 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fundamental CRB-Rate Tradeoff in Multi-Antenna ISAC Systems with Information Multicasting and Multi-Target Sensing
Jul 21, 2023
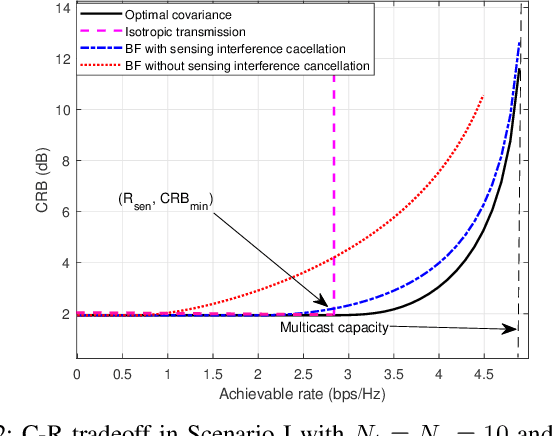
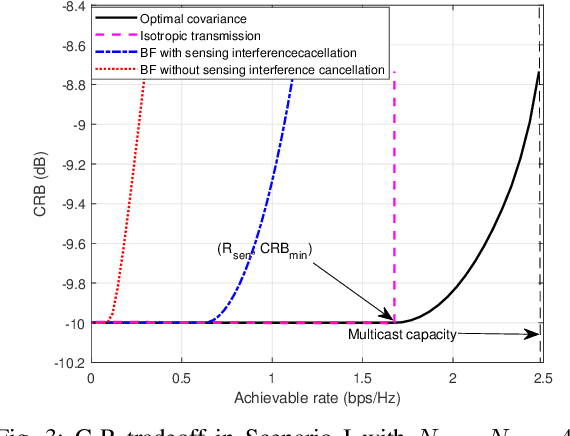
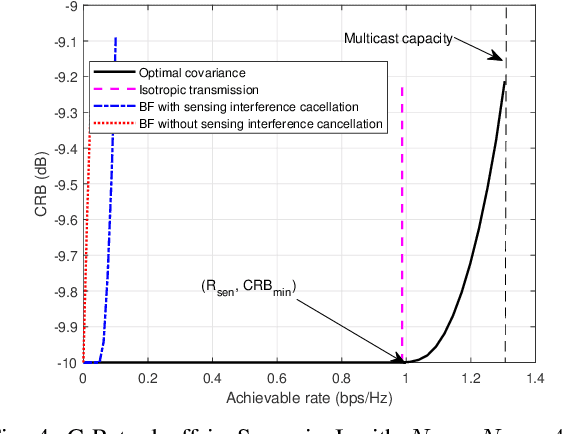
This paper investigates the performance tradeoff for a multi-antenna integrated sensing and communication (ISAC) system with simultaneous information multicasting and multi-target sensing, in which a multi-antenna base station (BS) sends the common information messages to a set of single-antenna communication users (CUs) and estimates the parameters of multiple sensing targets based on the echo signals concurrently. We consider two target sensing scenarios without and with prior target knowledge at the BS, in which the BS is interested in estimating the complete multi-target response matrix and the target reflection coefficients/angles, respectively. First, we consider the capacity-achieving transmission and characterize the fundamental tradeoff between the achievable rate and the multi-target estimation Cram\'er-Rao bound (CRB) accordingly.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023
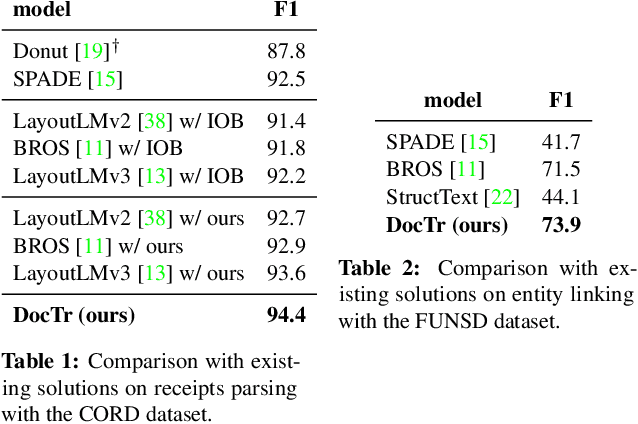
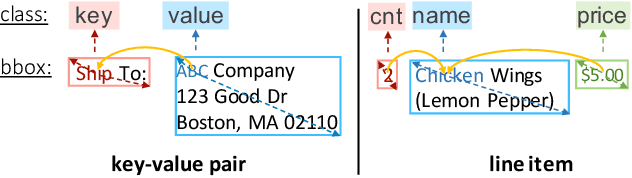
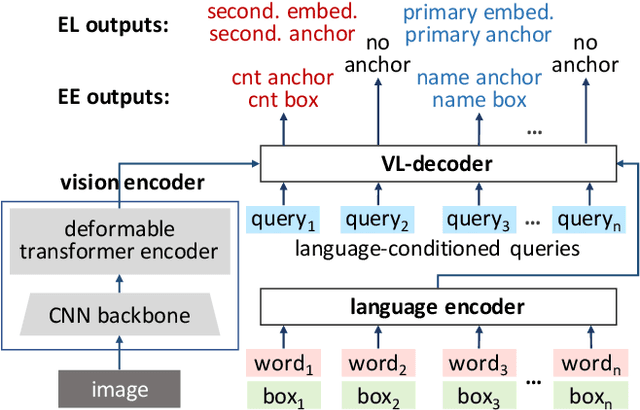
We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
Single Biological Neurons as Temporally Precise Spatio-Temporal Pattern Recognizers
Sep 26, 2023This PhD thesis is focused on the central idea that single neurons in the brain should be regarded as temporally precise and highly complex spatio-temporal pattern recognizers. This is opposed to the prevalent view of biological neurons as simple and mainly spatial pattern recognizers by most neuroscientists today. In this thesis, I will attempt to demonstrate that this is an important distinction, predominantly because the above-mentioned computational properties of single neurons have far-reaching implications with respect to the various brain circuits that neurons compose, and on how information is encoded by neuronal activity in the brain. Namely, that these particular "low-level" details at the single neuron level have substantial system-wide ramifications. In the introduction we will highlight the main components that comprise a neural microcircuit that can perform useful computations and illustrate the inter-dependence