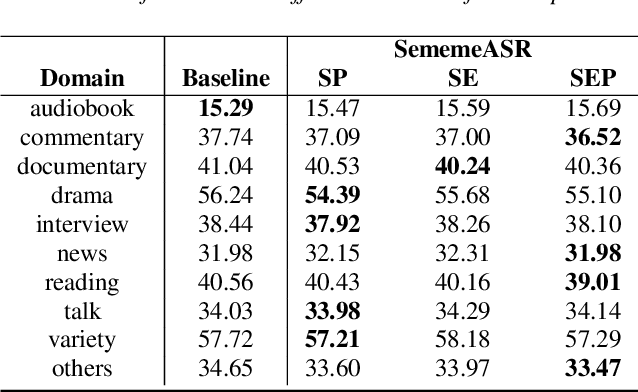
Recently, excellent progress has been made in speech recognition. However, pure data-driven approaches have struggled to solve the problem in domain-mismatch and long-tailed data. Considering that knowledge-driven approaches can help data-driven approaches alleviate their flaws, we introduce sememe-based semantic knowledge information to speech recognition (SememeASR). Sememe, according to the linguistic definition, is the minimum semantic unit in a language and is able to represent the implicit semantic information behind each word very well. Our experiments show that the introduction of sememe information can improve the effectiveness of speech recognition. In addition, our further experiments show that sememe knowledge can improve the model's recognition of long-tailed data and enhance the model's domain generalization ability.
Filtration Surfaces for Dynamic Graph Classification
Sep 07, 2023Existing approaches for classifying dynamic graphs either lift graph kernels to the temporal domain, or use graph neural networks (GNNs). However, current baselines have scalability issues, cannot handle a changing node set, or do not take edge weight information into account. We propose filtration surfaces, a novel method that is scalable and flexible, to alleviate said restrictions. We experimentally validate the efficacy of our model and show that filtration surfaces outperform previous state-of-the-art baselines on datasets that rely on edge weight information. Our method does so while being either completely parameter-free or having at most one parameter, and yielding the lowest overall standard deviation.