 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards a Brazilian History Knowledge Graph
Mar 28, 2024

This short paper describes the first steps in a project to construct a knowledge graph for Brazilian history based on the Brazilian Dictionary of Historical Biographies (DHBB) and Wikipedia/Wikidata. We contend that large repositories of Brazilian-named entities (people, places, organizations, and political events and movements) would be beneficial for extracting information from Portuguese texts. We show that many of the terms/entities described in the DHBB do not have corresponding concepts (or Q items) in Wikidata, the largest structured database of entities associated with Wikipedia. We describe previous work on extracting information from the DHBB and outline the steps to construct a Wikidata-based historical knowledge graph.
Leveraging Large Language Models to Extract Information on Substance Use Disorder Severity from Clinical Notes: A Zero-shot Learning Approach
Mar 18, 2024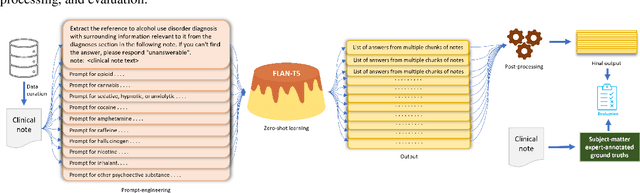
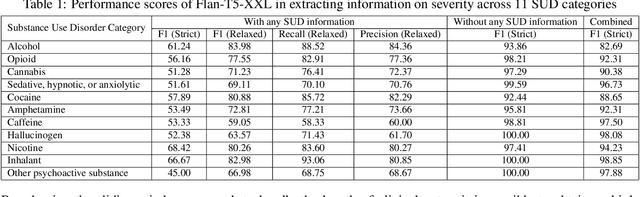
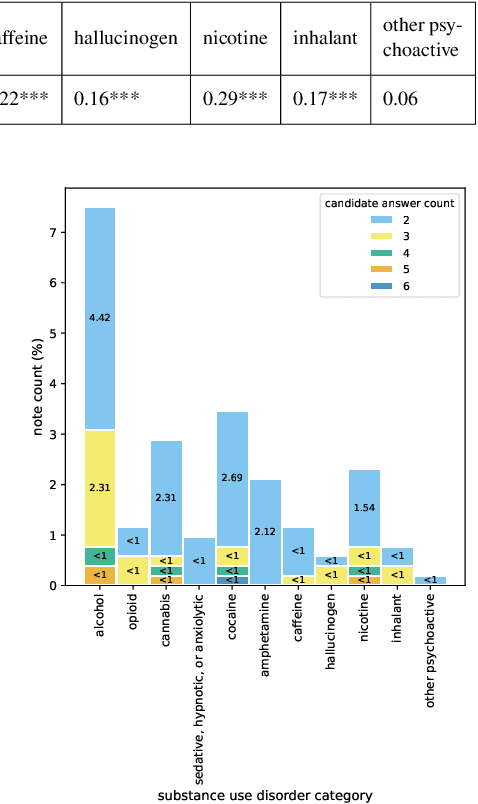
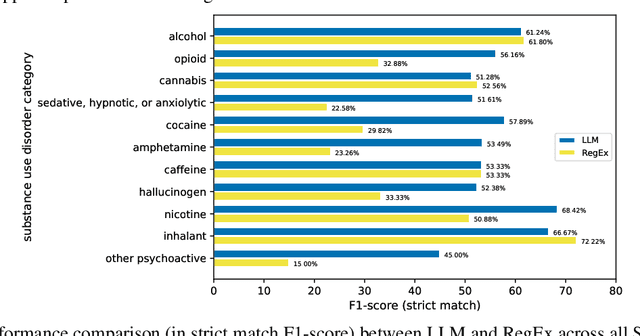
Substance use disorder (SUD) poses a major concern due to its detrimental effects on health and society. SUD identification and treatment depend on a variety of factors such as severity, co-determinants (e.g., withdrawal symptoms), and social determinants of health. Existing diagnostic coding systems used by American insurance providers, like the International Classification of Diseases (ICD-10), lack granularity for certain diagnoses, but clinicians will add this granularity (as that found within the Diagnostic and Statistical Manual of Mental Disorders classification or DSM-5) as supplemental unstructured text in clinical notes. Traditional natural language processing (NLP) methods face limitations in accurately parsing such diverse clinical language. Large Language Models (LLMs) offer promise in overcoming these challenges by adapting to diverse language patterns. This study investigates the application of LLMs for extracting severity-related information for various SUD diagnoses from clinical notes. We propose a workflow employing zero-shot learning of LLMs with carefully crafted prompts and post-processing techniques. Through experimentation with Flan-T5, an open-source LLM, we demonstrate its superior recall compared to the rule-based approach. Focusing on 11 categories of SUD diagnoses, we show the effectiveness of LLMs in extracting severity information, contributing to improved risk assessment and treatment planning for SUD patients.
