 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Consistent Deep Unfolding Network for Adaptive All-In-One Video Restoration
Sep 07, 2023
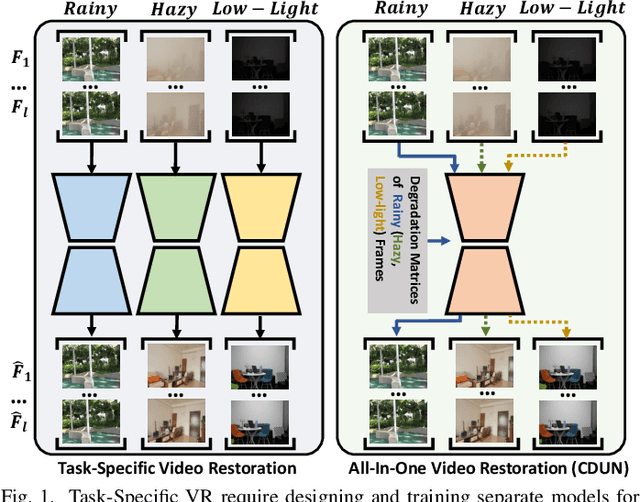

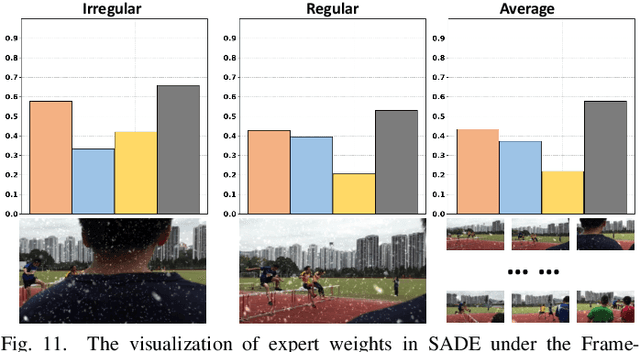
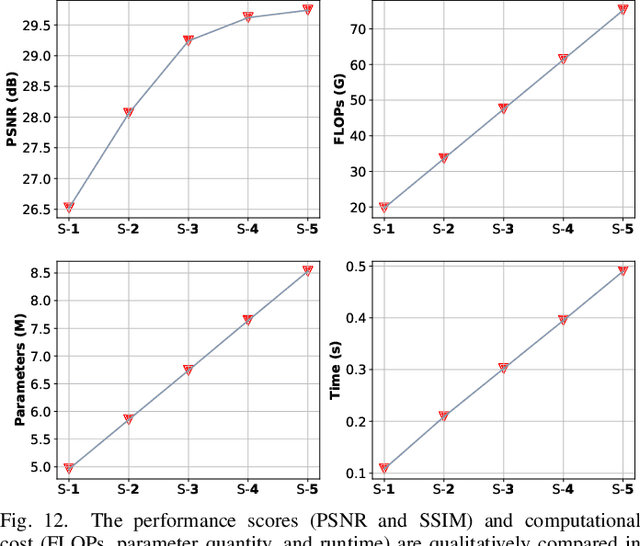
Existing Video Restoration (VR) methods always necessitate the individual deployment of models for each adverse weather to remove diverse adverse weather degradations, lacking the capability for adaptive processing of degradations. Such limitation amplifies the complexity and deployment costs in practical applications. To overcome this deficiency, in this paper, we propose a Cross-consistent Deep Unfolding Network (CDUN) for All-In-One VR, which enables the employment of a single model to remove diverse degradations for the first time. Specifically, the proposed CDUN accomplishes a novel iterative optimization framework, capable of restoring frames corrupted by corresponding degradations according to the degradation features given in advance. To empower the framework for eliminating diverse degradations, we devise a Sequence-wise Adaptive Degradation Estimator (SADE) to estimate degradation features for the input corrupted video. By orchestrating these two cascading procedures, CDUN achieves adaptive processing for diverse degradation. In addition, we introduce a window-based inter-frame fusion strategy to utilize information from more adjacent frames. This strategy involves the progressive stacking of temporal windows in multiple iterations, effectively enlarging the temporal receptive field and enabling each frame's restoration to leverage information from distant frames. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance in All-In-One VR.
