 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Pricing of Applications in Cloud Marketplaces using Game Theory
Sep 20, 2023
The competitive nature of Cloud marketplaces as new concerns in delivery of services makes the pricing policies a crucial task for firms. so that, pricing strategies has recently attracted many researchers. Since game theory can handle such competing well this concern is addressed by designing a normal form game between providers in current research. A committee is considered in which providers register for improving their competition based pricing policies. The functionality of game theory is applied to design dynamic pricing policies. The usage of the committee makes the game a complete information one, in which each player is aware of every others payoff functions. The players enhance their pricing policies to maximize their profits. The contribution of this paper is the quantitative modeling of Cloud marketplaces in form of a game to provide novel dynamic pricing strategies; the model is validated by proving the existence and the uniqueness of Nash equilibrium of the game.
OCC-VO: Dense Mapping via 3D Occupancy-Based Visual Odometry for Autonomous Driving
Sep 20, 2023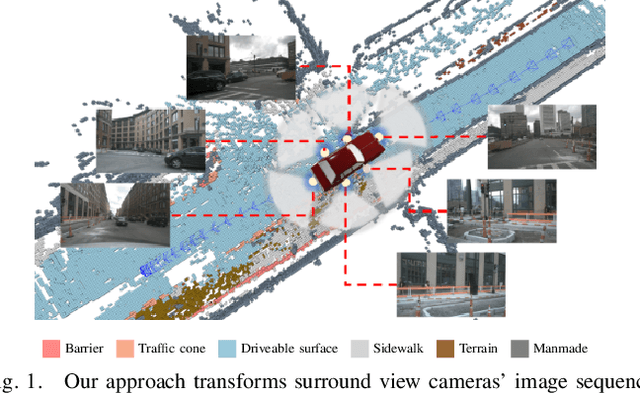
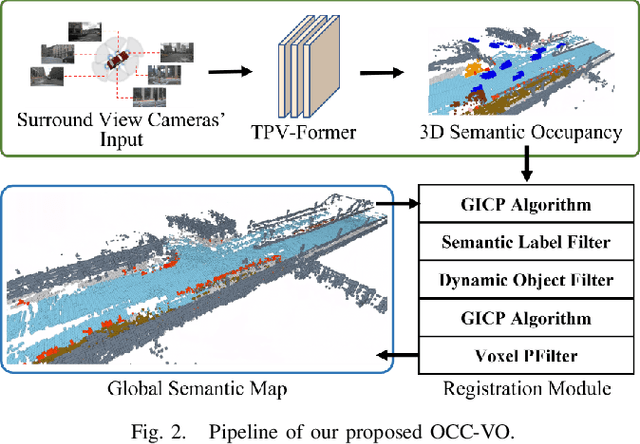
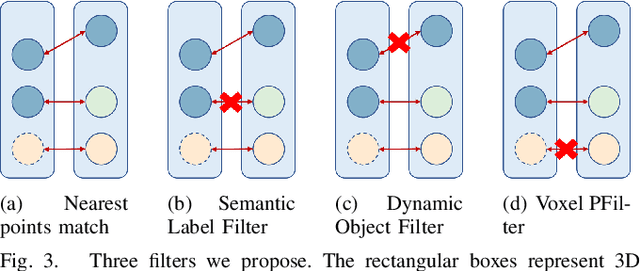
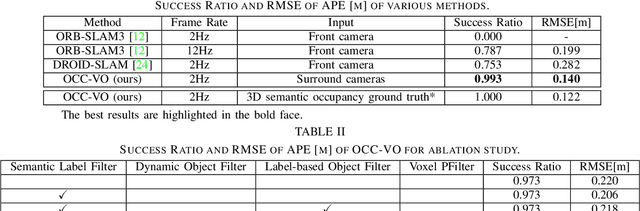
Visual Odometry (VO) plays a pivotal role in autonomous systems, with a principal challenge being the lack of depth information in camera images. This paper introduces OCC-VO, a novel framework that capitalizes on recent advances in deep learning to transform 2D camera images into 3D semantic occupancy, thereby circumventing the traditional need for concurrent estimation of ego poses and landmark locations. Within this framework, we utilize the TPV-Former to convert surround view cameras' images into 3D semantic occupancy. Addressing the challenges presented by this transformation, we have specifically tailored a pose estimation and mapping algorithm that incorporates Semantic Label Filter, Dynamic Object Filter, and finally, utilizes Voxel PFilter for maintaining a consistent global semantic map. Evaluations on the Occ3D-nuScenes not only showcase a 20.6% improvement in Success Ratio and a 29.6% enhancement in trajectory accuracy against ORB-SLAM3, but also emphasize our ability to construct a comprehensive map. Our implementation is open-sourced and available at: https://github.com/USTCLH/OCC-VO.
