 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Invariant Learning via Probability of Sufficient and Necessary Causes
Sep 22, 2023
Out-of-distribution (OOD) generalization is indispensable for learning models in the wild, where testing distribution typically unknown and different from the training. Recent methods derived from causality have shown great potential in achieving OOD generalization. However, existing methods mainly focus on the invariance property of causes, while largely overlooking the property of \textit{sufficiency} and \textit{necessity} conditions. Namely, a necessary but insufficient cause (feature) is invariant to distribution shift, yet it may not have required accuracy. By contrast, a sufficient yet unnecessary cause (feature) tends to fit specific data well but may have a risk of adapting to a new domain. To capture the information of sufficient and necessary causes, we employ a classical concept, the probability of sufficiency and necessary causes (PNS), which indicates the probability of whether one is the necessary and sufficient cause. To associate PNS with OOD generalization, we propose PNS risk and formulate an algorithm to learn representation with a high PNS value. We theoretically analyze and prove the generalizability of the PNS risk. Experiments on both synthetic and real-world benchmarks demonstrate the effectiveness of the proposed method. The details of the implementation can be found at the GitHub repository: https://github.com/ymy4323460/CaSN.
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 14, 2023
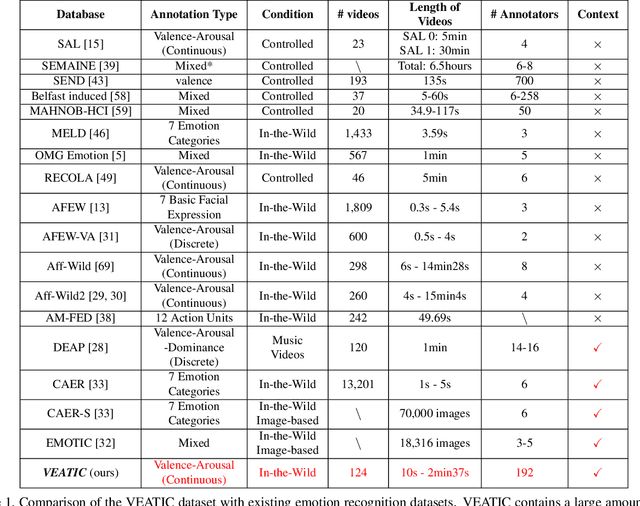

Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.
Road Disease Detection based on Latent Domain Background Feature Separation and Suppression
Sep 14, 2023


Road disease detection is challenging due to the the small proportion of road damage in target region and the diverse background,which introduce lots of domain information.Besides, disease categories have high similarity,makes the detection more difficult. In this paper, we propose a new LDBFSS(Latent Domain Background Feature Separation and Suppression) network which could perform background information separation and suppression without domain supervision and contrastive enhancement of object features.We combine our LDBFSS network with YOLOv5 model to enhance disease features for better road disease detection. As the components of LDBFSS network, we first design a latent domain discovery module and a domain adversarial learning module to obtain pseudo domain labels through unsupervised method, guiding domain discriminator and model to train adversarially to suppress background information. In addition, we introduce a contrastive learning module and design k-instance contrastive loss, optimize the disease feature representation by increasing the inter-class distance and reducing the intra-class distance for object features. We conducted experiments on two road disease detection datasets, GRDDC and CNRDD, and compared with other models,which show an increase of nearly 4% on GRDDC dataset compared with optimal model, and an increase of 4.6% on CNRDD dataset. Experimental results prove the effectiveness and superiority of our model.
