 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Solution to Co-occurrence Bias: Attributes Disentanglement via Mutual Information Minimization for Pedestrian Attribute Recognition
Jul 28, 2023
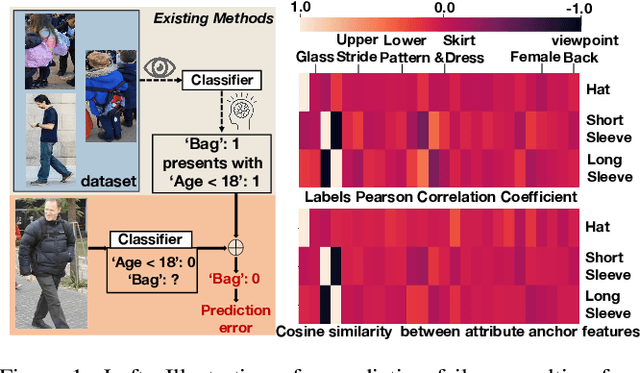
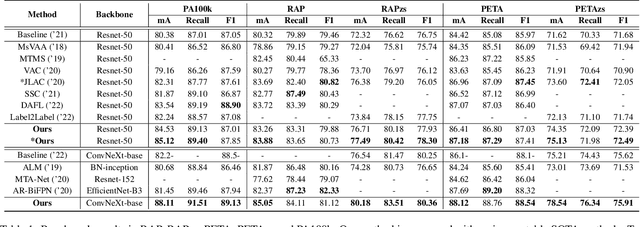
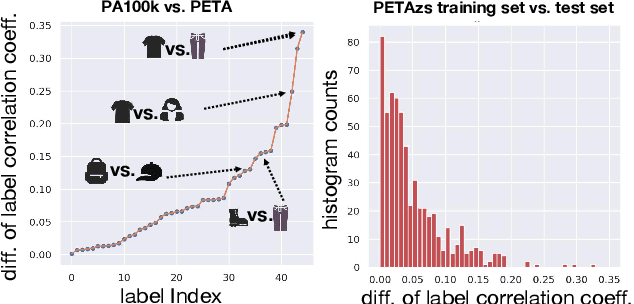
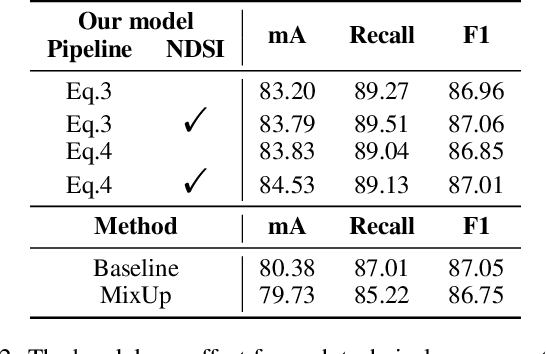
Recent studies on pedestrian attribute recognition progress with either explicit or implicit modeling of the co-occurrence among attributes. Considering that this known a prior is highly variable and unforeseeable regarding the specific scenarios, we show that current methods can actually suffer in generalizing such fitted attributes interdependencies onto scenes or identities off the dataset distribution, resulting in the underlined bias of attributes co-occurrence. To render models robust in realistic scenes, we propose the attributes-disentangled feature learning to ensure the recognition of an attribute not inferring on the existence of others, and which is sequentially formulated as a problem of mutual information minimization. Rooting from it, practical strategies are devised to efficiently decouple attributes, which substantially improve the baseline and establish state-of-the-art performance on realistic datasets like PETAzs and RAPzs. Code is released on https://github.com/SDret/A-Solution-to-Co-occurence-Bias-in-Pedestrian-Attribute-Recognition.
