 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Probabilistic Differentiable Filters Enable Ubiquitous Robot Control with Smartwatches
Sep 12, 2023
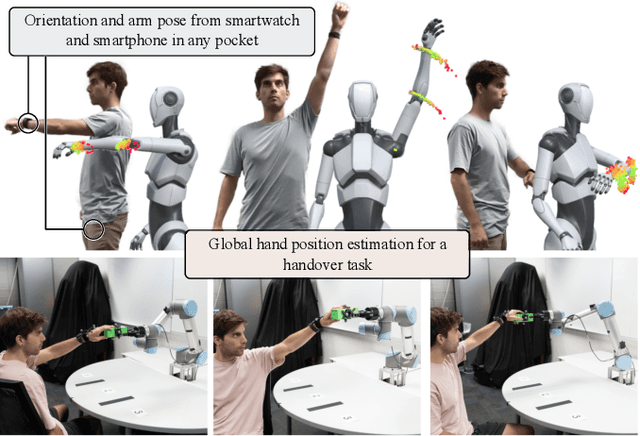
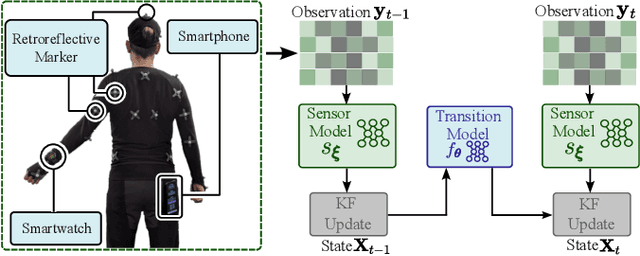
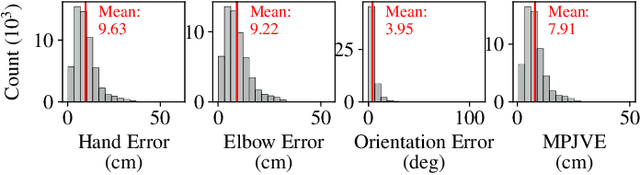
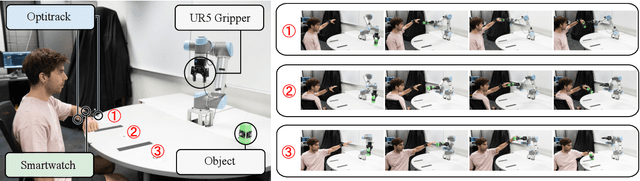
Ubiquitous robot control and human-robot collaboration using smart devices poses a challenging problem primarily due to strict accuracy requirements and sparse information. This paper presents a novel approach that incorporates a probabilistic differentiable filter, specifically the Differentiable Ensemble Kalman Filter (DEnKF), to facilitate robot control solely using Inertial Measurement Units (IMUs) observations from a smartwatch and a smartphone. The implemented system achieves accurate estimation of human pose state with a reduction of 30.2% compared to the baseline using the Mean Per Joint Vertex Error (MPJVE). Our results foster smartwatches and smartphones as a cost-effective alternative human-pose state estimation. Furthermore, experiment results from human-robot handover tasks underscore that smart devices allow for low-cost, versatile and ubiquitous robot control.
Domain-Aware Augmentations for Unsupervised Online General Continual Learning
Sep 13, 2023Continual Learning has been challenging, especially when dealing with unsupervised scenarios such as Unsupervised Online General Continual Learning (UOGCL), where the learning agent has no prior knowledge of class boundaries or task change information. While previous research has focused on reducing forgetting in supervised setups, recent studies have shown that self-supervised learners are more resilient to forgetting. This paper proposes a novel approach that enhances memory usage for contrastive learning in UOGCL by defining and using stream-dependent data augmentations together with some implementation tricks. Our proposed method is simple yet effective, achieves state-of-the-art results compared to other unsupervised approaches in all considered setups, and reduces the gap between supervised and unsupervised continual learning. Our domain-aware augmentation procedure can be adapted to other replay-based methods, making it a promising strategy for continual learning.