Multi-dimensional Fusion and Consistency for Semi-supervised Medical Image Segmentation
Sep 16, 2023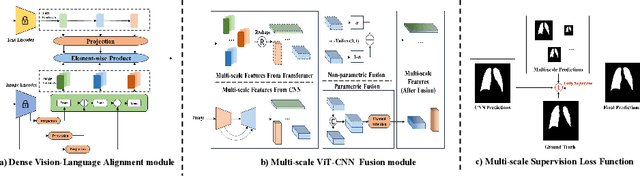
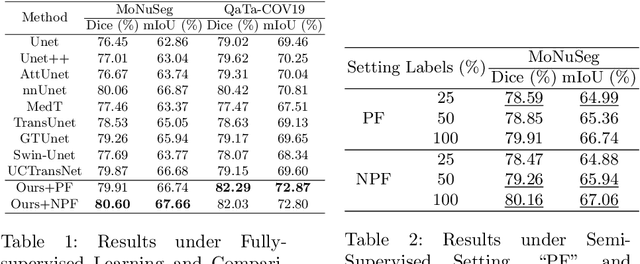
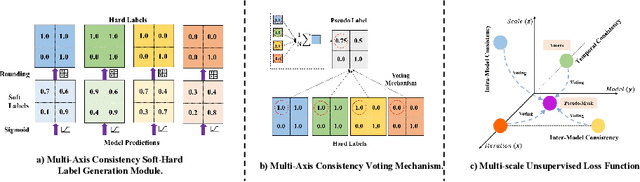
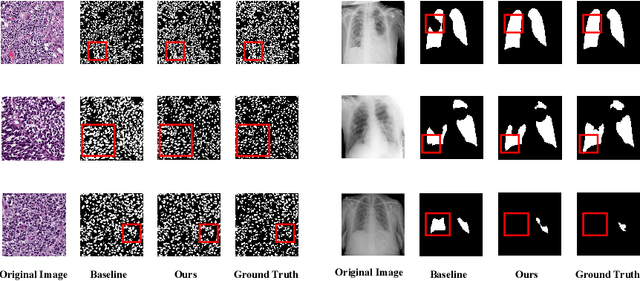
In this paper, we introduce a novel semi-supervised learning framework tailored for medical image segmentation. Central to our approach is the innovative Multi-scale Text-aware ViT-CNN Fusion scheme. This scheme adeptly combines the strengths of both ViTs and CNNs, capitalizing on the unique advantages of both architectures as well as the complementary information in vision-language modalities. Further enriching our framework, we propose the Multi-Axis Consistency framework for generating robust pseudo labels, thereby enhancing the semi-supervised learning process. Our extensive experiments on several widely-used datasets unequivocally demonstrate the efficacy of our approach.
Chasing Day and Night: Towards Robust and Efficient All-Day Object Detection Guided by an Event Camera
Sep 17, 2023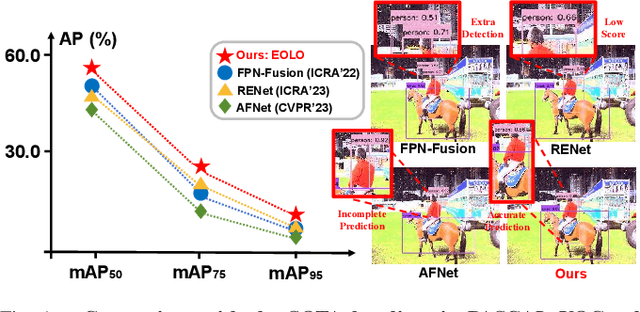
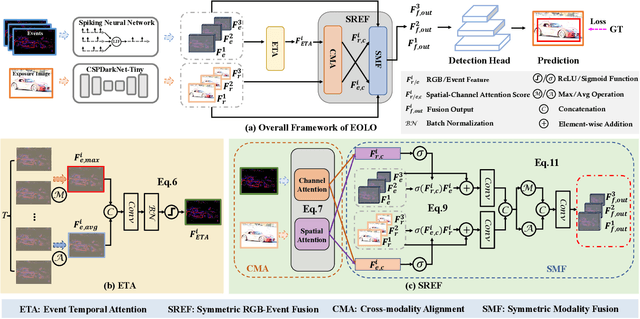
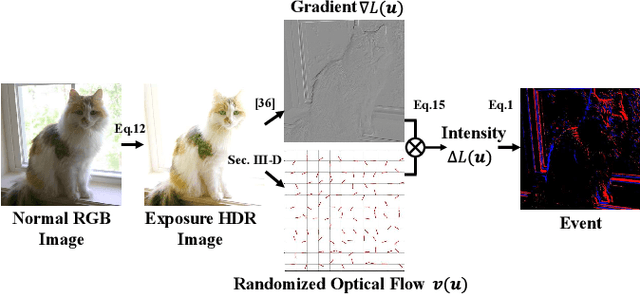

The ability to detect objects in all lighting (i.e., normal-, over-, and under-exposed) conditions is crucial for real-world applications, such as self-driving.Traditional RGB-based detectors often fail under such varying lighting conditions.Therefore, recent works utilize novel event cameras to supplement or guide the RGB modality; however, these methods typically adopt asymmetric network structures that rely predominantly on the RGB modality, resulting in limited robustness for all-day detection. In this paper, we propose EOLO, a novel object detection framework