One-shot lip-based biometric authentication: extending behavioral features with authentication phrase information
Aug 14, 2023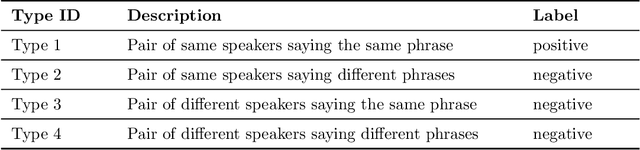



Lip-based biometric authentication (LBBA) is an authentication method based on a person's lip movements during speech in the form of video data captured by a camera sensor. LBBA can utilize both physical and behavioral characteristics of lip movements without requiring any additional sensory equipment apart from an RGB camera. State-of-the-art (SOTA) approaches use one-shot learning to train deep siamese neural networks which produce an embedding vector out of these features. Embeddings are further used to compute the similarity between an enrolled user and a user being authenticated. A flaw of these approaches is that they model behavioral features as style-of-speech without relation to what is being said. This makes the system vulnerable to video replay attacks of the client speaking any phrase. To solve this problem we propose a one-shot approach which models behavioral features to discriminate against what is being said in addition to style-of-speech. We achieve this by customizing the GRID dataset to obtain required triplets and training a siamese neural network based on 3D convolutions and recurrent neural network layers. A custom triplet loss for batch-wise hard-negative mining is proposed. Obtained results using an open-set protocol are 3.2% FAR and 3.8% FRR on the test set of the customized GRID dataset. Additional analysis of the results was done to quantify the influence and discriminatory power of behavioral and physical features for LBBA.
Towards Practical and Efficient Image-to-Speech Captioning with Vision-Language Pre-training and Multi-modal Tokens
Sep 15, 2023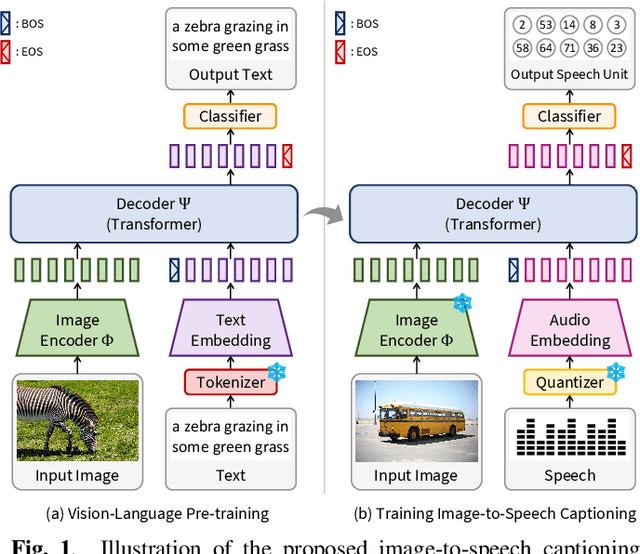

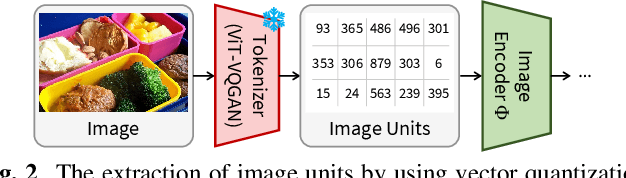

In this paper, we propose methods to build a powerful and efficient Image-to-Speech captioning (Im2Sp) model. To this end, we start with importing the rich knowledge related to image comprehension and language modeling from a large-scale pre-trained vision-language model into Im2Sp. We set the output of the proposed Im2Sp as discretized speech units, i.e., the quantized speech features of a self-supervised speech model. The speech units mainly contain linguistic information while suppressing other characteristics of speech. This allows us to incorporate the language modeling capability of the pre-trained vision-language model into the spoken language modeling of Im2Sp. With the vision-language pre-training strategy, we set new state-of-the-art Im2Sp performances on two widely used benchmark databases, COCO and Flickr8k. Then, we further improve the efficiency of the Im2Sp model. Similar to the speech unit case, we convert the original image into image units, which are derived through vector quantization of the raw image. With these image units, we can drastically reduce the required data storage for saving image data to just 0.8% when compared to the original image data in terms of bits. Demo page: https://ms-dot-k.github.io/Image-to-Speech-Captioning.
