 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reward Engineering for Generating Semi-structured Explanation
Sep 15, 2023
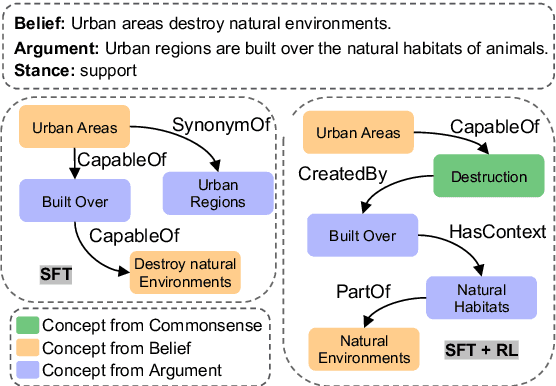

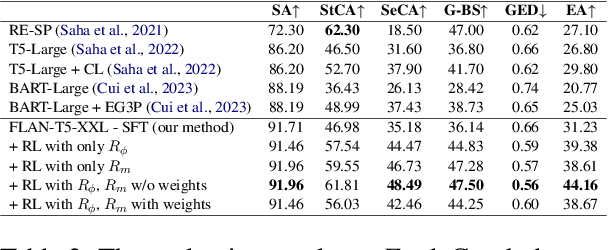
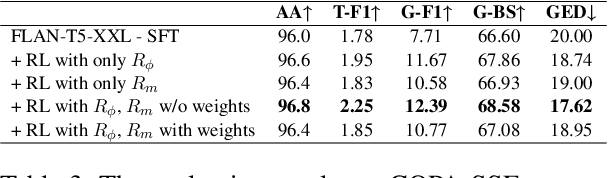
Semi-structured explanation depicts the implicit process of a reasoner with an explicit representation. This explanation highlights how available information in a specific query is supplemented with information a reasoner produces from its internal weights towards generating an answer. Despite the recent improvements in generative capabilities of language models, producing structured explanations to verify model's true reasoning capabilities remains a challenge. This issue is particularly pronounced for not-so-large LMs, as the reasoner is expected to couple a sequential answer with a structured explanation which embodies both the correct presentation and the correct reasoning process. In this work, we first underscore the limitations of supervised fine-tuning (SFT) in tackling this challenge, and then introduce a carefully crafted reward engineering method in reinforcement learning (RL) to better address this problem. We investigate multiple reward aggregation methods and provide a detailed discussion which sheds light on the promising potential of RL for future research. Our proposed reward on two semi-structured explanation generation benchmarks (ExplaGraph and COPA-SSE) achieves new state-of-the-art results.
When do Generative Query and Document Expansions Fail? A Comprehensive Study Across Methods, Retrievers, and Datasets
Sep 15, 2023
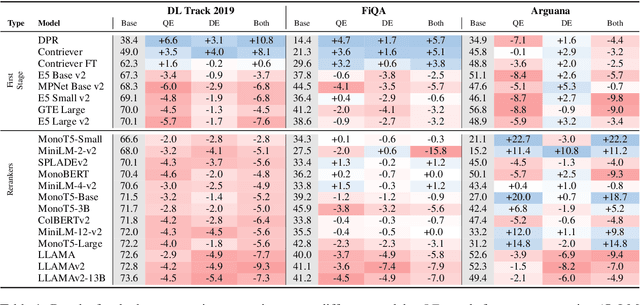
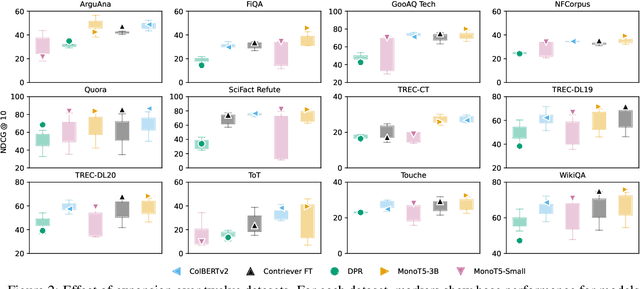
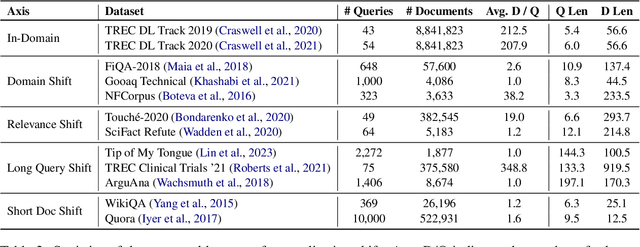
Using large language models (LMs) for query or document expansion can improve generalization in information retrieval. However, it is unknown whether these techniques are universally beneficial or only effective in specific settings, such as for particular retrieval models, dataset domains, or query types. To answer this, we conduct the first comprehensive analysis of LM-based expansion. We find that there exists a strong negative correlation between retriever performance and gains from expansion: expansion improves scores for weaker models, but generally harms stronger models. We show this trend holds across a set of eleven expansion techniques, twelve datasets with diverse distribution shifts, and twenty-four retrieval models. Through qualitative error analysis, we hypothesize that although expansions provide extra information (potentially improving recall), they add additional noise that makes it difficult to discern between the top relevant documents (thus introducing false positives). Our results suggest the following recipe: use expansions for weaker models or when the target dataset significantly differs from training corpus in format; otherwise, avoid expansions to keep the relevance signal clear.