Deep Learning Meets Swarm Intelligence for UAV-Assisted IoT Coverage in Massive MIMO
Sep 21, 2023This study considers a UAV-assisted multi-user massive multiple-input multiple-output (MU-mMIMO) systems, where a decode-and-forward (DF) relay in the form of an unmanned aerial vehicle (UAV) facilitates the transmission of multiple data streams from a base station (BS) to multiple Internet-of-Things (IoT) users. A joint optimization problem of hybrid beamforming (HBF), UAV relay positioning, and power allocation (PA) to multiple IoT users to maximize the total achievable rate (AR) is investigated. The study adopts a geometry-based millimeter-wave (mmWave) channel model for both links and proposes three different swarm intelligence (SI)-based algorithmic solutions to optimize: 1) UAV location with equal PA; 2) PA with fixed UAV location; and 3) joint PA with UAV deployment. The radio frequency (RF) stages are designed to reduce the number of RF chains based on the slow time-varying angular information, while the baseband (BB) stages are designed using the reduced-dimension effective channel matrices. Then, a novel deep learning (DL)-based low-complexity joint hybrid beamforming, UAV location and power allocation optimization scheme (J-HBF-DLLPA) is proposed via fully-connected deep neural network (DNN), consisting of an offline training phase, and an online prediction of UAV location and optimal power values for maximizing the AR. The illustrative results show that the proposed algorithmic solutions can attain higher capacity and reduce average delay for delay-constrained transmissions in a UAV-assisted MU-mMIMO IoT systems. Additionally, the proposed J-HBF-DLLPA can closely approach the optimal capacity while significantly reducing the runtime by 99%, which makes the DL-based solution a promising implementation for real-time online applications in UAV-assisted MU-mMIMO IoT systems.
End-to-End Learning on Multimodal Knowledge Graphs
Sep 03, 2023Knowledge graphs enable data scientists to learn end-to-end on heterogeneous knowledge. However, most end-to-end models solely learn from the relational information encoded in graphs' structure: raw values, encoded as literal nodes, are either omitted completely or treated as regular nodes without consideration for their values. In either case we lose potentially relevant information which could have otherwise been exploited by our learning methods. We propose a multimodal message passing network which not only learns end-to-end from the structure of graphs, but also from their possibly divers set of multimodal node features. Our model uses dedicated (neural) encoders