 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Prompt-based All-in-One Image Restoration using CNNs and Transformer
Sep 06, 2023
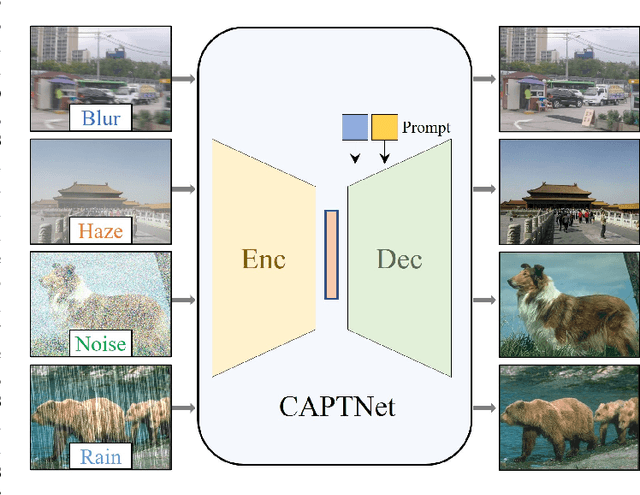



Image restoration aims to recover the high-quality images from their degraded observations. Since most existing methods have been dedicated into single degradation removal, they may not yield optimal results on other types of degradations, which do not satisfy the applications in real world scenarios. In this paper, we propose a novel data ingredient-oriented approach that leverages prompt-based learning to enable a single model to efficiently tackle multiple image degradation tasks. Specifically, we utilize a encoder to capture features and introduce prompts with degradation-specific information to guide the decoder in adaptively recovering images affected by various degradations. In order to model the local invariant properties and non-local information for high-quality image restoration, we combined CNNs operations and Transformers. Simultaneously, we made several key designs in the Transformer blocks (multi-head rearranged attention with prompts and simple-gate feed-forward network) to reduce computational requirements and selectively determines what information should be persevered to facilitate efficient recovery of potentially sharp images. Furthermore, we incorporate a feature fusion mechanism further explores the multi-scale information to improve the aggregated features. The resulting tightly interlinked hierarchy architecture, named as CAPTNet, despite being designed to handle different types of degradations, extensive experiments demonstrate that our method performs competitively to the task-specific algorithms.
Neuro-Symbolic Recommendation Model based on Logic Query
Sep 14, 2023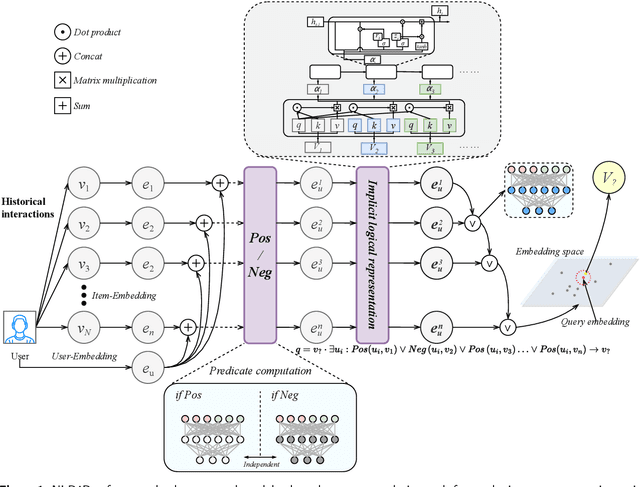

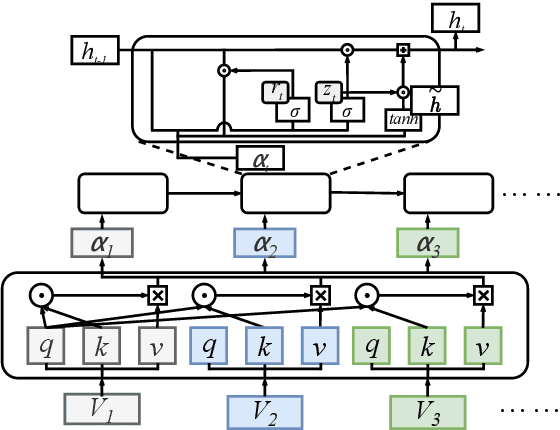
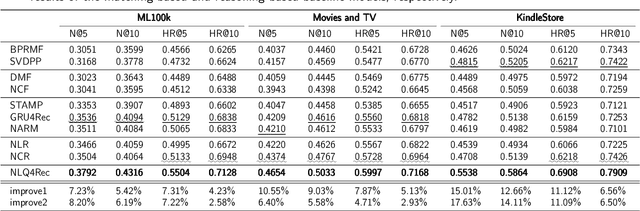
A recommendation system assists users in finding items that are relevant to them. Existing recommendation models are primarily based on predicting relationships between users and items and use complex matching models or incorporate extensive external information to capture association patterns in data. However, recommendation is not only a problem of inductive statistics using data; it is also a cognitive task of reasoning decisions based on knowledge extracted from information. Hence, a logic system could naturally be incorporated for the reasoning in a recommendation task. However, although hard-rule approaches based on logic systems can provide powerful reasoning ability, they struggle to cope with inconsistent and incomplete knowledge in real-world tasks, especially for complex tasks such as recommendation. Therefore, in this paper, we propose a neuro-symbolic recommendation model, which transforms the user history interactions into a logic expression and then transforms the recommendation prediction into a query task based on this logic expression. The logic expressions are then computed based on the modular logic operations of the neural network. We also construct an implicit logic encoder to reasonably reduce the complexity of the logic computation. Finally, a user's interest items can be queried in the vector space based on the computation results. Experiments on three well-known datasets verified that our method performs better compared to state of the art shallow, deep, session, and reasoning models.
