 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Vulnerability of 3D Face Recognition Systems to Morphing Attacks
Sep 21, 2023

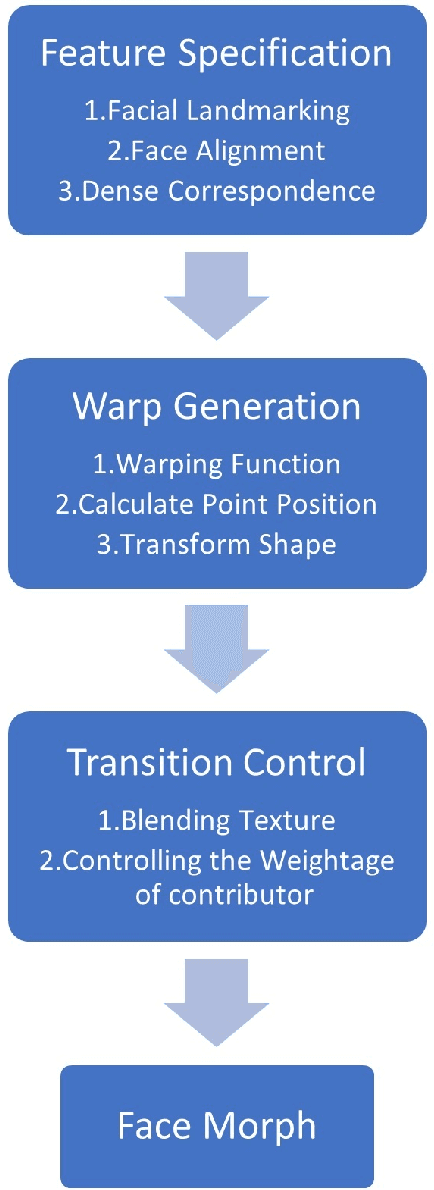


In recent years face recognition systems have been brought to the mainstream due to development in hardware and software. Consistent efforts are being made to make them better and more secure. This has also brought developments in 3D face recognition systems at a rapid pace. These 3DFR systems are expected to overcome certain vulnerabilities of 2DFR systems. One such problem that the domain of 2DFR systems face is face image morphing. A substantial amount of research is being done for generation of high quality face morphs along with detection of attacks from these morphs. Comparatively the understanding of vulnerability of 3DFR systems against 3D face morphs is less. But at the same time an expectation is set from 3DFR systems to be more robust against such attacks. This paper attempts to research and gain more information on this matter. The paper describes a couple of methods that can be used to generate 3D face morphs. The face morphs that are generated using this method are then compared to the contributing faces to obtain similarity scores. The highest MMPMR is obtained around 40% with RMMR of 41.76% when 3DFRS are attacked with look-a-like morphs.
Bridging the Gap: Learning Pace Synchronization for Open-World Semi-Supervised Learning
Sep 21, 2023In open-world semi-supervised learning, a machine learning model is tasked with uncovering novel categories from unlabeled data while maintaining performance on seen categories from labeled data. The central challenge is the substantial learning gap between seen and novel categories, as the model learns the former faster due to accurate supervisory information. To address this, we introduce 1) an adaptive margin loss based on estimated class distribution, which encourages a large negative margin for samples in seen classes, to synchronize learning paces, and 2) pseudo-label contrastive clustering, which pulls together samples which are likely from the same class in the output space, to enhance novel class discovery. Our extensive evaluations on multiple datasets demonstrate that existing models still hinder novel class learning, whereas our approach strikingly balances both seen and novel classes, achieving a remarkable 3% average accuracy increase on the ImageNet dataset compared to the prior state-of-the-art. Additionally, we find that fine-tuning the self-supervised pre-trained backbone significantly boosts performance over the default in prior literature. After our paper is accepted, we will release the code.
