 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Product Information Extraction using ChatGPT
Jun 23, 2023
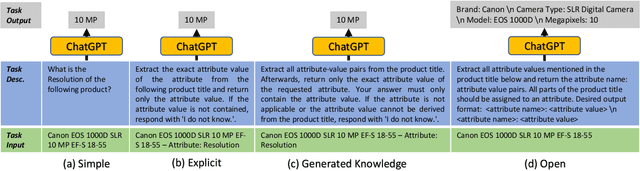
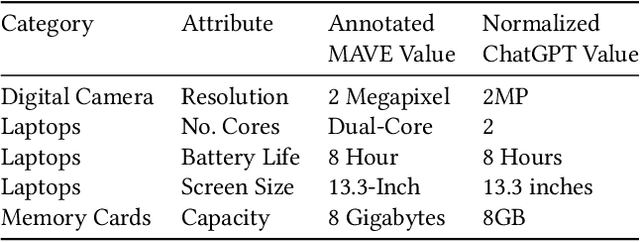
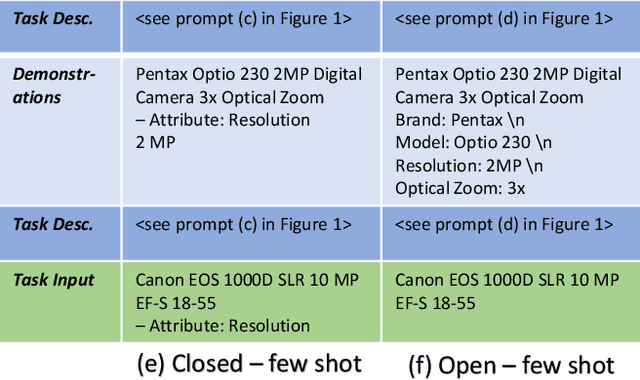
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
Addressing Feature Imbalance in Sound Source Separation
Sep 11, 2023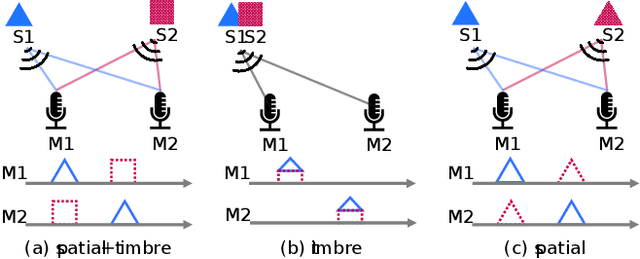
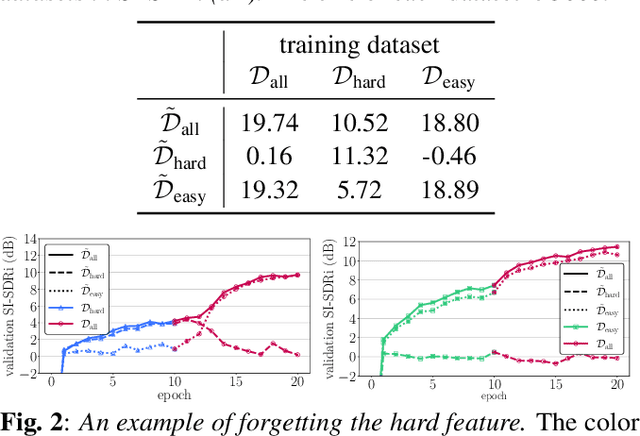


Neural networks often suffer from a feature preference problem, where they tend to overly rely on specific features to solve a task while disregarding other features, even if those neglected features are essential for the task. Feature preference problems have primarily been investigated in classification task. However, we observe that feature preference occurs in high-dimensional regression task, specifically, source separation. To mitigate feature preference in source separation, we propose FEAture BAlancing by Suppressing Easy feature (FEABASE). This approach enables efficient data utilization by learning hidden information about the neglected feature. We evaluate our method in a multi-channel source separation task, where feature preference between spatial feature and timbre feature appears.