to naturally learn embeddings for node features belonging to five different types of modalities, including numbers, texts, dates, images and geometries, which are projected into a joint representation space together with their relational information. We implement and demonstrate our model on node classification and link prediction for artificial and real-worlds datasets, and evaluate the effect that each modality has on the overall performance in an inverse ablation study. Our results indicate that end-to-end multimodal learning from any arbitrary knowledge graph is indeed possible, and that including multimodal information can significantly affect performance, but that much depends on the characteristics of the data.
Cross-Task Attention Network: Improving Multi-Task Learning for Medical Imaging Applications
Sep 07, 2023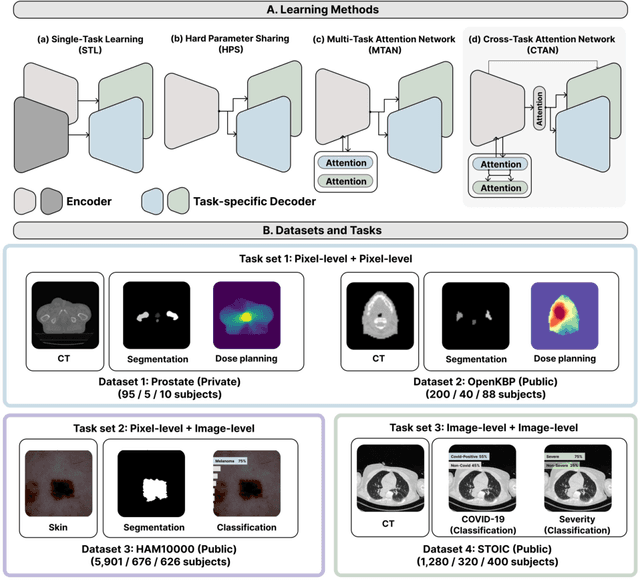

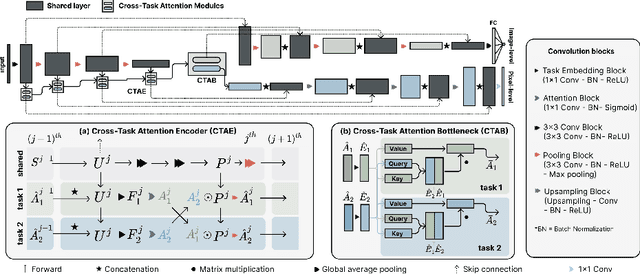
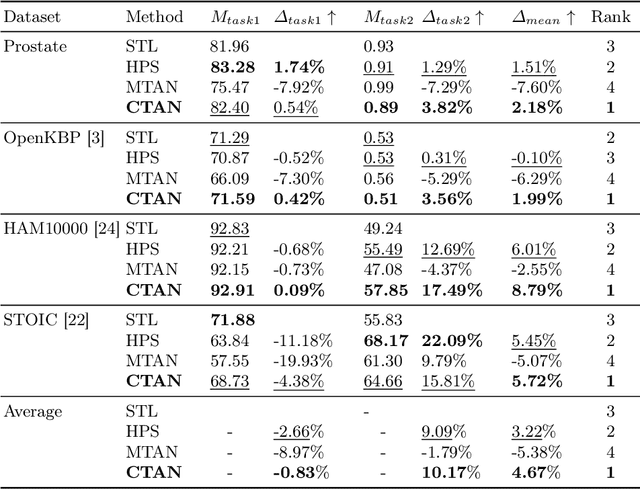
Multi-task learning (MTL) is a powerful approach in deep learning that leverages the information from multiple tasks during training to improve model performance. In medical imaging, MTL has shown great potential to solve various tasks. However, existing MTL architectures in medical imaging are limited in sharing information across tasks, reducing the potential performance improvements of MTL. In this study, we introduce a novel attention-based MTL framework to better leverage inter-task interactions for various tasks from pixel-level to image-level predictions. Specifically, we propose a Cross-Task Attention Network (CTAN) which utilizes cross-task attention mechanisms to incorporate information by interacting across tasks. We validated CTAN on four medical imaging datasets that span different domains and tasks including: radiation treatment planning prediction using planning CT images of two different target cancers (Prostate, OpenKBP); pigmented skin lesion segmentation and diagnosis using dermatoscopic images (HAM10000); and COVID-19 diagnosis and severity prediction using chest CT scans (STOIC). Our study demonstrates the effectiveness of CTAN in improving the accuracy of medical imaging tasks. Compared to standard single-task learning (STL), CTAN demonstrated a 4.67% improvement in performance and outperformed both widely used MTL baselines: hard parameter sharing (HPS) with an average performance improvement of 3.22%; and multi-task attention network (MTAN) with a relative decrease of 5.38%. These findings highlight the significance of our proposed MTL framework in solving medical imaging tasks and its potential to improve their accuracy across domains.
