 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AV-MaskEnhancer: Enhancing Video Representations through Audio-Visual Masked Autoencoder
Sep 15, 2023
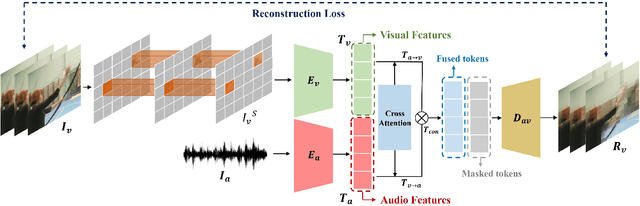

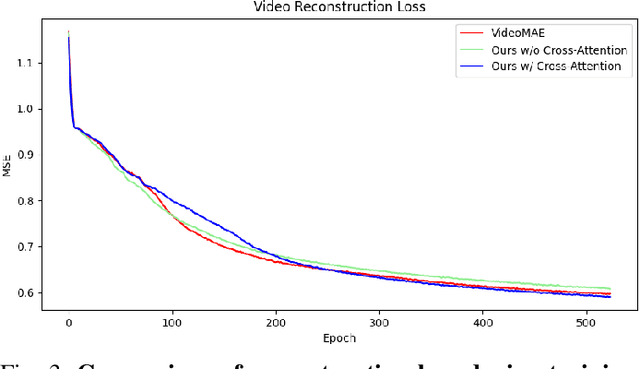
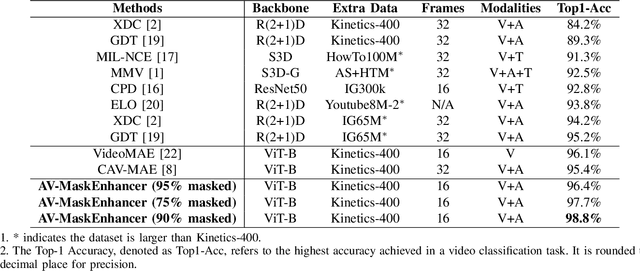
Learning high-quality video representation has shown significant applications in computer vision and remains challenging. Previous work based on mask autoencoders such as ImageMAE and VideoMAE has proven the effectiveness of learning representations in images and videos through reconstruction strategy in the visual modality. However, these models exhibit inherent limitations, particularly in scenarios where extracting features solely from the visual modality proves challenging, such as when dealing with low-resolution and blurry original videos. Based on this, we propose AV-MaskEnhancer for learning high-quality video representation by combining visual and audio information. Our approach addresses the challenge by demonstrating the complementary nature of audio and video features in cross-modality content. Moreover, our result of the video classification task on the UCF101 dataset outperforms the existing work and reaches the state-of-the-art, with a top-1 accuracy of 98.8% and a top-5 accuracy of 99.9%.
Uncertainty-bounded Active Monitoring of Unknown Dynamic Targets in Road-networks with Minimum Fleet
Sep 19, 2023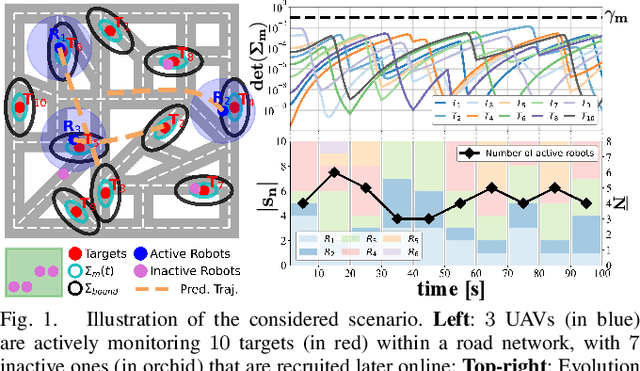
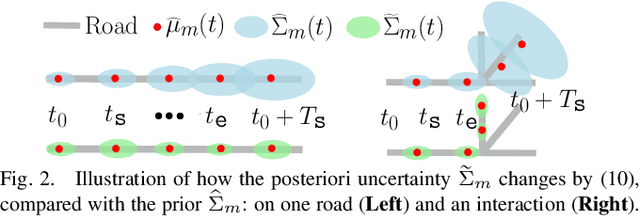
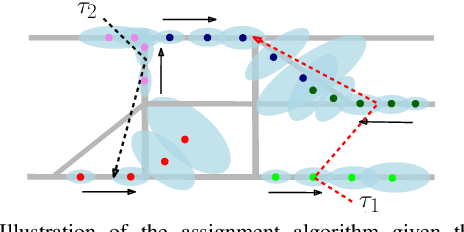
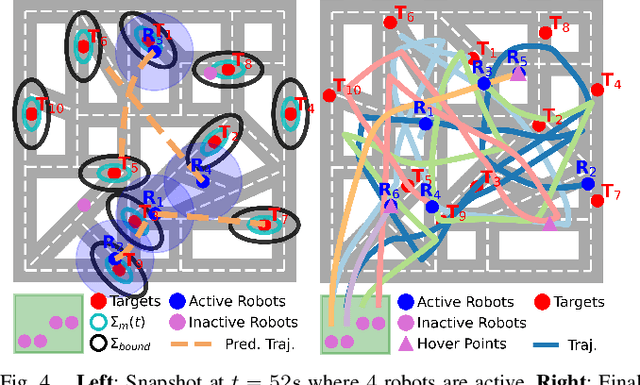