CONVERSER: Few-Shot Conversational Dense Retrieval with Synthetic Data Generation
Sep 13, 2023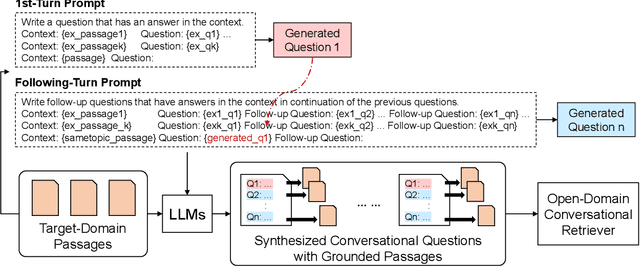
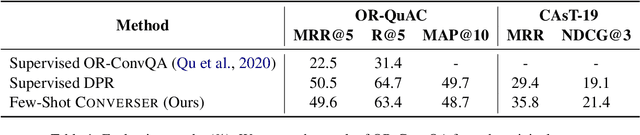
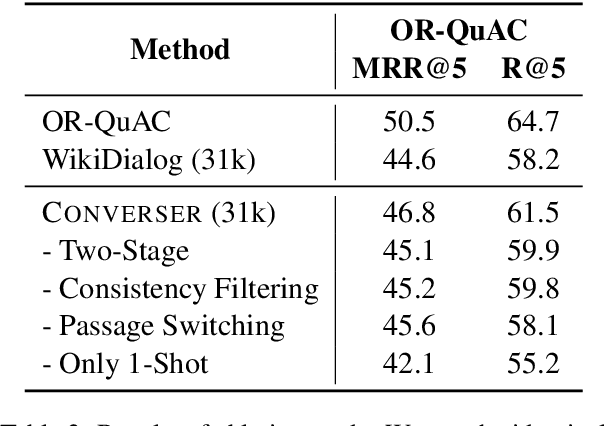
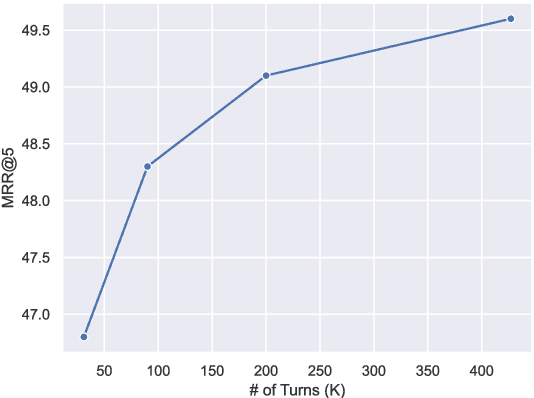
Conversational search provides a natural interface for information retrieval (IR). Recent approaches have demonstrated promising results in applying dense retrieval to conversational IR. However, training dense retrievers requires large amounts of in-domain paired data. This hinders the development of conversational dense retrievers, as abundant in-domain conversations are expensive to collect. In this paper, we propose CONVERSER, a framework for training conversational dense retrievers with at most 6 examples of in-domain dialogues. Specifically, we utilize the in-context learning capability of large language models to generate conversational queries given a passage in the retrieval corpus. Experimental results on conversational retrieval benchmarks OR-QuAC and TREC CAsT 19 show that the proposed CONVERSER achieves comparable performance to fully-supervised models, demonstrating the effectiveness of our proposed framework in few-shot conversational dense retrieval. All source code and generated datasets are available at https://github.com/MiuLab/CONVERSER
On the Local Quadratic Stability of T-S Fuzzy Systems in the Vicinity of the Origin
Sep 13, 2023The main goal of this paper is to introduce new local stability conditions for continuous-time Takagi-Sugeno (T-S) fuzzy systems. These stability conditions are based on linear matrix inequalities (LMIs) in combination with quadratic Lyapunov functions. Moreover, they integrate information on the membership functions at the origin and effectively leverage the linear structure of the underlying nonlinear system in the vicinity of the origin. As a result, the proposed conditions are proved to be less conservative compared to existing methods using fuzzy Lyapunov functions in the literature. Moreover, we establish that the proposed methods offer necessary and sufficient conditions for the local exponential stability of T-S fuzzy systems. The paper also includes discussions on the inherent limitations associated with fuzzy Lyapunov approaches. To demonstrate the theoretical results, we provide comprehensive examples that elucidate the core concepts and validate the efficacy of the proposed conditions.