Prompting Segmentation with Sound is Generalizable Audio-Visual Source Localizer
Sep 18, 2023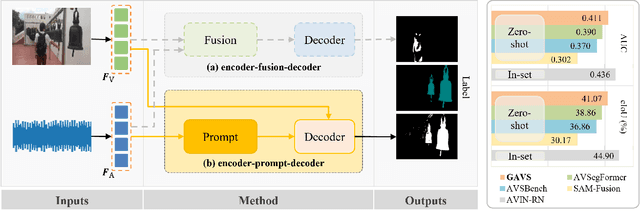
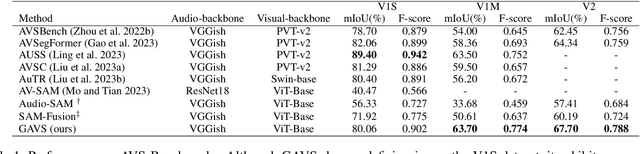
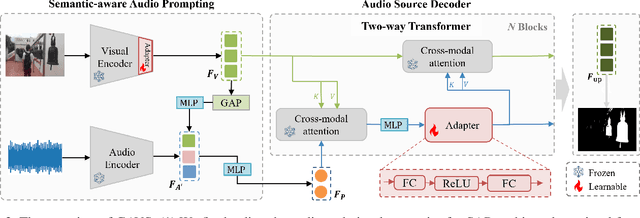

Never having seen an object and heard its sound simultaneously, can the model still accurately localize its visual position from the input audio? In this work, we concentrate on the Audio-Visual Localization and Segmentation tasks but under the demanding zero-shot and few-shot scenarios. To achieve this goal, different from existing approaches that mostly employ the encoder-fusion-decoder paradigm to decode localization information from the fused audio-visual feature, we introduce the encoder-prompt-decoder paradigm, aiming to better fit the data scarcity and varying data distribution dilemmas with the help of abundant knowledge from pre-trained models. Specifically, we first propose to construct Semantic-aware Audio Prompt (SAP) to help the visual foundation model focus on sounding objects, meanwhile, the semantic gap between the visual and audio modalities is also encouraged to shrink. Then, we develop a Correlation Adapter (ColA) to keep minimal training efforts as well as maintain adequate knowledge of the visual foundation model. By equipping with these means, extensive experiments demonstrate that this new paradigm outperforms other fusion-based methods in both the unseen class and cross-dataset settings. We hope that our work can further promote the generalization study of Audio-Visual Localization and Segmentation in practical application scenarios.
Target-aware Bi-Transformer for Few-shot Segmentation
Sep 18, 2023Traditional semantic segmentation tasks require a large number of labels and are difficult to identify unlearned categories. Few-shot semantic segmentation (FSS) aims to use limited labeled support images to identify the segmentation of new classes of objects, which is very practical in the real world. Previous researches were primarily based on prototypes or correlations. Due to colors, textures, and styles are similar in the same image, we argue that the query image can be regarded as its own support image. In this paper, we proposed the Target-aware Bi-Transformer Network (TBTNet) to equivalent treat of support images and query image. A vigorous Target-aware Transformer Layer (TTL) also be designed to distill correlations and force the model to focus on foreground information. It treats the hypercorrelation as a feature, resulting a significant reduction in the number of feature channels. Benefit from this characteristic, our model is the lightest up to now with only 0.4M learnable parameters. Futhermore, TBTNet converges in only 10% to 25% of the training epochs compared to traditional methods. The excellent performance on standard FSS benchmarks of PASCAL-5i and COCO-20i proves the efficiency of our method. Extensive ablation studies were also carried out to evaluate the effectiveness of Bi-Transformer architecture and TTL.
Scribble-based 3D Multiple Abdominal Organ Segmentation via Triple-branch Multi-dilated Network with Pixel- and Class-wise Consistency
Sep 18, 2023Multi-organ segmentation in abdominal Computed Tomography (CT) images is of great importance for diagnosis of abdominal lesions and subsequent treatment planning. Though deep learning based methods have attained high performance, they rely heavily on large-scale pixel-level annotations that are time-consuming and labor-intensive to obtain. Due to its low dependency on annotation, weakly supervised segmentation has attracted great attention. However, there is still a large performance gap between current weakly-supervised methods and fully supervised learning, leaving room for exploration. In this work, we propose a novel 3D framework with two consistency constraints for scribble-supervised multiple abdominal organ segmentation from CT. Specifically, we employ a Triple-branch multi-Dilated network (TDNet) with one encoder and three decoders using different dilation rates to capture features from different receptive fields that are complementary to each other to generate high-quality soft pseudo labels. For more stable unsupervised learning, we use voxel-wise uncertainty to rectify the soft pseudo labels and then supervise the outputs of each decoder. To further regularize the network, class relationship information is exploited by encouraging the generated class affinity matrices to be consistent across different decoders under multi-view projection. Experiments on the public WORD dataset show that our method outperforms five existing scribble-supervised methods.