of these components from a system perspective. In chapter 1 we discuss the great complexity of the spatio-temporal input-output relationship of cortical neurons that are the result of morphological structure and biophysical properties of the neuron. In chapter 2 we demonstrate that single neurons can generate temporally precise output patterns in response to specific spatio-temporal input patterns with a very simple biologically plausible learning rule. In chapter 3, we use the differentiable deep network analog of a realistic cortical neuron as a tool to approximate the gradient of the output of the neuron with respect to its input and use this capability in an attempt to teach the neuron to perform nonlinear XOR operation. In chapter 4 we expand chapter 3 to describe extension of our ideas to neuronal networks composed of many realistic biological spiking neurons that represent either small microcircuits or entire brain regions.
Light Field Diffusion for Single-View Novel View Synthesis
Sep 23, 2023Single-view novel view synthesis, the task of generating images from new viewpoints based on a single reference image, is an important but challenging task in computer vision. Recently, Denoising Diffusion Probabilistic Model (DDPM) has become popular in this area due to its strong ability to generate high-fidelity images. However, current diffusion-based methods directly rely on camera pose matrices as viewing conditions, globally and implicitly introducing 3D constraints. These methods may suffer from inconsistency among generated images from different perspectives, especially in regions with intricate textures and structures. In this work, we present Light Field Diffusion (LFD), a conditional diffusion-based model for single-view novel view synthesis. Unlike previous methods that employ camera pose matrices, LFD transforms the camera view information into light field encoding and combines it with the reference image. This design introduces local pixel-wise constraints within the diffusion models, thereby encouraging better multi-view consistency. Experiments on several datasets show that our LFD can efficiently generate high-fidelity images and maintain better 3D consistency even in intricate regions. Our method can generate images with higher quality than NeRF-based models, and we obtain sample quality similar to other diffusion-based models but with only one-third of the model size.