Zero-Shot Visual Classification with Guided Cropping
Sep 12, 2023Pretrained vision-language models, such as CLIP, show promising zero-shot performance across a wide variety of datasets. For closed-set classification tasks, however, there is an inherent limitation: CLIP image encoders are typically designed to extract generic image-level features that summarize superfluous or confounding information for the target tasks. This results in degradation of classification performance, especially when objects of interest cover small areas of input images. In this work, we propose CLIP with Guided Cropping (GC-CLIP), where we use an off-the-shelf zero-shot object detection model in a preprocessing step to increase focus of zero-shot classifier to the object of interest and minimize influence of extraneous image regions. We empirically show that our approach improves zero-shot classification results across architectures and datasets, favorably for small objects.
Goal Space Abstraction in Hierarchical Reinforcement Learning via Reachability Analysis
Sep 12, 2023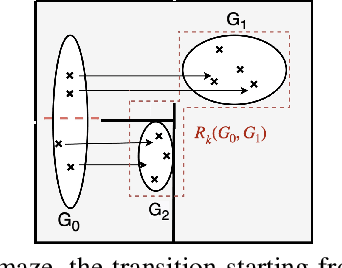
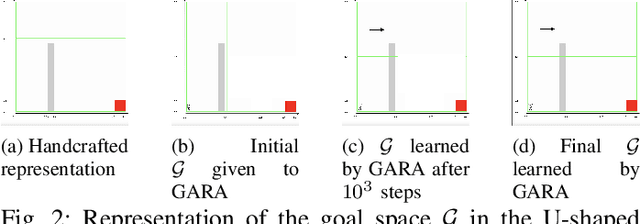
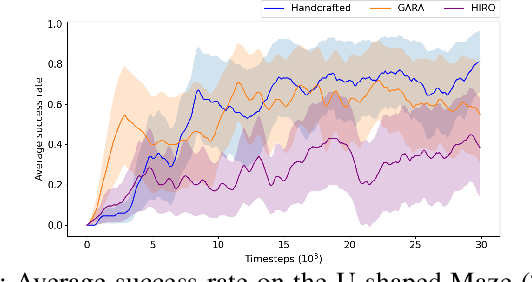
Open-ended learning benefits immensely from the use of symbolic methods for goal representation as they offer ways to structure knowledge for efficient and transferable learning. However, the existing Hierarchical Reinforcement Learning (HRL) approaches relying on symbolic reasoning are often limited as they require a manual goal representation. The challenge in autonomously discovering a symbolic goal representation is that it must preserve critical information, such as the environment dynamics. In this work, we propose a developmental mechanism for subgoal discovery via an emergent representation that abstracts (i.e., groups together) sets of environment states that have similar roles in the task. We create a HRL algorithm that gradually learns this representation along with the policies and evaluate it on navigation tasks to show the learned representation is interpretable and results in data efficiency.