Fleets of unmanned robots can be beneficial for the long-term monitoring of large areas, e.g., to monitor wild flocks, detect intruders, search and rescue. Monitoring numerous dynamic targets in a collaborative and efficient way is a challenging problem that requires online coordination and information fusion. The majority of existing works either assume a passive all-to-all observation model to minimize the summed uncertainties over all targets by all robots, or optimize over the jointed discrete actions while neglecting the dynamic constraints of the robots and unknown behaviors of the targets. This work proposes an online task and motion coordination algorithm that ensures an explicitly-bounded estimation uncertainty for the target states, while minimizing the average number of active robots. The robots have a limited-range perception to actively track a limited number of targets simultaneously, of which their future control decisions are all unknown. It includes: (i) the assignment of monitoring tasks, modeled as a flexible size multiple vehicle routing problem with time windows (m-MVRPTW), given the predicted target trajectories with uncertainty measure in the road-networks; (ii) the nonlinear model predictive control (NMPC) for optimizing the robot trajectories under uncertainty and safety constraints. It is shown that the robots can switch between active and inactive roles dynamically online as required by the unknown monitoring task. The proposed methods are validated via large-scale simulations of up to $100$ robots and targets.
Assessing the capacity of a denoising diffusion probabilistic model to reproduce spatial context
Sep 19, 2023
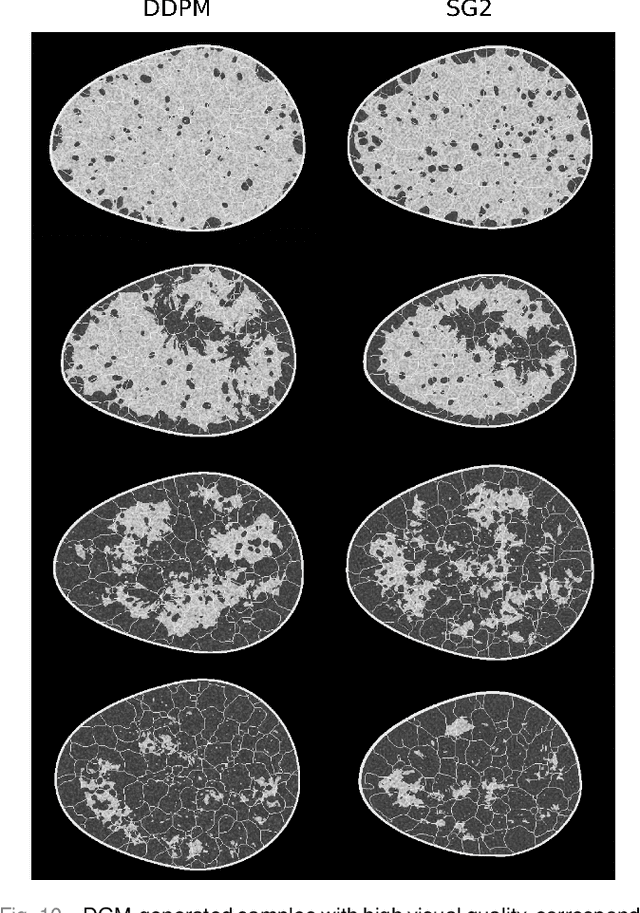
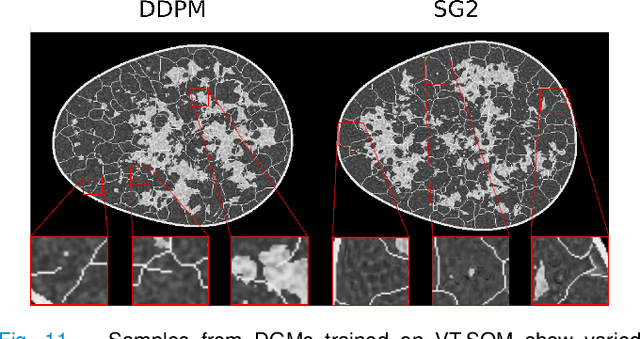

