 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decoding Probing: Revealing Internal Linguistic Structures in Neural Language Models using Minimal Pairs
Mar 26, 2024
Inspired by cognitive neuroscience studies, we introduce a novel `decoding probing' method that uses minimal pairs benchmark (BLiMP) to probe internal linguistic characteristics in neural language models layer by layer. By treating the language model as the `brain' and its representations as `neural activations', we decode grammaticality labels of minimal pairs from the intermediate layers' representations. This approach reveals: 1) Self-supervised language models capture abstract linguistic structures in intermediate layers that GloVe and RNN language models cannot learn. 2) Information about syntactic grammaticality is robustly captured through the first third layers of GPT-2 and also distributed in later layers. As sentence complexity increases, more layers are required for learning grammatical capabilities. 3) Morphological and semantics/syntax interface-related features are harder to capture than syntax. 4) For Transformer-based models, both embeddings and attentions capture grammatical features but show distinct patterns. Different attention heads exhibit similar tendencies toward various linguistic phenomena, but with varied contributions.
Powerful Lossy Compression for Noisy Images
Mar 26, 2024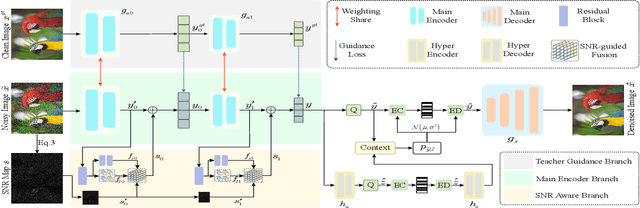
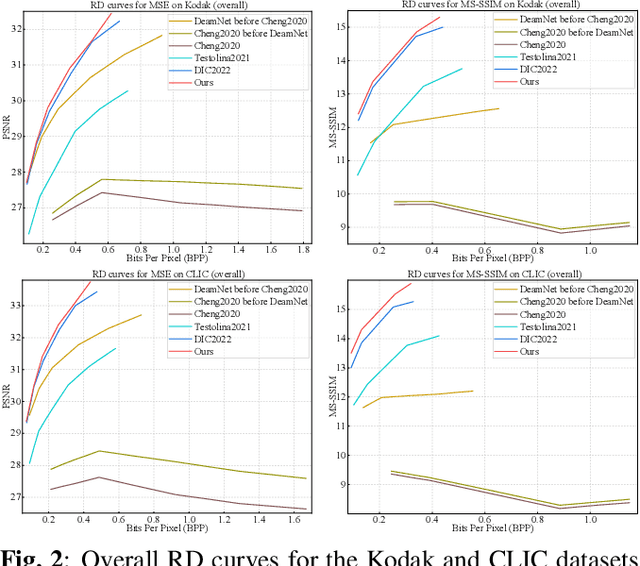
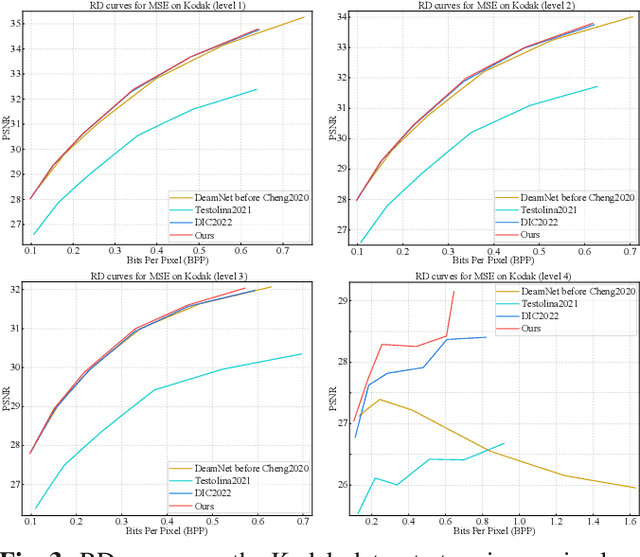
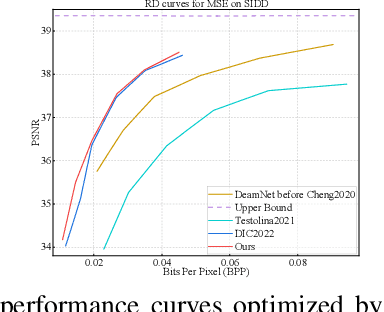
Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
OCAI: Improving Optical Flow Estimation by Occlusion and Consistency Aware Interpolation
Mar 26, 2024The scarcity of ground-truth labels poses one major challenge in developing optical flow estimation models that are both generalizable and robust. While current methods rely on data augmentation, they have yet to fully exploit the rich information available in labeled video sequences. We propose OCAI, a method that supports robust frame interpolation by generating intermediate video frames alongside optical flows in between. Utilizing a forward warping approach, OCAI employs occlusion awareness to resolve ambiguities in pixel values and fills in missing values by leveraging the forward-backward consistency of optical flows. Additionally, we introduce a teacher-student style semi-supervised learning method on top of the interpolated frames. Using a pair of unlabeled frames and the teacher model's predicted optical flow, we generate interpolated frames and flows to train a student model. The teacher's weights are maintained using Exponential Moving Averaging of the student. Our evaluations demonstrate perceptually superior interpolation quality and enhanced optical flow accuracy on established benchmarks such as Sintel and KITTI.