Reachability Analysis for Lexicase Selection via Community Assembly Graphs
Sep 20, 2023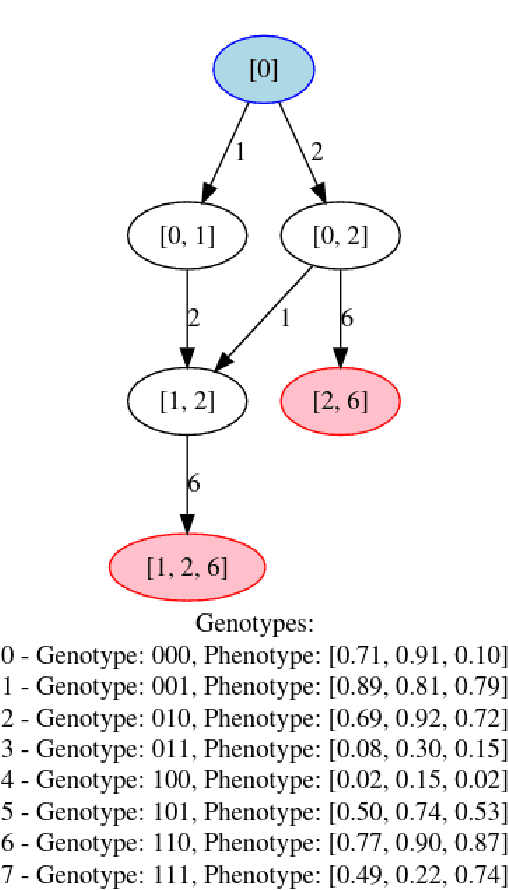
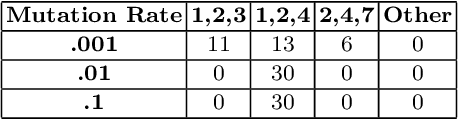
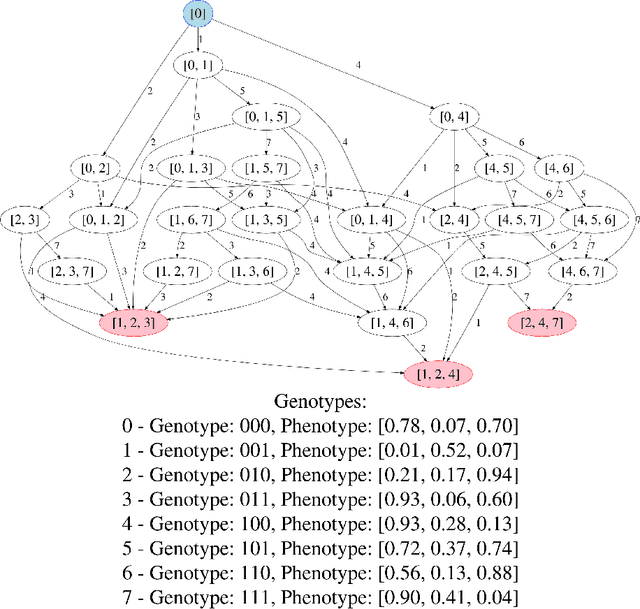
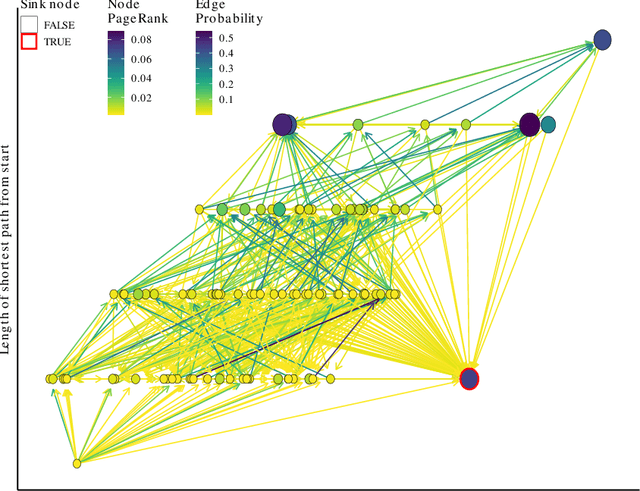
Fitness landscapes have historically been a powerful tool for analyzing the search space explored by evolutionary algorithms. In particular, they facilitate understanding how easily reachable an optimal solution is from a given starting point. However, simple fitness landscapes are inappropriate for analyzing the search space seen by selection schemes like lexicase selection in which the outcome of selection depends heavily on the current contents of the population (i.e. selection schemes with complex ecological dynamics). Here, we propose borrowing a tool from ecology to solve this problem: community assembly graphs. We demonstrate a simple proof-of-concept for this approach on an NK Landscape where we have perfect information. We then demonstrate that this approach can be successfully applied to a complex genetic programming problem. While further research is necessary to understand how to best use this tool, we believe it will be a valuable addition to our toolkit and facilitate analyses that were previously impossible.
Distribution and volume based scoring for Isolation Forests
Sep 20, 2023We make two contributions to the Isolation Forest method for anomaly and outlier detection. The first contribution is an information-theoretically motivated generalisation of the score function that is used to aggregate the scores across random tree estimators. This generalisation allows one to take into account not just the ensemble average across trees but instead the whole distribution. The second contribution is an alternative scoring function at the