 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data Distribution Bottlenecks in Grounding Language Models to Knowledge Bases
Sep 15, 2023
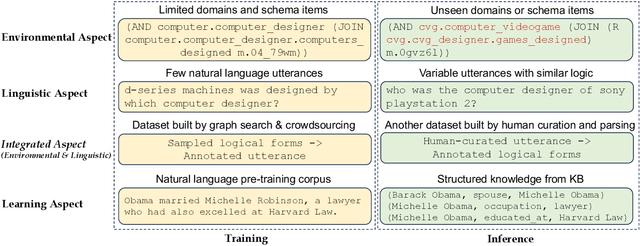
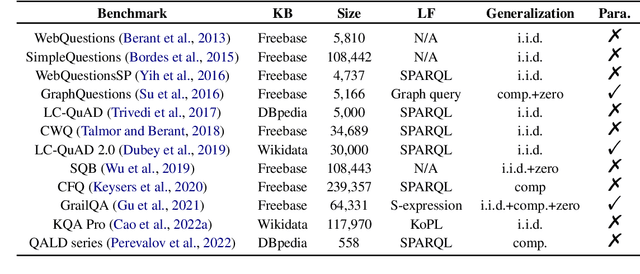


Language models (LMs) have already demonstrated remarkable abilities in understanding and generating both natural and formal language. Despite these advances, their integration with real-world environments such as large-scale knowledge bases (KBs) remains an underdeveloped area, affecting applications such as semantic parsing and indulging in "hallucinated" information. This paper is an experimental investigation aimed at uncovering the robustness challenges that LMs encounter when tasked with knowledge base question answering (KBQA). The investigation covers scenarios with inconsistent data distribution between training and inference, such as generalization to unseen domains, adaptation to various language variations, and transferability across different datasets. Our comprehensive experiments reveal that even when employed with our proposed data augmentation techniques, advanced small and large language models exhibit poor performance in various dimensions. While the LM is a promising technology, the robustness of the current form in dealing with complex environments is fragile and of limited practicality because of the data distribution issue. This calls for future research on data collection and LM learning paradims.
Semi-supervised Sound Event Detection with Local and Global Consistency Regularization
Sep 15, 2023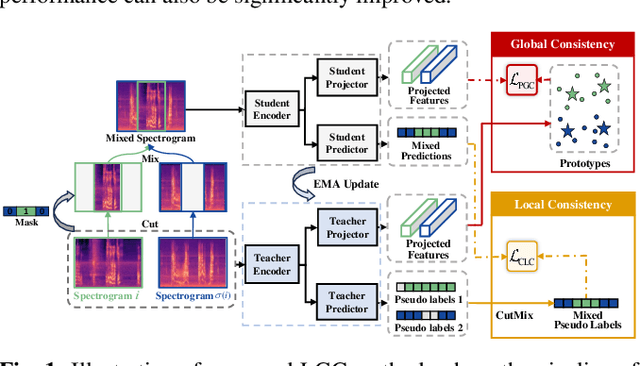
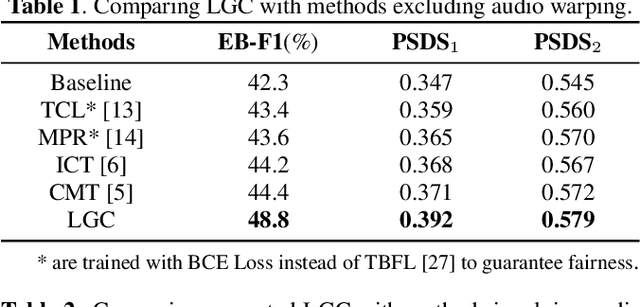
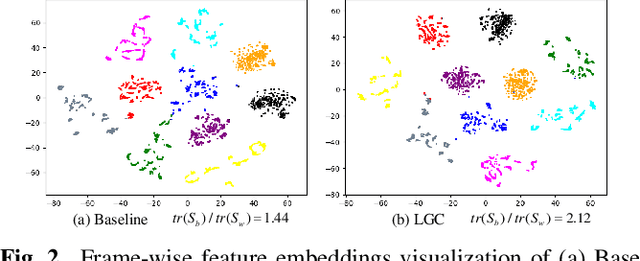
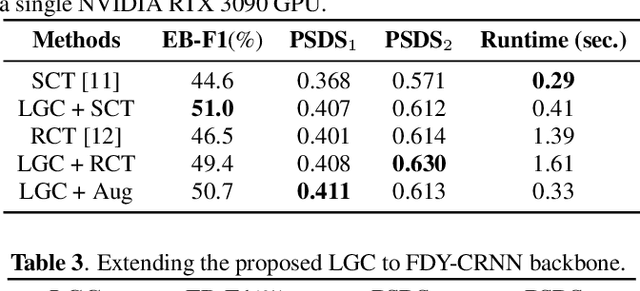
Learning meaningful frame-wise features on a partially labeled dataset is crucial to semi-supervised sound event detection. Prior works either maintain consistency on frame-level predictions or seek feature-level similarity among neighboring frames, which cannot exploit the potential of unlabeled data. In this work, we