Multi-user beamforming in RIS-aided communications and experimental validations
Sep 18, 2023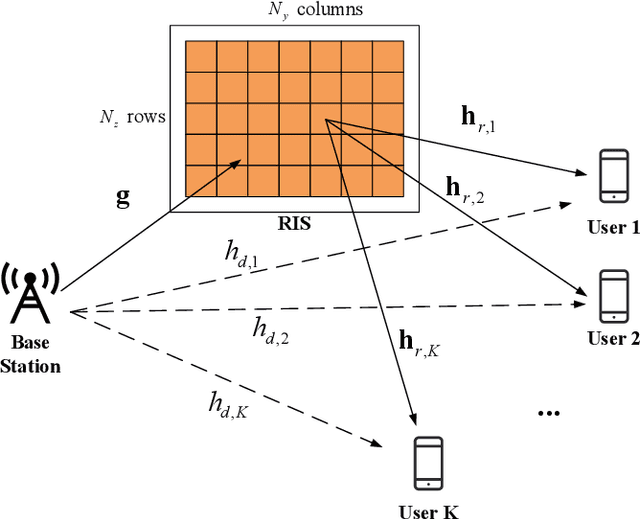
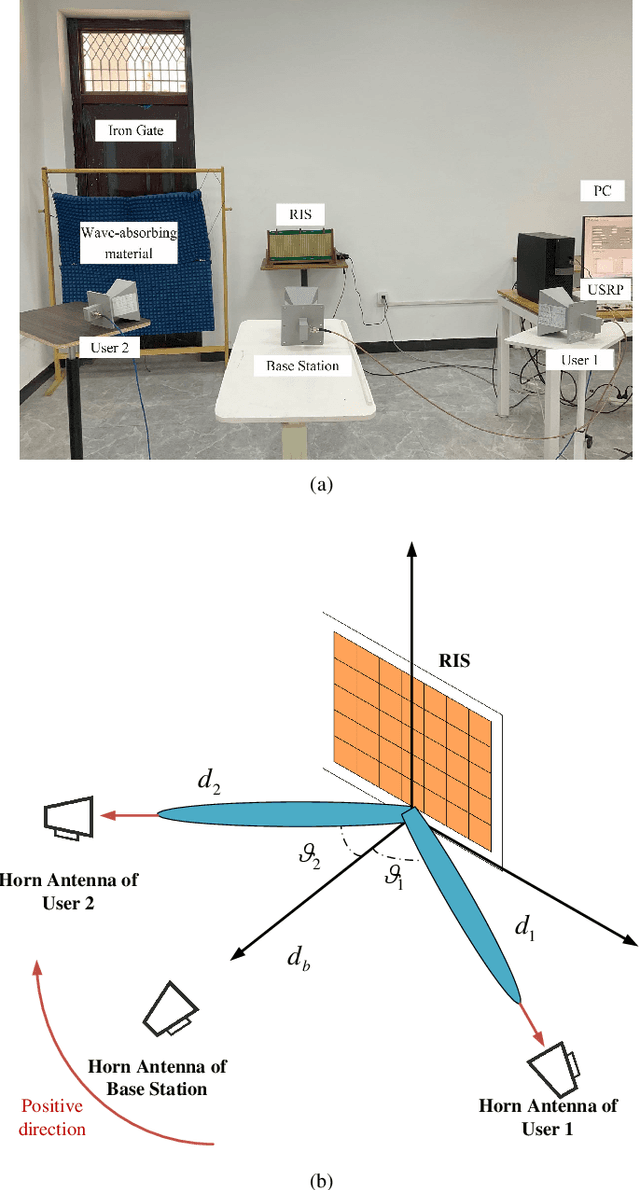
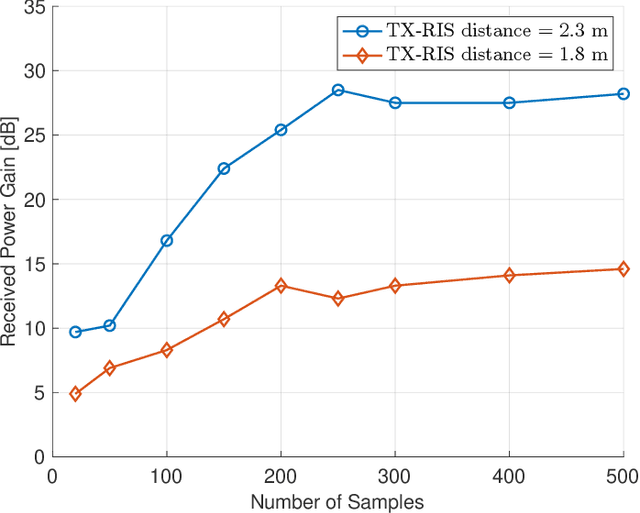
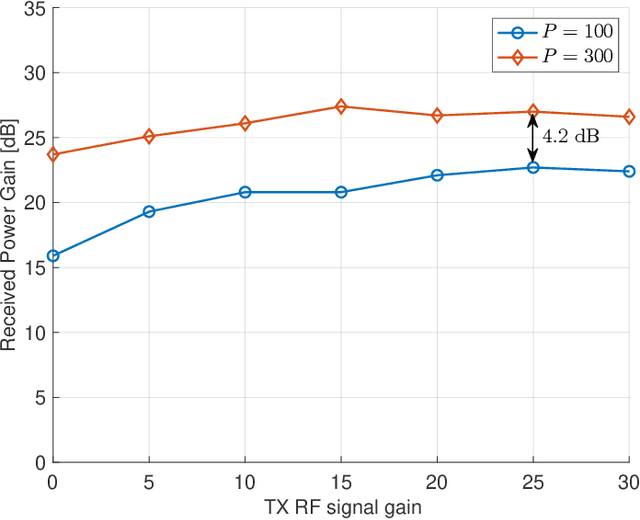
Reconfigurable intelligent surface (RIS) is a promising technology for future wireless communications due to its capability of optimizing the propagation environments. Nevertheless, in literature, there are few prototypes serving multiple users. In this paper, we propose a whole flow of channel estimation and beamforming design for RIS, and set up an RIS-aided multi-user system for experimental validations. Specifically, we combine a channel sparsification step with generalized approximate message passing (GAMP) algorithm, and propose to generate the measurement matrix as Rademacher distribution to obtain the channel state information (CSI). To generate the reflection coefficients with the aim of maximizing the spectral efficiency, we propose a quadratic transform-based low-rank multi-user beamforming (QTLM) algorithm. Our proposed algorithms exploit the sparsity and low-rank properties of the channel, which has the advantages of light calculation and fast convergence. Based on the universal software radio peripheral devices, we built a complete testbed working at 5.8GHz and implemented all the proposed algorithms to verify the possibility of RIS assisting multi-user systems. Experimental results show that the system has obtained an average spectral efficiency increase of 13.48bps/Hz, with respective received power gains of 26.6dB and 17.5dB for two users, compared with the case when RIS is powered-off.