Gradient-Based Feature Learning under Structured Data
Sep 07, 2023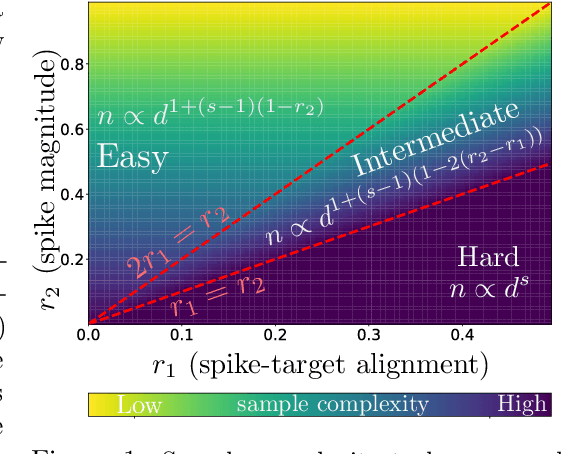
Recent works have demonstrated that the sample complexity of gradient-based learning of single index models, i.e. functions that depend on a 1-dimensional projection of the input data, is governed by their information exponent. However, these results are only concerned with isotropic data, while in practice the input often contains additional structure which can implicitly guide the algorithm. In this work, we investigate the effect of a spiked covariance structure and reveal several interesting phenomena. First, we show that in the anisotropic setting, the commonly used spherical gradient dynamics may fail to recover the true direction, even when the spike is perfectly aligned with the target direction. Next, we show that appropriate weight normalization that is reminiscent of batch normalization can alleviate this issue. Further, by exploiting the alignment between the (spiked) input covariance and the target, we obtain improved sample complexity compared to the isotropic case. In particular, under the spiked model with a suitably large spike, the sample complexity of gradient-based training can be made independent of the information exponent while also outperforming lower bounds for rotationally invariant kernel methods.
TSI-Net: A Timing Sequence Image Segmentation Network for Intracranial Artery Segmentation in Digital Subtraction Angiography
Sep 07, 2023Cerebrovascular disease is one of the major diseases facing the world today. Automatic segmentation of intracranial artery (IA) in digital subtraction angiography (DSA) sequences is an important step in the diagnosis of vascular related diseases and in guiding neurointerventional procedures. While, a single image can only show part of the IA within the contrast medium according to the imaging principle of DSA technology. Therefore, 2D DSA segmentation methods are unable to capture the complete IA information and treatment of cerebrovascular diseases. We propose A timing sequence image segmentation network with U-shape, called TSI-Net, which incorporates a bi-directional ConvGRU module (BCM) in the encoder. The network incorporates a bi-directional ConvGRU module (BCM) in the encoder, which can input variable-length DSA sequences, retain past and future information, segment them into 2D images. In addition, we introduce a sensitive detail branch (SDB) at the end for supervising fine vessels. Experimented on the DSA sequence dataset DIAS, the method performs significantly better than state-of-the-art networks in recent years. In particular, it achieves a Sen evaluation metric of 0.797, which is a 3% improvement compared to other methods.
T2IW: Joint Text to Image & Watermark Generation
Sep 07, 2023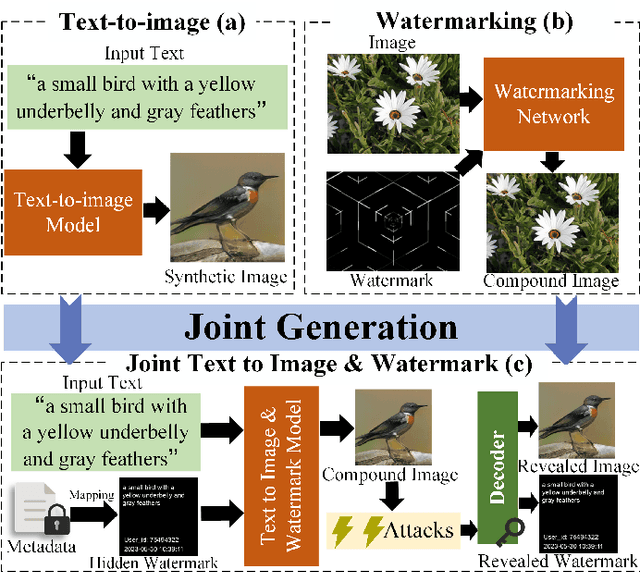