design a Local and Global Consistency (LGC) regularization scheme to enhance the model on both label- and feature-level. The audio CutMix is introduced to change the contextual information of clips. Then, the local consistency is adopted to encourage the model to leverage local features for frame-level predictions, and the global consistency is applied to force features to align with global prototypes through a specially designed contrastive loss. Experiments on the DESED dataset indicate the superiority of LGC, surpassing its respective competitors largely with the same settings as the baseline system. Besides, combining LGC with existing methods can obtain further improvements. The code will be released soon.
Cure the headache of Transformers via Collinear Constrained Attention
Sep 15, 2023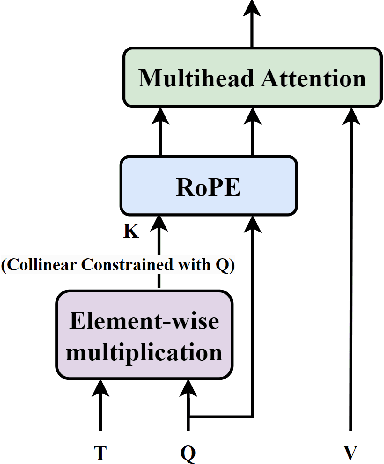
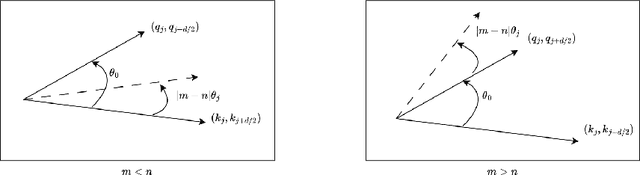
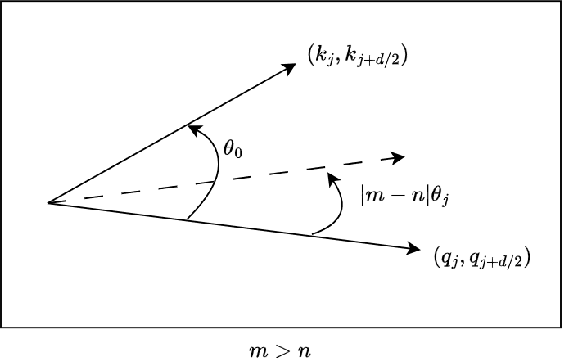

As the rapid progression of practical applications based on Large Language Models continues, the importance of extrapolating performance has grown exponentially in the research domain. In our study, we identified an anomalous behavior in Transformer models that had been previously overlooked, leading to a chaos around closest tokens which carried the most important information. We've coined this discovery the "headache of Transformers". To address this at its core, we introduced a novel self-attention structure named Collinear Constrained Attention (CoCA). This structure can be seamlessly integrated with existing extrapolation, interpolation methods, and other optimization strategies designed for traditional Transformer models. We have achieved excellent extrapolating performance even for 16 times to 24 times of sequence lengths during inference without any fine-tuning on our model. We have also enhanced CoCA's computational and spatial efficiency to ensure its practicality. We plan to open-source CoCA shortly. In the meantime, we've made our code available in the appendix for reappearing experiments.