BitCoin: Bidirectional Tagging and Supervised Contrastive Learning based Joint Relational Triple Extraction Framework
Sep 21, 2023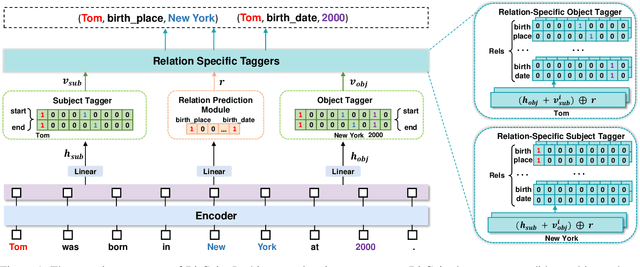
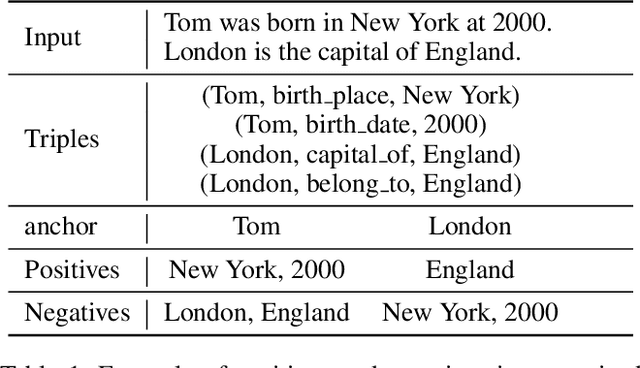

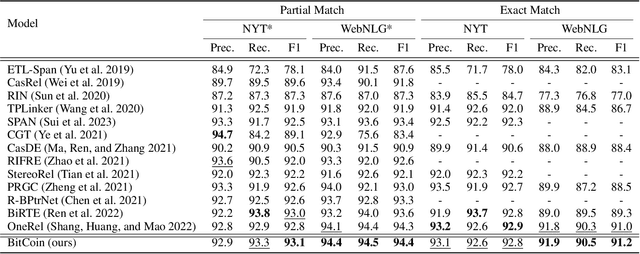
Relation triple extraction (RTE) is an essential task in information extraction and knowledge graph construction. Despite recent advancements, existing methods still exhibit certain limitations. They just employ generalized pre-trained models and do not consider the specificity of RTE tasks. Moreover, existing tagging-based approaches typically decompose the RTE task into two subtasks, initially identifying subjects and subsequently identifying objects and relations. They solely focus on extracting relational triples from subject to object, neglecting that once the extraction of a subject fails, it fails in extracting all triples associated with that subject. To address these issues, we propose BitCoin, an innovative Bidirectional tagging and supervised Contrastive learning based joint relational triple extraction framework. Specifically, we design a supervised contrastive learning method that considers multiple positives per anchor rather than restricting it to just one positive. Furthermore, a penalty term is introduced to prevent excessive similarity between the subject and object. Our framework implements taggers in two directions, enabling triples extraction from subject to object and object to subject. Experimental results show that BitCoin achieves state-of-the-art results on the benchmark datasets and significantly improves the F1 score on Normal, SEO, EPO, and multiple relation extraction tasks.
Resource Allocation for Semantic-Aware Mobile Edge Computing Systems
Sep 21, 2023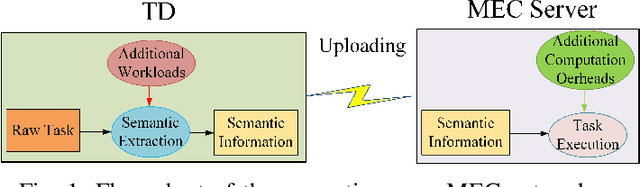
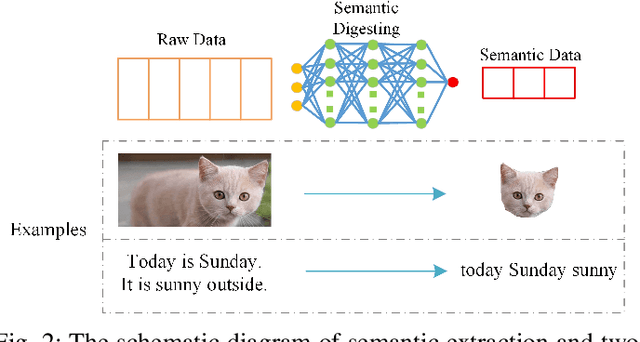
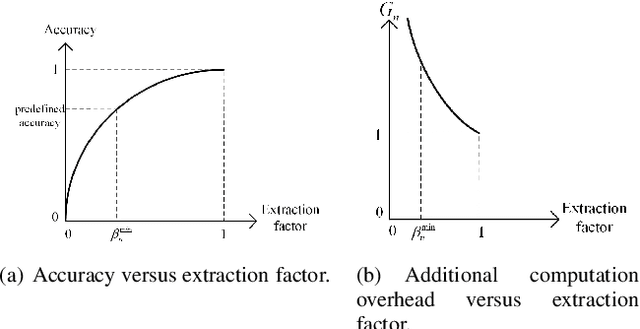
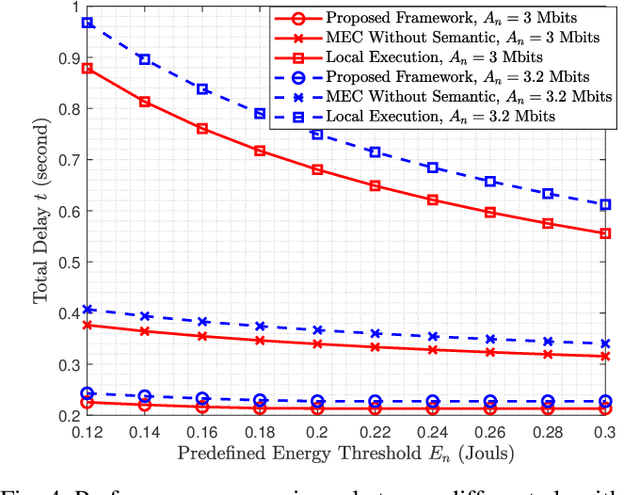
In this paper, a semantic-aware joint communication and computation resource allocation framework is proposed for mobile edge computing (MEC) systems. In the considered system, each terminal device (TD) has a computation task, which needs to be executed by offloading to the MEC server. To further decrease the transmission burden, each TD sends the small-size extracted semantic information of tasks to the server instead of