LiDAR-Generated Images Derived Keypoints Assisted Point Cloud Registration Scheme in Odometry Estimation
Sep 19, 2023

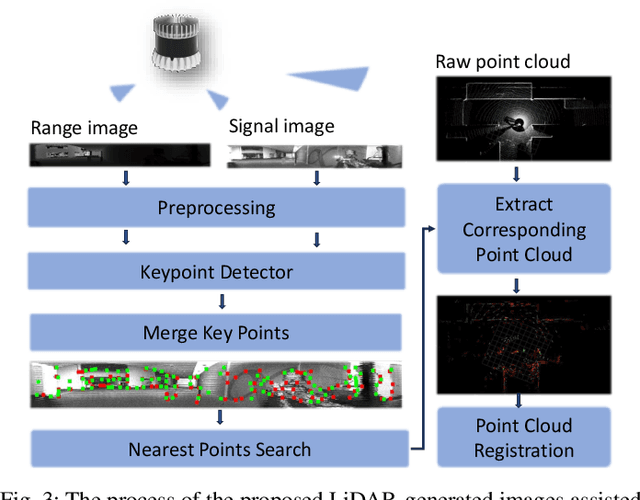

Keypoint detection and description play a pivotal role in various robotics and autonomous applications including visual odometry (VO), visual navigation, and Simultaneous localization and mapping (SLAM). While a myriad of keypoint detectors and descriptors have been extensively studied in conventional camera images, the effectiveness of these techniques in the context of LiDAR-generated images, i.e. reflectivity and ranges images, has not been assessed. These images have gained attention due to their resilience in adverse conditions such as rain or fog. Additionally, they contain significant textural information that supplements the geometric information provided by LiDAR point clouds in the point cloud registration phase, especially when reliant solely on LiDAR sensors. This addresses the challenge of drift encountered in LiDAR Odometry (LO) within geometrically identical scenarios or where not all the raw point cloud is informative and may even be misleading. This paper aims to analyze the applicability of conventional image key point extractors and descriptors on LiDAR-generated images via a comprehensive quantitative investigation. Moreover, we propose a novel approach to enhance the robustness and reliability of LO. After extracting key points, we proceed to downsample the point cloud, subsequently integrating it into the point cloud registration phase for the purpose of odometry estimation. Our experiment demonstrates that the proposed approach has comparable accuracy but reduced computational overhead, higher odometry publishing rate, and even superior performance in scenarios prone to drift by using the raw point cloud. This, in turn, lays a foundation for subsequent investigations into the integration of LiDAR-generated images with LO. Our code is available on GitHub: https://github.com/TIERS/ws-lidar-as-camera-odom.
Hierarchical Imitation Learning for Stochastic Environments
Sep 25, 2023Many applications of imitation learning require the agent to generate the full distribution of behaviour observed in the training data. For example, to evaluate the safety of autonomous vehicles in simulation, accurate and diverse behaviour models of other road users are paramount. Existing methods that improve this distributional realism typically rely on hierarchical policies. These condition the policy on types such as goals or personas that give rise to multi-modal behaviour. However, such methods are often inappropriate for stochastic environments where the agent must also react to external factors: because agent types are inferred from the observed future trajectory during training, these environments require that the contributions of internal and external factors to the agent behaviour are disentangled and only internal factors, i.e., those under the agent's control, are encoded in the type. Encoding future information about external factors leads to inappropriate agent reactions during testing, when the future is unknown and types must be drawn independently from the actual future. We formalize this challenge as distribution shift in the conditional distribution of agent types under environmental stochasticity. We propose Robust Type Conditioning (RTC), which eliminates this shift with adversarial training under randomly sampled types. Experiments on two domains, including the large-scale Waymo Open Motion Dataset, show improved distributional realism while maintaining or improving task performance compared to state-of-the-art baselines.
