 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Stochastic LLMs do not Understand Language: Towards Symbolic, Explainable and Ontologically Based LLMs
Sep 13, 2023
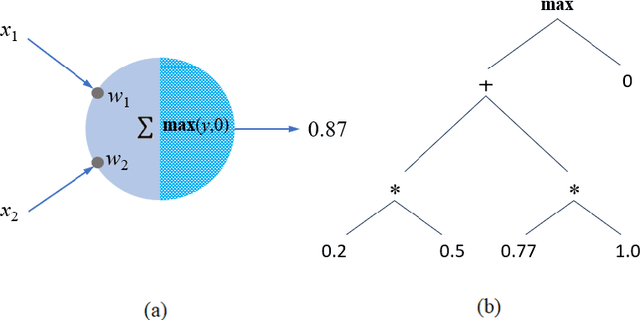
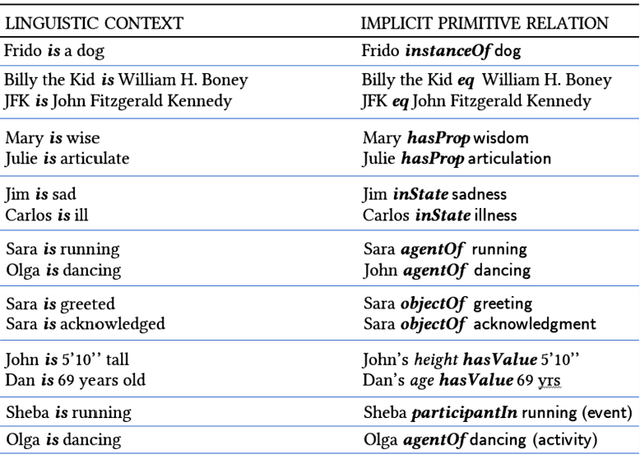


In our opinion the exuberance surrounding the relative success of data-driven large language models (LLMs) is slightly misguided and for several reasons (i) LLMs cannot be relied upon for factual information since for LLMs all ingested text (factual or non-factual) was created equal; (ii) due to their subsymbolic na-ture, whatever 'knowledge' these models acquire about language will always be buried in billions of microfeatures (weights), none of which is meaningful on its own; and (iii) LLMs will often fail to make the correct inferences in several linguistic contexts (e.g., nominal compounds, copredication, quantifier scope ambi-guities, intensional contexts. Since we believe the relative success of data-driven large language models (LLMs) is not a reflection on the symbolic vs. subsymbol-ic debate but a reflection on applying the successful strategy of a bottom-up reverse engineering of language at scale, we suggest in this paper applying the effective bottom-up strategy in a symbolic setting resulting in symbolic, explainable, and ontologically grounded language models.
A fixed-parameter tractable algorithm for combinatorial filter reduction
Sep 13, 2023What is the minimal information that a robot must retain to achieve its task? To design economical robots, the literature dealing with reduction of combinatorial filters approaches this problem algorithmically.As lossless state compression is NP-hard, prior work has examined, along with minimization algorithms, a variety of special cases in which specific properties enable efficient solution. Complementing those findings, this paper refines the present understanding from the perspective of parameterized complexity. We give a fixed-parameter tractable algorithm for the general reduction problem by exploiting a transformation into minimal clique covering. The transformation introduces new constraints that arise from sequential dependencies encoded within the input filter -- some of these constraints can be repaired, others are treated through enumeration. Through this approach, we identify parameters affecting filter reduction that are based upon inter-constraint couplings (expressed as a notion of their height and width), which add to the structural parameters present in the unconstrained problem of minimal clique covering.