Multi-Robot Informative Path Planning from Regression with Sparse Gaussian Processes
Sep 13, 2023
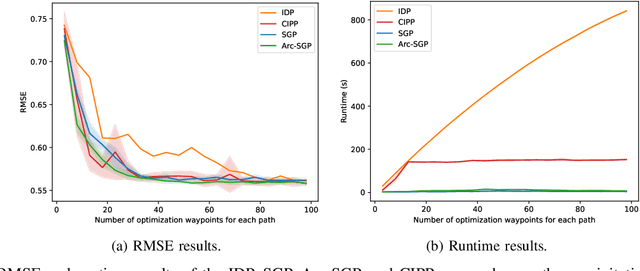
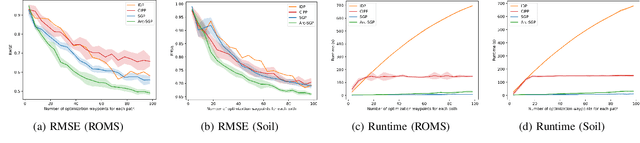
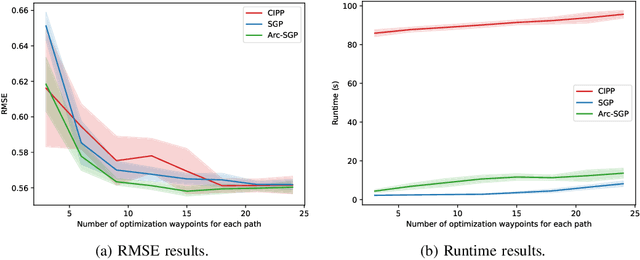
This paper addresses multi-robot informative path planning (IPP) for environmental monitoring. The problem involves determining informative regions in the environment that should be visited by robots in order to gather the most information about the environment. We propose an efficient sparse Gaussian process-based approach that uses gradient descent to optimize paths in continuous environments. Our approach efficiently scales to both spatially and spatio-temporally correlated environments. Moreover, our approach can simultaneously optimize the informative paths while accounting for routing constraints, such as a distance budget and limits on the robot's velocity and acceleration. Our approach can be used for IPP with both discrete and continuous sensing robots, with point and non-point field-of-view sensing shapes, and for multi-robot IPP. The proposed approach is demonstrated to be fast and accurate on real-world data.
LMBiS-Net: A Lightweight Multipath Bidirectional Skip Connection based CNN for Retinal Blood Vessel Segmentation
Sep 10, 2023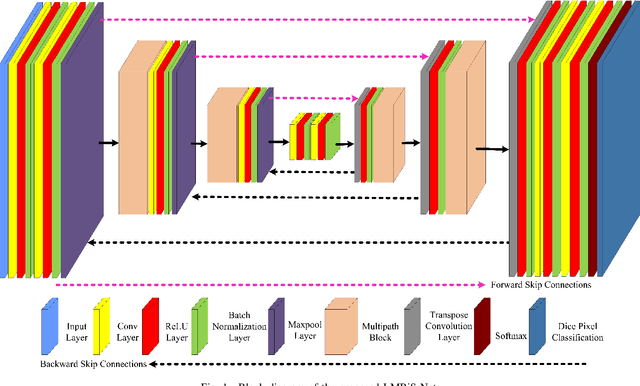
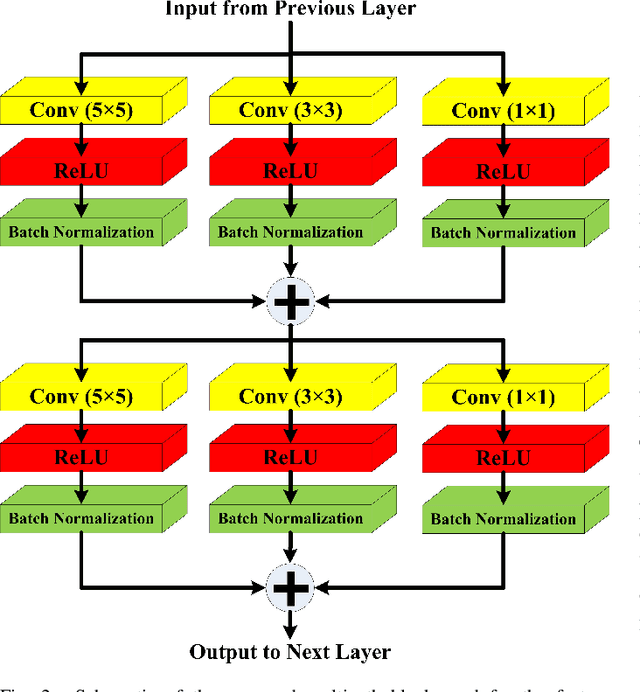
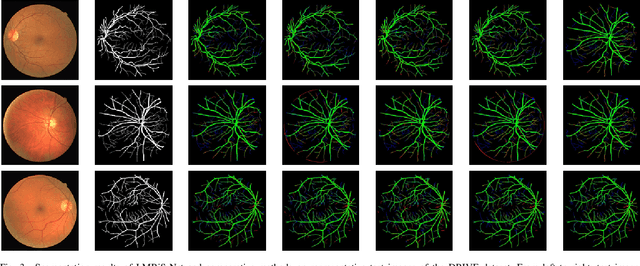
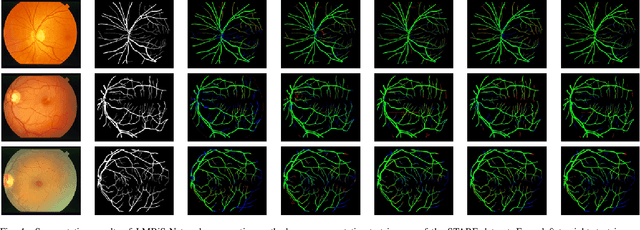
Blinding eye diseases are often correlated with altered retinal morphology, which can be clinically identified by segmenting retinal structures in fundus images. However, current methodologies often fall short in accurately segmenting delicate vessels. Although deep learning has shown promise in medical image segmentation, its reliance on repeated convolution and pooling operations can hinder the representation of edge information, ultimately limiting overall segmentation accuracy. In this paper, we propose a lightweight pixel-level CNN named LMBiS-Net for the segmentation of retinal vessels with an exceptionally low number of learnable parameters \textbf{(only 0.172 M)}. The network used multipath feature extraction blocks and incorporates bidirectional skip connections for the information flow between the encoder and decoder. Additionally, we have optimized the efficiency of the model by carefully selecting the number of filters to avoid filter overlap. This optimization significantly reduces training time and enhances computational