Diffusion models have emerged as a popular family of deep generative models (DGMs). In the literature, it has been claimed that one class of diffusion models -- denoising diffusion probabilistic models (DDPMs) -- demonstrate superior image synthesis performance as compared to generative adversarial networks (GANs). To date, these claims have been evaluated using either ensemble-based methods designed for natural images, or conventional measures of image quality such as structural similarity. However, there remains an important need to understand the extent to which DDPMs can reliably learn medical imaging domain-relevant information, which is referred to as `spatial context' in this work. To address this, a systematic assessment of the ability of DDPMs to learn spatial context relevant to medical imaging applications is reported for the first time. A key aspect of the studies is the use of stochastic context models (SCMs) to produce training data. In this way, the ability of the DDPMs to reliably reproduce spatial context can be quantitatively assessed by use of post-hoc image analyses. Error-rates in DDPM-generated ensembles are reported, and compared to those corresponding to a modern GAN. The studies reveal new and important insights regarding the capacity of DDPMs to learn spatial context. Notably, the results demonstrate that DDPMs hold significant capacity for generating contextually correct images that are `interpolated' between training samples, which may benefit data-augmentation tasks in ways that GANs cannot.
Decoupling the Curve Modeling and Pavement Regression for Lane Detection
Sep 19, 2023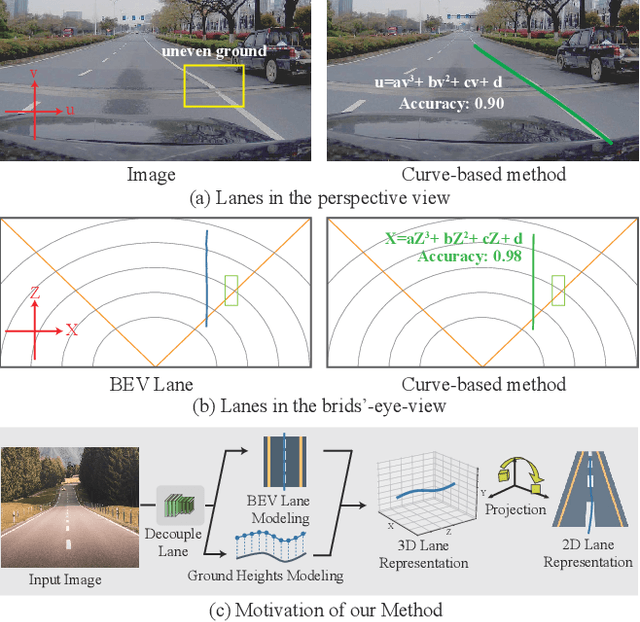
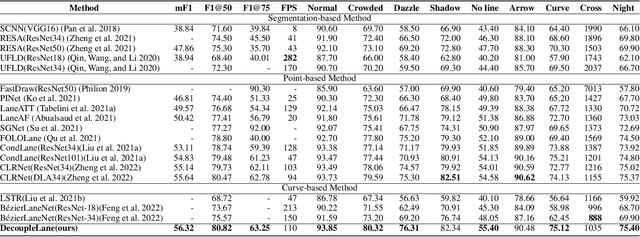
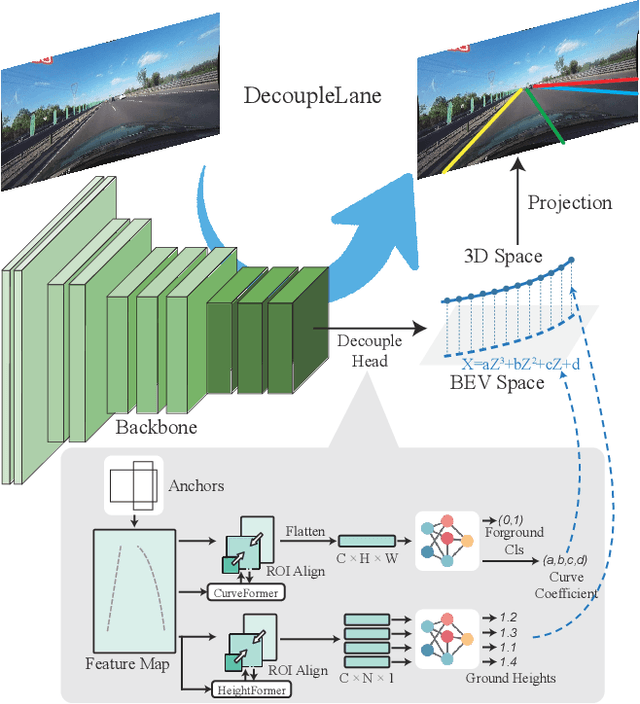
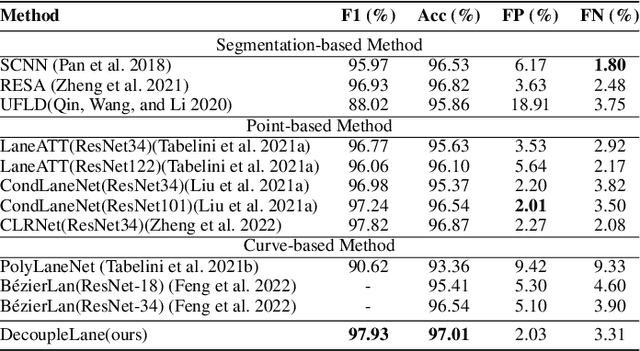
The curve-based lane representation is a popular approach in many lane detection methods, as it allows for the representation of lanes as a whole object and maximizes the use of holistic information about the lanes. However, the curves produced by these methods may not fit well with irregular lines, which can lead to gaps in performance compared to indirect representations such as segmentation-based or point-based methods. We have observed that these lanes are not intended to be irregular, but they appear zigzagged in the perspective view due to being drawn on uneven pavement. In this paper, we propose a new approach to the lane detection task by decomposing it into two parts: curve modeling and ground height regression. Specifically, we use a parameterized curve to represent lanes in the BEV space to reflect the original distribution of lanes. For the second part, since ground heights are determined by natural factors such as road conditions and are less holistic, we regress the ground heights of key points separately from the curve modeling. Additionally, we have unified the 2D and 3D lane detection tasks by designing a new framework and a series of losses to guide the optimization of models with or without 3D lane labels. Our experiments on 2D lane detection benchmarks (TuSimple and CULane), as well as the recently proposed 3D lane detection datasets (ONCE-3Dlane and OpenLane), have shown significant improvements. We will make our well-documented source code publicly available.