Learning to Explore Indoor Environments using Autonomous Micro Aerial Vehicles
Sep 13, 2023
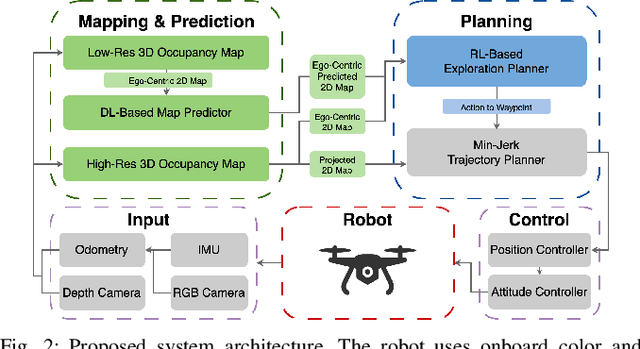
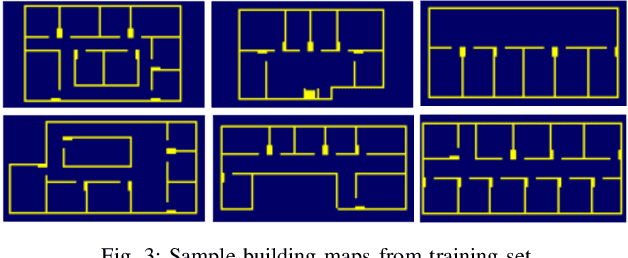
In this paper, we address the challenge of exploring unknown indoor aerial environments using autonomous aerial robots with Size Weight and Power (SWaP) constraints. The SWaP constraints induce limits on mission time requiring efficiency in exploration. We present a novel exploration framework that uses Deep Learning (DL) to predict the most likely indoor map given the previous observations, and Deep Reinforcement Learning (DRL) for exploration, designed to run on modern SWaP constraints neural processors. The DL-based map predictor provides a prediction of the occupancy of the unseen environment while the DRL-based planner determines the best navigation goals that can be safely reached to provide the most information. The two modules are tightly coupled and run onboard allowing the vehicle to safely map an unknown environment. Extensive experimental and simulation results show that our approach surpasses state-of-the-art methods by 50-60% in efficiency, which we measure by the fraction of the explored space as a function of the length of the trajectory traveled.
GCL: Gradient-Guided Contrastive Learning for Medical Image Segmentation with Multi-Perspective Meta Labels
Sep 16, 2023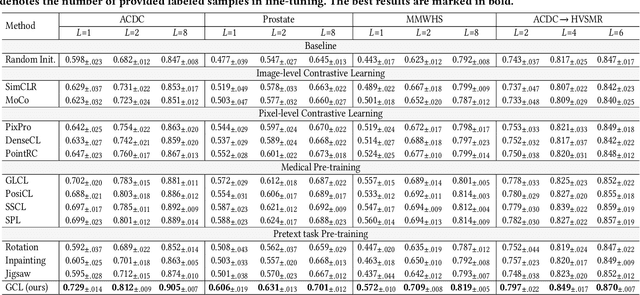
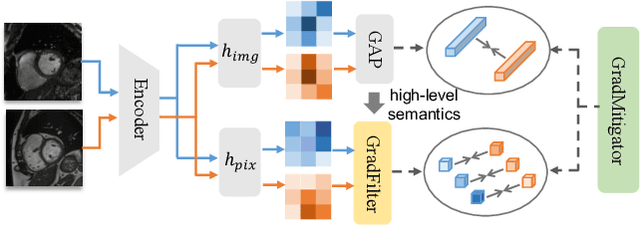
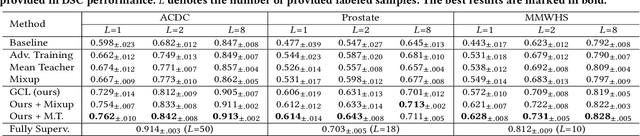
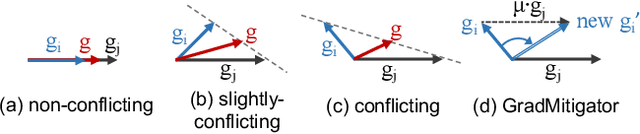
Since annotating medical images for segmentation tasks commonly incurs expensive costs, it is highly desirable to design an annotation-efficient method to alleviate the annotation burden. Recently, contrastive learning has exhibited a great potential in learning robust representations to boost downstream tasks with limited labels. In medical imaging scenarios, ready-made meta labels (i.e., specific attribute information of medical images) inherently reveal semantic relationships among images, which have been used to define positive pairs in previous work. However, the multi-perspective semantics revealed by various meta labels are usually incompatible and can incur intractable "semantic contradiction" when combining different meta labels. In this paper, we tackle the issue of "semantic contradiction" in a gradient-guided manner using our proposed Gradient Mitigator method, which systematically unifies multi-perspective meta labels to enable a pre-trained model to attain a better high-level semantic recognition ability. Moreover, we emphasize that the fine-grained discrimination ability is vital for segmentation-oriented pre-training, and develop a novel method called Gradient Filter to dynamically screen pixel pairs with the most discriminating power based on the magnitude of gradients. Comprehensive experiments on four medical image segmentation datasets verify that our new method GCL: (1) learns informative image representations and considerably boosts segmentation performance with limited labels, and (2) shows promising generalizability on out-of-distribution datasets.