A Survey of Hallucination in Large Foundation Models
Sep 12, 2023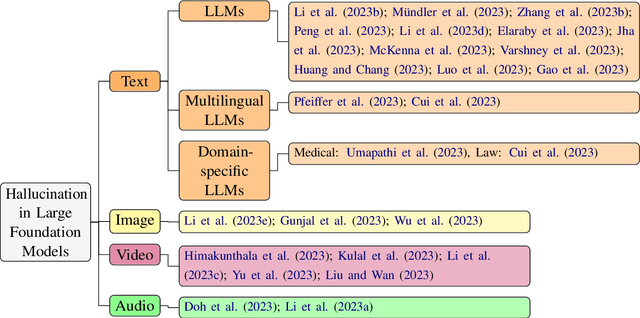
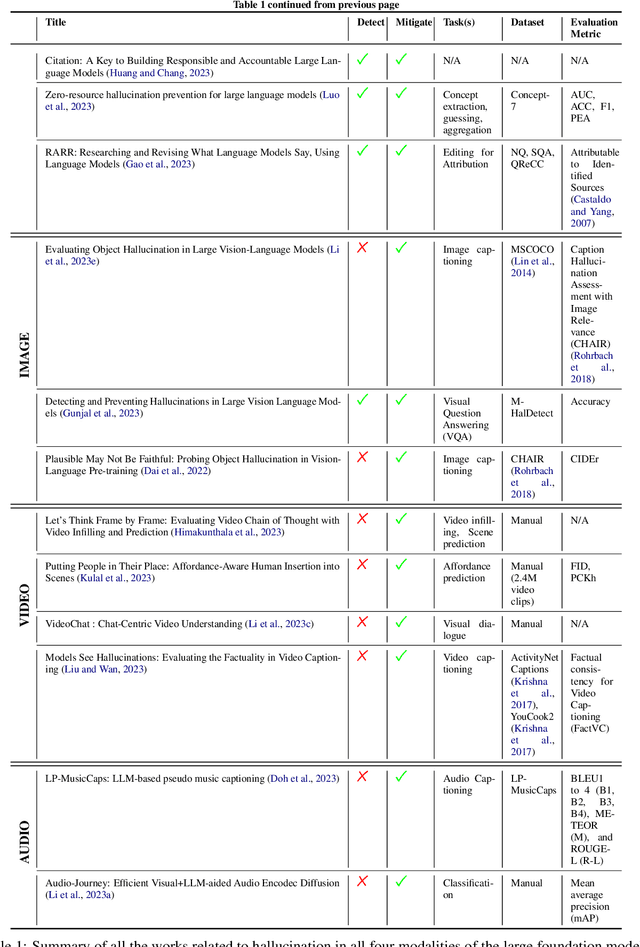
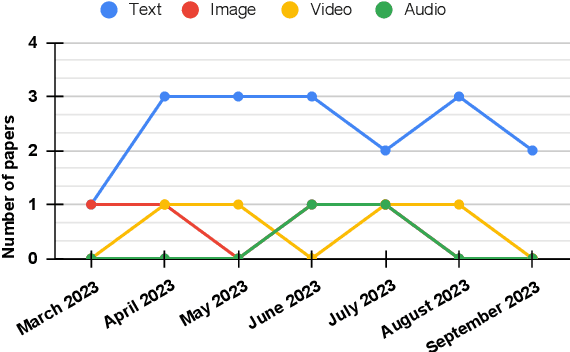

Hallucination in a foundation model (FM) refers to the generation of content that strays from factual reality or includes fabricated information. This survey paper provides an extensive overview of recent efforts that aim to identify, elucidate, and tackle the problem of hallucination, with a particular focus on ``Large'' Foundation Models (LFMs). The paper classifies various types of hallucination phenomena that are specific to LFMs and establishes evaluation criteria for assessing the extent of hallucination. It also examines existing strategies for mitigating hallucination in LFMs and discusses potential directions for future research in this area. Essentially, the paper offers a comprehensive examination of the challenges and solutions related to hallucination in LFMs.
