 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MonoHair: High-Fidelity Hair Modeling from a Monocular Video
Mar 27, 2024
Undoubtedly, high-fidelity 3D hair is crucial for achieving realism, artistic expression, and immersion in computer graphics. While existing 3D hair modeling methods have achieved impressive performance, the challenge of achieving high-quality hair reconstruction persists: they either require strict capture conditions, making practical applications difficult, or heavily rely on learned prior data, obscuring fine-grained details in images. To address these challenges, we propose MonoHair,a generic framework to achieve high-fidelity hair reconstruction from a monocular video, without specific requirements for environments. Our approach bifurcates the hair modeling process into two main stages: precise exterior reconstruction and interior structure inference. The exterior is meticulously crafted using our Patch-based Multi-View Optimization (PMVO). This method strategically collects and integrates hair information from multiple views, independent of prior data, to produce a high-fidelity exterior 3D line map. This map not only captures intricate details but also facilitates the inference of the hair's inner structure. For the interior, we employ a data-driven, multi-view 3D hair reconstruction method. This method utilizes 2D structural renderings derived from the reconstructed exterior, mirroring the synthetic 2D inputs used during training. This alignment effectively bridges the domain gap between our training data and real-world data, thereby enhancing the accuracy and reliability of our interior structure inference. Lastly, we generate a strand model and resolve the directional ambiguity by our hair growth algorithm. Our experiments demonstrate that our method exhibits robustness across diverse hairstyles and achieves state-of-the-art performance. For more results, please refer to our project page https://keyuwu-cs.github.io/MonoHair/.
Connecting the Dots: Inferring Patent Phrase Similarity with Retrieved Phrase Graphs
Mar 24, 2024We study the patent phrase similarity inference task, which measures the semantic similarity between two patent phrases. As patent documents employ legal and highly technical language, existing semantic textual similarity methods that use localized contextual information do not perform satisfactorily in inferring patent phrase similarity. To address this, we introduce a graph-augmented approach to amplify the global contextual information of the patent phrases. For each patent phrase, we construct a phrase graph that links to its focal patents and a list of patents that are either cited by or cite these focal patents. The augmented phrase embedding is then derived from combining its localized contextual embedding with its global embedding within the phrase graph. We further propose a self-supervised learning objective that capitalizes on the retrieved topology to refine both the contextualized embedding and the graph parameters in an end-to-end manner. Experimental results from a unique patent phrase similarity dataset demonstrate that our approach significantly enhances the representation of patent phrases, resulting in marked improvements in similarity inference in a self-supervised fashion. Substantial improvements are also observed in the supervised setting, underscoring the potential benefits of leveraging retrieved phrase graph augmentation.
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Mar 24, 2024Cross-modal feature extraction and integration have led to steady performance improvements in few-shot learning tasks due to generating richer features. However, existing multi-modal object detection (MM-OD) methods degrade when facing significant domain-shift and are sample insufficient. We hypothesize that rich text information could more effectively help the model to build a knowledge relationship between the vision instance and its language description and can help mitigate domain shift. Specifically, we study the Cross-Domain few-shot generalization of MM-OD (CDMM-FSOD) and propose a meta-learning based multi-modal few-shot object detection method that utilizes rich text semantic information as an auxiliary modality to achieve domain adaptation in the context of FSOD. Our proposed network contains (i) a multi-modal feature aggregation module that aligns the vision and language support feature embeddings and (ii) a rich text semantic rectify module that utilizes bidirectional text feature generation to reinforce multi-modal feature alignment and thus to enhance the model's language understanding capability. We evaluate our model on common standard cross-domain object detection datasets and demonstrate that our approach considerably outperforms existing FSOD methods.