GRID: Scene-Graph-based Instruction-driven Robotic Task Planning
Sep 14, 2023Recent works have shown that Large Language Models (LLMs) can promote grounding instructions to robotic task planning. Despite the progress, most existing works focused on utilizing raw images to help LLMs understand environmental information, which not only limits the observation scope but also typically requires massive multimodal data collection and large-scale models. In this paper, we propose a novel approach called Graph-based Robotic Instruction Decomposer (GRID), leverages scene graph instead of image to perceive global scene information and continuously plans subtask in each stage for a given instruction. Our method encodes object attributes and relationships in graphs through an LLM and Graph Attention Networks, integrating instruction features to predict subtasks consisting of pre-defined robot actions and target objects in the scene graph. This strategy enables robots to acquire semantic knowledge widely observed in the environment from the scene graph. To train and evaluate GRID, we build a dataset construction pipeline to generate synthetic datasets in graph-based robotic task planning. Experiments have shown that our method outperforms GPT-4 by over 25.4% in subtask accuracy and 43.6% in task accuracy. Experiments conducted on datasets of unseen scenes and scenes with different numbers of objects showed that the task accuracy of GRID declined by at most 3.8%, which demonstrates its good cross-scene generalization ability. We validate our method in both physical simulation and the real world.
Examining the Effectiveness of Chatbots in Gathering Family History Information in Comparison to the Standard In-Person Interview-Based Approach
Sep 01, 2023
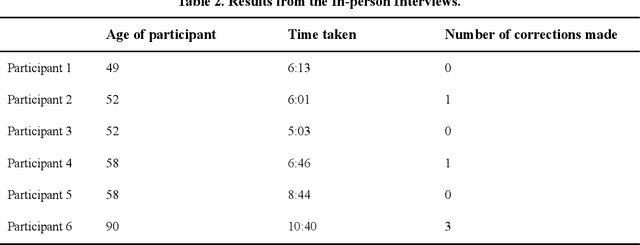
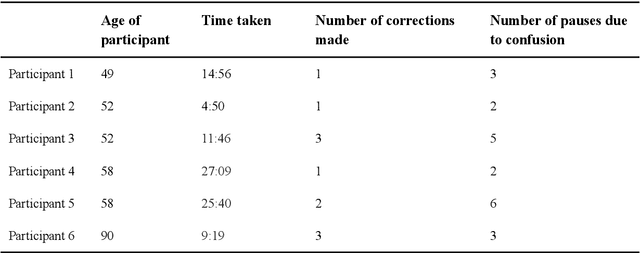
One of the most common things that a genealogist is tasked with is the gathering of a person's initial family history, normally via in-person interviews or with the use of a platform such as ancestry.com, as this can provide a strong foundation upon which a genealogist may build. However, the ability to conduct these interviews can often be hindered by both geographical constraints and the technical proficiency of the interviewee, as the interviewee in these types of interviews is most often an elderly person with a lower than average level of technical proficiency. With this in mind, this study presents what we believe, based on prior research, to be the first chatbot geared entirely towards the gathering of family histories, and explores the viability of utilising such a chatbot by comparing the performance and usability of such a method with the aforementioned alternatives. With a chatbot-based approach, we show that, though the average time taken to conduct an interview may be longer than if the user had used ancestry.com or participated in an in-person interview, the number of mistakes made and the level of confusion from the user regarding the UI and process required is lower than the other two methods. Note that the final metric regarding the user's confusion is not applicable for the in-person interview sessions due to its lack of a UI. With refinement, we believe this use of a chatbot could be a valuable tool for genealogists, especially when dealing with interviewees who are based in other countries where it is not possible to conduct an in-person interview.