AMLP:Adaptive Masking Lesion Patches for Self-supervised Medical Image Segmentation
Sep 08, 2023Self-supervised masked image modeling has shown promising results on natural images. However, directly applying such methods to medical images remains challenging. This difficulty stems from the complexity and distinct characteristics of lesions compared to natural images, which impedes effective representation learning. Additionally, conventional high fixed masking ratios restrict reconstructing fine lesion details, limiting the scope of learnable information. To tackle these limitations, we propose a novel self-supervised medical image segmentation framework, Adaptive Masking Lesion Patches (AMLP). Specifically, we design a Masked Patch Selection (MPS) strategy to identify and focus learning on patches containing lesions. Lesion regions are scarce yet critical, making their precise reconstruction vital. To reduce misclassification of lesion and background patches caused by unsupervised clustering in MPS, we introduce an Attention Reconstruction Loss (ARL) to focus on hard-to-reconstruct patches likely depicting lesions. We further propose a Category Consistency Loss (CCL) to refine patch categorization based on reconstruction difficulty, strengthening distinction between lesions and background. Moreover, we develop an Adaptive Masking Ratio (AMR) strategy that gradually increases the masking ratio to expand reconstructible information and improve learning. Extensive experiments on two medical segmentation datasets demonstrate AMLP's superior performance compared to existing self-supervised approaches. The proposed strategies effectively address limitations in applying masked modeling to medical images, tailored to capturing fine lesion details vital for segmentation tasks.
PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
Aug 31, 2023
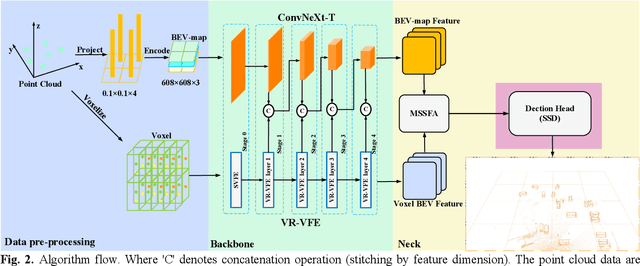
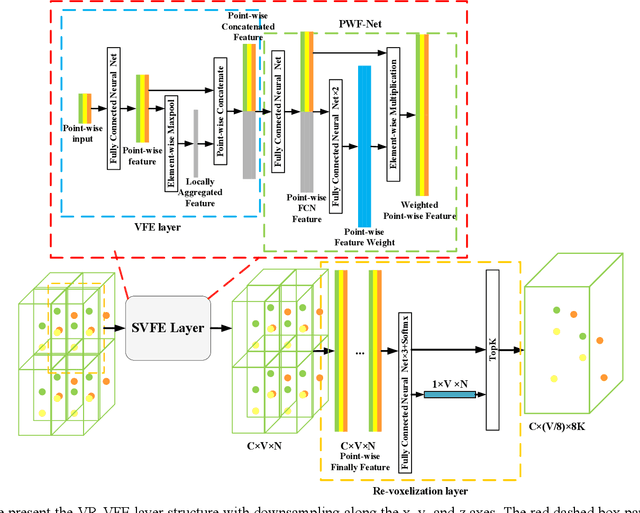
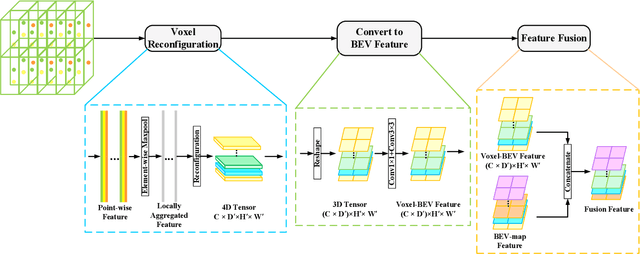
LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.