NYC-Indoor-VPR: A Long-Term Indoor Visual Place Recognition Dataset with Semi-Automatic Annotation
Mar 31, 2024Visual Place Recognition (VPR) in indoor environments is beneficial to humans and robots for better localization and navigation. It is challenging due to appearance changes at various frequencies, and difficulties of obtaining ground truth metric trajectories for training and evaluation. This paper introduces the NYC-Indoor-VPR dataset, a unique and rich collection of over 36,000 images compiled from 13 distinct crowded scenes in New York City taken under varying lighting conditions with appearance changes. Each scene has multiple revisits across a year. To establish the ground truth for VPR, we propose a semiautomatic annotation approach that computes the positional information of each image. Our method specifically takes pairs of videos as input and yields matched pairs of images along with their estimated relative locations. The accuracy of this matching is refined by human annotators, who utilize our annotation software to correlate the selected keyframes. Finally, we present a benchmark evaluation of several state-of-the-art VPR algorithms using our annotated dataset, revealing its challenge and thus value for VPR research.
DRAGIN: Dynamic Retrieval Augmented Generation based on the Real-time Information Needs of Large Language Models
Mar 15, 2024
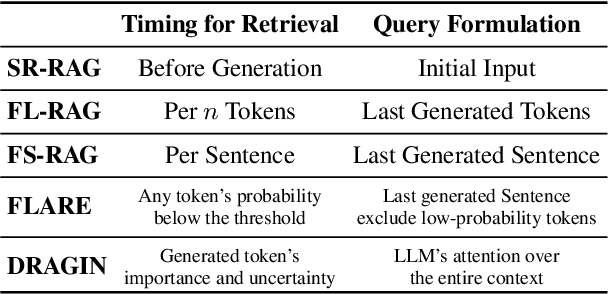
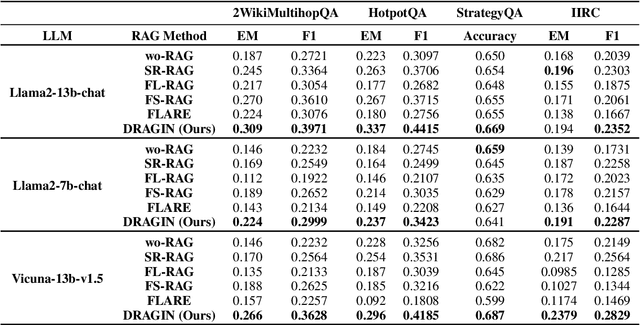
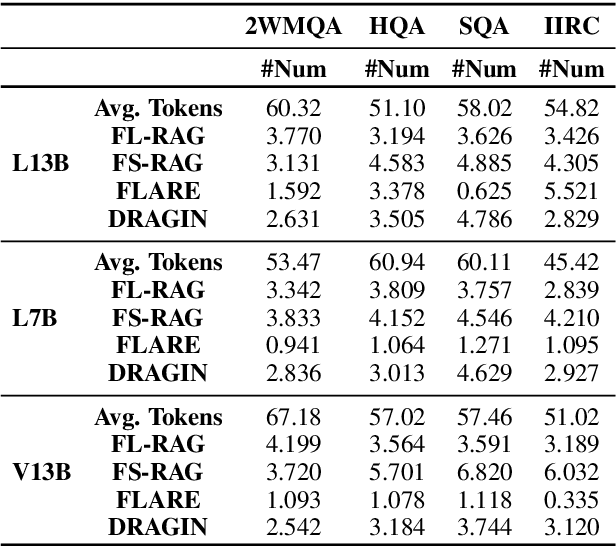
Dynamic retrieval augmented generation (RAG) paradigm actively decides when and what to retrieve during the text generation process of Large Language Models (LLMs). There are two key elements of this paradigm: identifying the optimal moment to activate the retrieval module (deciding when to retrieve) and crafting the appropriate query once retrieval is triggered (determining what to retrieve). However, current dynamic RAG methods fall short in both aspects. Firstly, the strategies for deciding when to