 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Violations of Differential Privacy for Quantum Algorithms
Sep 09, 2023
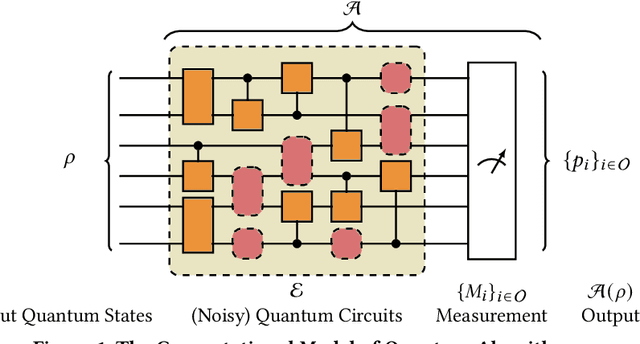
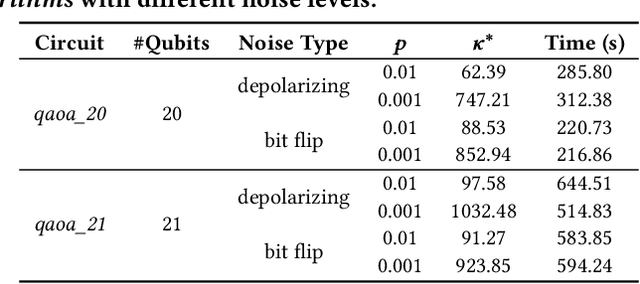
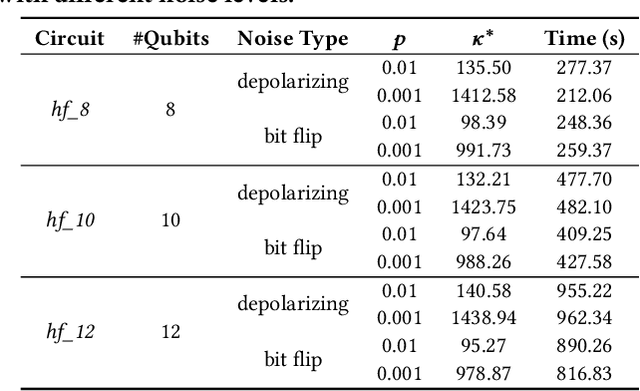
Quantum algorithms for solving a wide range of practical problems have been proposed in the last ten years, such as data search and analysis, product recommendation, and credit scoring. The concern about privacy and other ethical issues in quantum computing naturally rises up. In this paper, we define a formal framework for detecting violations of differential privacy for quantum algorithms. A detection algorithm is developed to verify whether a (noisy) quantum algorithm is differentially private and automatically generate bugging information when the violation of differential privacy is reported. The information consists of a pair of quantum states that violate the privacy, to illustrate the cause of the violation. Our algorithm is equipped with Tensor Networks, a highly efficient data structure, and executed both on TensorFlow Quantum and TorchQuantum which are the quantum extensions of famous machine learning platforms -- TensorFlow and PyTorch, respectively. The effectiveness and efficiency of our algorithm are confirmed by the experimental results of almost all types of quantum algorithms already implemented on realistic quantum computers, including quantum supremacy algorithms (beyond the capability of classical algorithms), quantum machine learning models, quantum approximate optimization algorithms, and variational quantum eigensolvers with up to 21 quantum bits.