Efficient Multi-View Graph Clustering with Local and Global Structure Preservation
Aug 31, 2023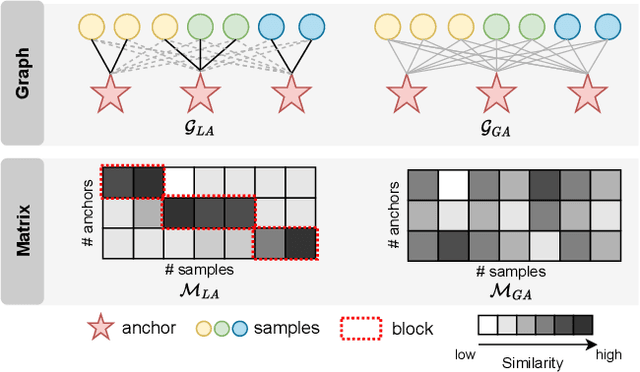
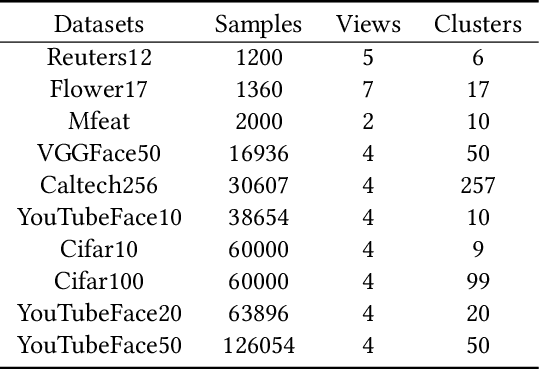
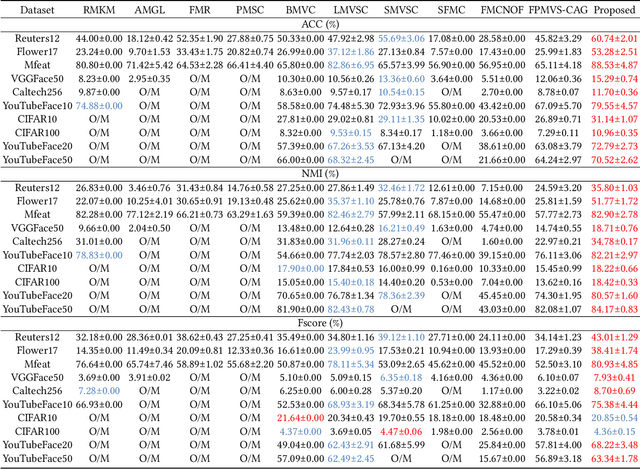
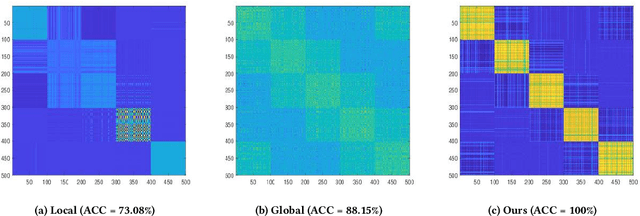
Anchor-based multi-view graph clustering (AMVGC) has received abundant attention owing to its high efficiency and the capability to capture complementary structural information across multiple views. Intuitively, a high-quality anchor graph plays an essential role in the success of AMVGC. However, the existing AMVGC methods only consider single-structure information, i.e., local or global structure, which provides insufficient information for the learning task. To be specific, the over-scattered global structure leads to learned anchors failing to depict the cluster partition well. In contrast, the local structure with an improper similarity measure results in potentially inaccurate anchor assignment, ultimately leading to sub-optimal clustering performance. To tackle the issue, we propose a novel anchor-based multi-view graph clustering framework termed Efficient Multi-View Graph Clustering with Local and Global Structure Preservation (EMVGC-LG). Specifically, a unified framework with a theoretical