the large-size raw data. An optimization problem of joint semantic-aware division factor, communication and computation resource management is formulated. The problem aims to minimize the maximum execution delay of all TDs while satisfying energy consumption constraints. The original non-convex problem is transformed into a convex one based on the geometric programming and the optimal solution is obtained by the alternating optimization algorithm. Moreover, the closed-form optimal solution of the semantic extraction factor is derived. Simulation results show that the proposed algorithm yields up to 37.10% delay reduction compared with the benchmark algorithm without semantic-aware allocation. Furthermore, small semantic extraction factors are preferred in the case of large task sizes and poor channel conditions.
Fast Satellite Tensorial Radiance Field for Multi-date Satellite Imagery of Large Size
Sep 21, 2023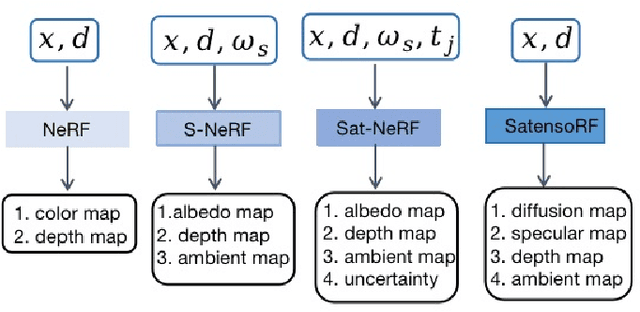
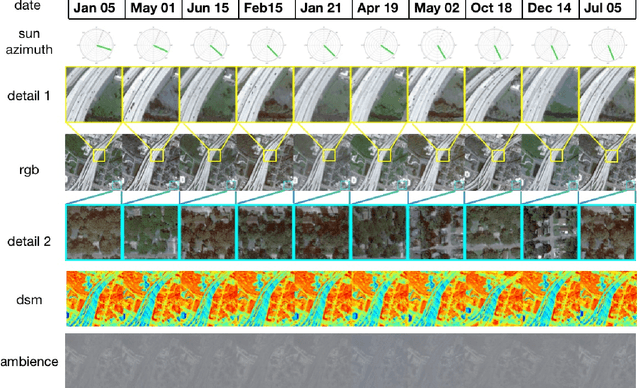

Existing NeRF models for satellite images suffer from slow speeds, mandatory solar information as input, and limitations in handling large satellite images. In response, we present SatensoRF, which significantly accelerates the entire process while employing fewer parameters for satellite imagery of large size. Besides, we observed that the prevalent assumption of Lambertian surfaces in neural radiance fields falls short for vegetative and aquatic elements. In contrast to the traditional hierarchical MLP-based scene representation, we have chosen a multiscale tensor decomposition approach for color, volume density, and auxiliary variables to model the lightfield with specular color. Additionally, to rectify inconsistencies in multi-date imagery, we incorporate total variation loss to restore the density tensor field and treat the problem as a denosing task.To validate our approach, we conducted assessments of SatensoRF using subsets from the spacenet multi-view dataset, which includes both multi-date and single-date multi-view RGB images. Our results clearly demonstrate that SatensoRF surpasses the state-of-the-art Sat-NeRF series in terms of novel view synthesis performance. Significantly, SatensoRF requires fewer parameters for training, resulting in faster training and inference speeds and reduced computational demands.