XFedHunter: An Explainable Federated Learning Framework for Advanced Persistent Threat Detection in SDN
Sep 15, 2023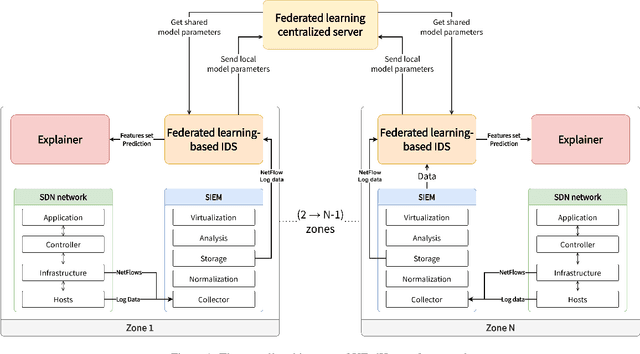
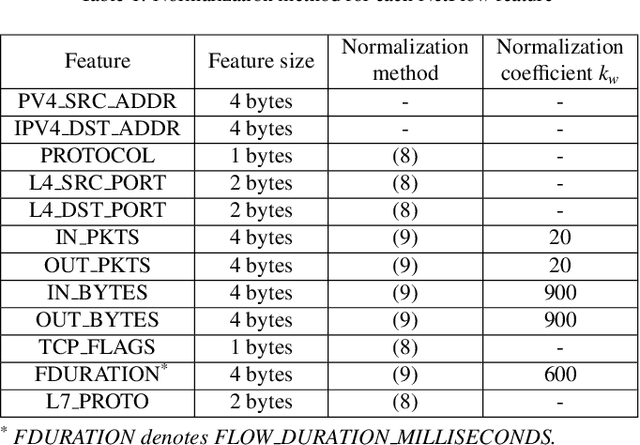
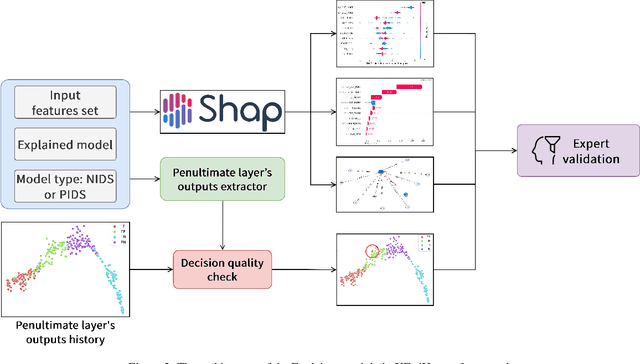
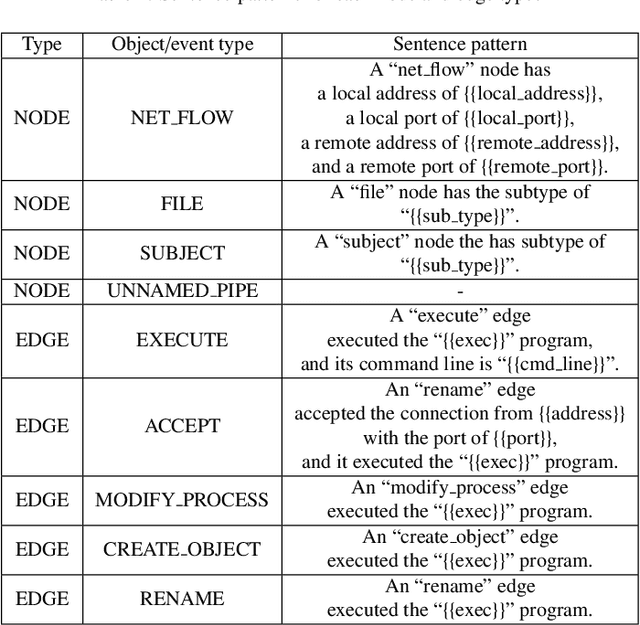
Advanced Persistent Threat (APT) attacks are highly sophisticated and employ a multitude of advanced methods and techniques to target organizations and steal sensitive and confidential information. APT attacks consist of multiple stages and have a defined strategy, utilizing new and innovative techniques and technologies developed by hackers to evade security software monitoring. To effectively protect against APTs, detecting and predicting APT indicators with an explanation from Machine Learning (ML) prediction is crucial to reveal the characteristics of attackers lurking in the network system. Meanwhile, Federated Learning (FL) has emerged as a promising approach for building intelligent applications without compromising privacy. This is particularly important in cybersecurity, where sensitive data and high-quality labeling play a critical role in constructing effective machine learning models for detecting cyber threats. Therefore, this work proposes XFedHunter, an explainable federated learning framework for APT detection in Software-Defined Networking (SDN) leveraging local cyber threat knowledge from many training collaborators. In XFedHunter, Graph Neural Network (GNN) and Deep Learning model are utilized to reveal the malicious events effectively in the large number of normal ones in the network system. The experimental results on NF-ToN-IoT and DARPA TCE3 datasets indicate that our framework can enhance the trust and accountability of ML-based systems utilized for cybersecurity purposes without privacy leakage.