guarantee is designed to capture local and global information. Besides, EMVGC-LG jointly optimizes anchor construction and graph learning to enhance the clustering quality. In addition, EMVGC-LG inherits the linear complexity of existing AMVGC methods respecting the sample number, which is time-economical and scales well with the data size. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method.
Deep photonic reservoir computing recurrent network
Sep 11, 2023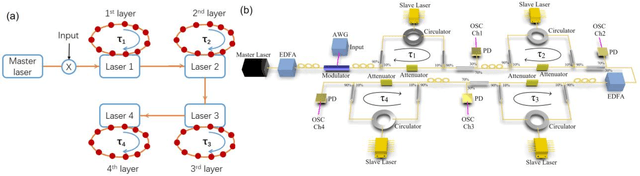
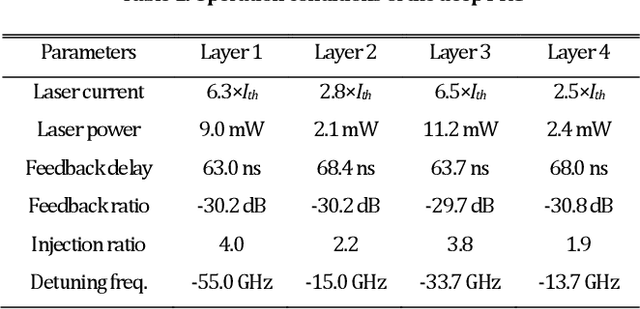
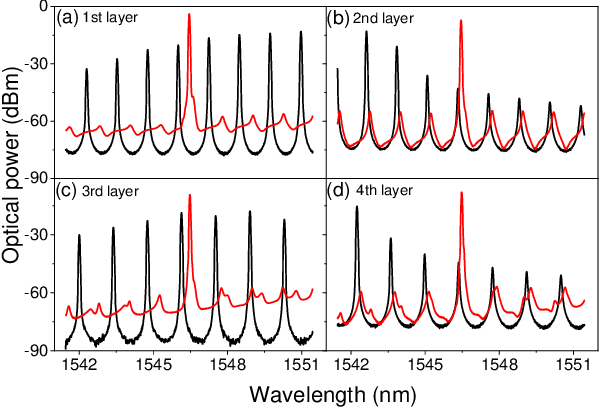
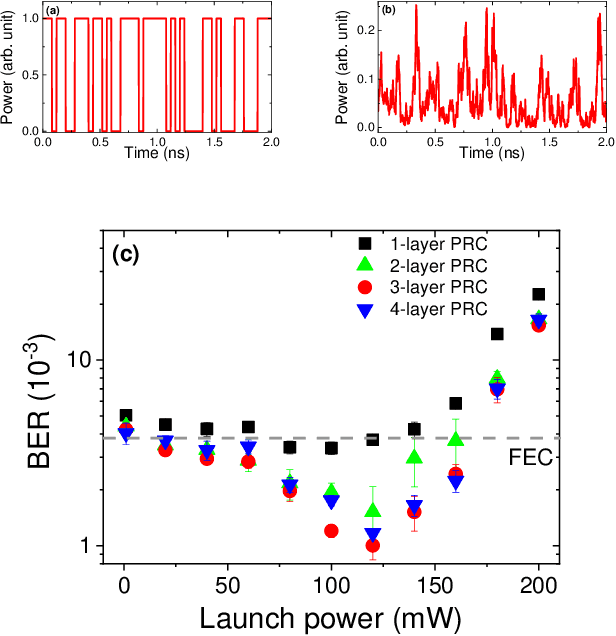
Deep neural networks usually process information through multiple hidden layers. However, most hardware reservoir computing recurrent networks only have one hidden reservoir layer, which significantly limits the capability of solving real-world complex tasks. Here we show a deep photonic reservoir computing (PRC) architecture, which is constructed by cascading injection-locked semiconductor lasers. In particular, the connection between successive hidden layers is all optical, without any optical-electrical conversion or analog-digital conversion. The proof of concept is demonstrated on a PRC consisting of 4 hidden layers and 320 