Multi-Source Domain Adaptation meets Dataset Distillation through Dataset Dictionary Learning
Sep 14, 2023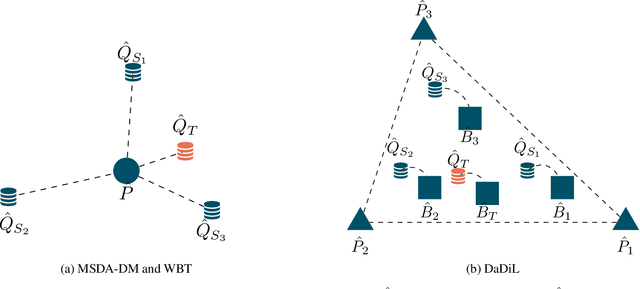
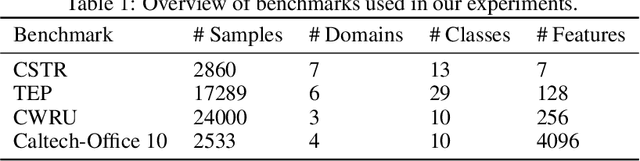
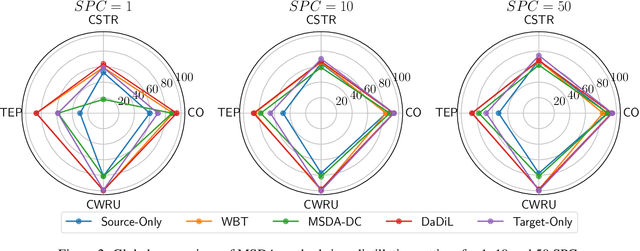
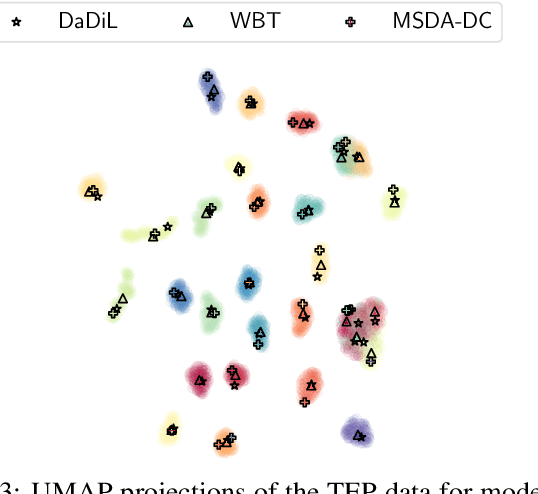
In this paper, we consider the intersection of two problems in machine learning: Multi-Source Domain Adaptation (MSDA) and Dataset Distillation (DD). On the one hand, the first considers adapting multiple heterogeneous labeled source domains to an unlabeled target domain. On the other hand, the second attacks the problem of synthesizing a small summary containing all the information about the datasets. We thus consider a new problem called MSDA-DD. To solve it, we adapt previous works in the MSDA literature, such as Wasserstein Barycenter Transport and Dataset Dictionary Learning, as well as DD method Distribution Matching. We thoroughly experiment with this novel problem on four benchmarks (Caltech-Office 10, Tennessee-Eastman Process, Continuous Stirred Tank Reactor, and Case Western Reserve University), where we show that, even with as little as 1 sample per class, one achieves state-of-the-art adaptation performance.
Connecting the Dots in News Analysis: A Cross-Disciplinary Survey of Media Bias and Framing
Sep 14, 2023
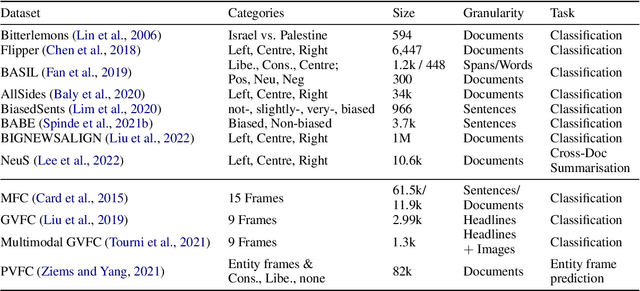
The manifestation and effect of bias in news reporting have been central topics in the social sciences for decades, and have received increasing attention in the NLP community recently. While NLP can help to scale up analyses or contribute automatic procedures to investigate the impact of biased news in society, we argue that methodologies that are currently dominant fall short of addressing the complex questions and effects addressed in theoretical media studies. In this survey paper, we review social science approaches and draw a comparison with typical task formulations, methods, and evaluation metrics used in the analysis of media bias in NLP. We discuss open questions and suggest possible directions to close identified gaps between theory and predictive models, and their evaluation. These include model transparency, considering document-external information, and cross-document reasoning rather than single-label assignment.