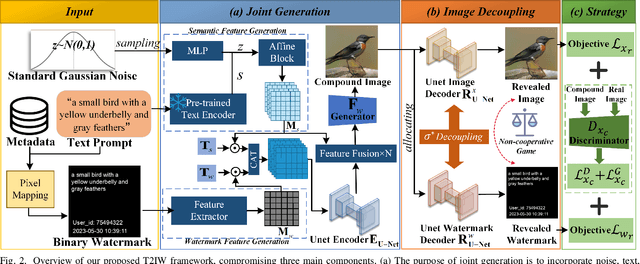
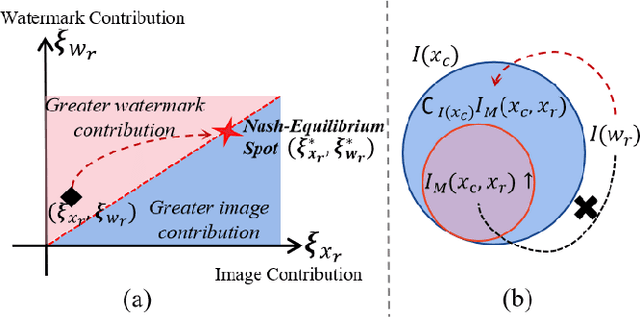
Recent developments in text-conditioned image generative models have revolutionized the production of realistic results. Unfortunately, this has also led to an increase in privacy violations and the spread of false information, which requires the need for traceability, privacy protection, and other security measures. However, existing text-to-image paradigms lack the technical capabilities to link traceable messages with image generation. In this study, we introduce a novel task for the joint generation of text to image and watermark (T2IW). This T2IW scheme ensures minimal damage to image quality when generating a compound image by forcing the semantic feature and the watermark signal to be compatible in pixels. Additionally, by utilizing principles from Shannon information theory and non-cooperative game theory, we are able to separate the revealed image and the revealed watermark from the compound image. Furthermore, we strengthen the watermark robustness of our approach by subjecting the compound image to various post-processing attacks, with minimal pixel distortion observed in the revealed watermark. Extensive experiments have demonstrated remarkable achievements in image quality, watermark invisibility, and watermark robustness, supported by our proposed set of evaluation metrics.
Behind Recommender Systems: the Geography of the ACM RecSys Community
Sep 07, 2023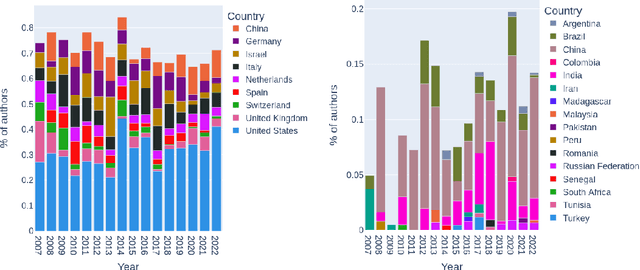
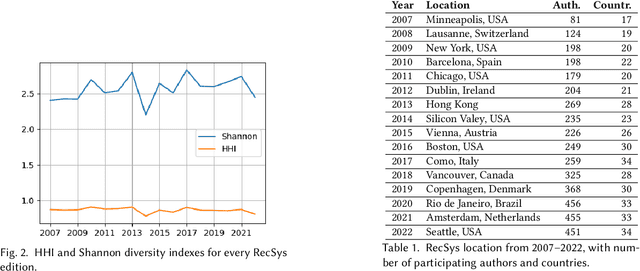
The amount and dissemination rate of media content accessible online is nowadays overwhelming. Recommender Systems filter this information into manageable streams or feeds, adapted to our personal needs or preferences. It is of utter importance that algorithms employed to filter information do not distort or cut out important elements from our perspectives of the world. Under this principle, it is essential to involve diverse views and teams from the earliest stages of their design and development. This has been highlighted, for instance, in recent European Union regulations such as the Digital Services Act, via the requirement of risk monitoring, including the risk of discrimination, and the AI Act, through the requirement to involve people with diverse backgrounds in the development of AI systems. We look into the geographic diversity of the recommender systems research community, specifically by analyzing the affiliation countries of the authors who contributed to the ACM Conference on Recommender Systems (RecSys) during the last 15 years. This study has been carried out in the framework of the Diversity in AI - DivinAI project, whose main objective is the long-term monitoring of diversity in AI forums through a set of indexes.