 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Music Genre Classification: Algorithm Analysis and Deployment Architecture
Sep 14, 2023
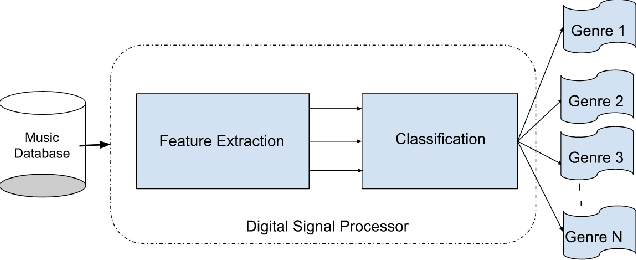
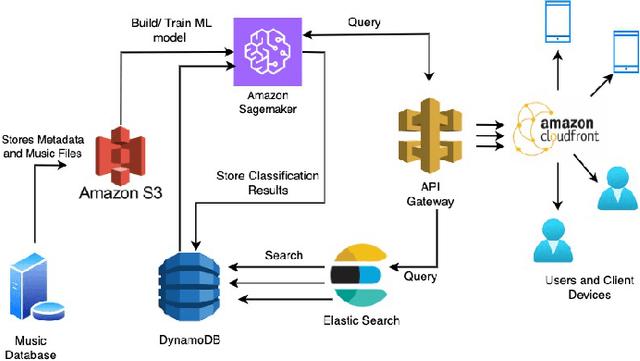
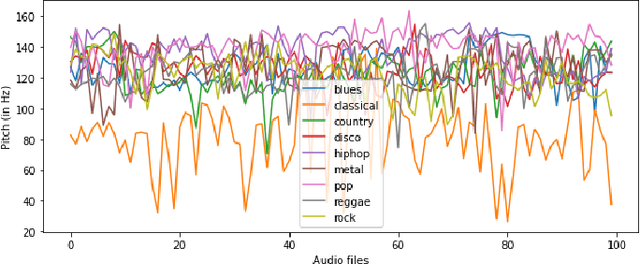

Music genre classification has become increasingly critical with the advent of various streaming applications. Nowadays, we find it impossible to imagine using the artist's name and song title to search for music in a sophisticated music app. It is always difficult to classify music correctly because the information linked to music, such as region, artist, album, or non-album, is so variable. This paper presents a study on music genre classification using a combination of Digital Signal Processing (DSP) and Deep Learning (DL) techniques. A novel algorithm is proposed that utilizes both DSP and DL methods to extract relevant features from audio signals and classify them into various genres. The algorithm was tested on the GTZAN dataset and achieved high accuracy. An end-to-end deployment architecture is also proposed for integration into music-related applications. The performance of the algorithm is analyzed and future directions for improvement are discussed. The proposed DSP and DL-based music genre classification algorithm and deployment architecture demonstrate a promising approach for music genre classification.
A Conversation is Worth A Thousand Recommendations: A Survey of Holistic Conversational Recommender Systems
Sep 14, 2023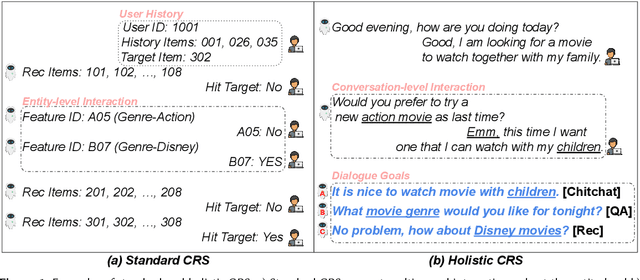
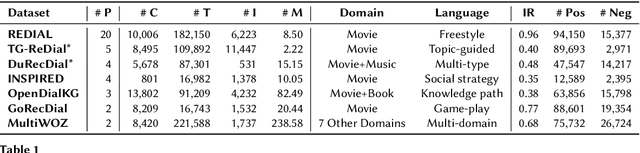
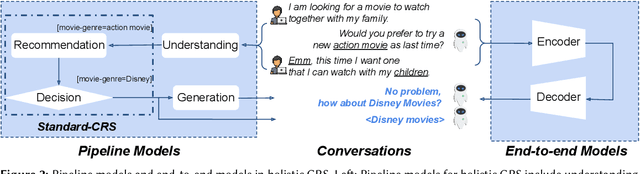
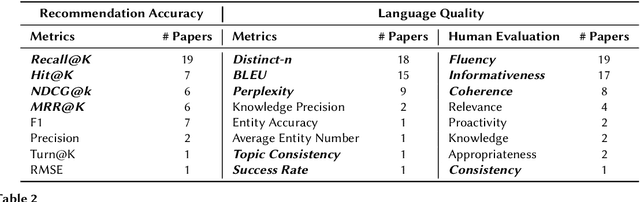
Conversational recommender systems (CRS) generate recommendations through an interactive process. However, not all CRS approaches use human conversations as their source of interaction data; the majority of prior CRS work simulates interactions by exchanging entity-level information. As a result, claims of prior CRS work do not generalise to real-world settings where conversations