Gaining Insights into Denoising by Inpainting
Sep 23, 2023The filling-in effect of diffusion processes is a powerful tool for various image analysis tasks such as inpainting-based compression and dense optic flow computation. For noisy data, an interesting side effect occurs: The interpolated data have higher confidence, since they average information from many noisy sources. This observation forms the basis of our denoising by inpainting (DbI) framework. It averages multiple inpainting results from different noisy subsets. Our goal is to obtain fundamental insights into key properties of DbI and its connections to existing methods. Like in inpainting-based image compression, we choose homogeneous diffusion as a very simple inpainting operator that performs well for highly optimized data. We propose several strategies to choose the location of the selected pixels. Moreover, to improve the global approximation quality further, we also allow to change the function values of the noisy pixels. In contrast to traditional denoising methods that adapt the operator to the data, our approach adapts the data to the operator. Experimentally we show that replacing homogeneous diffusion inpainting by biharmonic inpainting does not improve the reconstruction quality. This again emphasizes the importance of data adaptivity over operator adaptivity. On the foundational side, we establish deterministic and probabilistic theories with convergence estimates. In the non-adaptive 1-D case, we derive equivalence results between DbI on shifted regular grids and classical homogeneous diffusion filtering via an explicit relation between the density and the diffusion time.
A Survey on Image-text Multimodal Models
Sep 23, 2023Amidst the evolving landscape of artificial intelligence, the convergence of visual and textual information has surfaced as a crucial frontier, leading to the advent of image-text multimodal models. This paper provides a comprehensive review of the evolution and current state of image-text multimodal models, exploring their application value, challenges, and potential research trajectories. Initially, we revisit the basic concepts and developmental milestones of these models, introducing a novel classification that segments their evolution into three distinct phases, based on their time of introduction and subsequent impact on the discipline. Furthermore, based on the tasks' significance and prevalence in the academic landscape, we propose a categorization of the tasks associated with image-text multimodal models into five major types, elucidating the recent progress and key technologies within each category. Despite the remarkable accomplishments of these models, numerous challenges and issues persist. This paper delves into the inherent challenges and limitations of image-text multimodal models, fostering the exploration of prospective research directions. Our objective is to offer an exhaustive overview of the present research landscape of image-text multimodal models and to serve as a valuable reference for future scholarly endeavors. We extend an invitation to the broader community to collaborate in enhancing the image-text multimodal model community, accessible at: \href{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}{https://github.com/i2vec/A-survey-on-image-text-multimodal-models}.