Zero-shot Audio Topic Reranking using Large Language Models
Sep 14, 2023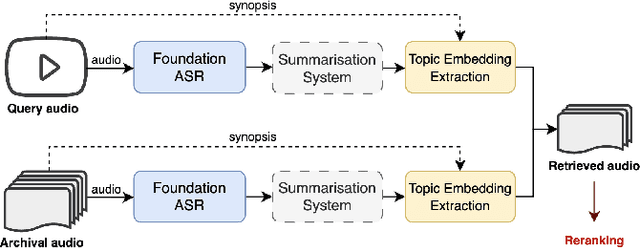
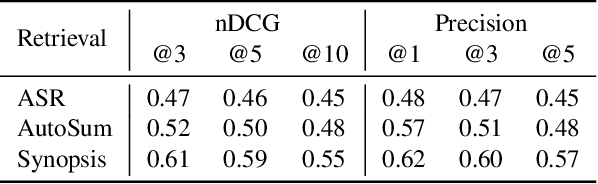
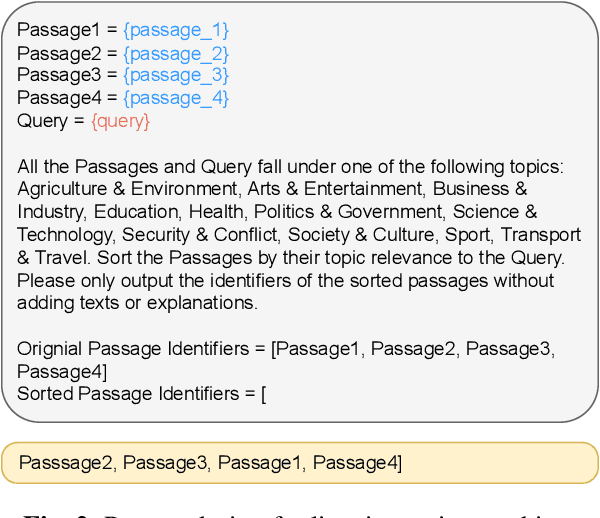
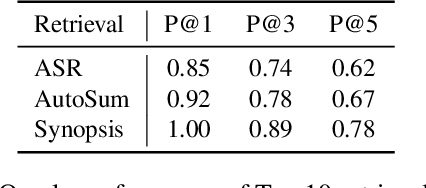
The Multimodal Video Search by Examples (MVSE) project investigates using video clips as the query term for information retrieval, rather than the more traditional text query. This enables far richer search modalities such as images, speaker, content, topic, and emotion. A key element for this process is highly rapid, flexible, search to support large archives, which in MVSE is facilitated by representing video attributes by embeddings. This work aims to mitigate any performance loss from this rapid archive search by examining reranking approaches. In particular, zero-shot reranking methods using large language models are investigated as these are applicable to any video archive audio content. Performance is evaluated for topic-based retrieval on a publicly available video archive, the BBC Rewind corpus. Results demonstrate that reranking can achieve improved retrieval ranking without the need for any task-specific training data.