Modeling Recommender Ecosystems: Research Challenges at the Intersection of Mechanism Design, Reinforcement Learning and Generative Models
Sep 22, 2023
Modern recommender systems lie at the heart of complex ecosystems that couple the behavior of users, content providers, advertisers, and other actors. Despite this, the focus of the majority of recommender research -- and most practical recommenders of any import -- is on the local, myopic optimization of the recommendations made to individual users. This comes at a significant cost to the long-term utility that recommenders could generate for its users. We argue that explicitly modeling the incentives and behaviors of all actors in the system -- and the interactions among them induced by the recommender's policy -- is strictly necessary if one is to maximize the value the system brings to these actors and improve overall ecosystem "health". Doing so requires: optimization over long horizons using techniques such as reinforcement learning; making inevitable tradeoffs in the utility that can be generated for different actors using the methods of social choice; reducing information asymmetry, while accounting for incentives and strategic behavior, using the tools of mechanism design; better modeling of both user and item-provider behaviors by incorporating notions from behavioral economics and psychology; and exploiting recent advances in generative and foundation models to make these mechanisms interpretable and actionable. We propose a conceptual framework that encompasses these elements, and articulate a number of research challenges that emerge at the intersection of these different disciplines.
PI-RADS v2 Compliant Automated Segmentation of Prostate Zones Using co-training Motivated Multi-task Dual-Path CNN
Sep 22, 2023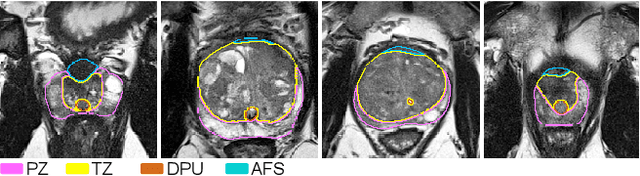

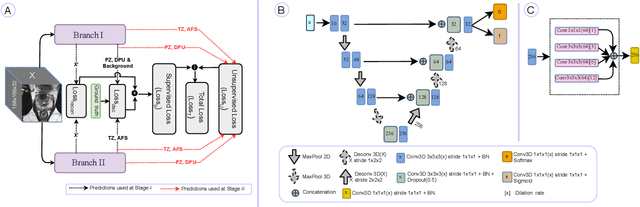
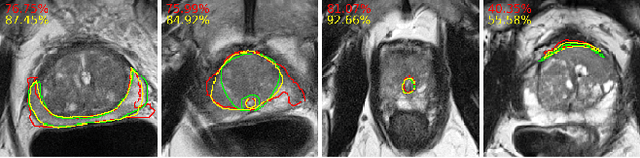
The detailed images produced by Magnetic Resonance Imaging (MRI) provide life-critical information for the diagnosis and treatment of prostate cancer. To provide standardized acquisition, interpretation and usage of the complex MRI images, the PI-RADS v2 guideline was proposed. An automated segmentation following the guideline facilitates consistent and precise lesion detection, staging and treatment. The guideline recommends a division of the prostate into four zones, PZ (peripheral zone), TZ (transition zone), DPU (distal prostatic urethra) and AFS (anterior fibromuscular stroma). Not every zone shares a boundary with the others and is present in every slice. Further, the representations captured by a single model might not suffice for all zones. This motivated us to design a dual-branch convolutional neural network (CNN), where each branch captures the representations of the connected zones separately. Further, the representations from different branches act complementary to each other at the second stage of training, where they are fine-tuned through an unsupervised loss. The loss penalises the difference in predictions from the two branches for the same class. We also incorporate multi-task learning in our framework to further improve the segmentation accuracy. The proposed approach improves the segmentation accuracy of the baseline (mean absolute symmetric distance) by 7.56%, 11.00%, 58.43% and 19.67% for PZ, TZ, DPU and AFS zones respectively.