retrieve often rely on static rules. Moreover, the strategies for deciding what to retrieve typically limit themselves to the LLM's most recent sentence or the last few tokens, while the LLM's real-time information needs may span across the entire context. To overcome these limitations, we introduce a new framework, DRAGIN, i.e., Dynamic Retrieval Augmented Generation based on the real-time Information Needs of LLMs. Our framework is specifically designed to make decisions on when and what to retrieve based on the LLM's real-time information needs during the text generation process. We evaluate DRAGIN along with existing methods comprehensively over 4 knowledge-intensive generation datasets. Experimental results show that DRAGIN achieves superior performance on all tasks, demonstrating the effectiveness of our method. We have open-sourced all the code, data, and models in GitHub: https://github.com/oneal2000/DRAGIN/tree/main
LocCa: Visual Pretraining with Location-aware Captioners
Mar 28, 2024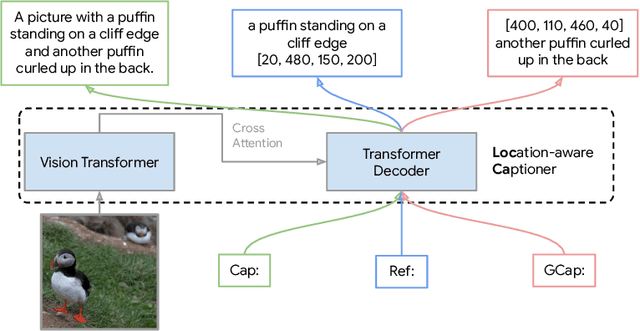
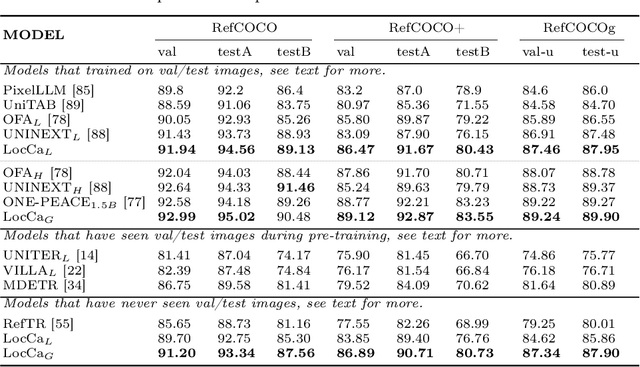
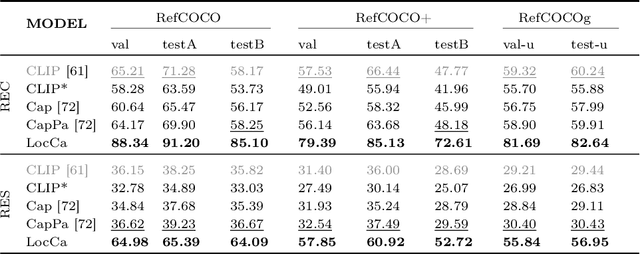
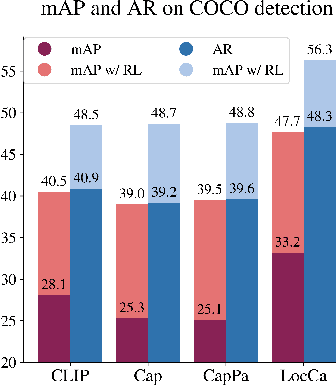
Image captioning has been shown as an effective pretraining method similar to contrastive pretraining. However, the incorporation of location-aware information into visual pretraining remains an area with limited research. In this paper, we propose a simple visual pretraining method with location-aware captioners (LocCa). LocCa uses a simple image captioner task interface, to teach a model to read out rich information, i.e. bounding box coordinates, and captions, conditioned on the image pixel input. Thanks to the multitask capabilities of an encoder-decoder architecture, we show that an image captioner can easily handle multiple tasks during pretraining. Our experiments demonstrate that LocCa outperforms standard captioners significantly on localization downstream tasks while maintaining comparable performance on holistic tasks.