All Labels Together: Low-shot Intent Detection with an Efficient Label Semantic Encoding Paradigm
Sep 07, 2023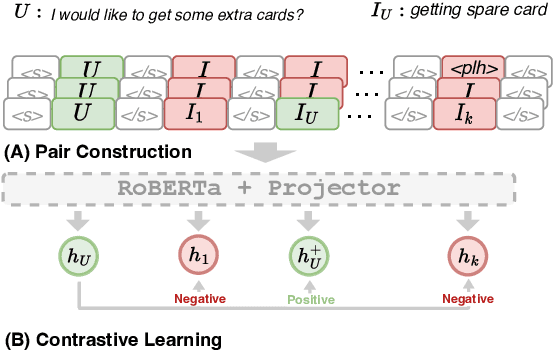
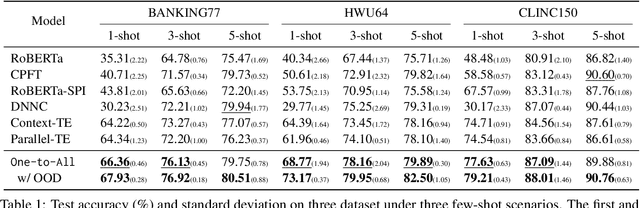
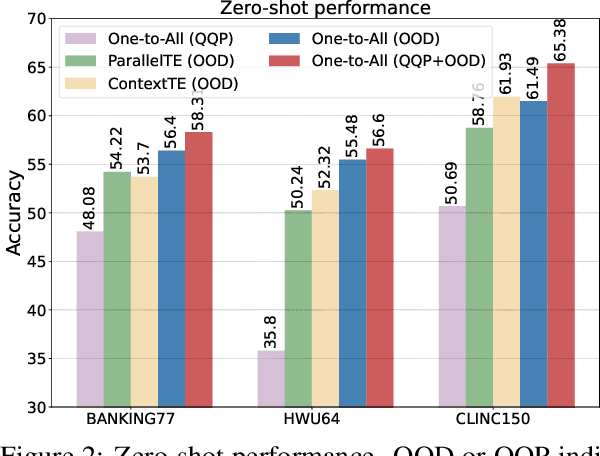

In intent detection tasks, leveraging meaningful semantic information from intent labels can be particularly beneficial for few-shot scenarios. However, existing few-shot intent detection methods either ignore the intent labels, (e.g. treating intents as indices) or do not fully utilize this information (e.g. only using part of the intent labels). In this work, we present an end-to-end One-to-All system that enables the comparison of an input utterance with all label candidates. The system can then fully utilize label semantics in this way. Experiments on three few-shot intent detection tasks demonstrate that One-to-All is especially effective when the training resource is extremely scarce, achieving state-of-the-art performance in 1-, 3- and 5-shot settings. Moreover, we present a novel pretraining strategy for our model that utilizes indirect supervision from paraphrasing, enabling zero-shot cross-domain generalization on intent detection tasks. Our code is at https://github.com/jiangshdd/AllLablesTogethe.
Harnessing Collective Intelligence Under a Lack of Cultural Consensus
Sep 19, 2023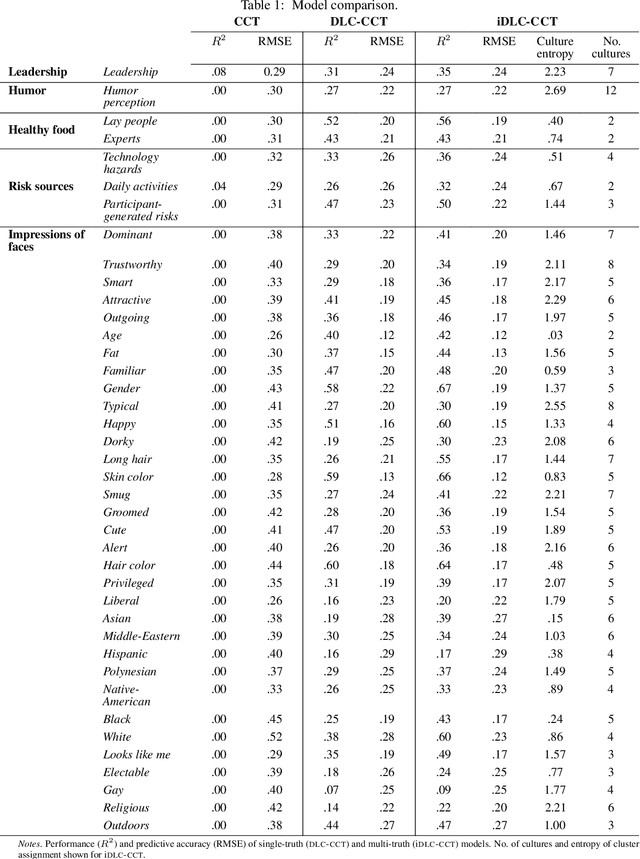
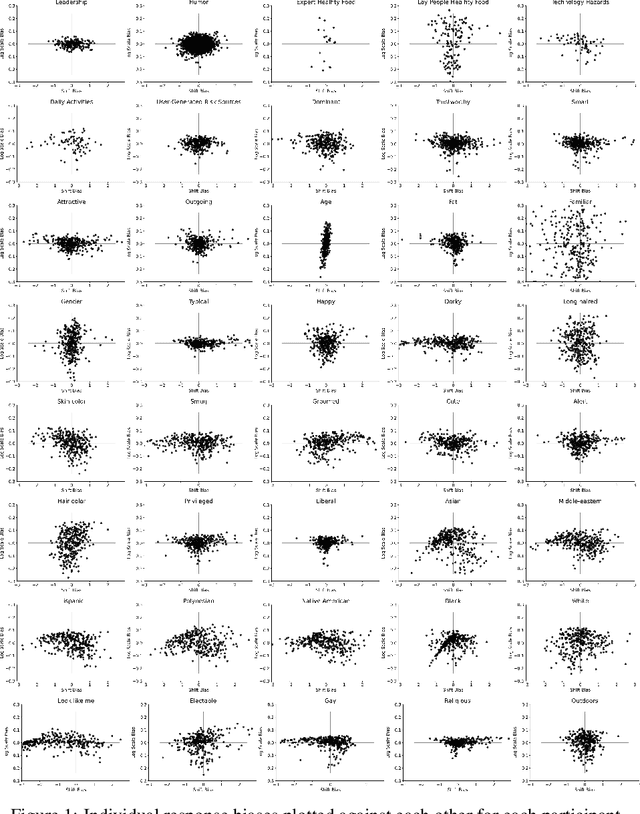
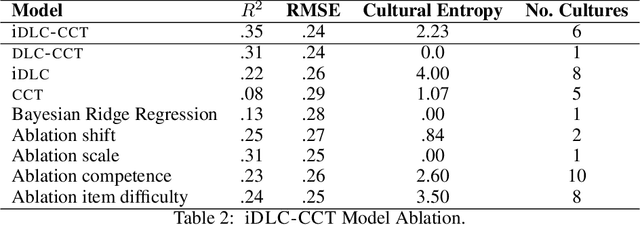
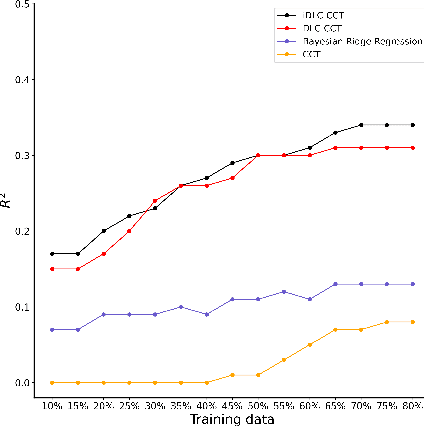