level of the individual tree estimator, in which we replace the depth-based scoring of the Isolation Forest with one based on hyper-volumes associated to an isolation tree's leaf nodes. We motivate the use of both of these methods on generated data and also evaluate them on 34 datasets from the recent and exhaustive ``ADBench'' benchmark, finding significant improvement over the standard isolation forest for both variants on some datasets and improvement on average across all datasets for one of the two variants. The code to reproduce our results is made available as part of the submission.
TRAVID: An End-to-End Video Translation Framework
Sep 20, 2023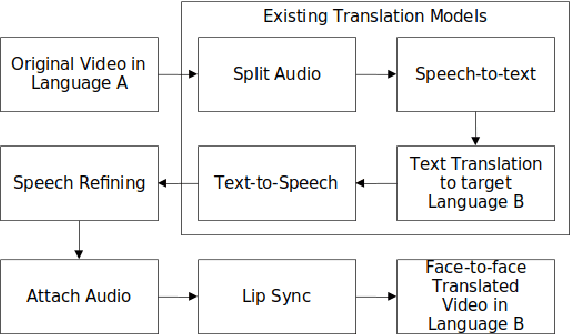

In today's globalized world, effective communication with people from diverse linguistic backgrounds has become increasingly crucial. While traditional methods of language translation, such as written text or voice-only translations, can accomplish the task, they often fail to capture the complete context and nuanced information conveyed through nonverbal cues like facial expressions and lip movements. In this paper, we present an end-to-end video translation system that not only translates spoken language but also synchronizes the translated speech with the lip movements of the speaker. Our system focuses on translating educational lectures in various Indian languages, and it is designed to be effective even in low-resource system settings. By incorporating lip movements that align with the target language and matching them with the speaker's voice using voice cloning techniques, our application offers an enhanced experience for students and users. This additional feature creates a more immersive and realistic learning environment, ultimately making the learning process more effective and engaging.