that achieves robust and efficient all-day detection by fusing both RGB and event modalities. Our EOLO framework is built based on a lightweight spiking neural network (SNN) to efficiently leverage the asynchronous property of events. Buttressed by it, we first introduce an Event Temporal Attention (ETA) module to learn the high temporal information from events while preserving crucial edge information. Secondly, as different modalities exhibit varying levels of importance under diverse lighting conditions, we propose a novel Symmetric RGB-Event Fusion (SREF) module to effectively fuse RGB-Event features without relying on a specific modality, thus ensuring a balanced and adaptive fusion for all-day detection. In addition, to compensate for the lack of paired RGB-Event datasets for all-day training and evaluation, we propose an event synthesis approach based on the randomized optical flow that allows for directly generating the event frame from a single exposure image. We further build two new datasets, E-MSCOCO and E-VOC based on the popular benchmarks MSCOCO and PASCAL VOC. Extensive experiments demonstrate that our EOLO outperforms the state-of-the-art detectors,e.g.,RENet,by a substantial margin (+3.74% mAP50) in all lighting conditions.Our code and datasets will be available at https://vlislab22.github.io/EOLO/
A Survey on Privacy in Graph Neural Networks: Attacks, Preservation, and Applications
Sep 19, 2023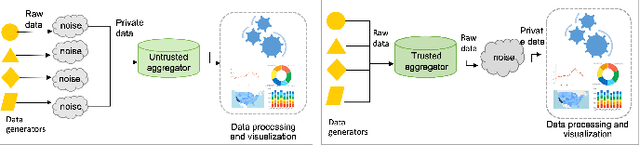
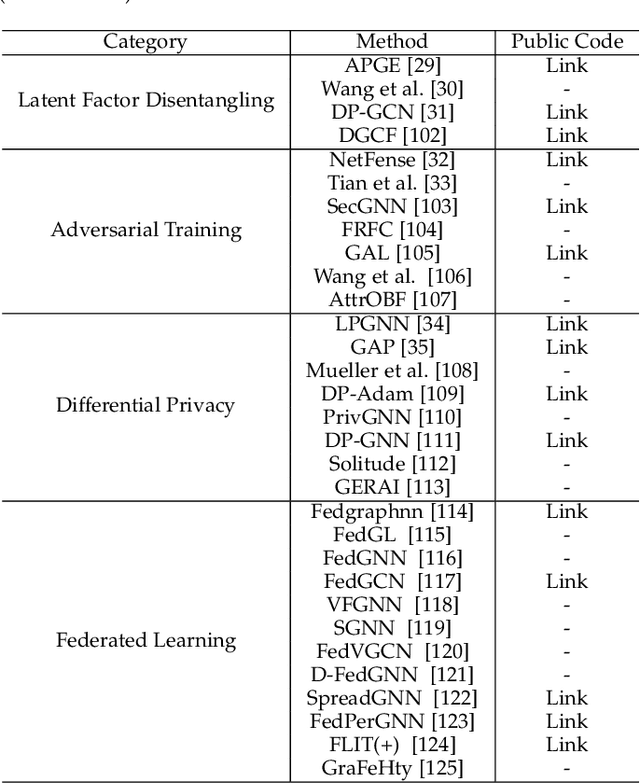

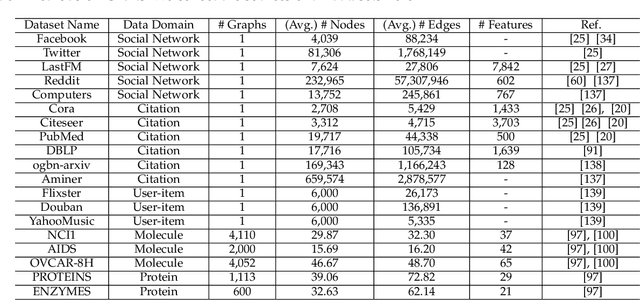