FedNMUT -- Federated Noisy Model Update Tracking Convergence Analysis
Mar 24, 2024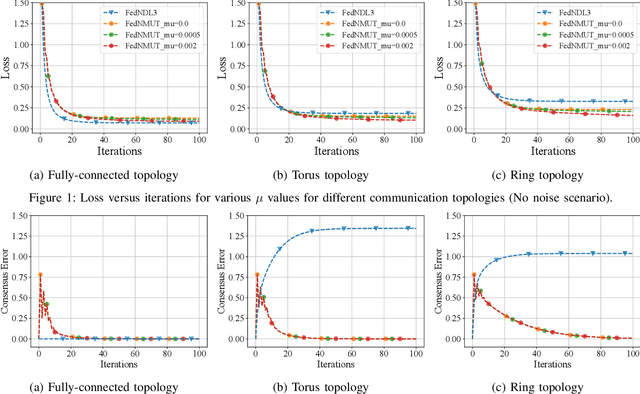
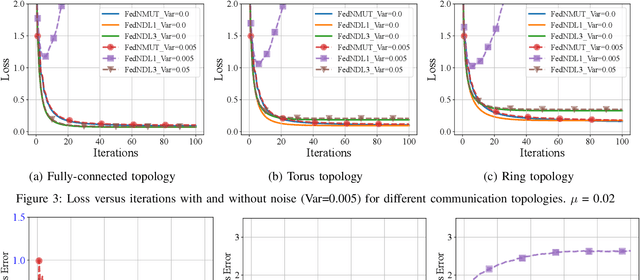
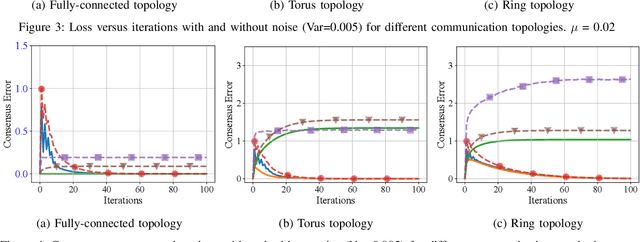
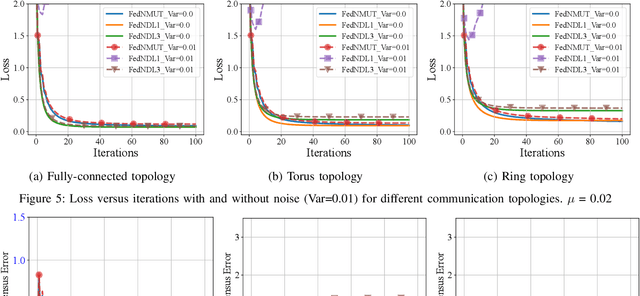
A novel Decentralized Noisy Model Update Tracking Federated Learning algorithm (FedNMUT) is proposed that is tailored to function efficiently in the presence of noisy communication channels that reflect imperfect information exchange. This algorithm uses gradient tracking to minimize the impact of data heterogeneity while minimizing communication overhead. The proposed algorithm incorporates noise into its parameters to mimic the conditions of noisy communication channels, thereby enabling consensus among clients through a communication graph topology in such challenging environments. FedNMUT prioritizes parameter sharing and noise incorporation to increase the resilience of decentralized learning systems against noisy communications. Theoretical results for the smooth non-convex objective function are provided by us, and it is shown that the $\epsilon-$stationary solution is achieved by our algorithm at the rate of $\mathcal{O}\left(\frac{1}{\sqrt{T}}\right)$, where $T$ is the total number of communication rounds. Additionally, via empirical validation, we demonstrated that the performance of FedNMUT is superior to the existing state-of-the-art methods and conventional parameter-mixing approaches in dealing with imperfect information sharing. This proves the capability of the proposed algorithm to counteract the negative effects of communication noise in a decentralized learning framework.
AE SemRL: Learning Semantic Association Rules with Autoencoders
Mar 26, 2024Association Rule Mining (ARM) is the task of learning associations among data features in the form of logical rules. Mining association rules from high-dimensional numerical data, for example, time series data from a large number of sensors in a smart environment, is a computationally intensive task. In this study, we propose an Autoencoder-based approach to learn and extract association rules from time series data (AE SemRL). Moreover, we argue that in the presence of semantic information related to time series data sources, semantics can facilitate learning generalizable and explainable association rules. Despite enriching time series data with additional semantic features, AE SemRL makes learning association rules from high-dimensional data feasible. Our experiments show that semantic association rules can be extracted from a latent representation created by an Autoencoder and this method has in the order of hundreds of times faster execution time than state-of-the-art ARM approaches in many scenarios. We believe that this study advances a new way of extracting associations from representations and has the potential to inspire more research in this field.
ShapeGrasp: Zero-Shot Task-Oriented Grasping with Large Language Models through Geometric Decomposition
Mar 26, 2024Task-oriented grasping of unfamiliar objects is a necessary skill for robots in dynamic in-home environments. Inspired by the human capability to grasp such objects through intuition about their shape and structure, we present a novel zero-shot task-oriented grasping method leveraging a geometric decomposition of the target object into simple, convex shapes that we represent in a graph structure, including geometric attributes and spatial relationships. Our approach employs minimal essential information - the object's name and the intended task - to facilitate zero-shot task-oriented grasping. We utilize the commonsense reasoning capabilities of large language models to dynamically assign semantic meaning to each decomposed part and subsequently reason over the utility of each part for the intended task. Through extensive experiments on a real-world robotics platform, we demonstrate that our grasping approach's decomposition and reasoning pipeline is capable of selecting the correct part in 92% of the cases and successfully grasping the object in 82% of the tasks we evaluate. Additional videos, experiments, code, and data are available on our project website: https://shapegrasp.github.io/.