interconnected neurons. In addition, we apply the deep PRC in the real-world signal equalization of an optical fiber communication system. It is found that the deep PRC owns strong ability to compensate the nonlinearity of fibers.
Distribution-Aligned Diffusion for Human Mesh Recovery
Sep 11, 2023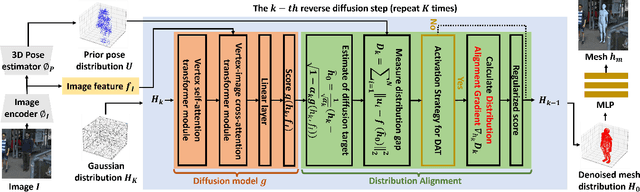
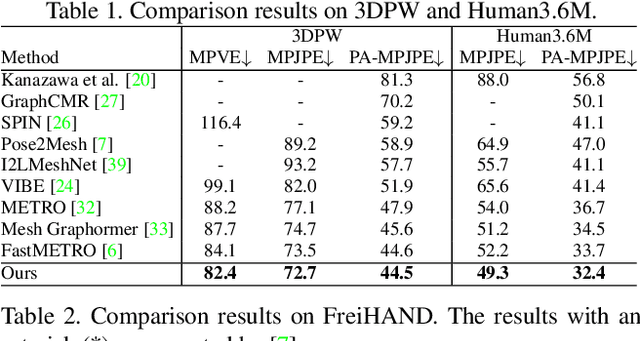
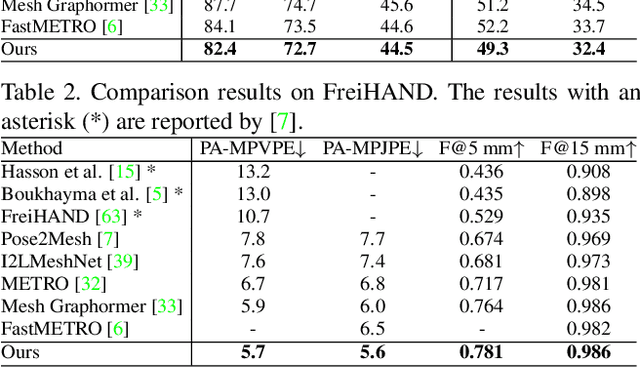

Recovering a 3D human mesh from a single RGB image is a challenging task due to depth ambiguity and self-occlusion, resulting in a high degree of uncertainty. Meanwhile, diffusion models have recently seen much success in generating high-quality outputs by progressively denoising noisy inputs. Inspired by their capability, we explore a diffusion-based approach for human mesh recovery, and propose a Human Mesh Diffusion (HMDiff) framework which frames mesh recovery as a reverse diffusion process. We also propose a Distribution Alignment Technique (DAT) that infuses prior distribution information into the mesh distribution diffusion process, and provides useful prior knowledge to facilitate the mesh recovery task. Our method achieves state-of-the-art performance on three widely used datasets. Project page: https://gongjia0208.github.io/HMDiff/.