Grounded Complex Task Segmentation for Conversational Assistants
Sep 20, 2023Following complex instructions in conversational assistants can be quite daunting due to the shorter attention and memory spans when compared to reading the same instructions. Hence, when conversational assistants walk users through the steps of complex tasks, there is a need to structure the task into manageable pieces of information of the right length and complexity. In this paper, we tackle the recipes domain and convert reading structured instructions into conversational structured ones. We annotated the structure of instructions according to a conversational scenario, which provided insights into what is expected in this setting. To computationally model the conversational step's characteristics, we tested various Transformer-based architectures, showing that a token-based approach delivers the best results. A further user study showed that users tend to favor steps of manageable complexity and length, and that the proposed methodology can improve the original web-based instructional text. Specifically, 86% of the evaluated tasks were improved from a conversational suitability point of view.
Lightning-Fast Dual-Layer Lossless Coding for Radiance Format High Dynamic Range Images
Sep 20, 2023
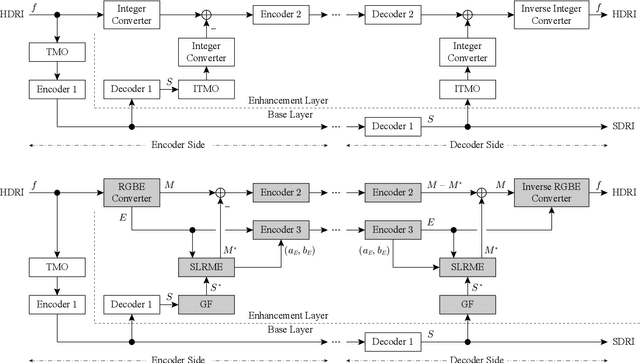
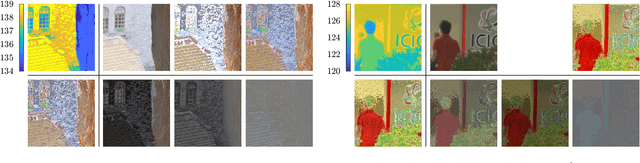
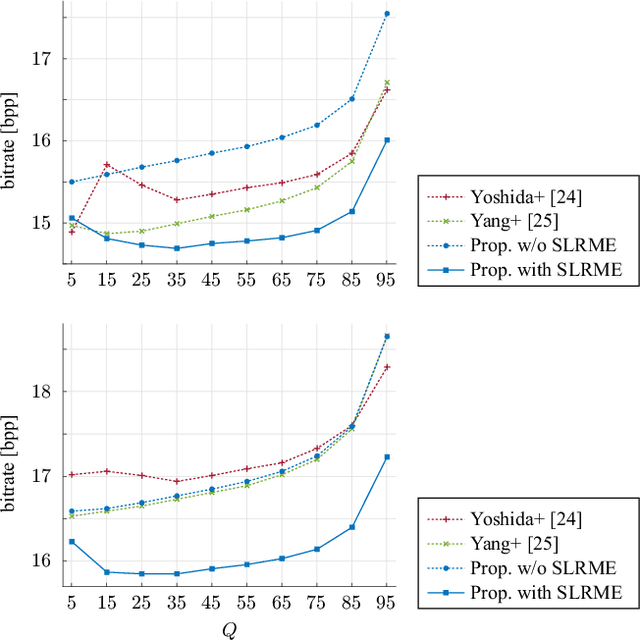
This paper proposes a fast dual-layer lossless coding for high dynamic range images (HDRIs) in the Radiance format. The coding, which consists of a base layer and a lossless enhancement layer, provides a standard dynamic range image (SDRI) without requiring an additional algorithm at the decoder and can losslessly decode the HDRI by adding the residual signals (residuals) between the HDRI and SDRI to the SDRI, if desired. To suppress the dynamic range of the residuals in the enhancement layer, the coding directly uses the mantissa and exponent information from the Radiance format. To further reduce the residual energy, each mantissa is modeled (estimated) as a linear function, i.e., a simple linear regression, of the encoded-decoded SDRI in each region with the same exponent. This is called simple linear regressive mantissa estimator. Experimental results show that, compared with existing methods, our coding reduces the average bitrate by approximately $1.57$-$6.68$ % and significantly reduces the average encoder implementation time by approximately $87.13$-$98.96$ %.