Harnessing collective intelligence to drive effective decision-making and collaboration benefits from the ability to detect and characterize heterogeneity in consensus beliefs. This is particularly true in domains such as technology acceptance or leadership perception, where a consensus defines an intersubjective truth, leading to the possibility of multiple "ground truths" when subsets of respondents sustain mutually incompatible consensuses. Cultural Consensus Theory (CCT) provides a statistical framework for detecting and characterizing these divergent consensus beliefs. However, it is unworkable in modern applications because it lacks the ability to generalize across even highly similar beliefs, is ineffective with sparse data, and can leverage neither external knowledge bases nor learned machine representations. Here, we overcome these limitations through Infinite Deep Latent Construct Cultural Consensus Theory (iDLC-CCT), a nonparametric Bayesian model that extends CCT with a latent construct that maps between pretrained deep neural network embeddings of entities and the consensus beliefs regarding those entities among one or more subsets of respondents. We validate the method across domains including perceptions of risk sources, food healthiness, leadership, first impressions, and humor. We find that iDLC-CCT better predicts the degree of consensus, generalizes well to out-of-sample entities, and is effective even with sparse data. To improve scalability, we introduce an efficient hard-clustering variant of the iDLC-CCT using an algorithm derived from a small-variance asymptotic analysis of the model. The iDLC-CCT, therefore, provides a workable computational foundation for harnessing collective intelligence under a lack of cultural consensus and may potentially form the basis of consensus-aware information technologies.