Towards Real-World Burst Image Super-Resolution: Benchmark and Method
Sep 09, 2023
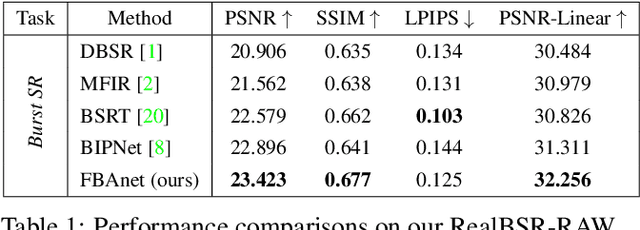
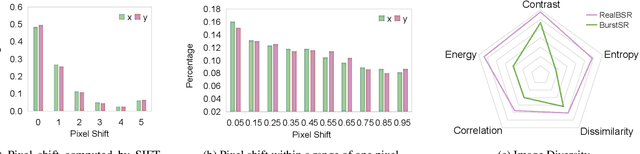
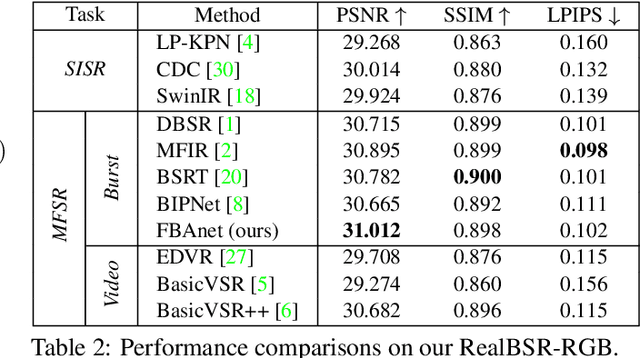
Despite substantial advances, single-image super-resolution (SISR) is always in a dilemma to reconstruct high-quality images with limited information from one input image, especially in realistic scenarios. In this paper, we establish a large-scale real-world burst super-resolution dataset, i.e., RealBSR, to explore the faithful reconstruction of image details from multiple frames. Furthermore, we introduce a Federated Burst Affinity network (FBAnet) to investigate non-trivial pixel-wise displacements among images under real-world image degradation. Specifically, rather than using pixel-wise alignment, our FBAnet employs a simple homography alignment from a structural geometry aspect and a Federated Affinity Fusion (FAF) strategy to aggregate the complementary information among frames. Those fused informative representations are fed to a Transformer-based module of burst representation decoding. Besides, we have conducted extensive experiments on two versions of our datasets, i.e., RealBSR-RAW and RealBSR-RGB. Experimental results demonstrate that our FBAnet outperforms existing state-of-the-art burst SR methods and also achieves visually-pleasant SR image predictions with model details. Our dataset, codes, and models are publicly available at https://github.com/yjsunnn/FBANet.
Early diagnosis of autism spectrum disorder using machine learning approaches
Sep 20, 2023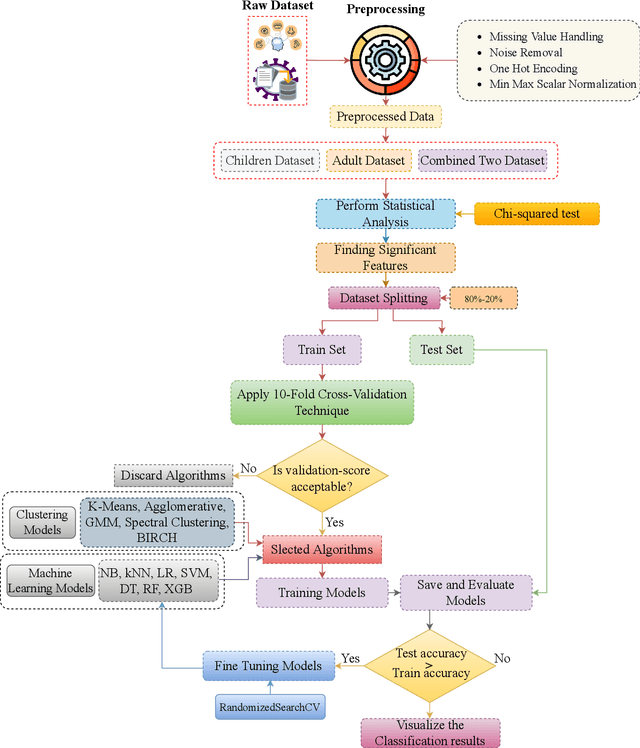

Autistic Spectrum Disorder (ASD) is a neurological disease characterized by difficulties with social interaction, communication, and repetitive activities. The severity of these difficulties varies, and those with this diagnosis face unique challenges. While its primary origin lies in genetics, identifying and addressing it early can contribute to the enhancement of the condition. In recent years, machine learning-driven intelligent diagnosis has emerged as a supplement to conventional clinical approaches, aiming to address the potential drawbacks of time-consuming and costly traditional methods. In this work, we utilize different machine learning algorithms to find the most significant traits responsible for ASD and to automate the diagnostic process. We study six classification models to see which model works best to identify ASD and also study five popular clustering methods to get a meaningful insight of these ASD datasets. To find the best classifier for these binary datasets, we evaluate the models using accuracy, precision, recall, specificity, F1-score, AUC, kappa and log loss metrics. Our evaluation demonstrates that five out of the six selected models perform exceptionally, achieving a 100% accuracy rate on the ASD datasets when hyperparameters are meticulously tuned for each model. As almost all classification models are able to get 100% accuracy, we become interested in observing the underlying insights of the datasets by implementing some popular clustering algorithms on these datasets. We calculate Normalized Mutual Information (NMI), Adjusted Rand Index (ARI) & Silhouette Coefficient (SC) metrics to select the best clustering models. Our evaluation finds that spectral clustering outperforms all other benchmarking clustering models in terms of NMI & ARI metrics and it also demonstrates comparability to the optimal SC achieved by k-means.
HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving
Sep 11, 2023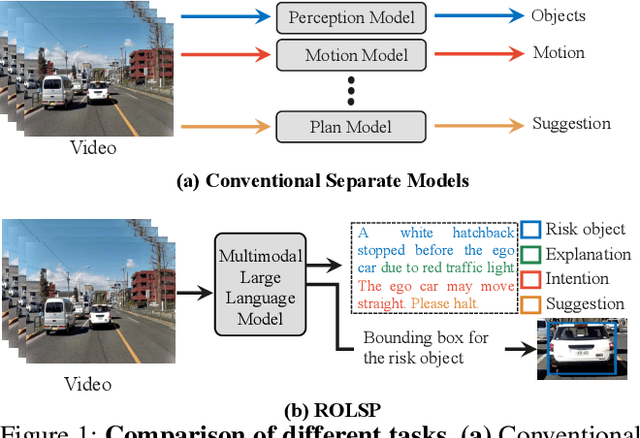
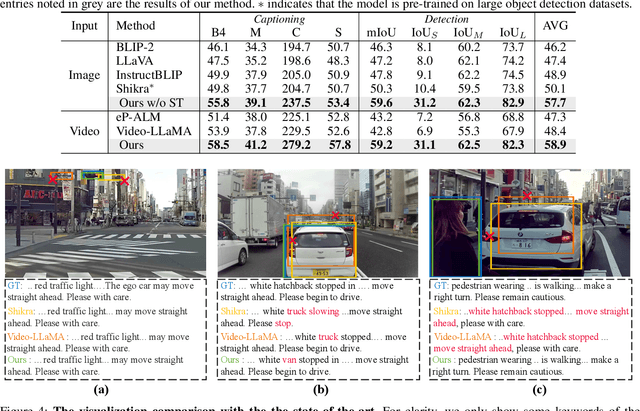
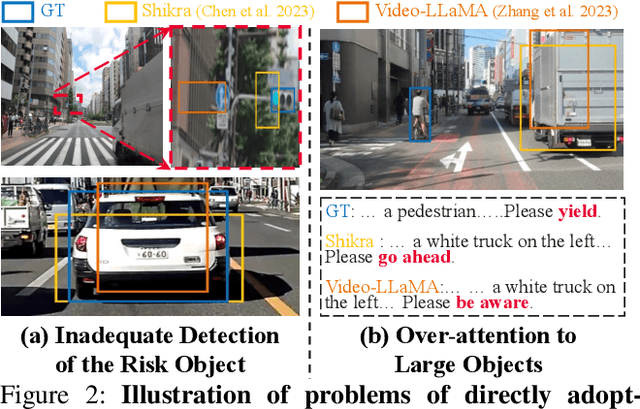
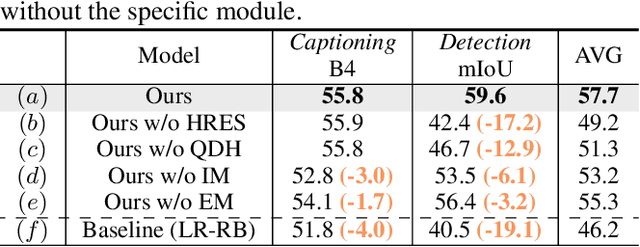
Autonomous driving systems generally employ separate models for different tasks resulting in intricate designs. For the first time, we leverage singular multimodal large language models (MLLMs) to consolidate multiple autonomous driving tasks from videos, i.e., the Risk Object Localization and Intention and Suggestion Prediction (ROLISP) task. ROLISP uses natural language to simultaneously identify and interpret risk objects, understand ego-vehicle intentions, and provide motion suggestions, eliminating the necessity for task-specific architectures. However, lacking high-resolution (HR) information, existing MLLMs often miss small objects (e.g., traffic cones) and overly focus on salient ones (e.g., large trucks) when applied to ROLISP. We propose HiLM-D (Towards High-Resolution Understanding in MLLMs for Autonomous Driving), an efficient method to incorporate HR information into MLLMs for the ROLISP task. Especially, HiLM-D integrates two branches: (i) the low-resolution reasoning branch, can be any MLLMs, processes low-resolution videos to caption risk objects and discern ego-vehicle intentions/suggestions; (ii) the high-resolution perception branch (HR-PB), prominent to HiLM-D,, ingests HR images to enhance detection by capturing vision-specific HR feature maps and prioritizing all potential risks over merely salient objects. Our HR-PB serves as a plug-and-play module, seamlessly fitting into current MLLMs. Experiments on the ROLISP benchmark reveal HiLM-D's notable advantage over leading MLLMs, with improvements of 4.8% in BLEU-4 for captioning and 17.2% in mIoU for detection.