take unexpected turns, or where conversational and intent understanding is not perfect. To tackle this challenge, the research community has started to examine holistic CRS, which are trained using conversational data collected from real-world scenarios. Despite their emergence, such holistic approaches are under-explored. We present a comprehensive survey of holistic CRS methods by summarizing the literature in a structured manner. Our survey recognises holistic CRS approaches as having three components: 1) a backbone language model, the optional use of 2) external knowledge, and/or 3) external guidance. We also give a detailed analysis of CRS datasets and evaluation methods in real application scenarios. We offer our insight as to the current challenges of holistic CRS and possible future trends.
Incorporating Class-based Language Model for Named Entity Recognition in Factorized Neural Transducer
Sep 14, 2023In spite of the excellent strides made by end-to-end (E2E) models in speech recognition in recent years, named entity recognition is still challenging but critical for semantic understanding. In order to enhance the ability to recognize named entities in E2E models, previous studies mainly focus on various rule-based or attention-based contextual biasing algorithms. However, their performance might be sensitive to the biasing weight or degraded by excessive attention to the named entity list, along with a risk of false triggering. Inspired by the success of the class-based language model (LM) in named entity recognition in conventional hybrid systems and the effective decoupling of acoustic and linguistic information in the factorized neural Transducer (FNT), we propose a novel E2E model to incorporate class-based LMs into FNT, which is referred as C-FNT. In C-FNT, the language model score of named entities can be associated with the name class instead of its surface form. The experimental results show that our proposed C-FNT presents significant error reduction in named entities without hurting performance in general word recognition.