CryoAlign: feature-based method for global and local 3D alignment of EM density maps
Sep 17, 2023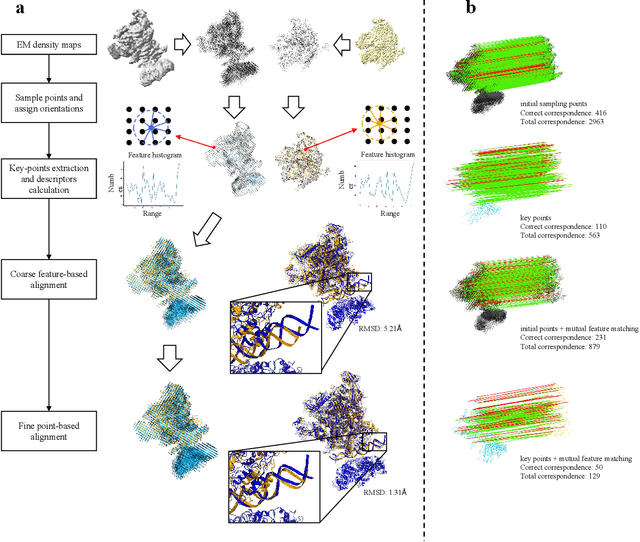
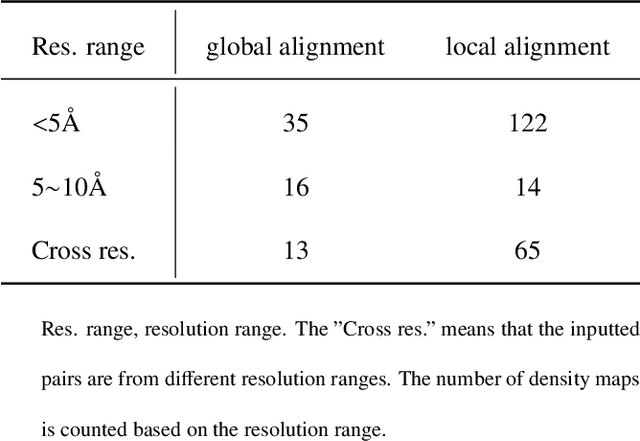
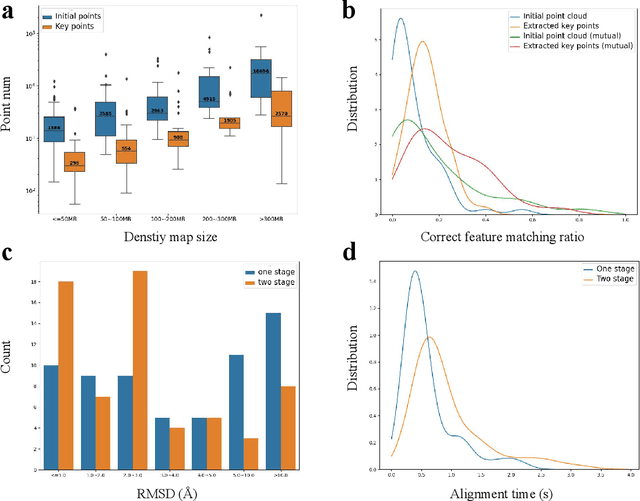
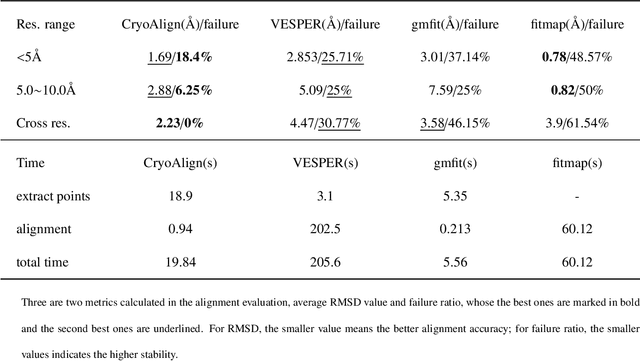
Advances on cryo-electron imaging technologies have led to a rapidly increasing number of density maps. Alignment and comparison of density maps play a crucial role in interpreting structural information, such as conformational heterogeneity analysis using global alignment and atomic model assembly through local alignment. Here, we propose a fast and accurate global and local cryo-electron microscopy density map alignment method CryoAlign, which leverages local density feature descriptors to capture spatial structure similarities. CryoAlign is the first feature-based EM map alignment tool, in which the employment of feature-based architecture enables the rapid establishment of point pair correspondences and robust estimation of alignment parameters. Extensive experimental evaluations demonstrate the superiority of CryoAlign over the existing methods in both alignment accuracy and speed.