VidChapters-7M: Video Chapters at Scale
Sep 25, 2023
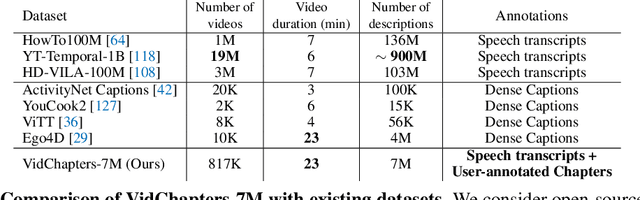
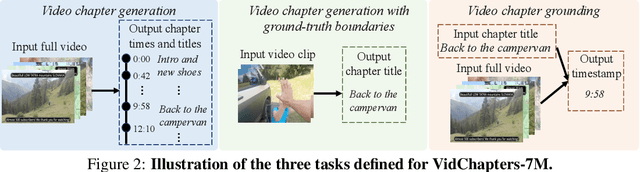
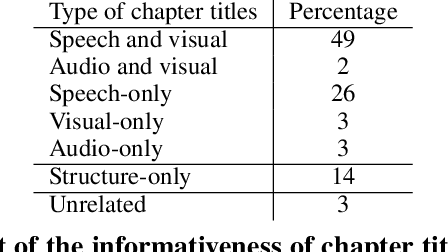
Segmenting long videos into chapters enables users to quickly navigate to the information of their interest. This important topic has been understudied due to the lack of publicly released datasets. To address this issue, we present VidChapters-7M, a dataset of 817K user-chaptered videos including 7M chapters in total. VidChapters-7M is automatically created from videos online in a scalable manner by scraping user-annotated chapters and hence without any additional manual annotation. We introduce the following three tasks based on this data. First, the video chapter generation task consists of temporally segmenting the video and generating a chapter title for each segment. To further dissect the problem, we also define two variants of this task: video chapter generation given ground-truth boundaries, which requires generating a chapter title given an annotated video segment, and video chapter grounding, which requires temporally localizing a chapter given its annotated title. We benchmark both simple baselines and state-of-the-art video-language models for these three tasks. We also show that pretraining on VidChapters-7M transfers well to dense video captioning tasks in both zero-shot and finetuning settings, largely improving the state of the art on the YouCook2 and ViTT benchmarks. Finally, our experiments reveal that downstream performance scales well with the size of the pretraining dataset. Our dataset, code, and models are publicly available at https://antoyang.github.io/vidchapters.html.
Synthetic Boost: Leveraging Synthetic Data for Enhanced Vision-Language Segmentation in Echocardiography
Sep 22, 2023Accurate segmentation is essential for echocardiography-based assessment of cardiovascular diseases (CVDs). However, the variability among sonographers and the inherent challenges of ultrasound images hinder precise segmentation. By leveraging the joint representation of image and text modalities, Vision-Language Segmentation Models (VLSMs) can incorporate rich contextual information, potentially aiding in accurate and explainable segmentation. However, the lack of readily available data in echocardiography hampers the training of VLSMs. In this study, we explore using synthetic datasets from Semantic Diffusion Models (SDMs) to enhance VLSMs for echocardiography segmentation. We evaluate results for two popular VLSMs (CLIPSeg and CRIS) using seven different kinds of language prompts derived from several attributes, automatically extracted from echocardiography images, segmentation masks, and their metadata. Our results show improved metrics and faster convergence when pretraining VLSMs on SDM-generated synthetic images before finetuning on real images. The code, configs, and prompts are available at https://github.com/naamiinepal/synthetic-boost.