Leave no Place Behind: Improved Geolocation in Humanitarian Documents
Sep 06, 2023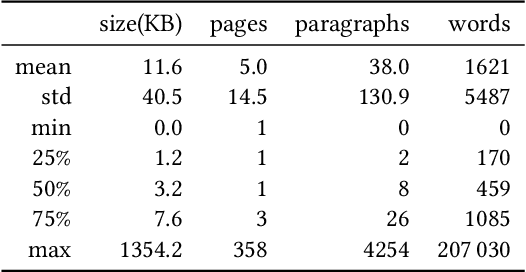
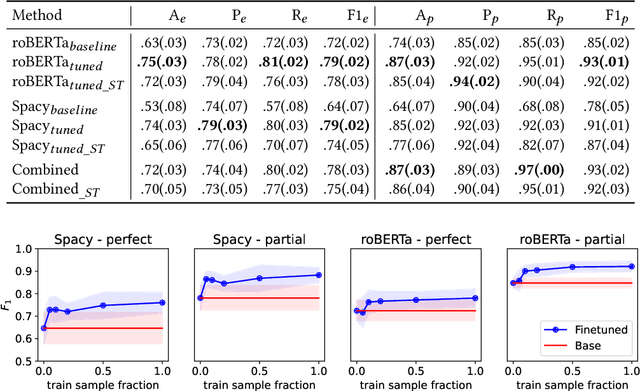
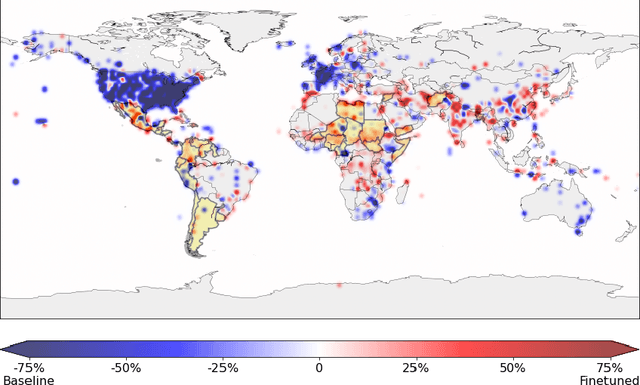
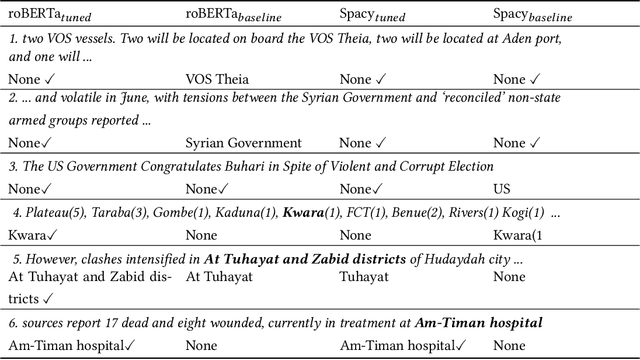
Geographical location is a crucial element of humanitarian response, outlining vulnerable populations, ongoing events, and available resources. Latest developments in Natural Language Processing may help in extracting vital information from the deluge of reports and documents produced by the humanitarian sector. However, the performance and biases of existing state-of-the-art information extraction tools are unknown. In this work, we develop annotated resources to fine-tune the popular Named Entity Recognition (NER) tools Spacy and roBERTa to perform geotagging of humanitarian texts. We then propose a geocoding method FeatureRank which links the candidate locations to the GeoNames database. We find that not only does the humanitarian-domain data improves the performance of the classifiers (up to F1 = 0.92), but it also alleviates some of the bias of the existing tools, which erroneously favor locations in the Western countries. Thus, we conclude that more resources from non-Western documents are necessary to ensure that off-the-shelf NER systems are suitable for the deployment in the humanitarian sector.
GPT-InvestAR: Enhancing Stock Investment Strategies through Annual Report Analysis with Large Language Models
Sep 06, 2023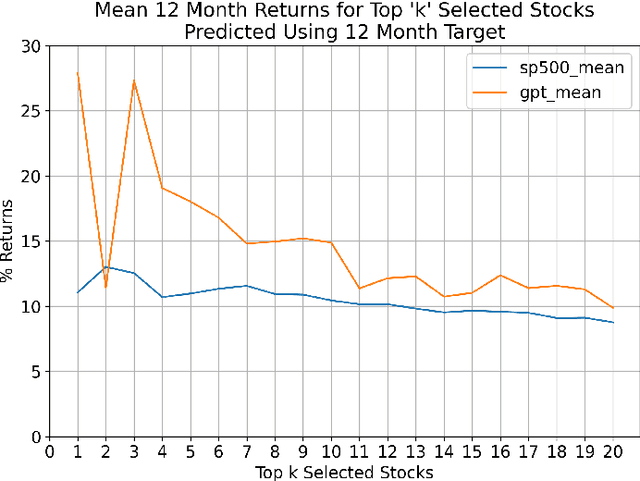
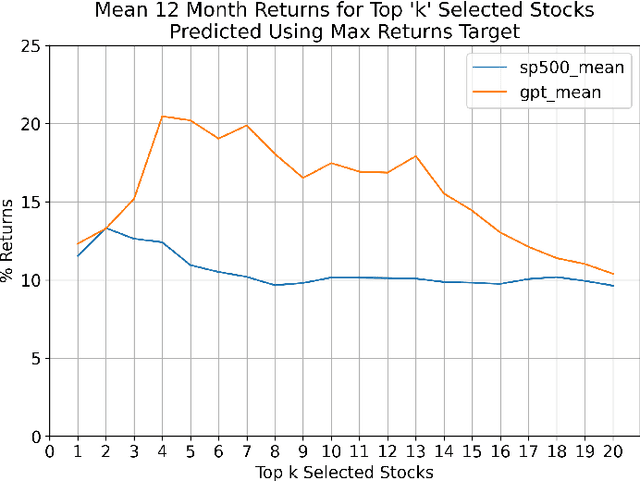
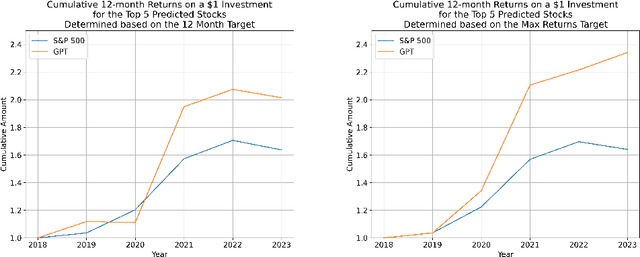
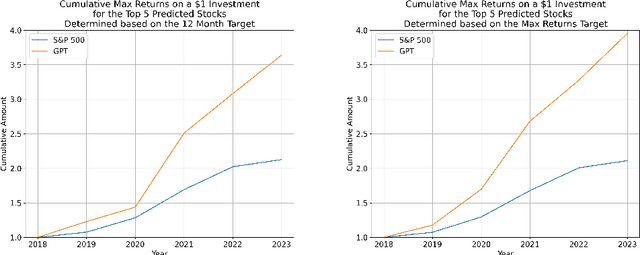
Annual Reports of publicly listed companies contain vital information about their financial health which can help assess the potential impact on Stock price of the firm. These reports are comprehensive in nature, going up to, and sometimes exceeding, 100 pages. Analysing these reports is cumbersome even for a single firm, let alone the whole universe of firms that exist. Over the years, financial experts have