Share Your Representation Only: Guaranteed Improvement of the Privacy-Utility Tradeoff in Federated Learning
Sep 11, 2023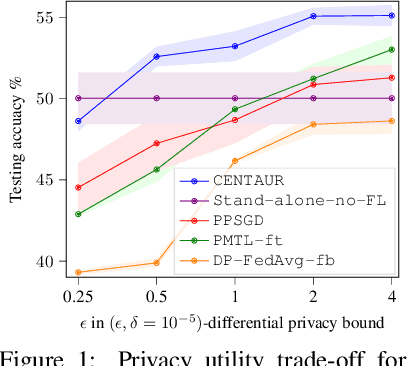


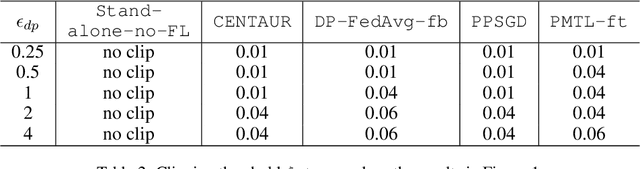
Repeated parameter sharing in federated learning causes significant information leakage about private data, thus defeating its main purpose: data privacy. Mitigating the risk of this information leakage, using state of the art differentially private algorithms, also does not come for free. Randomized mechanisms can prevent convergence of models on learning even the useful representation functions, especially if there is more disagreement between local models on the classification functions (due to data heterogeneity). In this paper, we consider a representation federated learning objective that encourages various parties to collaboratively refine the consensus part of the model, with differential privacy guarantees, while separately allowing sufficient freedom for local personalization (without releasing it). We prove that in the linear representation setting, while the objective is non-convex, our proposed new algorithm \DPFEDREP\ converges to a ball centered around the \emph{global optimal} solution at a linear rate, and the radius of the ball is proportional to the reciprocal of the privacy budget. With this novel utility analysis, we improve the SOTA utility-privacy trade-off for this problem by a factor of $\sqrt{d}$, where $d$ is the input dimension. We empirically evaluate our method with the image classification task on CIFAR10, CIFAR100, and EMNIST, and observe a significant performance improvement over the prior work under the same small privacy budget. The code can be found in this link: https://github.com/shenzebang/CENTAUR-Privacy-Federated-Representation-Learning.