Improving Voice Conversion for Dissimilar Speakers Using Perceptual Losses
Sep 18, 2023The rising trend of using voice as a means of interacting with smart devices has sparked worries over the protection of users' privacy and data security. These concerns have become more pressing, especially after the European Union's adoption of the General Data Protection Regulation (GDPR). The information contained in an utterance encompasses critical personal details about the speaker, such as their age, gender, socio-cultural origins and more. If there is a security breach and the data is compromised, attackers may utilise the speech data to circumvent the speaker verification systems or imitate authorised users. Therefore, it is pertinent to anonymise the speech data before being shared across devices, such that the source speaker of the utterance cannot be traced. Voice conversion (VC) can be used to achieve speech anonymisation, which involves altering the speaker's characteristics while preserving the linguistic content.
Dual-Reference Source-Free Active Domain Adaptation for Nasopharyngeal Carcinoma Tumor Segmentation across Multiple Hospitals
Sep 23, 2023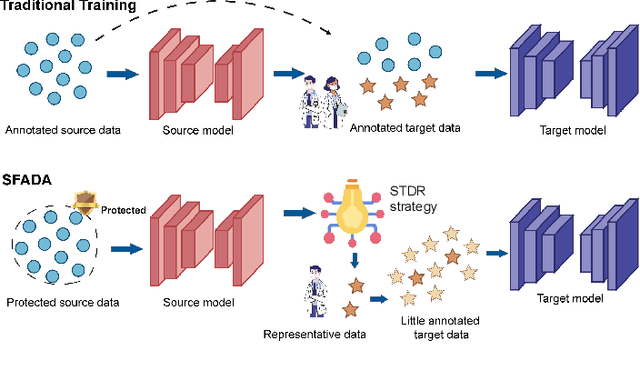
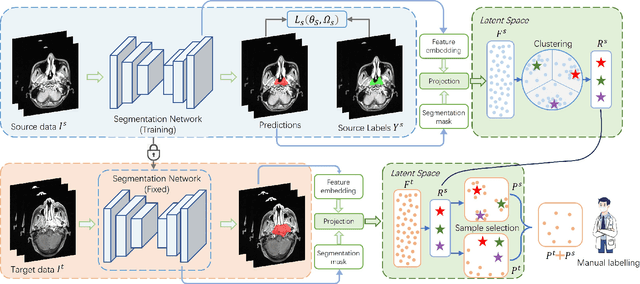
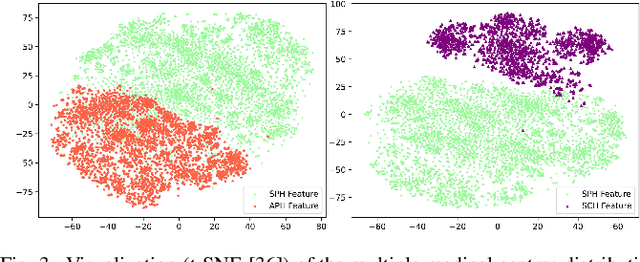
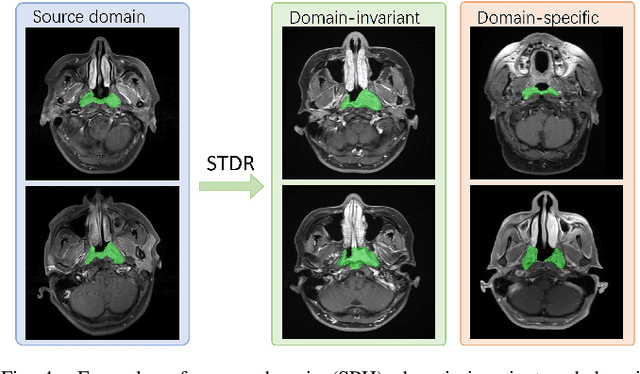
Nasopharyngeal carcinoma (NPC) is a prevalent and clinically significant malignancy that predominantly impacts the head and neck area. Precise delineation of the Gross Tumor Volume (GTV) plays a pivotal role in ensuring effective radiotherapy for NPC. Despite recent methods that have achieved promising results on GTV segmentation, they are still limited by lacking carefully-annotated data and hard-to-access data from multiple hospitals in clinical practice. Although some unsupervised domain adaptation (UDA) has been proposed to alleviate this problem, unconditionally mapping the distribution distorts the underlying structural information, leading to inferior performance. To address this challenge, we devise a novel Sourece-Free Active Domain Adaptation (SFADA) framework to facilitate domain adaptation for the GTV segmentation task. Specifically, we design a dual reference strategy to select domain-invariant and domain-specific representative samples from a specific target domain for annotation and model fine-tuning without relying on source-domain data. Our approach not only ensures data privacy but also reduces the workload for oncologists as it just requires annotating a few representative samples from the target domain and does not need to access the source data. We collect a large-scale clinical dataset comprising 1057 NPC patients from five hospitals to validate our approach. Experimental results show that our method outperforms the UDA methods and achieves comparable results to the fully supervised upper bound, even with few annotations, highlighting the significant medical utility of our approach. In addition, there is no public dataset about multi-center NPC segmentation, we will release code and dataset for future research.