Anomalous Sound Detection Using Self-Attention-Based Frequency Pattern Analysis of Machine Sounds
Sep 06, 2023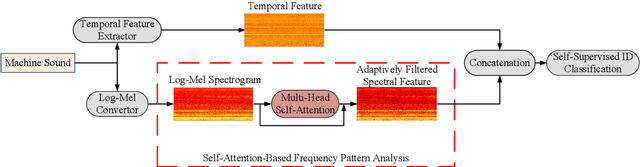

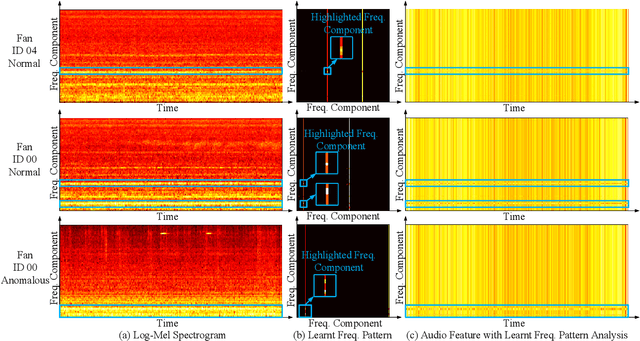
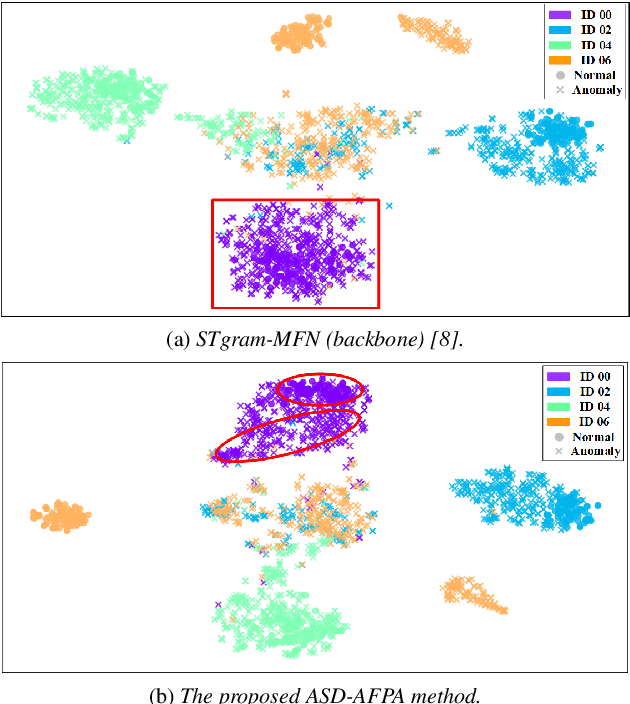
Different machines can exhibit diverse frequency patterns in their emitted sound. This feature has been recently explored in anomaly sound detection and reached state-of-the-art performance. However, existing methods rely on the manual or empirical determination of the frequency filter by observing the effective frequency range in the training data, which may be impractical for general application. This paper proposes an anomalous sound detection method using self-attention-based frequency pattern analysis and spectral-temporal information fusion. Our experiments demonstrate that the self-attention module automatically and adaptively analyses the effective frequencies of a machine sound and enhances that information in the spectral feature representation. With spectral-temporal information fusion, the obtained audio feature eventually improves the anomaly detection performance on the DCASE 2020 Challenge Task 2 dataset.
Finite-Sample Symmetric Mean Estimation with Fisher Information Rate
Jun 28, 2023
The mean of an unknown variance-$\sigma^2$ distribution $f$ can be estimated from $n$ samples with variance $\frac{\sigma^2}{n}$ and nearly corresponding subgaussian rate. When $f$ is known up to translation, this can be improved asymptotically to $\frac{1}{n\mathcal I}$, where $\mathcal I$ is the Fisher information of the distribution. Such an improvement is not possible for general unknown $f$, but [Stone, 1975] showed that this asymptotic convergence $\textit{is}$ possible if $f$ is $\textit{symmetric}$ about its mean. Stone's bound is asymptotic, however: the $n$ required for convergence depends in an unspecified way on the distribution $f$ and failure probability $\delta$. In this paper we give finite-sample guarantees for symmetric mean estimation in terms of Fisher information. For every $f, n, \delta$ with $n > \log \frac{1}{\delta}$, we get convergence close to a subgaussian with variance $\frac{1}{n \mathcal I_r}$, where $\mathcal I_r$ is the $r$-$\textit{smoothed}$ Fisher information with smoothing radius $r$ that decays polynomially in $n$. Such a bound essentially matches the finite-sample guarantees in the known-$f$ setting.