Graph Neural Networks (GNNs) have gained significant attention owing to their ability to handle graph-structured data and the improvement in practical applications. However, many of these models prioritize high utility performance, such as accuracy, with a lack of privacy consideration, which is a major concern in modern society where privacy attacks are rampant. To address this issue, researchers have started to develop privacy-preserving GNNs. Despite this progress, there is a lack of a comprehensive overview of the attacks and the techniques for preserving privacy in the graph domain. In this survey, we aim to address this gap by summarizing the attacks on graph data according to the targeted information, categorizing the privacy preservation techniques in GNNs, and reviewing the datasets and applications that could be used for analyzing/solving privacy issues in GNNs. We also outline potential directions for future research in order to build better privacy-preserving GNNs.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023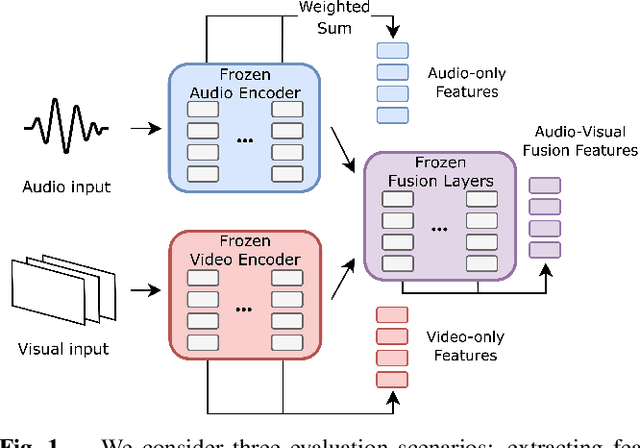
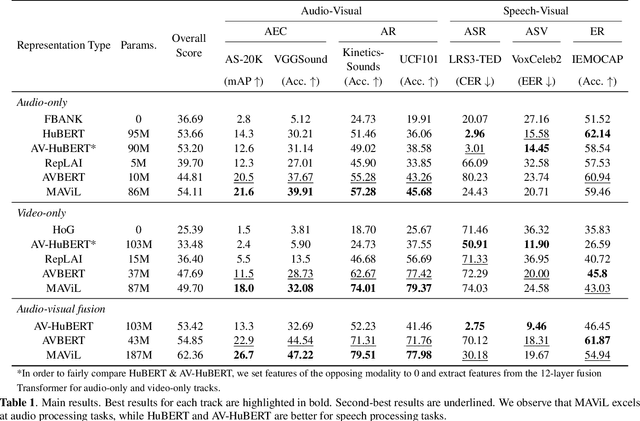
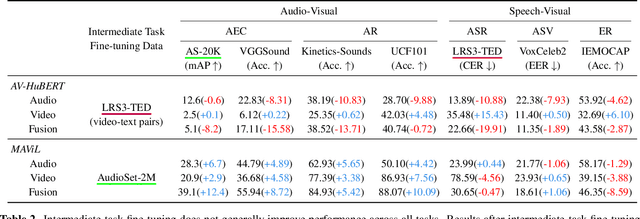
Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023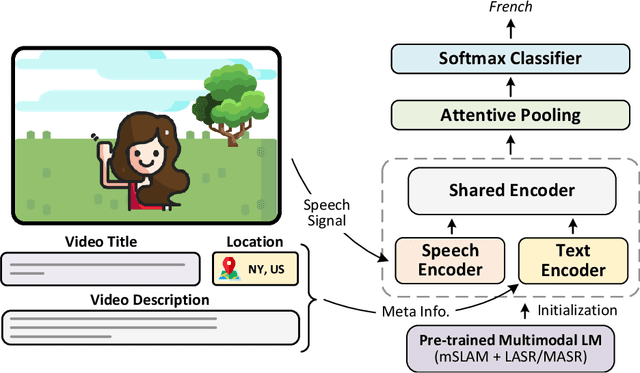
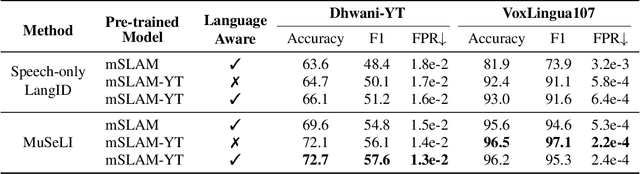
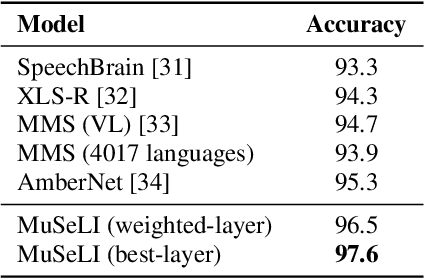
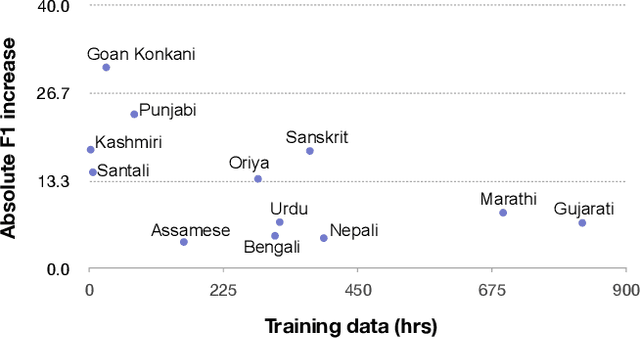
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
Advanced Computing and Related Applications Leveraging Brain-inspired Spiking Neural Networks
Sep 08, 2023In the rapid evolution of next-generation brain-inspired artificial intelligence and increasingly sophisticated electromagnetic environment, the most bionic characteristics and anti-interference performance of spiking neural networks show great potential in terms of computational speed, real-time information processing, and spatio-temporal information processing. Data processing. Spiking neural network