DS-NeRV: Implicit Neural Video Representation with Decomposed Static and Dynamic Codes
Mar 23, 2024Implicit neural representations for video (NeRV) have recently become a novel way for high-quality video representation. However, existing works employ a single network to represent the entire video, which implicitly confuse static and dynamic information. This leads to an inability to effectively compress the redundant static information and lack the explicitly modeling of global temporal-coherent dynamic details. To solve above problems, we propose DS-NeRV, which decomposes videos into sparse learnable static codes and dynamic codes without the need for explicit optical flow or residual supervision. By setting different sampling rates for two codes and applying weighted sum and interpolation sampling methods, DS-NeRV efficiently utilizes redundant static information while maintaining high-frequency details. Additionally, we design a cross-channel attention-based (CCA) fusion module to efficiently fuse these two codes for frame decoding. Our approach achieves a high quality reconstruction of 31.2 PSNR with only 0.35M parameters thanks to separate static and dynamic codes representation and outperforms existing NeRV methods in many downstream tasks. Our project website is at https://haoyan14.github.io/DS-NeRV.
Point-DETR3D: Leveraging Imagery Data with Spatial Point Prior for Weakly Semi-supervised 3D Object Detection
Mar 25, 2024Training high-accuracy 3D detectors necessitates massive labeled 3D annotations with 7 degree-of-freedom, which is laborious and time-consuming. Therefore, the form of point annotations is proposed to offer significant prospects for practical applications in 3D detection, which is not only more accessible and less expensive but also provides strong spatial information for object localization. In this paper, we empirically discover that it is non-trivial to merely adapt Point-DETR to its 3D form, encountering two main bottlenecks: 1) it fails to encode strong 3D prior into the model, and 2) it generates low-quality pseudo labels in distant regions due to the extreme sparsity of LiDAR points. To overcome these challenges, we introduce Point-DETR3D, a teacher-student framework for weakly semi-supervised 3D detection, designed to fully capitalize on point-wise supervision within a constrained instance-wise annotation budget.Different from Point-DETR which encodes 3D positional information solely through a point encoder, we propose an explicit positional query initialization strategy to enhance the positional prior. Considering the low quality of pseudo labels at distant regions produced by the teacher model, we enhance the detector's perception by incorporating dense imagery data through a novel Cross-Modal Deformable RoI Fusion (D-RoI).Moreover, an innovative point-guided self-supervised learning technique is proposed to allow for fully exploiting point priors, even in student models.Extensive experiments on representative nuScenes dataset demonstrate our Point-DETR3D obtains significant improvements compared to previous works. Notably, with only 5% of labeled data, Point-DETR3D achieves over 90% performance of its fully supervised counterpart.
Causal Discovery from Poisson Branching Structural Causal Model Using High-Order Cumulant with Path Analysis
Mar 25, 2024Count data naturally arise in many fields, such as finance, neuroscience, and epidemiology, and discovering causal structure among count data is a crucial task in various scientific and industrial scenarios. One of the most common characteristics of count data is the inherent branching structure described by a binomial thinning operator and an independent Poisson distribution that captures both branching and noise. For instance, in a population count scenario, mortality and immigration contribute to the count, where survival follows a Bernoulli distribution, and immigration follows a Poisson distribution. However, causal discovery from such data is challenging due to the non-identifiability issue: a single causal pair is Markov equivalent, i.e., $X\rightarrow Y$ and $Y\rightarrow X$ are distributed equivalent. Fortunately, in this work, we found that the causal order from $X$ to its child $Y$ is identifiable if $X$ is a root vertex and has at least two directed paths to $Y$, or the ancestor of $X$ with the most directed path to $X$ has a directed path to $Y$ without passing $X$. Specifically, we propose a Poisson Branching Structure Causal Model (PB-SCM) and perform a path analysis on PB-SCM using high-order cumulants. Theoretical results establish the connection between the path and cumulant and demonstrate that the path information can be obtained from the cumulant. With the path information, causal order is identifiable under some graphical conditions. A practical algorithm for learning causal structure under PB-SCM is proposed and the experiments demonstrate and verify the effectiveness of the proposed method.