Poisoning Decentralized Collaborative Recommender System and Its Countermeasures
Apr 01, 2024To make room for privacy and efficiency, the deployment of many recommender systems is experiencing a shift from central servers to personal devices, where the federated recommender systems (FedRecs) and decentralized collaborative recommender systems (DecRecs) are arguably the two most representative paradigms. While both leverage knowledge (e.g., gradients) sharing to facilitate learning local models, FedRecs rely on a central server to coordinate the optimization process, yet in DecRecs, the knowledge sharing directly happens between clients. Knowledge sharing also opens a backdoor for model poisoning attacks, where adversaries disguise themselves as benign clients and disseminate polluted knowledge to achieve malicious goals like promoting an item's exposure rate. Although research on such poisoning attacks provides valuable insights into finding security loopholes and corresponding countermeasures, existing attacks mostly focus on FedRecs, and are either inapplicable or ineffective for DecRecs. Compared with FedRecs where the tampered information can be universally distributed to all clients once uploaded to the cloud, each adversary in DecRecs can only communicate with neighbor clients of a small size, confining its impact to a limited range. To fill the gap, we present a novel attack method named Poisoning with Adaptive Malicious Neighbors (PAMN). With item promotion in top-K recommendation as the attack objective, PAMN effectively boosts target items' ranks with several