Practical Homomorphic Aggregation for Byzantine ML
Sep 15, 2023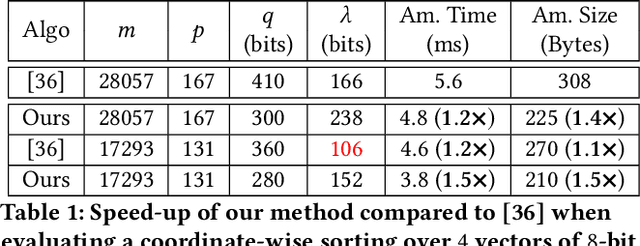
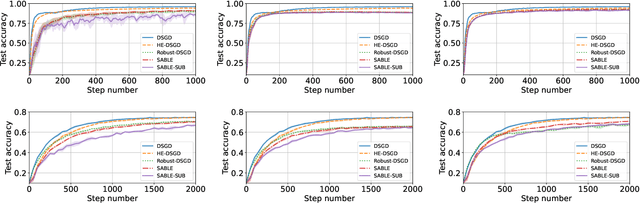
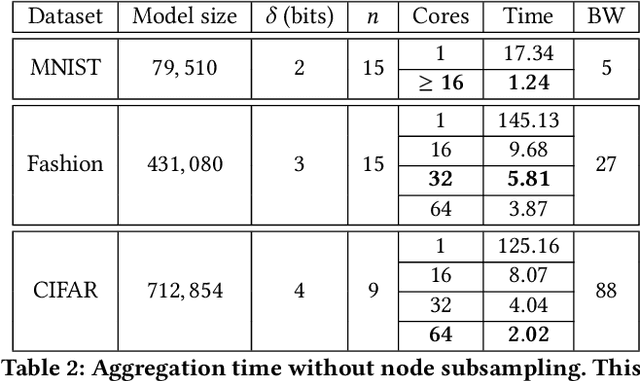
Due to the large-scale availability of data, machine learning (ML) algorithms are being deployed in distributed topologies, where different nodes collaborate to train ML models over their individual data by exchanging model-related information (e.g., gradients) with a central server. However, distributed learning schemes are notably vulnerable to two threats. First, Byzantine nodes can single-handedly corrupt the learning by sending incorrect information to the server, e.g., erroneous gradients. The standard approach to mitigate such behavior is to use a non-linear robust aggregation method at the server. Second, the server can violate the privacy of the nodes. Recent attacks have shown that exchanging (unencrypted) gradients enables a curious server to recover the totality of the nodes' data. The use of homomorphic encryption (HE), a gold standard security primitive, has extensively been studied as a privacy-preserving solution to distributed learning in non-Byzantine scenarios. However, due to HE's large computational demand especially for high-dimensional ML models, there has not yet been any attempt to design purely homomorphic operators for non-linear robust aggregators. In this work, we present SABLE, the first completely homomorphic and Byzantine robust distributed learning algorithm. SABLE essentially relies on a novel plaintext encoding method that enables us to implement the robust aggregator over batching-friendly BGV. Moreover, this encoding scheme also accelerates state-of-the-art homomorphic sorting with larger security margins and smaller ciphertext size. We perform extensive experiments on image classification tasks and show that our algorithm achieves practical execution times while matching the ML performance of its non-private counterpart.