become proficient in extracting valuable information from these documents relatively quickly. However, this requires years of practice and experience. This paper aims to simplify the process of assessing Annual Reports of all the firms by leveraging the capabilities of Large Language Models (LLMs). The insights generated by the LLM are compiled in a Quant styled dataset and augmented by historical stock price data. A Machine Learning model is then trained with LLM outputs as features. The walkforward test results show promising outperformance wrt S&P500 returns. This paper intends to provide a framework for future work in this direction. To facilitate this, the code has been released as open source.
Learning Vehicle Dynamics from Cropped Image Patches for Robot Navigation in Unpaved Outdoor Terrains
Sep 06, 2023

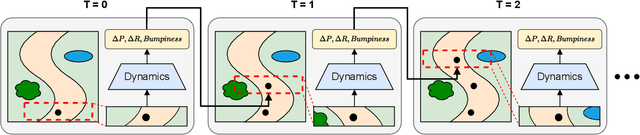

In the realm of autonomous mobile robots, safe navigation through unpaved outdoor environments remains a challenging task. Due to the high-dimensional nature of sensor data, extracting relevant information becomes a complex problem, which hinders adequate perception and path planning. Previous works have shown promising performances in extracting global features from full-sized images. However, they often face challenges in capturing essential local information. In this paper, we propose Crop-LSTM, which iteratively takes cropped image patches around the current robot's position and predicts the future position, orientation, and bumpiness. Our method performs local feature extraction by paying attention to corresponding image patches along the predicted robot trajectory in the 2D image plane. This enables more accurate predictions of the robot's future trajectory. With our wheeled mobile robot platform Raicart, we demonstrated the effectiveness of Crop-LSTM for point-goal navigation in an unpaved outdoor environment. Our method enabled safe and robust navigation using RGBD images in challenging unpaved outdoor terrains. The summary video is available at https://youtu.be/iIGNZ8ignk0.