adversaries that emulate benign clients and transfers adaptively crafted gradients conditioned on each adversary's neighbors. Moreover, with the vulnerabilities of DecRecs uncovered, a dedicated defensive mechanism based on user-level gradient clipping with sparsified updating is proposed. Extensive experiments demonstrate the effectiveness of the poisoning attack and the robustness of our defensive mechanism.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024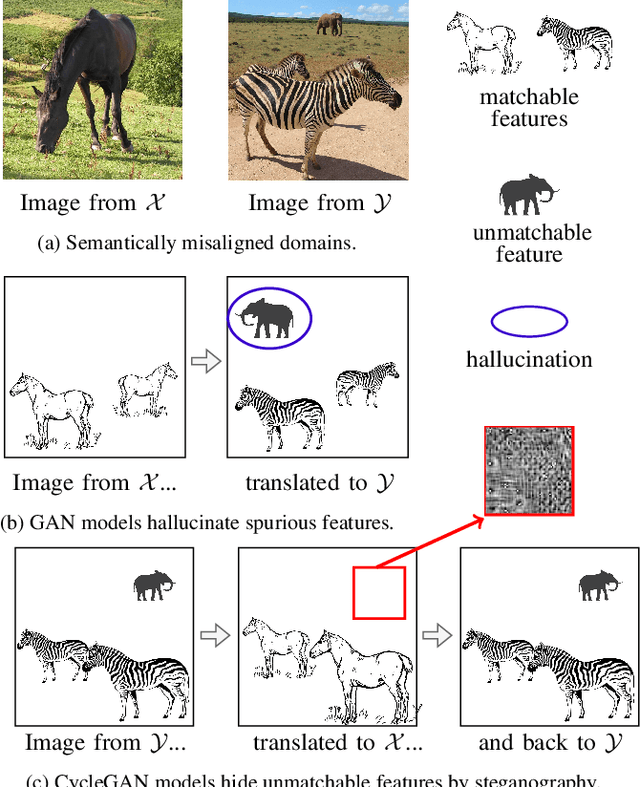
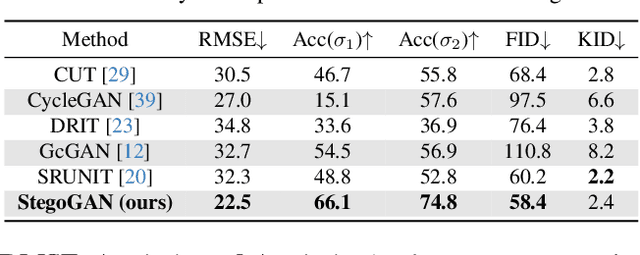
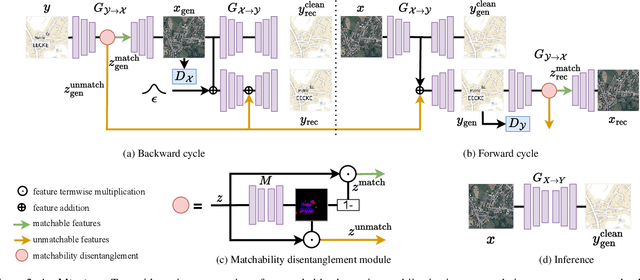
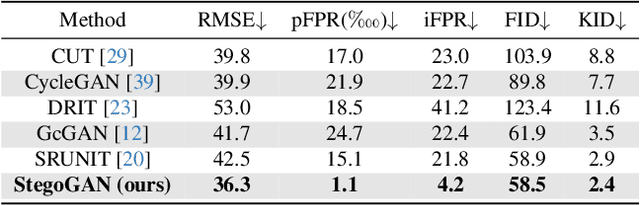
Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
MRNaB: Mixed Reality-based Robot Navigation Interface using Optical-see-through MR-beacon
Mar 28, 2024Recent advancements in robotics have led to the development of numerous interfaces to enhance the intuitiveness of robot navigation. However, the reliance on traditional 2D displays imposes limitations on the simultaneous visualization of information. Mixed Reality (MR) technology addresses this issue by enhancing the dimensionality of information visualization, allowing users to perceive multiple pieces of information concurrently. This paper proposes Mixed reality-based robot navigation interface using an optical-see-through MR-beacon (MRNaB), a novel approach that incorporates an MR-beacon, situated atop the real-world environment, to function as a signal transmitter for robot navigation. This MR-beacon is designed to be persistent, eliminating the need for repeated navigation inputs for the same