Beyond Fairness: Age-Harmless Parkinson's Detection via Voice
Sep 23, 2023Parkinson's disease (PD), a neurodegenerative disorder, often manifests as speech and voice dysfunction. While utilizing voice data for PD detection has great potential in clinical applications, the widely used deep learning models currently have fairness issues regarding different ages of onset. These deep models perform well for the elderly group (age $>$ 55) but are less accurate for the young group (age $\leq$ 55). Through our investigation, the discrepancy between the elderly and the young arises due to 1) an imbalanced dataset and 2) the milder symptoms often seen in early-onset patients. However, traditional debiasing methods are impractical as they typically impair the prediction accuracy for the majority group while minimizing the discrepancy. To address this issue, we present a new debiasing method using GradCAM-based feature masking combined with ensemble models, ensuring that neither fairness nor accuracy is compromised. Specifically, the GradCAM-based feature masking selectively obscures age-related features in the input voice data while preserving essential information for PD detection. The ensemble models further improve the prediction accuracy for the minority (young group). Our approach effectively improves detection accuracy for early-onset patients without sacrificing performance for the elderly group. Additionally, we propose a two-step detection strategy for the young group, offering a practical risk assessment for potential early-onset PD patients.
Deep evidential fusion with uncertainty quantification and contextual discounting for multimodal medical image segmentation
Sep 12, 2023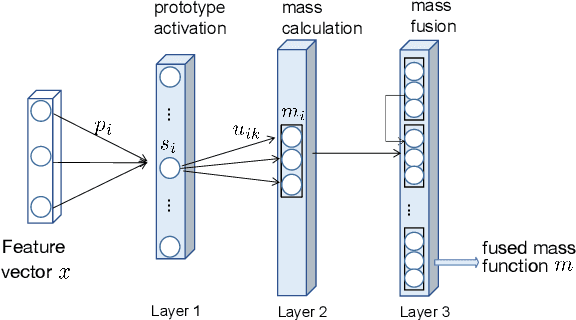
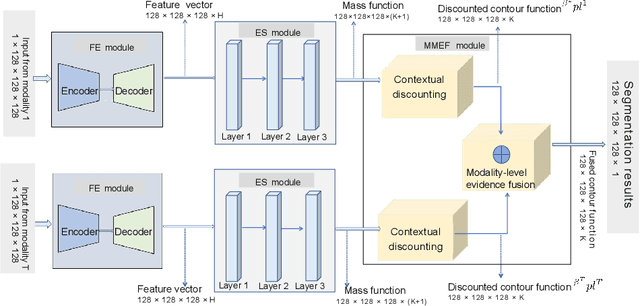
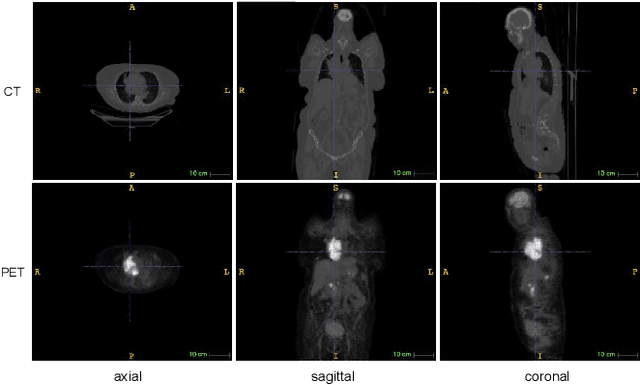
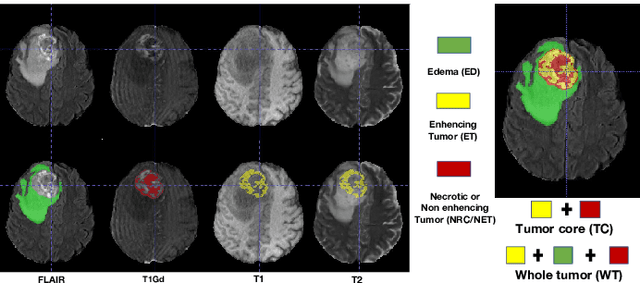
Single-modality medical images generally do not contain enough information to reach an accurate and reliable diagnosis. For this reason, physicians generally diagnose diseases based on multimodal medical images such as, e.g., PET/CT. The effective fusion of multimodal information is essential to reach a reliable decision and explain how the decision is made as well. In this paper, we propose a fusion framework for multimodal medical image segmentation based on deep learning and the Dempster-Shafer theory of evidence. In this framework, the reliability of each single modality image when segmenting different objects is taken into account by a contextual discounting operation. The discounted pieces of evidence from each modality are then combined by Dempster's rule to reach a final decision. Experimental results with a PET-CT dataset with lymphomas and a multi-MRI dataset with brain tumors show that our method outperforms the state-of-the-art methods in accuracy and reliability.