Double Deep Q-Learning-based Path Selection and Service Placement for Latency-Sensitive Beyond 5G Applications
Sep 18, 2023Nowadays, as the need for capacity continues to grow, entirely novel services are emerging. A solid cloud-network integrated infrastructure is necessary to supply these services in a real-time responsive, and scalable way. Due to their diverse characteristics and limited capacity, communication and computing resources must be collaboratively managed to unleash their full potential. Although several innovative methods have been proposed to orchestrate the resources, most ignored network resources or relaxed the network as a simple graph, focusing only on cloud resources. This paper fills the gap by studying the joint problem of communication and computing resource allocation, dubbed CCRA, including function placement and assignment, traffic prioritization, and path selection considering capacity constraints and quality requirements, to minimize total cost. We formulate the problem as a non-linear programming model and propose two approaches, dubbed B\&B-CCRA and WF-CCRA, based on the Branch \& Bound and Water-Filling algorithms to solve it when the system is fully known. Then, for partially known systems, a Double Deep Q-Learning (DDQL) architecture is designed. Numerical simulations show that B\&B-CCRA optimally solves the problem, whereas WF-CCRA delivers near-optimal solutions in a substantially shorter time. Furthermore, it is demonstrated that DDQL-CCRA obtains near-optimal solutions in the absence of request-specific information.