A Ground Segmentation Method Based on Point Cloud Map for Unstructured Roads
Sep 15, 2023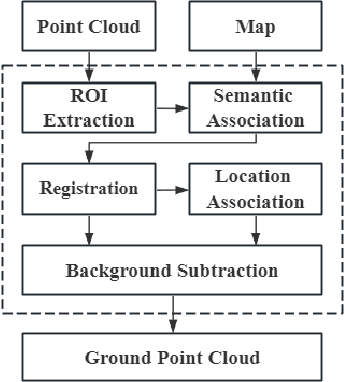
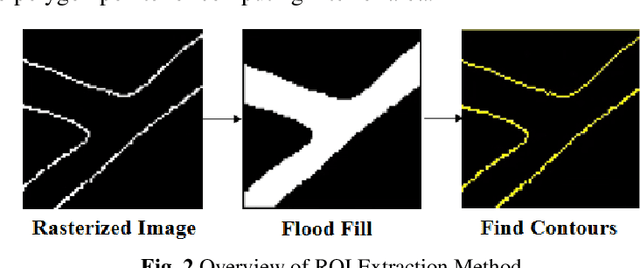
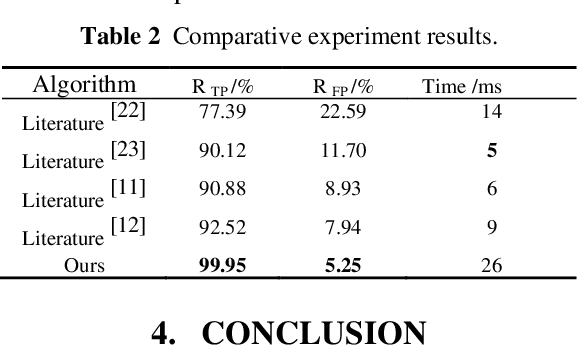

Ground segmentation, as the basic task of unmanned intelligent perception, provides an important support for the target detection task. Unstructured road scenes represented by open-pit mines have irregular boundary lines and uneven road surfaces, which lead to segmentation errors in current ground segmentation methods. To solve this problem, a ground segmentation method based on point cloud map is proposed, which involves three parts: region of interest extraction, point cloud registration and background subtraction. Firstly, establishing boundary semantic associations to obtain regions of interest in unstructured roads. Secondly, establishing the location association between point cloud map and the real-time point cloud of region of interest by semantics information. Thirdly, establishing a background model based on Gaussian distribution according to location association, and segments the ground in real-time point cloud by the background substraction method. Experimental results show that the correct segmentation rate of ground points is 99.95%, and the running time is 26ms. Compared with state of the art ground segmentation algorithm Patchwork++, the average accuracy of ground point segmentation is increased by 7.43%, and the running time is increased by 17ms. Furthermore, the proposed method is practically applied to unstructured road scenarios represented by open pit mines.