location. Our system is mainly constructed into four primary functions: "Add", "Move", "Delete", and "Select". These allow for the addition of a MR-beacon, location movement, its deletion, and the selection of MR-beacon for navigation purposes, respectively. The effectiveness of the proposed method was then validated through experiments by comparing it with the traditional 2D system. As the result, MRNaB was proven to increase the performance of the user when doing navigation to a certain place subjectively and objectively. For additional material, please check: https://mertcookimg.github.io/mrnab
Blockchain-Enabled Variational Information Bottleneck for IoT Networks
Mar 10, 2024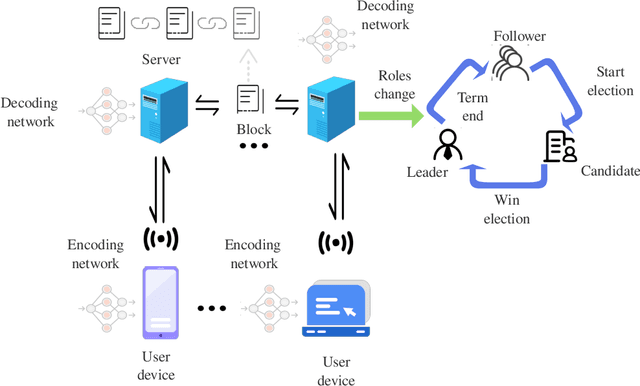
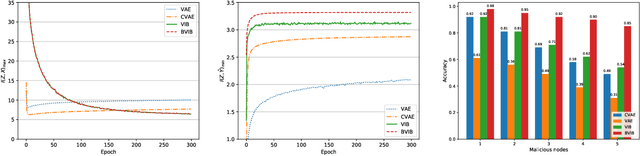
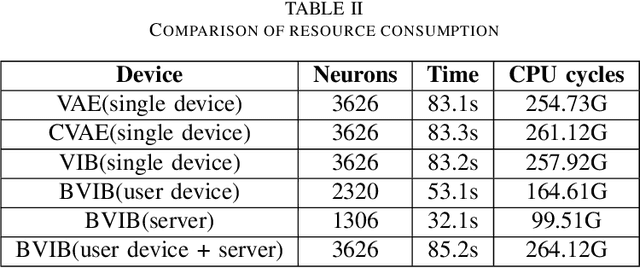
In Internet of Things (IoT) networks, the amount of data sensed by user devices may be huge, resulting in the serious network congestion. To solve this problem, intelligent data compression is critical. The variational information bottleneck (VIB) approach, combined with machine learning, can be employed to train the encoder and decoder, so that the required transmission data size can be reduced significantly. However, VIB suffers from the computing burden and network insecurity. In this paper, we propose a blockchain-enabled VIB (BVIB) approach to relieve the computing burden while guaranteeing network security. Extensive simulations conducted by Python and C++ demonstrate that BVIB outperforms VIB by 36%, 22% and 57% in terms of time and CPU cycles cost, mutual information, and accuracy under attack, respectively.