Limits of Actor-Critic Algorithms for Decision Tree Policies Learning in IBMDPs
Sep 23, 2023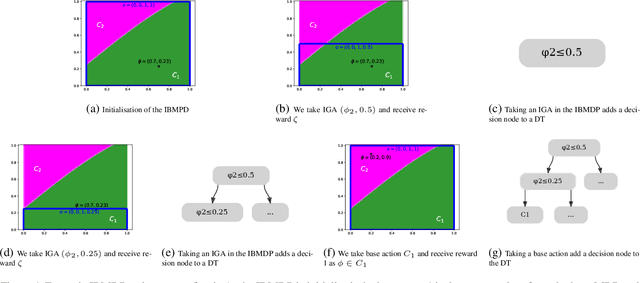
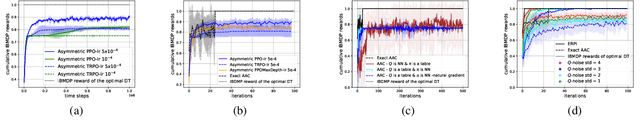
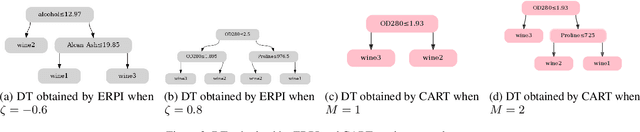
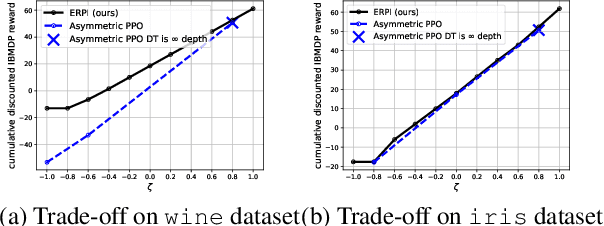
Interpretability of AI models allows for user safety checks to build trust in such AIs. In particular, Decision Trees (DTs) provide a global look at the learned model and transparently reveal which features of the input are critical for making a decision. However, interpretability is hindered if the DT is too large. To learn compact trees, a recent Reinforcement Learning (RL) framework has been proposed to explore the space of DTs using deep RL. This framework augments a decision problem (e.g. a supervised classification task) with additional actions that gather information about the features of an otherwise hidden input. By appropriately penalizing these actions, the agent learns to optimally trade-off size and performance of DTs. In practice, a reactive policy for a partially observable Markov decision process (MDP) needs to be learned, which is still an open problem. We show in this paper that deep RL can fail even on simple toy tasks of this class. However, when the underlying decision problem is a supervised classification task, we show that finding the optimal tree can be cast as a fully observable Markov decision problem and be solved efficiently, giving rise to a new family of algorithms for learning DTs that go beyond the classical greedy maximization ones.
LLMs as Counterfactual Explanation Modules: Can ChatGPT Explain Black-box Text Classifiers?
Sep 23, 2023Large language models (LLMs) are increasingly being used for tasks beyond text generation, including complex tasks such as data labeling, information extraction, etc. With the recent surge in research efforts to comprehend the full extent of LLM capabilities, in this work, we investigate the role of LLMs as counterfactual explanation modules, to explain decisions of black-box text classifiers. Inspired by causal thinking, we propose a pipeline for using LLMs to generate post-hoc, model-agnostic counterfactual explanations in a principled way via (i) leveraging the textual understanding capabilities of the LLM to identify and extract latent features, and (ii) leveraging the perturbation and generation capabilities of the same LLM to generate a counterfactual explanation by perturbing input features derived from the extracted latent features. We evaluate three variants of our framework, with varying degrees of specificity, on a suite of state-of-the-art LLMs, including ChatGPT and LLaMA 2. We evaluate the effectiveness and quality of the generated counterfactual explanations, over a variety of text classification benchmarks. Our results show varied performance of these models in different settings, with a full two-step feature extraction based variant outperforming others in most cases. Our pipeline can be used in automated explanation systems, potentially reducing human effort.
SUDS: Sanitizing Universal and Dependent Steganography
Sep 23, 2023Steganography, or hiding messages in plain sight, is a form of information hiding that is most commonly used for covert communication. As modern steganographic mediums include images, text, audio, and video, this communication method is being increasingly used by bad actors to propagate malware, exfiltrate data, and discreetly communicate. Current protection mechanisms rely upon steganalysis, or the detection of steganography, but these approaches are dependent upon prior knowledge, such as steganographic signatures from publicly available tools and statistical knowledge about known hiding methods. These dependencies render steganalysis useless against new or unique hiding methods, which are becoming increasingly common with the application of deep learning models. To mitigate the shortcomings of steganalysis, this work focuses on a deep learning sanitization technique called SUDS that is not reliant upon knowledge of steganographic hiding techniques and is able to sanitize universal and dependent steganography. SUDS is tested using least significant bit method (LSB), dependent deep hiding (DDH), and universal deep hiding (UDH). We demonstrate the capabilities and limitations of SUDS by answering five research questions, including baseline comparisons and an ablation study. Additionally, we apply SUDS to a real-world scenario, where it is able to increase the resistance of a poisoned classifier against attacks by 1375%.