Muti-Stage Hierarchical Food Classification
Sep 03, 2023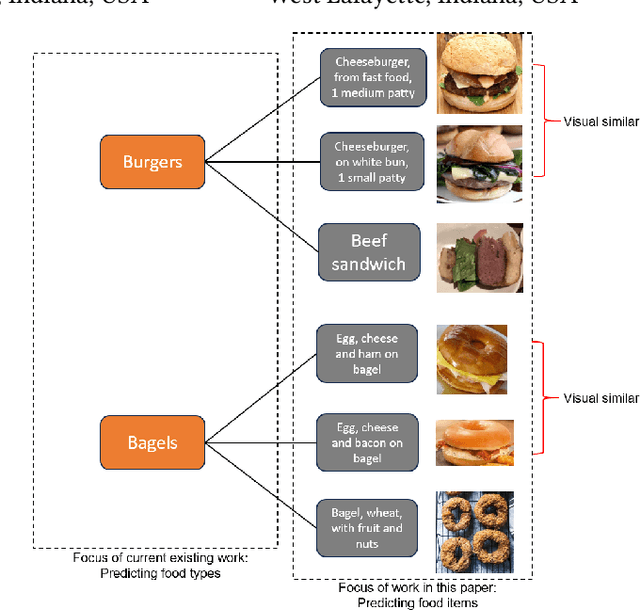
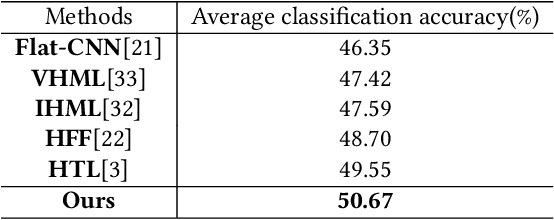
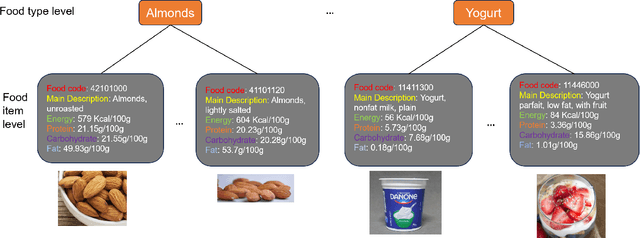
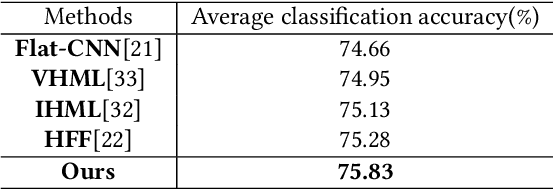
Food image classification serves as a fundamental and critical step in image-based dietary assessment, facilitating nutrient intake analysis from captured food images. However, existing works in food classification predominantly focuses on predicting 'food types', which do not contain direct nutritional composition information. This limitation arises from the inherent discrepancies in nutrition databases, which are tasked with associating each 'food item' with its respective information. Therefore, in this work we aim to classify food items to align with nutrition database. To this end, we first introduce VFN-nutrient dataset by annotating each food image in VFN with a food item that includes nutritional composition information. Such annotation of food items, being more discriminative than food types, creates a hierarchical structure within the dataset. However, since the food item annotations are solely based on nutritional composition information, they do not always show visual relations with each other, which poses significant challenges when applying deep learning-based techniques for classification. To address this issue, we then propose a multi-stage hierarchical framework for food item classification by iteratively clustering and merging food items during the training process, which allows the deep model to extract image features that are discriminative across labels. Our method is evaluated on VFN-nutrient dataset and achieve promising results compared with existing work in terms of both food type and food item classification.
PromptTTS 2: Describing and Generating Voices with Text Prompt
Sep 05, 2023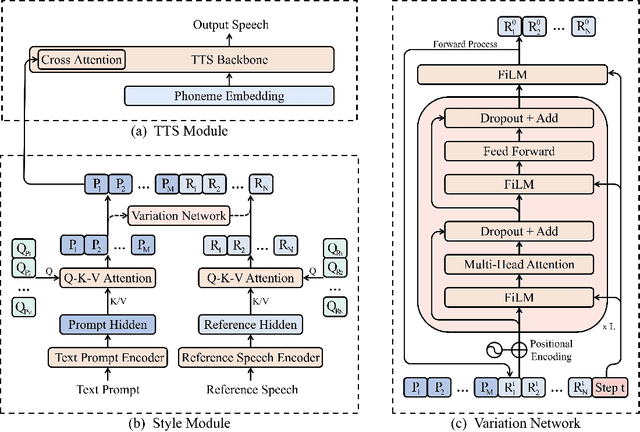

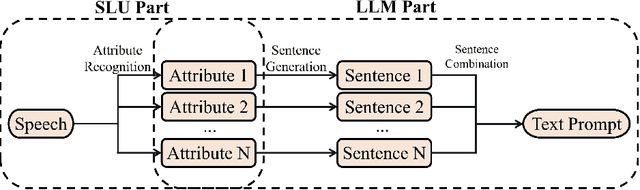
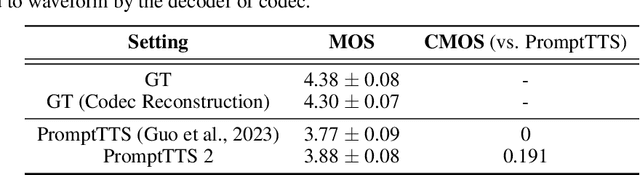
Speech conveys more information than just text, as the same word can be uttered in various voices to convey diverse information. Compared to traditional text-to-speech (TTS) methods relying on speech prompts (reference speech) for voice variability, using text prompts (descriptions) is more user-friendly since speech prompts can be hard to find or may not exist at all. TTS approaches based on the text prompt face two challenges: 1) the one-to-many problem, where not all details about voice variability can be described in the text prompt, and 2) the limited availability of text prompt datasets, where vendors and large cost of data labeling are required to write text prompt for speech. In this work, we introduce PromptTTS 2 to address these challenges with a variation network to provide variability information of voice not captured by text prompts, and a prompt generation pipeline