Stochastic Deep Koopman Model for Quality Propagation Analysis in Multistage Manufacturing Systems
Sep 18, 2023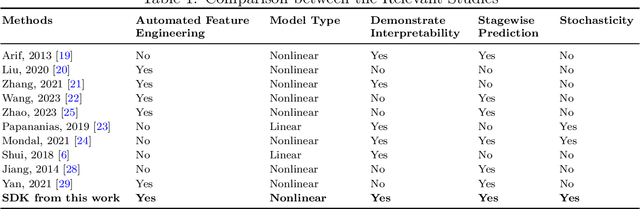
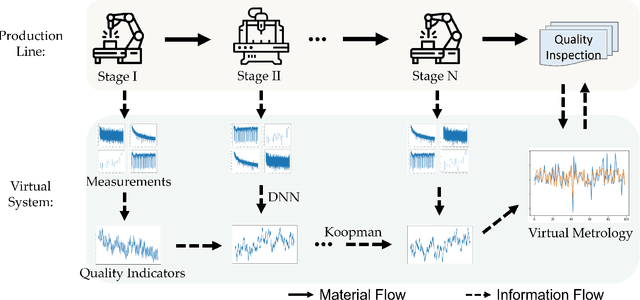
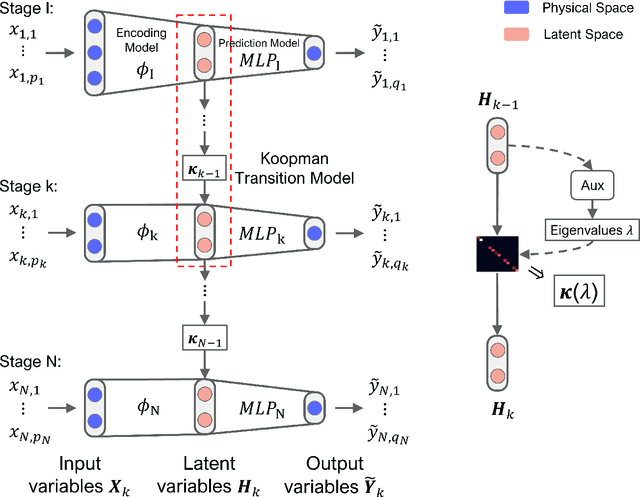
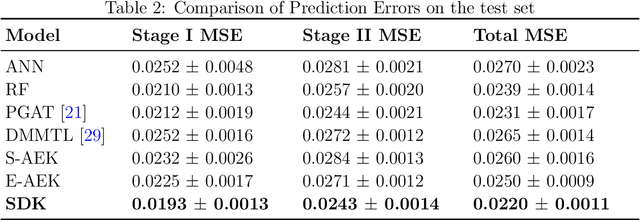
The modeling of multistage manufacturing systems (MMSs) has attracted increased attention from both academia and industry. Recent advancements in deep learning methods provide an opportunity to accomplish this task with reduced cost and expertise. This study introduces a stochastic deep Koopman (SDK) framework to model the complex behavior of MMSs. Specifically, we present a novel application of Koopman operators to propagate critical quality information extracted by variational autoencoders. Through this framework, we can effectively capture the general nonlinear evolution of product quality using a transferred linear representation, thus enhancing the interpretability of the data-driven model. To evaluate the performance of the SDK framework, we carried out a comparative study on an open-source dataset. The main findings of this paper are as follows. Our results indicate that SDK surpasses other popular data-driven models in accuracy when predicting stagewise product quality within the MMS. Furthermore, the unique linear propagation property in the stochastic latent space of SDK enables traceability for quality evolution throughout the process, thereby facilitating the design of root cause analysis schemes. Notably, the proposed framework requires minimal knowledge of the underlying physics of production lines. It serves as a virtual metrology tool that can be applied to various MMSs, contributing to the ultimate goal of Zero Defect Manufacturing.