Recovering from Privacy-Preserving Masking with Large Language Models
Sep 12, 2023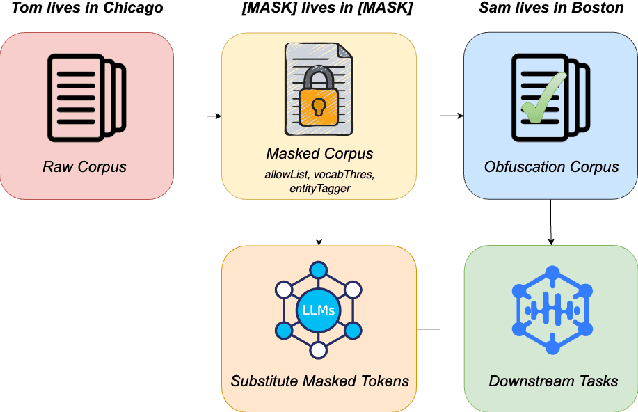
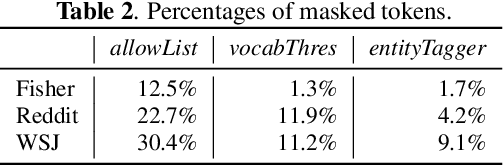
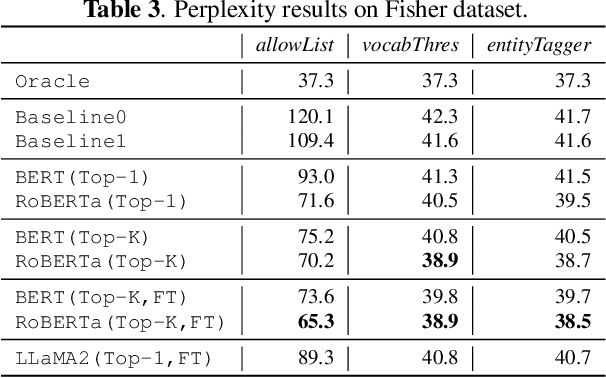
Model adaptation is crucial to handle the discrepancy between proxy training data and actual users data received. To effectively perform adaptation, textual data of users is typically stored on servers or their local devices, where downstream natural language processing (NLP) models can be directly trained using such in-domain data. However, this might raise privacy and security concerns due to the extra risks of exposing user information to adversaries. Replacing identifying information in textual data with a generic marker has been recently explored. In this work, we leverage large language models (LLMs) to suggest substitutes of masked tokens and have their effectiveness evaluated on downstream language modeling tasks. Specifically, we propose multiple pre-trained and fine-tuned LLM-based approaches and perform empirical studies on various datasets for the comparison of these methods. Experimental results show that models trained on the obfuscation corpora are able to achieve comparable performance with the ones trained on the original data without privacy-preserving token masking.