efficiency. To assess the robustness and generalizability of LMBiS-Net, we performed comprehensive evaluations on various aspects of retinal images. Specifically, the model was subjected to rigorous tests to accurately segment retinal vessels, which play a vital role in ophthalmological diagnosis and treatment. By focusing on the retinal blood vessels, we were able to thoroughly analyze the performance and effectiveness of the LMBiS-Net model. The results of our tests demonstrate that LMBiS-Net is not only robust and generalizable but also capable of maintaining high levels of segmentation accuracy. These characteristics highlight the potential of LMBiS-Net as an efficient tool for high-speed and accurate segmentation of retinal images in various clinical applications.
Efficient Low-Rank GNN Defense Against Structural Attacks
Sep 18, 2023Graph Neural Networks (GNNs) have been shown to possess strong representation abilities over graph data. However, GNNs are vulnerable to adversarial attacks, and even minor perturbations to the graph structure can significantly degrade their performance. Existing methods either are ineffective against sophisticated attacks or require the optimization of dense adjacency matrices, which is time-consuming and prone to local minima. To remedy this problem, we propose an Efficient Low-Rank Graph Neural Network (ELR-GNN) defense method, which aims to learn low-rank and sparse graph structures for defending against adversarial attacks, ensuring effective defense with greater efficiency. Specifically, ELR-GNN consists of two modules: a Coarse Low-Rank Estimation Module and a Fine-Grained Estimation Module. The first module adopts the truncated Singular Value Decomposition (SVD) to initialize the low-rank adjacency matrix estimation, which serves as a starting point for optimizing the low-rank matrix. In the second module, the initial estimate is refined by jointly learning a low-rank sparse graph structure with the GNN model. Sparsity is incorporated into the learned low-rank adjacency matrix by pruning weak connections, which can reduce redundant data while maintaining valuable information. As a result, instead of using the dense adjacency matrix directly, ELR-GNN can learn a low-rank and sparse estimate of it in a simple, efficient and easy to optimize manner. The experimental results demonstrate that ELR-GNN outperforms the state-of-the-art GNN defense methods in the literature, in addition to being very efficient and easy to train.