D-PAD: Deep-Shallow Multi-Frequency Patterns Disentangling for Time Series Forecasting
Mar 26, 2024In time series forecasting, effectively disentangling intricate temporal patterns is crucial. While recent works endeavor to combine decomposition techniques with deep learning, multiple frequencies may still be mixed in the decomposed components, e.g., trend and seasonal. Furthermore, frequency domain analysis methods, e.g., Fourier and wavelet transforms, have limitations in resolution in the time domain and adaptability. In this paper, we propose D-PAD, a deep-shallow multi-frequency patterns disentangling neural network for time series forecasting. Specifically, a multi-component decomposing (MCD) block is introduced to decompose the series into components with different frequency ranges, corresponding to the "shallow" aspect. A decomposition-reconstruction-decomposition (D-R-D) module is proposed to progressively extract the information of frequencies mixed in the components, corresponding to the "deep" aspect. After that, an interaction and fusion (IF) module is used to further analyze the components. Extensive experiments on seven real-world datasets demonstrate that D-PAD achieves the state-of-the-art performance, outperforming the best baseline by an average of 9.48% and 7.15% in MSE and MAE, respectively.
SGHormer: An Energy-Saving Graph Transformer Driven by Spikes
Mar 26, 2024Graph Transformers (GTs) with powerful representation learning ability make a huge success in wide range of graph tasks. However, the costs behind outstanding performances of GTs are higher energy consumption and computational overhead. The complex structure and quadratic complexity during attention calculation in vanilla transformer seriously hinder its scalability on the large-scale graph data. Though existing methods have made strides in simplifying combinations among blocks or attention-learning paradigm to improve GTs' efficiency, a series of energy-saving solutions originated from biologically plausible structures are rarely taken into consideration when constructing GT framework. To this end, we propose a new spiking-based graph transformer (SGHormer). It turns full-precision embeddings into sparse and binarized spikes to reduce memory and computational costs. The spiking graph self-attention and spiking rectify blocks in SGHormer explicitly capture global structure information and recover the expressive power of spiking embeddings, respectively. In experiments, SGHormer achieves comparable performances to other full-precision GTs with extremely low computational energy consumption. The results show that SGHomer makes a remarkable progress in the field of low-energy GTs.
Waveform Design for Joint Communication and SAR Imaging Under Random Signaling
Mar 26, 2024Conventional synthetic aperture radar (SAR) imaging systems typically employ deterministic signal designs, which lack the capability to convey communication information and are thus not suitable for integrated sensing and communication (ISAC) scenarios. In this letter, we propose a joint communication and SAR imaging (JCASAR) system based on orthogonal frequency-division multiplexing (OFDM) signal with cyclic prefix (CP), which is capable of reconstructing the target profile while serving a communication user. In contrast to traditional matched filters, we propose a least squares (LS) estimator for range profiling. Then the SAR image is obtained followed by range cell migration correction (RCMC) and azimuth processing. By minimizing the mean squared error (MSE) of the proposed LS estimator, we investigate the optimal waveform design for SAR imaging, and JCASAR under random signaling, where power allocation strategies are conceived for Gaussian-distributed ISAC signals, in an effort to strike a flexible performance tradeoff between the communication and SAR imaging tasks. Numerical results are provided to validate the effectiveness of the proposed ISAC waveform design for JCASAR systems.
END4Rec: Efficient Noise-Decoupling for Multi-Behavior Sequential Recommendation
Mar 26, 2024In recommendation systems, users frequently engage in multiple types of behaviors, such as clicking, adding to a cart, and purchasing. However, with diversified behavior data, user behavior sequences will become very long in the short term, which brings challenges to the efficiency of the sequence recommendation model. Meanwhile, some behavior data will also bring inevitable noise to the modeling of user interests. To address the aforementioned issues, firstly, we develop the Efficient Behavior Sequence Miner (EBM) that efficiently captures intricate patterns in user behavior while maintaining low time complexity and parameter count. Secondly, we design hard and soft denoising modules for different noise types and fully explore the relationship between behaviors and noise. Finally, we introduce a contrastive loss function along with a guided training strategy to compare the valid information in the data with the noisy signal, and seamlessly integrate the two denoising processes to achieve a high degree of decoupling of the noisy signal. Sufficient experiments on real-world datasets demonstrate the effectiveness and efficiency of our approach in dealing with multi-behavior sequential recommendation.