FedWOA: A Federated Learning Model that uses the Whale Optimization Algorithm for Renewable Energy Prediction
Sep 19, 2023Privacy is important when dealing with sensitive personal information in machine learning models, which require large data sets for training. In the energy field, access to household prosumer energy data is crucial for energy predictions to support energy grid management and large-scale adoption of renewables however citizens are often hesitant to grant access to cloud-based machine learning models. Federated learning has been proposed as a solution to privacy challenges however report issues in generating the global prediction model due to data heterogeneity, variations in generation patterns, and the high number of parameters leading to even lower prediction accuracy. This paper addresses these challenges by introducing FedWOA a novel federated learning model that employs the Whale Optimization Algorithm to aggregate global prediction models from the weights of local LTSM neural network models trained on prosumer energy data. The proposed solution identifies the optimal vector of weights in the search spaces of the local models to construct the global shared model and then is subsequently transmitted to the local nodes to improve the prediction quality at the prosumer site while for handling non-IID data K-Means was used for clustering prosumers with similar scale of energy data. The evaluation results on prosumers energy data have shown that FedWOA can effectively enhance the accuracy of energy prediction models accuracy by 25% for MSE and 16% for MAE compared to FedAVG while demonstrating good convergence and reduced loss.
MMST-ViT: Climate Change-aware Crop Yield Prediction via Multi-Modal Spatial-Temporal Vision Transformer
Sep 19, 2023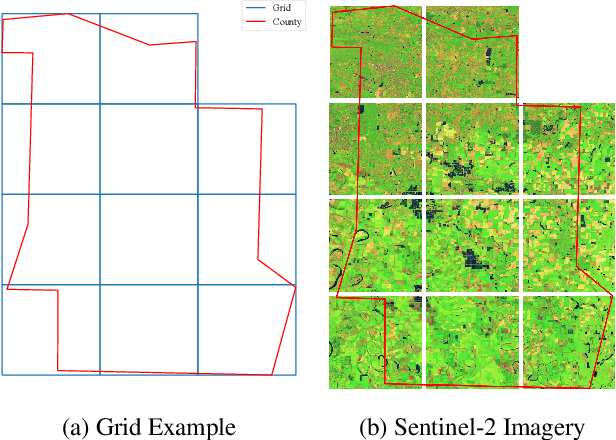

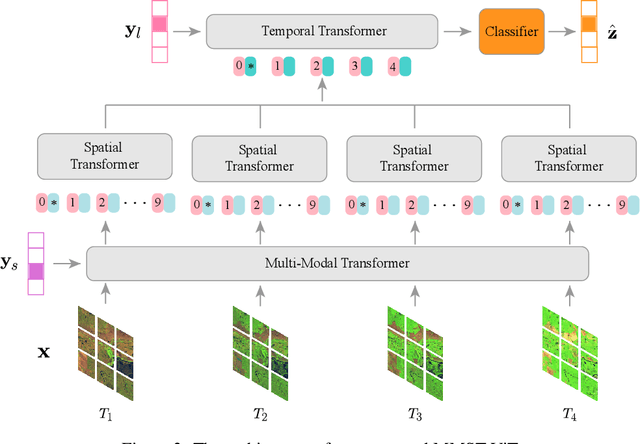

Precise crop yield prediction provides valuable information for agricultural planning and decision-making processes. However, timely predicting crop yields remains challenging as crop growth is sensitive to growing season weather variation and climate change. In this work, we develop a deep learning-based solution, namely Multi-Modal Spatial-Temporal Vision Transformer (MMST-ViT), for predicting crop yields at the county level across the United States, by considering the effects of short-term meteorological variations during the growing season and the long-term climate change on crops. Specifically, our MMST-ViT consists of a Multi-Modal Transformer, a Spatial Transformer, and a Temporal Transformer. The Multi-Modal Transformer leverages both visual remote sensing data and short-term meteorological data for modeling the effect of growing season weather variations on crop growth. The Spatial Transformer learns the high-resolution spatial dependency among counties for accurate agricultural tracking. The Temporal Transformer captures the long-range temporal dependency for learning the impact of long-term climate change on crops. Meanwhile, we also devise a novel multi-modal contrastive learning technique to pre-train our model without extensive human supervision. Hence, our MMST-ViT captures the impacts of both short-term weather variations and long-term climate change on crops by leveraging both satellite images and meteorological data. We have conducted extensive experiments on over 200 counties in the United States, with the experimental results exhibiting that our MMST-ViT outperforms its counterparts under three performance metrics of interest.