Toward collision-free trajectory for autonomous and pilot-controlled unmanned aerial vehicles
Sep 18, 2023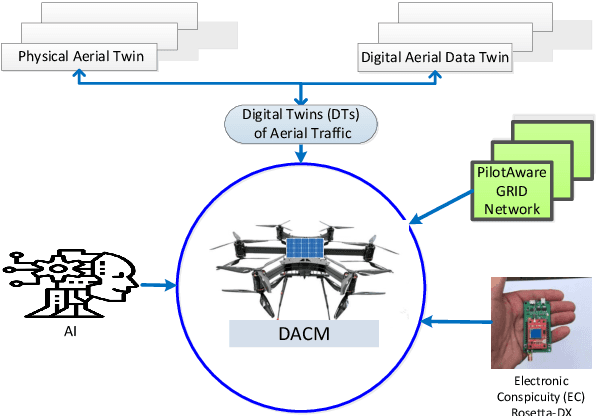
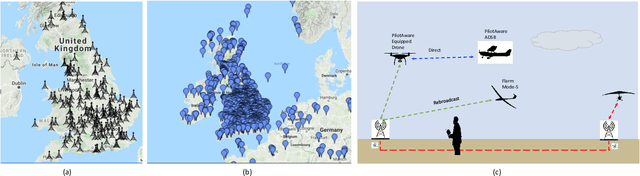


For drones, as safety-critical systems, there is an increasing need for onboard detect & avoid (DAA) technology i) to see, sense or detect conflicting traffic or imminent non-cooperative threats due to their high mobility with multiple degrees of freedom and the complexity of deployed unstructured environments, and subsequently ii) to take the appropriate actions to avoid collisions depending upon the level of autonomy. The safe and efficient integration of UAV traffic management (UTM) systems with air traffic management (ATM) systems, using intelligent autonomous approaches, is an emerging requirement where the number of diverse UAV applications is increasing on a large scale in dense air traffic environments for completing swarms of multiple complex missions flexibly and simultaneously. Significant progress over the past few years has been made in detecting UAVs present in aerospace, identifying them, and determining their existing flight path. This study makes greater use of electronic conspicuity (EC) information made available by PilotAware Ltd in developing an advanced collision management methodology -- Drone Aware Collision Management (DACM) -- capable of determining and executing a variety of time-optimal evasive collision avoidance (CA) manoeuvres using a reactive geometric conflict detection and resolution (CDR) technique. The merits of the DACM methodology have been demonstrated through extensive simulations and real-world field tests in avoiding mid-air collisions (MAC) between UAVs and manned aeroplanes. The results show that the proposed methodology can be employed successfully in avoiding collisions while limiting the deviation from the original trajectory in highly dynamic aerospace without requiring sophisticated sensors and prior training.
Selecting which Dense Retriever to use for Zero-Shot Search
Sep 18, 2023We propose the new problem of choosing which dense retrieval model to use when searching on a new collection for which no labels are available, i.e. in a zero-shot setting. Many dense retrieval models are readily available. Each model however is characterized by very differing search effectiveness -- not just on the test portion of the datasets in which the dense representations have been learned but, importantly, also across different datasets for which data was not used to learn the dense representations. This is because dense retrievers typically require training on a large amount of labeled data to achieve satisfactory search effectiveness in a specific dataset or domain. Moreover, effectiveness gains obtained by dense retrievers on datasets for which they are able to observe labels during training, do not necessarily generalise to datasets that have not been observed during training. This is however a hard problem: through empirical experimentation we show that methods inspired by recent work in unsupervised performance evaluation with the presence of domain shift in the area of computer vision and machine learning are not effective for choosing highly performing dense retrievers in our setup. The availability of reliable methods for the selection of dense retrieval models in zero-shot settings that do not require the collection of labels for evaluation would allow to streamline the widespread adoption of dense retrieval. This is therefore an important new problem we believe the information retrieval community should consider. Implementation of methods, along with raw result files and analysis scripts are made publicly available at https://www.github.com/anonymized.