to utilize the large language models (LLM) to compose high quality text prompts. Specifically, the variation network predicts the representation extracted from the reference speech (which contains full information about voice) based on the text prompt representation. For the prompt generation pipeline, it generates text prompts for speech with a speech understanding model to recognize voice attributes (e.g., gender, speed) from speech and a large language model to formulate text prompt based on the recognition results. Experiments on a large-scale (44K hours) speech dataset demonstrate that compared to the previous works, PromptTTS 2 generates voices more consistent with text prompts and supports the sampling of diverse voice variability, thereby offering users more choices on voice generation. Additionally, the prompt generation pipeline produces high-quality prompts, eliminating the large labeling cost. The demo page of PromptTTS 2 is available online\footnote{https://speechresearch.github.io/prompttts2}.
PreprintResolver: Improving Citation Quality by Resolving Published Versions of ArXiv Preprints using Literature Databases
Sep 04, 2023The growing impact of preprint servers enables the rapid sharing of time-sensitive research. Likewise, it is becoming increasingly difficult to distinguish high-quality, peer-reviewed research from preprints. Although preprints are often later published in peer-reviewed journals, this information is often missing from preprint servers. To overcome this problem, the PreprintResolver was developed, which uses four literature databases (DBLP, SemanticScholar, OpenAlex, and CrossRef / CrossCite) to identify preprint-publication pairs for the arXiv preprint server. The target audience focuses on, but is not limited to inexperienced researchers and students, especially from the field of computer science. The tool is based on a fuzzy matching of author surnames, titles, and DOIs. Experiments were performed on a sample of 1,000 arXiv-preprints from the research field of computer science and without any publication information. With 77.94 %, computer science is highly affected by missing publication information in arXiv. The results show that the PreprintResolver was able to resolve 603 out of 1,000 (60.3 %) arXiv-preprints from the research field of computer science and without any publication information. All four literature databases contributed to the final result. In a manual validation, a random sample of 100 resolved preprints was checked. For all preprints, at least one result is plausible. For nine preprints, more than one result was identified, three of which are partially invalid. In conclusion the PreprintResolver is suitable for individual, manually reviewed requests, but less suitable for bulk requests. The PreprintResolver tool (https://preprintresolver.eu, Available from 2023-08-01) and source code (https://gitlab.com/ippolis_wp3/preprint-resolver, Accessed: 2023-07-19) is available online.