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair
Mar 25, 2024Automated program repair has emerged as a powerful technique to mitigate the impact of software bugs on system reliability and user experience. This paper introduces RepairAgent, the first work to address the program repair challenge through an autonomous agent based on a large language model (LLM). Unlike existing deep learning-based approaches, which prompt a model with a fixed prompt or in a fixed feedback loop, our work treats the LLM as an agent capable of autonomously planning and executing actions to fix bugs by invoking suitable tools. RepairAgent freely interleaves gathering information about the bug, gathering repair ingredients, and validating fixes, while deciding which tools to invoke based on the gathered information and feedback from previous fix attempts. Key contributions that enable RepairAgent include a set of tools that are useful for program repair, a dynamically updated prompt format that allows the LLM to interact with these tools, and a finite state machine that guides the agent in invoking the tools. Our evaluation on the popular Defects4J dataset demonstrates RepairAgent's effectiveness in autonomously repairing 164 bugs, including 39 bugs not fixed by prior techniques. Interacting with the LLM imposes an average cost of 270,000 tokens per bug, which, under the current pricing of OpenAI's GPT-3.5 model, translates to 14 cents of USD per bug. To the best of our knowledge, this work is the first to present an autonomous, LLM-based agent for program repair, paving the way for future agent-based techniques in software engineering.
Investigation of the effectiveness of applying ChatGPT in Dialogic Teaching Using Electroencephalography
Mar 25, 2024In recent years, the rapid development of artificial intelligence technology, especially the emergence of large language models (LLMs) such as ChatGPT, has presented significant prospects for application in the field of education. LLMs possess the capability to interpret knowledge, answer questions, and consider context, thus providing support for dialogic teaching to students. Therefore, an examination of the capacity of LLMs to effectively fulfill instructional roles, thereby facilitating student learning akin to human educators within dialogic teaching scenarios, is an exceptionally valuable research topic. This research recruited 34 undergraduate students as participants, who were randomly divided into two groups. The experimental group engaged in dialogic teaching using ChatGPT, while the control group interacted with human teachers. Both groups learned the histogram equalization unit in the information-related course "Digital Image Processing". The research findings show comparable scores between the two groups on the retention test. However, students who engaged in dialogue with ChatGPT exhibited lower performance on the transfer test. Electroencephalography data revealed that students who interacted with ChatGPT exhibited higher levels of cognitive activity, suggesting that ChatGPT could help students establish a knowledge foundation and stimulate cognitive activity. However, its strengths on promoting students. knowledge application and creativity were insignificant. Based upon the research findings, it is evident that ChatGPT cannot fully excel in fulfilling teaching tasks in the dialogue teaching in information related courses. Combining ChatGPT with traditional human teachers might be a more ideal approach. The synergistic use of both can provide students with more comprehensive learning support, thus contributing to enhancing the quality of teaching.
Passive Screen-to-Camera Communication
Mar 24, 2024A recent technology known as transparent screens is transforming windows into displays. These smart windows are present in buses, airports and offices. They can remain transparent, as a normal window, or display relevant information that overlays their panoramic views. In this paper, we propose transforming these windows not only into screens but also into wireless transmitters. To achieve this goal, we build upon the research area of screen-to-camera communication. In this area, videos are modified in a way that smartphone cameras can decode data out of them, while this data remains invisible to the viewers. A person sees a normal video, but the camera sees the video plus additional information. In this communication method, one of the biggest disadvantages is the traditional screens' power consumption, more than 80% of which is used to generate light. To solve this, we employ novel transparent screens relying on ambient light to display pictures, hence eliminating the power source. However, this comes at the cost of a lower image quality, since they use variable and out-of-control environment light, instead of generating a constant and strong light by LED panels. Our work, dubbed PassiveCam, overcomes the challenge of creating the first screen-to-camera communication link using passive displays. This paper presents two main contributions. First, we analyze and modify existing screens and encoding methods to embed information reliably in ambient light. Second, we develop an Android App that optimizes the decoding process, obtaining a real-time performance. Our evaluation, which considers a musical application, shows a Packet Success Rate (PSR) of close to 90%. In addition, our real-time application achieves response times of 530 ms and 1071 ms when the camera is static and when it is hand-held, respectively.
Tensor-based Graph Learning with Consistency and Specificity for Multi-view Clustering
Mar 27, 2024Graph learning is widely recognized as a crucial technique in multi-view clustering. Existing graph learning methods typically involve constructing an adaptive neighbor graph based on probabilistic neighbors and then learning a consensus graph to for clustering, however, they are confronted with two limitations. Firstly, they often rely on Euclidean distance to measure similarity when constructing the adaptive neighbor graph, which proves inadequate in capturing the intrinsic structure among data points in many real-world scenarios. Secondly, most of these methods focus solely on consensus graph, ignoring view-specific graph information. In response to the aforementioned drawbacks, we in this paper propose a novel tensor-based graph learning framework that simultaneously considers consistency and specificity for multi-view clustering. Specifically, we calculate the similarity distance on the Stiefel manifold to preserve the intrinsic structure among data points. By making an assumption that the learned neighbor graph of each view comprises both a consistent graph and a view-specific graph, we formulate a new tensor-based target graph learning paradigm. Owing to the benefits of tensor singular value decomposition (t-SVD) in uncovering high-order correlations, this model is capable of achieving a complete understanding of the target graph. Furthermore, we develop an iterative algorithm to solve the proposed objective optimization problem. Experiments conducted on real-world datasets have demonstrated the superior performance of the proposed method over some state-of-the-art multi-view clustering methods. The source code has been released on https://github.com/lshi91/CSTGL-Code.