RUEL: Retrieval-Augmented User Representation with Edge Browser Logs for Sequential Recommendation
Sep 19, 2023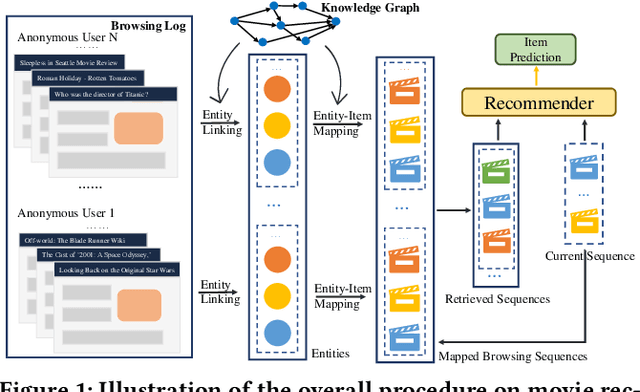
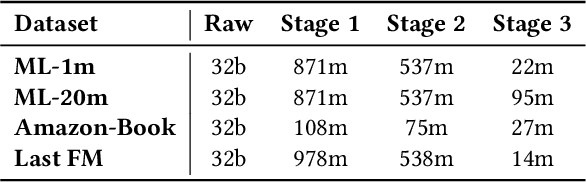
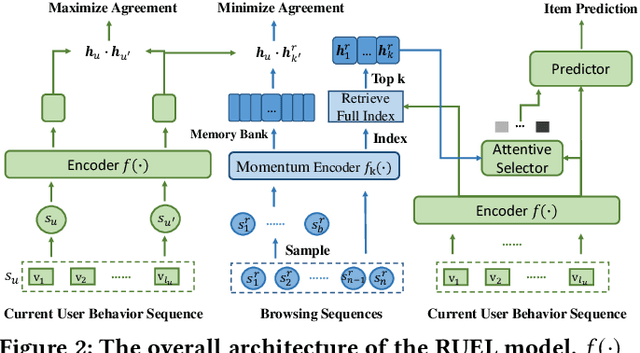
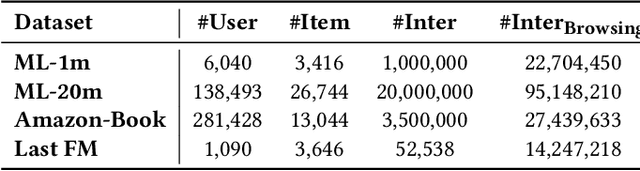
Online recommender systems (RS) aim to match user needs with the vast amount of resources available on various platforms. A key challenge is to model user preferences accurately under the condition of data sparsity. To address this challenge, some methods have leveraged external user behavior data from multiple platforms to enrich user representation. However, all of these methods require a consistent user ID across platforms and ignore the information from similar users. In this study, we propose RUEL, a novel retrieval-based sequential recommender that can effectively incorporate external anonymous user behavior data from Edge browser logs to enhance recommendation. We first collect and preprocess a large volume of Edge browser logs over a one-year period and link them to target entities that correspond to candidate items in recommendation datasets. We then design a contrastive learning framework with a momentum encoder and a memory bank to retrieve the most relevant and diverse browsing sequences from the full browsing log based on the semantic similarity between user representations. After retrieval, we apply an item-level attentive selector to filter out noisy items and generate refined sequence embeddings for the final predictor. RUEL is the first method that connects user browsing data with typical recommendation datasets and can be generalized to various recommendation scenarios and datasets. We conduct extensive experiments on four real datasets for sequential recommendation tasks and demonstrate that RUEL significantly outperforms state-of-the-art baselines. We also conduct ablation studies and qualitative analysis to validate the effectiveness of each component of RUEL and provide additional insights into our method.