Belief Control Barrier Functions for Risk-aware Control
Sep 12, 2023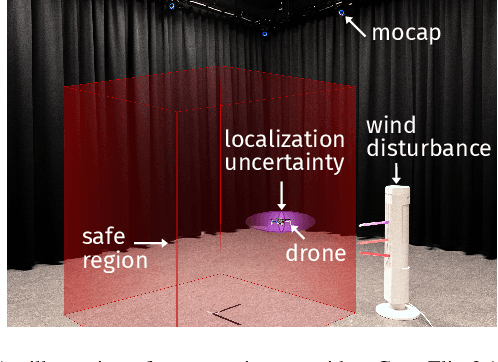
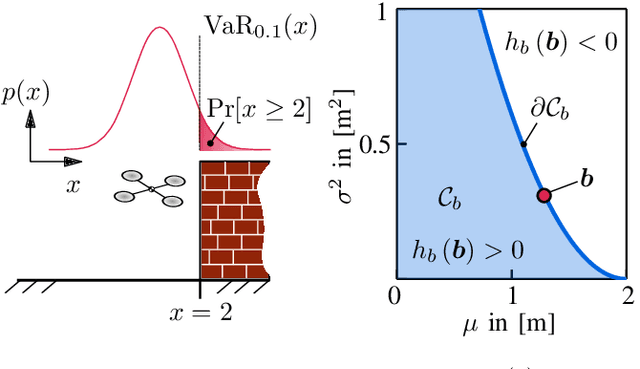
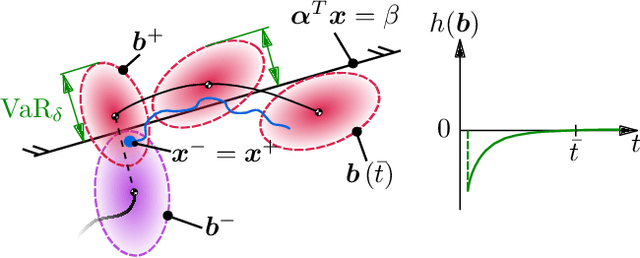
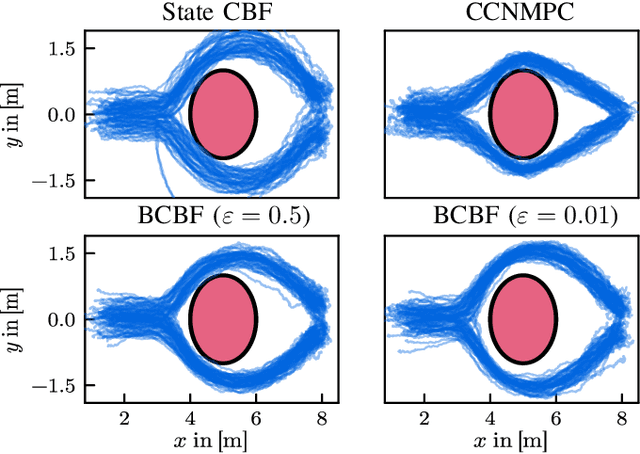
Ensuring safety in real-world robotic systems is often challenging due to unmodeled disturbances and noisy sensor measurements. To account for such stochastic uncertainties, many robotic systems leverage probabilistic state estimators such as Kalman filters to obtain a robot's belief, i.e. a probability distribution over possible states. We propose belief control barrier functions (BCBFs) to enable risk-aware control synthesis, leveraging all information provided by state estimators. This allows robots to stay in predefined safety regions with desired confidence under these stochastic uncertainties. BCBFs are general and can be applied to a variety of robotic systems that use extended Kalman filters as state estimator. We demonstrate BCBFs on a quadrotor that is exposed to external disturbances and varying sensing conditions. Our results show improved safety compared to traditional state-based approaches while allowing control frequencies of up to 1kHz.