Globally Convergent Accelerated Algorithms for Multilinear Sparse Logistic Regression with $\ell_0$-constraints
Sep 17, 2023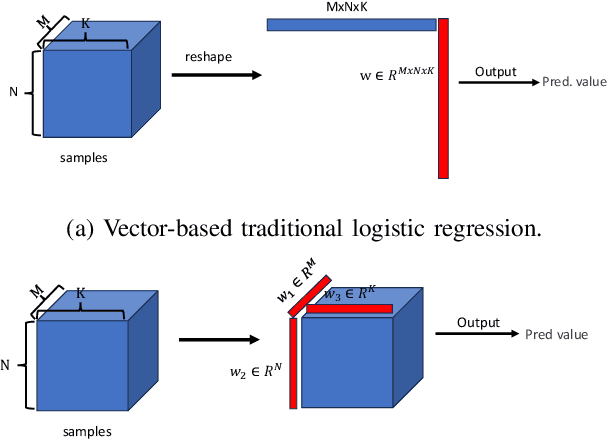
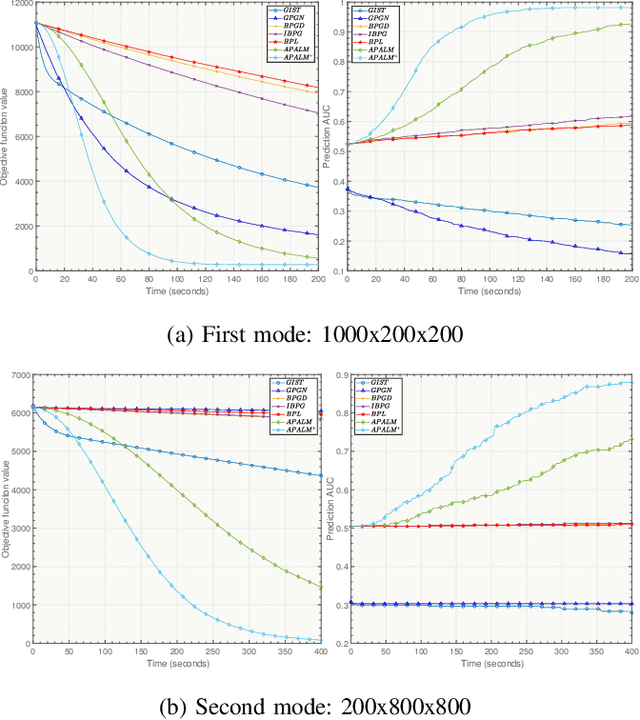
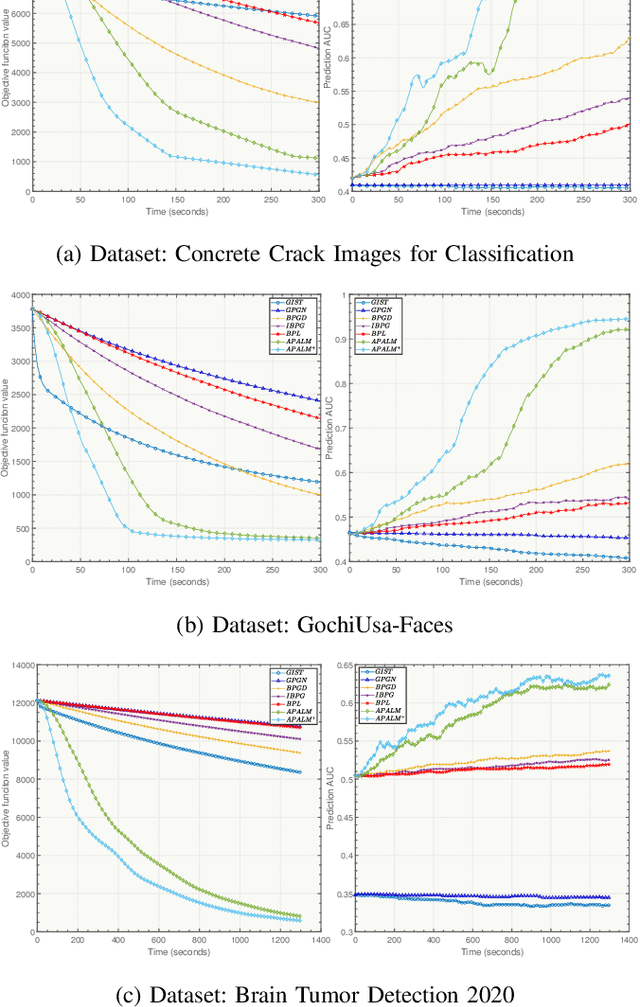

Tensor data represents a multidimensional array. Regression methods based on low-rank tensor decomposition leverage structural information to reduce the parameter count. Multilinear logistic regression serves as a powerful tool for the analysis of multidimensional data. To improve its efficacy and interpretability, we present a Multilinear Sparse Logistic Regression model with $\ell_0$-constraints ($\ell_0$-MLSR). In contrast to the $\ell_1$-norm and $\ell_2$-norm, the $\ell_0$-norm constraint is better suited for feature selection. However, due to its nonconvex and nonsmooth properties, solving it is challenging and convergence guarantees are lacking. Additionally, the multilinear operation in $\ell_0$-MLSR also brings non-convexity. To tackle these challenges, we propose an Accelerated Proximal Alternating Linearized Minimization with Adaptive Momentum (APALM$^+$) method to solve the $\ell_0$-MLSR model. We provide a proof that APALM$^+$ can ensure the convergence of the objective function of $\ell_0$-MLSR. We also demonstrate that APALM$^+$ is globally convergent to a first-order critical point as well as establish convergence rate by using the Kurdyka-Lojasiewicz property. Empirical results obtained from synthetic and real-world datasets validate the superior performance of our algorithm in terms of both accuracy and speed compared to other state-of-the-art methods.