is one of the cores of brain-like artificial intelligence, which realizes brain-like computing by simulating the structure and information transfer mode of biological neural networks. This paper summarizes the strengths, weaknesses and applicability of five neuronal models and analyzes the characteristics of five network topologies; then reviews the spiking neural network algorithms and summarizes the unsupervised learning algorithms based on synaptic plasticity rules and four types of supervised learning algorithms from the perspectives of unsupervised learning and supervised learning; finally focuses on the review of brain-like neuromorphic chips under research at home and abroad. This paper is intended to provide learning concepts and research orientations for the peers who are new to the research field of spiking neural networks through systematic summaries.
On the Use of the Kantorovich-Rubinstein Distance for Dimensionality Reduction
Sep 18, 2023The goal of this thesis is to study the use of the Kantorovich-Rubinstein distance as to build a descriptor of sample complexity in classification problems. The idea is to use the fact that the Kantorovich-Rubinstein distance is a metric in the space of measures that also takes into account the geometry and topology of the underlying metric space. We associate to each class of points a measure and thus study the geometrical information that we can obtain from the Kantorovich-Rubinstein distance between those measures. We show that a large Kantorovich-Rubinstein distance between those measures allows to conclude that there exists a 1-Lipschitz classifier that classifies well the classes of points. We also discuss the limitation of the Kantorovich-Rubinstein distance as a descriptor.