Personalized Food Image Classification: Benchmark Datasets and New Baseline
Sep 15, 2023Food image classification is a fundamental step of image-based dietary assessment, enabling automated nutrient analysis from food images. Many current methods employ deep neural networks to train on generic food image datasets that do not reflect the dynamism of real-life food consumption patterns, in which food images appear sequentially over time, reflecting the progression of what an individual consumes. Personalized food classification aims to address this problem by training a deep neural network using food images that reflect the consumption pattern of each individual. However, this problem is under-explored and there is a lack of benchmark datasets with individualized food consumption patterns due to the difficulty in data collection. In this work, we first introduce two benchmark personalized datasets including the Food101-Personal, which is created based on surveys of daily dietary patterns from participants in the real world, and the VFNPersonal, which is developed based on a dietary study. In addition, we propose a new framework for personalized food image classification by leveraging self-supervised learning and temporal image feature information. Our method is evaluated on both benchmark datasets and shows improved performance compared to existing works. The dataset has been made available at: https://skynet.ecn.purdue.edu/~pan161/dataset_personal.html
Pseudo-Labeling Enhanced by Privileged Information and Its Application to In Situ Sequencing Images
Jun 28, 2023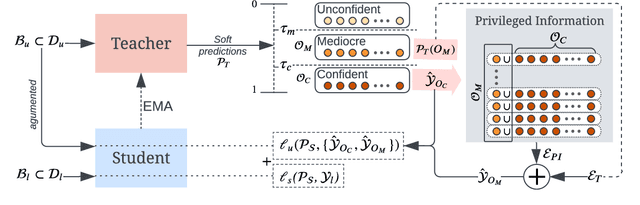
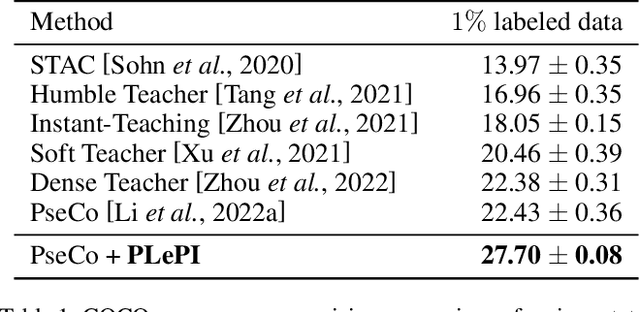
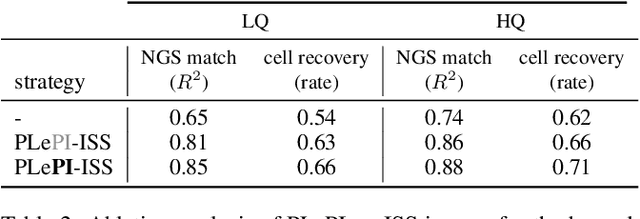

Various strategies for label-scarce object detection have been explored by the computer vision research community. These strategies mainly rely on assumptions that are specific to natural images and not directly applicable to the biological and biomedical vision domains. For example, most semi-supervised learning strategies rely on a small set of labeled data as a confident source of ground truth. In many biological vision applications, however, the ground truth is unknown and indirect information might be available in the form of noisy estimations or orthogonal evidence. In this work, we frame a crucial problem in spatial transcriptomics - decoding barcodes from In-Situ-Sequencing (ISS) images - as a semi-supervised object detection (SSOD) problem. Our proposed framework incorporates additional available sources of information into a semi-supervised learning framework in the form of privileged information. The privileged information is incorporated into the teacher's pseudo-labeling in a teacher-student self-training iteration. Although the available privileged information could be data domain specific, we have introduced a general strategy of pseudo-labeling enhanced by privileged information (PLePI) and exemplified the concept using ISS images, as well on the COCO benchmark using extra evidence provided by CLIP.
* This paper has been accepted for publication at IJCAI 2023
Co-evolving Vector Quantization for ID-based Recommendation
Aug 31, 2023Category information plays a crucial role in enhancing the quality and personalization of recommendations. Nevertheless, the availability of item category information is not consistently present, particularly in the context of ID-based recommendations. In this work, we propose an alternative approach to automatically learn and generate entity (i.e., user and item) categorical information at different levels of granularity, specifically for ID-based recommendation. Specifically, we devise a co-evolving vector quantization framework, namely COVE, which enables the simultaneous learning and refinement of code representation and entity embedding in an end-to-end manner, starting from the randomly initialized states. With its high adaptability, COVE can be easily integrated into existing recommendation models. We validate the effectiveness of COVE on various recommendation tasks including list completion, collaborative filtering, and click-through rate prediction, across different recommendation models. We will publish the code and data for other researchers to reproduce our work.