Is Learning in Biological Neural Networks based on Stochastic Gradient Descent? An analysis using stochastic processes
Sep 10, 2023In recent years, there has been an intense debate about how learning in biological neural networks (BNNs) differs from learning in artificial neural networks. It is often argued that the updating of connections in the brain relies only on local information, and therefore a stochastic gradient-descent type optimization method cannot be used. In this paper, we study a stochastic model for supervised learning in BNNs. We show that a (continuous) gradient step occurs approximately when each learning opportunity is processed by many local updates. This result suggests that stochastic gradient descent may indeed play a role in optimizing BNNs.
Multi-camera Bird's Eye View Perception for Autonomous Driving
Sep 19, 2023
Most automated driving systems comprise a diverse sensor set, including several cameras, Radars, and LiDARs, ensuring a complete 360\deg coverage in near and far regions. Unlike Radar and LiDAR, which measure directly in 3D, cameras capture a 2D perspective projection with inherent depth ambiguity. However, it is essential to produce perception outputs in 3D to enable the spatial reasoning of other agents and structures for optimal path planning. The 3D space is typically simplified to the BEV space by omitting the less relevant Z-coordinate, which corresponds to the height dimension.The most basic approach to achieving the desired BEV representation from a camera image is IPM, assuming a flat ground surface. Surround vision systems that are pretty common in new vehicles use the IPM principle to generate a BEV image and to show it on display to the driver. However, this approach is not suited for autonomous driving since there are severe distortions introduced by this too-simplistic transformation method. More recent approaches use deep neural networks to output directly in BEV space. These methods transform camera images into BEV space using geometric constraints implicitly or explicitly in the network. As CNN has more context information and a learnable transformation can be more flexible and adapt to image content, the deep learning-based methods set the new benchmark for BEV transformation and achieve state-of-the-art performance. First, this chapter discusses the contemporary trends of multi-camera-based DNN (deep neural network) models outputting object representations directly in the BEV space. Then, we discuss how this approach can extend to effective sensor fusion and coupling downstream tasks like situation analysis and prediction. Finally, we show challenges and open problems in BEV perception.
Adaptive Generation of Privileged Intermediate Information for Visible-Infrared Person Re-Identification
Jul 06, 2023Visible-infrared person re-identification seeks to retrieve images of the same individual captured over a distributed network of RGB and IR sensors. Several V-I ReID approaches directly integrate both V and I modalities to discriminate persons within a shared representation space. However, given the significant gap in data distributions between V and I modalities, cross-modal V-I ReID remains challenging. Some recent approaches improve generalization by leveraging intermediate spaces that can bridge V and I modalities, yet effective methods are required to select or generate data for such informative domains. In this paper, the Adaptive Generation of Privileged Intermediate Information training approach is introduced to adapt and generate a virtual domain that bridges discriminant information between the V and I modalities. The key motivation behind AGPI^2 is to enhance the training of a deep V-I ReID backbone by generating privileged images that provide additional information. These privileged images capture shared discriminative features that are not easily accessible within the original V or I modalities alone. Towards this goal, a non-linear generative module is trained with an adversarial objective, translating V images into intermediate spaces with a smaller domain shift w.r.t. the I domain. Meanwhile, the embedding module within AGPI^2 aims to produce similar features for both V and generated images, encouraging the extraction of features that are common to all modalities. In addition to these contributions, AGPI^2 employs adversarial objectives for adapting the intermediate images, which play a crucial role in creating a non-modality-specific space to address the large domain shifts between V and I domains. Experimental results conducted on challenging V-I ReID datasets indicate that AGPI^2 increases matching accuracy without extra computational resources during inference.