ChatGPT Hallucinates when Attributing Answers
Sep 17, 2023
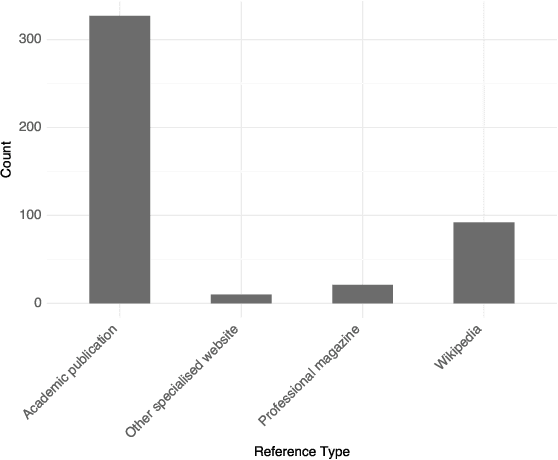
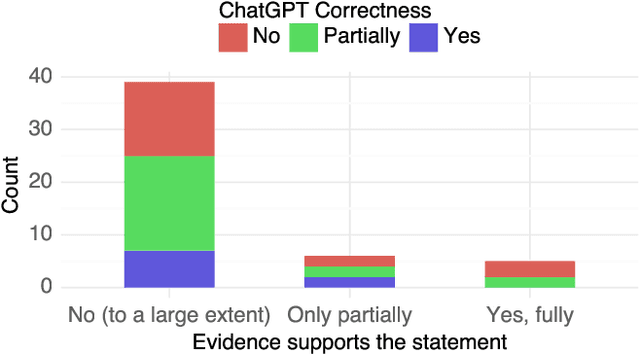
Can ChatGPT provide evidence to support its answers? Does the evidence it suggests actually exist and does it really support its answer? We investigate these questions using a collection of domain-specific knowledge-based questions, specifically prompting ChatGPT to provide both an answer and supporting evidence in the form of references to external sources. We also investigate how different prompts impact answers and evidence. We find that ChatGPT provides correct or partially correct answers in about half of the cases (50.6% of the times), but its suggested references only exist 14% of the times. We further provide insights on the generated references that reveal common traits among the references that ChatGPT generates, and show how even if a reference provided by the model does exist, this reference often does not support the claims ChatGPT attributes to it. Our findings are important because (1) they are the first systematic analysis of the references created by ChatGPT in its answers; (2) they suggest that the model may leverage good quality information in producing correct answers, but is unable to attribute real evidence to support its answers. Prompts, raw result files and manual analysis are made publicly available.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023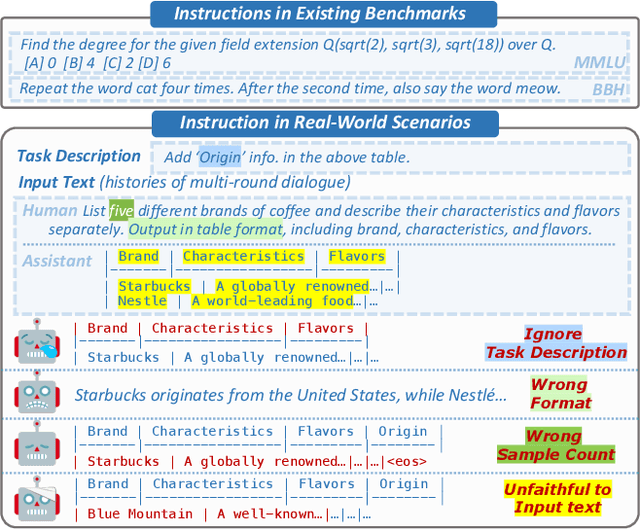
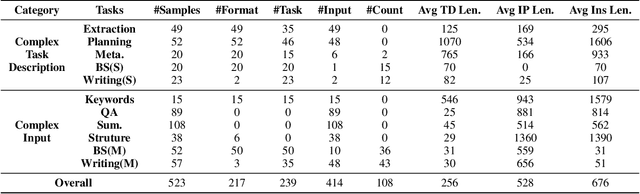