Deep Unfolding Convolutional Dictionary Model for Multi-Contrast MRI Super-resolution and Reconstruction
Sep 03, 2023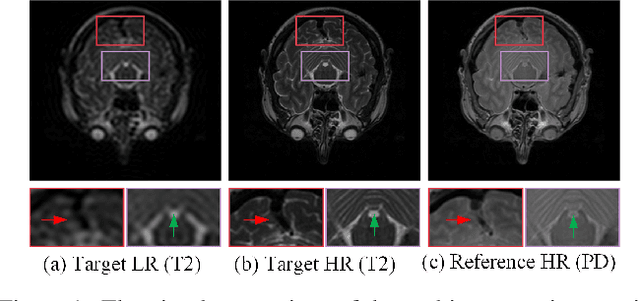
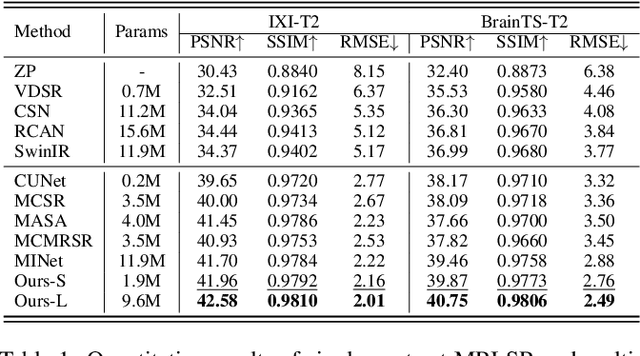
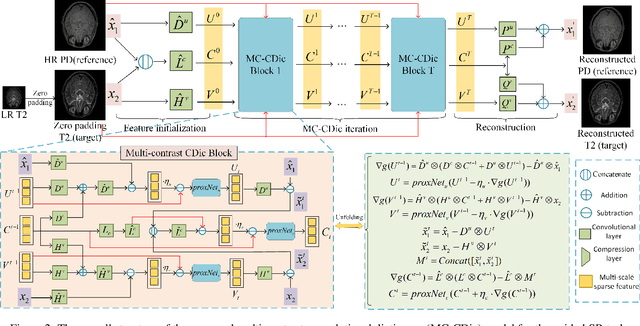
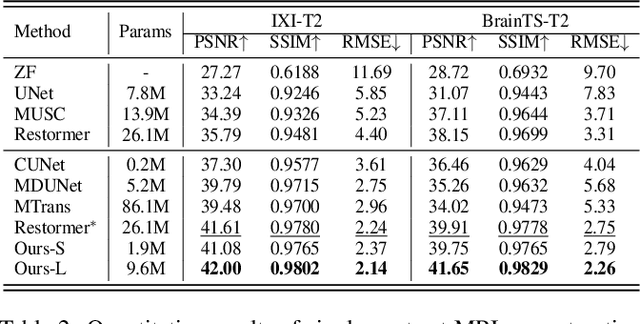
Magnetic resonance imaging (MRI) tasks often involve multiple contrasts. Recently, numerous deep learning-based multi-contrast MRI super-resolution (SR) and reconstruction methods have been proposed to explore the complementary information from the multi-contrast images. However, these methods either construct parameter-sharing networks or manually design fusion rules, failing to accurately model the correlations between multi-contrast images and lacking certain interpretations. In this paper, we propose a multi-contrast convolutional dictionary (MC-CDic) model under the guidance of the optimization algorithm with a well-designed data fidelity term. Specifically, we bulid an observation model for the multi-contrast MR images to explicitly model the multi-contrast images as common features and unique features. In this way, only the useful information in the reference image can be transferred to the target image, while the inconsistent information will be ignored. We employ the proximal gradient algorithm to optimize the model and unroll the iterative steps into a deep CDic model. Especially, the proximal operators are replaced by learnable ResNet. In addition, multi-scale dictionaries are introduced to further improve the model performance. We test our MC-CDic model on multi-contrast MRI SR and reconstruction tasks. Experimental results demonstrate the superior performance of the proposed MC-CDic model against existing SOTA methods. Code is available at https://github.com/lpcccc-cv/MC-CDic.
Pre-trained Neural Recommenders: A Transferable Zero-Shot Framework for Recommendation Systems
Sep 03, 2023Modern neural collaborative filtering techniques are critical to the success of e-commerce, social media, and content-sharing platforms. However, despite technical advances -- for every new application domain, we need to train an NCF model from scratch. In contrast, pre-trained vision and language models are routinely applied to diverse applications directly (zero-shot) or with limited fine-tuning. Inspired by the impact of pre-trained models, we explore the possibility of pre-trained recommender models that support building recommender systems in new domains, with minimal or no retraining, without the use of any auxiliary user or item information. Zero-shot recommendation without auxiliary information is challenging because we cannot form associations between users and items across datasets when there are no overlapping users or items. Our fundamental insight is that the statistical characteristics of the user-item interaction matrix are universally available across different domains and datasets. Thus, we use the statistical characteristics of the user-item interaction matrix to identify dataset-independent representations for users and items. We show how to learn universal (i.e., supporting zero-shot adaptation without user or item auxiliary information) representations for nodes and edges from the bipartite user-item interaction graph. We learn representations by exploiting the statistical properties of the interaction data, including user and item marginals, and the size and density distributions of their clusters.