An Improved Encoder-Decoder Framework for Food EnergyEstimation
Sep 01, 2023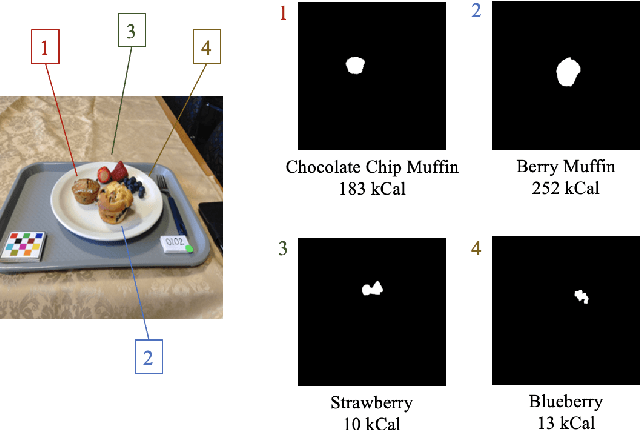

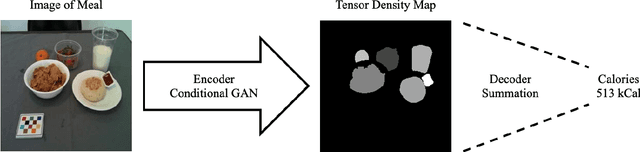

Dietary assessment is essential to maintaining a healthy lifestyle. Automatic image-based dietary assessment is a growing field of research due to the increasing prevalence of image capturing devices (e.g. mobile phones). In this work, we estimate food energy from a single monocular image, a difficult task due to the limited hard-to-extract amount of energy information present in an image. To do so, we employ an improved encoder-decoder framework for energy estimation; the encoder transforms the image into a representation embedded with food energy information in an easier-to-extract format, which the decoder then extracts the energy information from. To implement our method, we compile a high-quality food image dataset verified by registered dietitians containing eating scene images, food-item segmentation masks, and ground truth calorie values. Our method improves upon previous caloric estimation methods by over 10\% and 30 kCal in terms of MAPE and MAE respectively.
Debunking Disinformation: Revolutionizing Truth with NLP in Fake News Detection
Aug 30, 2023The Internet and social media have altered how individuals access news in the age of instantaneous information distribution. While this development has increased access to information, it has also created a significant problem: the spread of fake news and information. Fake news is rapidly spreading on digital platforms, which has a negative impact on the media ecosystem, public opinion, decision-making, and social cohesion. Natural Language Processing(NLP), which offers a variety of approaches to identify content as authentic, has emerged as a potent weapon in the growing war against disinformation. This paper takes an in-depth look at how NLP technology can be used to detect fake news and reveals the challenges and opportunities it presents.
ShaDocFormer: A Shadow-attentive Threshold Detector with Cascaded Fusion Refiner for document shadow removal' to the ICASSP 2024 online submission system
Sep 13, 2023
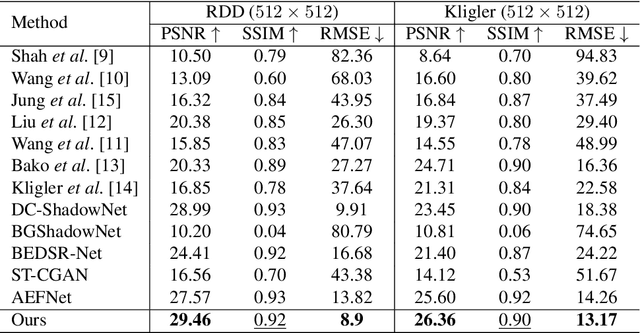
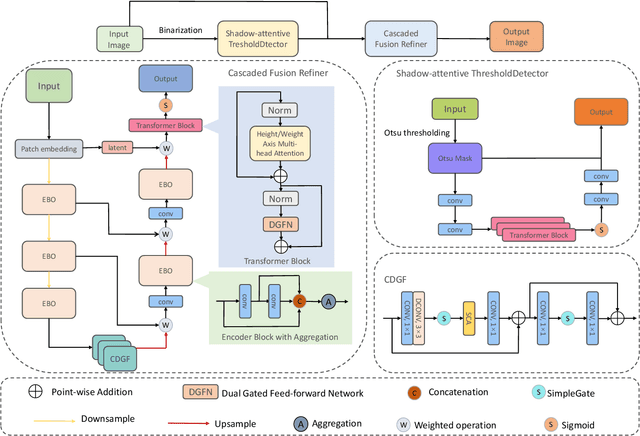
Document shadow is a common issue that arise when capturing documents using mobile devices, which significantly impacts the readability. Current methods encounter various challenges including inaccurate detection of shadow masks and estimation of illumination. In this paper, we propose ShaDocFormer, a Transformer-based architecture that integrates traditional methodologies and deep learning techniques to tackle the problem of document shadow removal. The ShaDocFormer architecture comprises two components: the Shadow-attentive Threshold Detector (STD) and the Cascaded Fusion Refiner (CFR). The STD module employs a traditional thresholding technique and leverages the attention mechanism of the Transformer to gather global information, thereby enabling precise detection of shadow masks. The cascaded and aggregative structure of the CFR module facilitates a coarse-to-fine restoration process for the entire image. As a result, ShaDocFormer excels in accurately detecting and capturing variations in both shadow and illumination, thereby enabling effective removal of shadows. Extensive experiments demonstrate that ShaDocFormer outperforms current state-of-the-art methods in both qualitative and quantitative measurements.