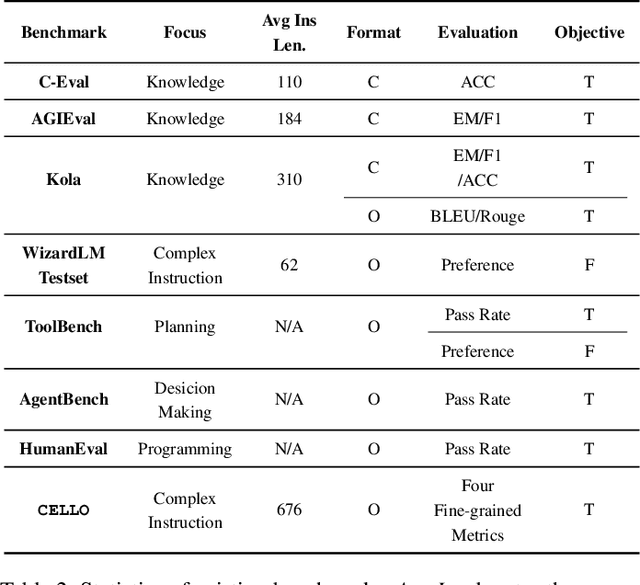
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.
Private Matrix Factorization with Public Item Features
Sep 17, 2023We consider the problem of training private recommendation models with access to public item features. Training with Differential Privacy (DP) offers strong privacy guarantees, at the expense of loss in recommendation quality. We show that incorporating public item features during training can help mitigate this loss in quality. We propose a general approach based on collective matrix factorization (CMF), that works by simultaneously factorizing two matrices: the user feedback matrix (representing sensitive data) and an item feature matrix that encodes publicly available (non-sensitive) item information. The method is conceptually simple, easy to tune, and highly scalable. It can be applied to different types of public item data, including: (1) categorical item features; (2) item-item similarities learned from public sources; and (3) publicly available user feedback. Furthermore, these data modalities can be collectively utilized to fully leverage public data. Evaluating our method on a standard DP recommendation benchmark, we find that using public item features significantly narrows the quality gap between private models and their non-private counterparts. As privacy constraints become more stringent, models rely more heavily on public side features for recommendation. This results in a smooth transition from collaborative filtering to item-based contextual recommendations.