HAVE-Net: Hallucinated Audio-Visual Embeddings for Few-Shot Classification with Unimodal Cues
Sep 23, 2023Recognition of remote sensing (RS) or aerial images is currently of great interest, and advancements in deep learning algorithms added flavor to it in recent years. Occlusion, intra-class variance, lighting, etc., might arise while training neural networks using unimodal RS visual input. Even though joint training of audio-visual modalities improves classification performance in a low-data regime, it has yet to be thoroughly investigated in the RS domain. Here, we aim to solve a novel problem where both the audio and visual modalities are present during the meta-training of a few-shot learning (FSL) classifier; however, one of the modalities might be missing during the meta-testing stage. This problem formulation is pertinent in the RS domain, given the difficulties in data acquisition or sensor malfunctioning. To mitigate, we propose a novel few-shot generative framework, Hallucinated Audio-Visual Embeddings-Network (HAVE-Net), to meta-train cross-modal features from limited unimodal data. Precisely, these hallucinated features are meta-learned from base classes and used for few-shot classification on novel classes during the inference phase. The experimental results on the benchmark ADVANCE and AudioSetZSL datasets show that our hallucinated modality augmentation strategy for few-shot classification outperforms the classifier performance trained with the real multimodal information at least by 0.8-2%.
Personalized Search Via Neural Contextual Semantic Relevance Ranking
Sep 10, 2023
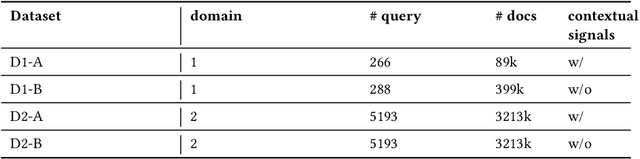
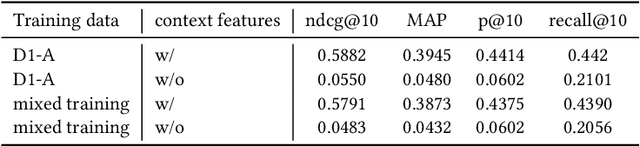
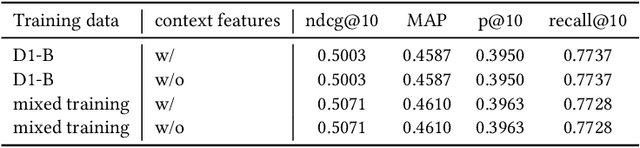
Existing neural relevance models do not give enough consideration for query and item context information which diversifies the search results to adapt for personal preference. To bridge this gap, this paper presents a neural learning framework to personalize document ranking results by leveraging the signals to capture how the document fits into users' context. In particular, it models the relationships between document content and user query context using both lexical representations and semantic embeddings such that the user's intent can be better understood by data enrichment of personalized query context information. Extensive experiments performed on the search dataset, demonstrate the effectiveness of the proposed method.
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 15, 2023
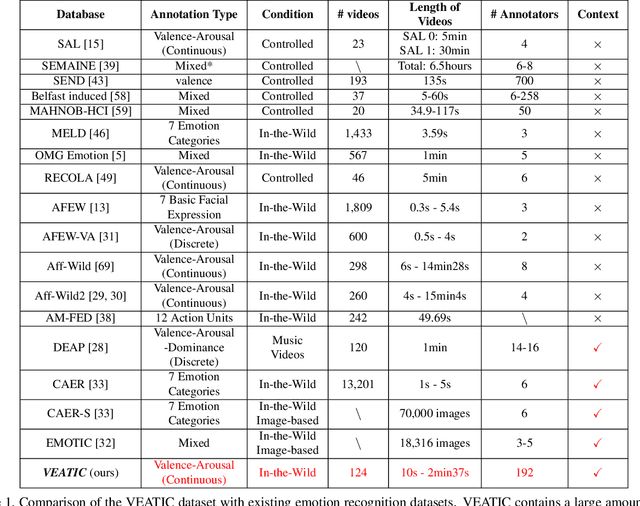

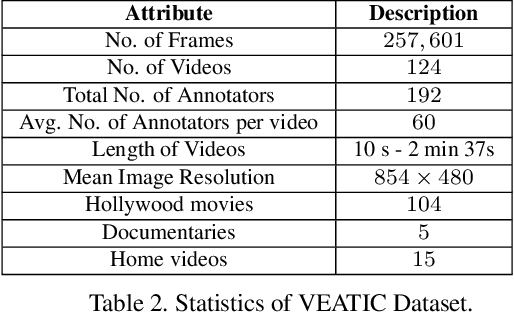
Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.