Can physical information aid the generalization ability of Neural Networks for hydraulic modeling?
Mar 13, 2024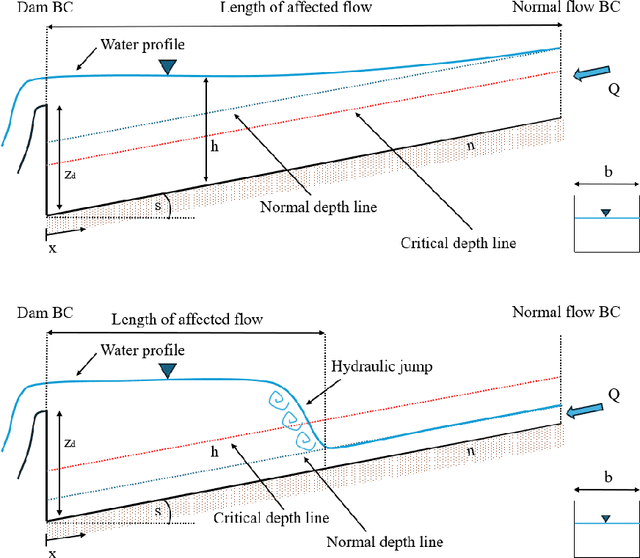
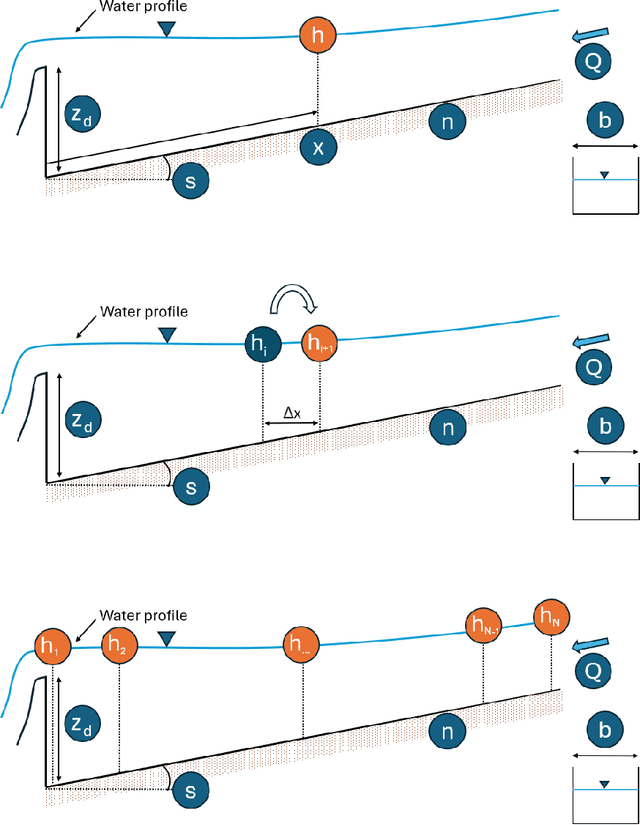
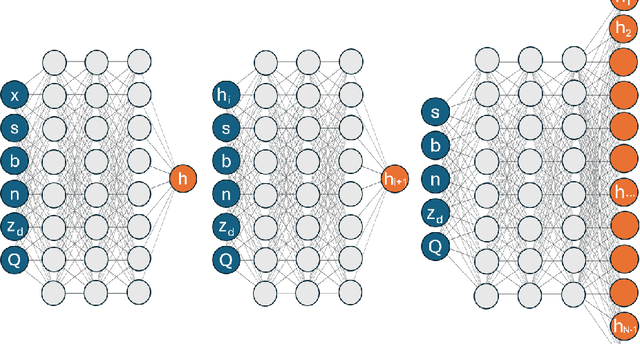
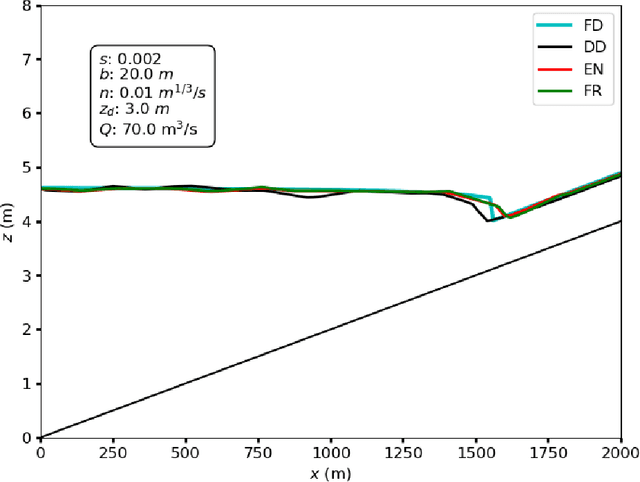
Application of Neural Networks to river hydraulics is fledgling, despite the field suffering from data scarcity, a challenge for machine learning techniques. Consequently, many purely data-driven Neural Networks proved to lack predictive capabilities. In this work, we propose to mitigate such problem by introducing physical information into the training phase. The idea is borrowed from Physics-Informed Neural Networks which have been recently proposed in other contexts. Physics-Informed Neural Networks embed physical information in the form of the residual of the Partial Differential Equations (PDEs) governing the phenomenon and, as such, are conceived as neural solvers, i.e. an alternative to traditional numerical solvers. Such approach is seldom suitable for environmental hydraulics, where epistemic uncertainties are large, and computing residuals of PDEs exhibits difficulties similar to those faced by classical numerical methods. Instead, we envisaged the employment of Neural Networks as neural operators, featuring physical constraints formulated without resorting to PDEs. The proposed novel methodology shares similarities with data augmentation and regularization. We show that incorporating such soft physical information can improve predictive capabilities.