Leveraging Multi-lingual Positive Instances in Contrastive Learning to Improve Sentence Embedding
Sep 16, 2023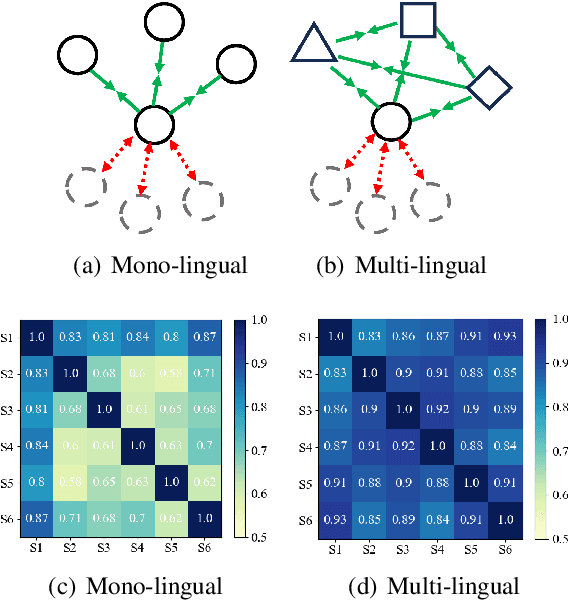
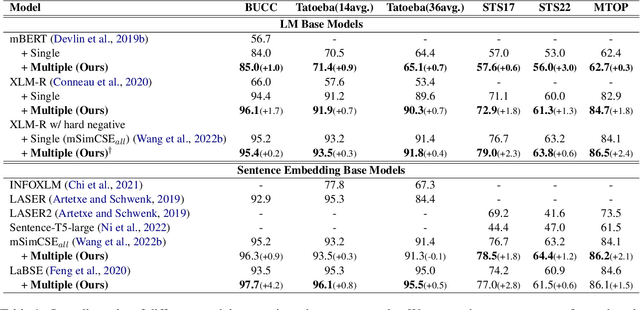
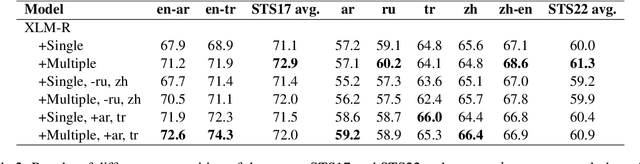
Learning multi-lingual sentence embeddings is a fundamental and significant task in natural language processing. Recent trends of learning both mono-lingual and multi-lingual sentence embeddings are mainly based on contrastive learning (CL) with an anchor, one positive, and multiple negative instances. In this work, we argue that leveraging multiple positives should be considered for multi-lingual sentence embeddings because (1) positives in a diverse set of languages can benefit cross-lingual learning, and (2) transitive similarity across multiple positives can provide reliable structural information to learn. In order to investigate the impact of CL with multiple positives, we propose a novel approach MPCL to effectively utilize multiple positive instances to improve learning multi-lingual sentence embeddings. Our experimental results on various backbone models and downstream tasks support that compared with conventional CL, MPCL leads to better retrieval, semantic similarity, and classification performances. We also observe that on unseen languages, sentence embedding models trained on multiple positives have better cross-lingual transferring performance than models trained on a single positive instance.
Improving Speech Recognition for African American English With Audio Classification
Sep 16, 2023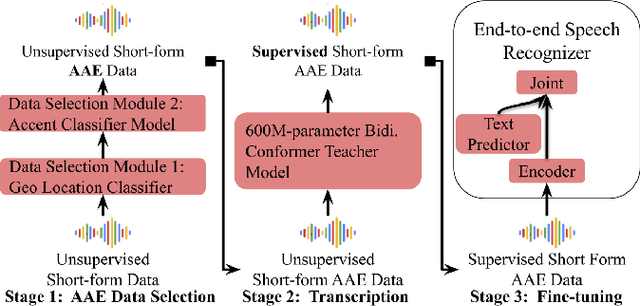
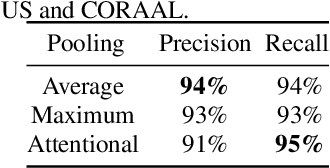
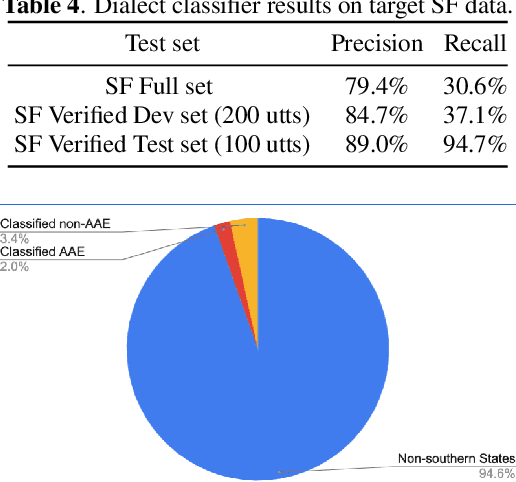

Automatic speech recognition (ASR) systems have been shown to have large quality disparities between the language varieties they are intended or expected to recognize. One way to mitigate this is to train or fine-tune models with more representative datasets. But this approach can be hindered by limited in-domain data for training and evaluation. We propose a new way to improve the robustness of a US English short-form speech recognizer using a small amount of out-of-domain (long-form) African American English (AAE) data. We use CORAAL, YouTube and Mozilla Common Voice to train an audio classifier to approximately output whether an utterance is AAE or some other variety including Mainstream American English (MAE). By combining the classifier output with coarse geographic information, we can select a subset of utterances from a large corpus of untranscribed short-form queries for semi-supervised learning at scale. Fine-tuning on this data results in a 38.5% relative word error rate disparity reduction between AAE and MAE without reducing MAE quality.