Phase-Specific Augmented Reality Guidance for Microscopic Cataract Surgery Using Long-Short Spatiotemporal Aggregation Transformer
Sep 11, 2023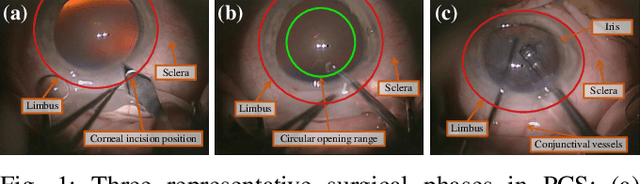
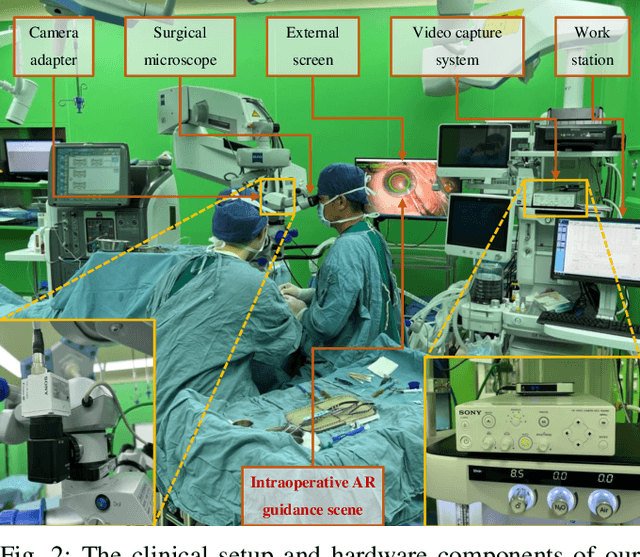
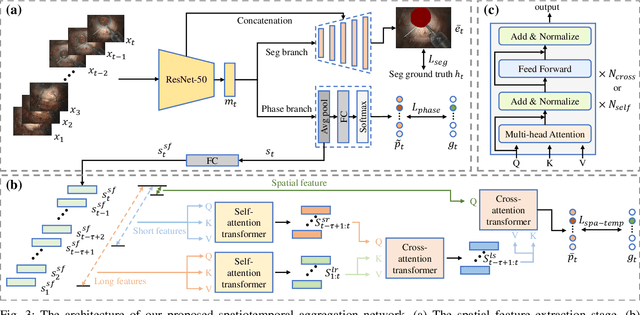
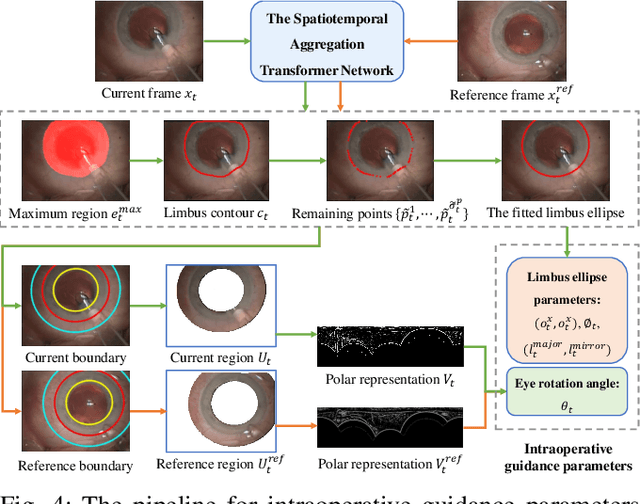
Phacoemulsification cataract surgery (PCS) is a routine procedure conducted using a surgical microscope, heavily reliant on the skill of the ophthalmologist. While existing PCS guidance systems extract valuable information from surgical microscopic videos to enhance intraoperative proficiency, they suffer from non-phasespecific guidance, leading to redundant visual information. In this study, our major contribution is the development of a novel phase-specific augmented reality (AR) guidance system, which offers tailored AR information corresponding to the recognized surgical phase. Leveraging the inherent quasi-standardized nature of PCS procedures, we propose a two-stage surgical microscopic video recognition network. In the first stage, we implement a multi-task learning structure to segment the surgical limbus region and extract limbus region-focused spatial feature for each frame. In the second stage, we propose the long-short spatiotemporal aggregation transformer (LS-SAT) network to model local fine-grained and global temporal relationships, and combine the extracted spatial features to recognize the current surgical phase. Additionally, we collaborate closely with ophthalmologists to design AR visual cues by utilizing techniques such as limbus ellipse fitting and regional restricted normal cross-correlation rotation computation. We evaluated the network on publicly available and in-house datasets, with comparison results demonstrating its superior performance compared to related works. Ablation results further validated the effectiveness of the limbus region-focused spatial feature extractor and the combination of temporal features. Furthermore, the developed system was evaluated in a clinical setup, with results indicating remarkable accuracy and real-time performance. underscoring its potential for clinical applications.