Temporal compressive edge imaging enabled by a lensless diffuser camera
Sep 13, 2023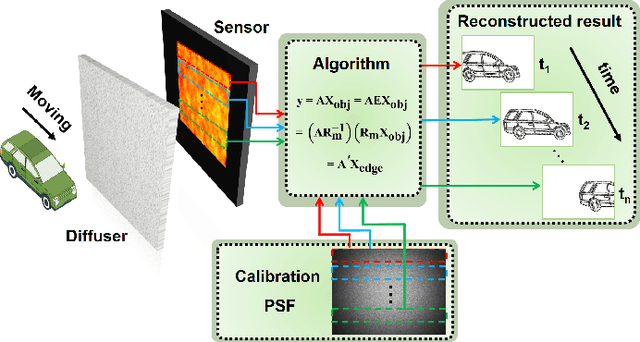

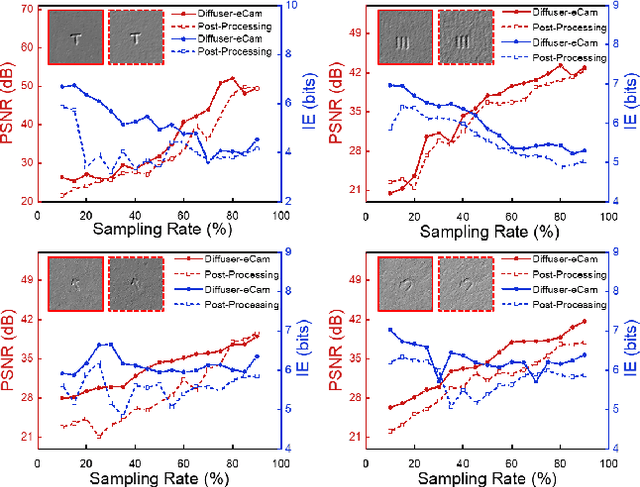

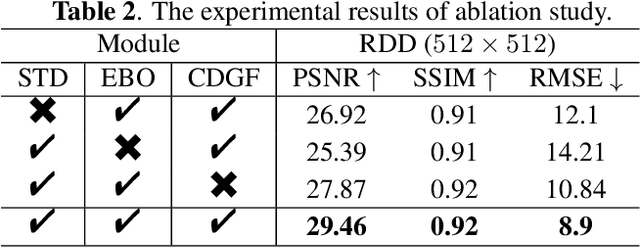
Lensless imagers based on diffusers or encoding masks enable high-dimensional imaging from a single shot measurement and have been applied in various applications. However, to further extract image information such as edge detection, conventional post-processing filtering operations are needed after the reconstruction of the original object images in the diffuser imaging systems. Here, we present the concept of a temporal compressive edge detection method based on a lensless diffuser camera, which can directly recover a time sequence of edge images of a moving object from a single-shot measurement, without further post-processing steps. Our approach provides higher image quality during edge detection, compared with the conventional post-processing method. We demonstrate the effectiveness of this approach by both numerical simulation and experiments. The proof-of-concept approach can be further developed with other image post-process operations or versatile computer vision assignments toward task-oriented intelligent lensless imaging systems.