mixed attention auto encoder for multi-class industrial anomaly detection
Sep 22, 2023
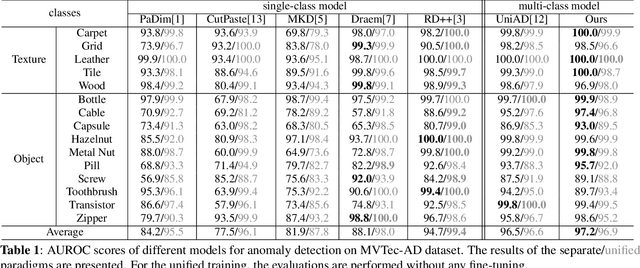
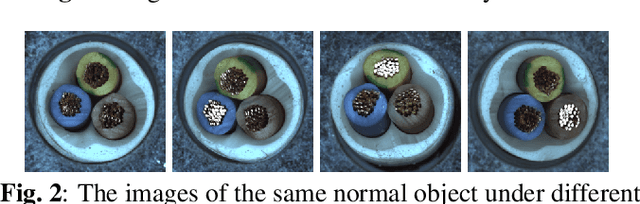
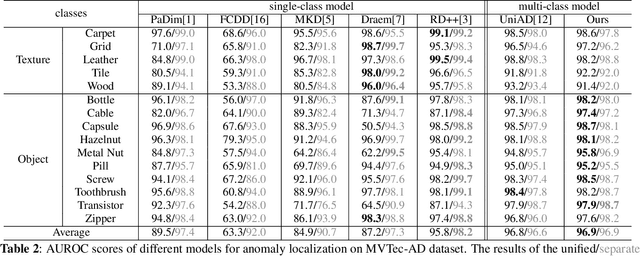
Most existing methods for unsupervised industrial anomaly detection train a separate model for each object category. This kind of approach can easily capture the category-specific feature distributions, but results in high storage cost and low training efficiency. In this paper, we propose a unified mixed-attention auto encoder (MAAE) to implement multi-class anomaly detection with a single model. To alleviate the performance degradation due to the diverse distribution patterns of different categories, we employ spatial attentions and channel attentions to effectively capture the global category information and model the feature distributions of multiple classes. Furthermore, to simulate the realistic noises on features and preserve the surface semantics of objects from different categories which are essential for detecting the subtle anomalies, we propose an adaptive noise generator and a multi-scale fusion module for the pre-trained features. MAAE delivers remarkable performances on the benchmark dataset compared with the state-of-the-art methods.
UWA360CAM: A 360$^{\circ}$ 24/7 Real-Time Streaming Camera System for Underwater Applications
Sep 22, 2023


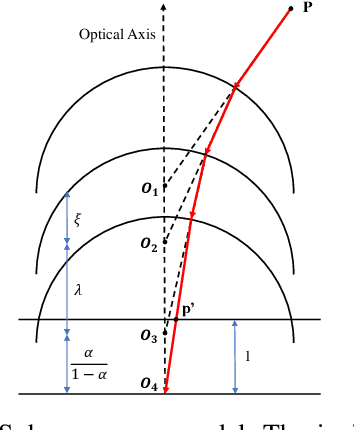
Omnidirectional camera is a cost-effective and information-rich sensor highly suitable for many marine applications and the ocean scientific community, encompassing several domains such as augmented reality, mapping, motion estimation, visual surveillance, and simultaneous localization and mapping. However, designing and constructing such a high-quality 360$^{\circ}$ real-time streaming camera system for underwater applications is a challenging problem due to the technical complexity in several aspects including sensor resolution, wide field of view, power supply, optical design, system calibration, and overheating management. This paper presents a novel and comprehensive system that addresses the complexities associated with the design, construction, and implementation of a fully functional 360$^{\circ}$ real-time streaming camera system specifically tailored for underwater environments. Our proposed system, UWA360CAM, can stream video in real time, operate in 24/7, and capture 360$^{\circ}$ underwater panorama images. Notably, our work is the pioneering effort in providing a detailed and replicable account of this system. The experiments provide a comprehensive analysis of our proposed system.
Open Source Robot Localization for Non-Planar Environments
Sep 22, 2023
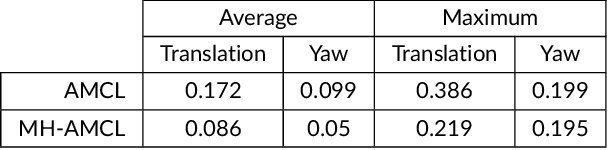
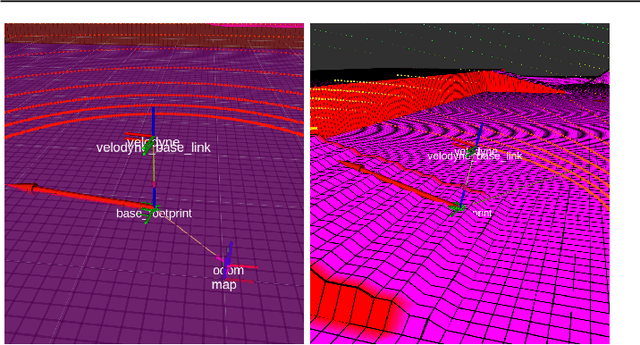

The operational environments in which a mobile robot executes its missions often exhibit non-flat terrain characteristics, encompassing outdoor and indoor settings featuring ramps and slopes. In such scenarios, the conventional methodologies employed for localization encounter novel challenges and limitations. This study delineates a localization framework incorporating ground elevation and inclination considerations, deviating from traditional 2D localization paradigms that may falter in such contexts. In our proposed approach, the map encompasses elevation and spatial occupancy information, employing Gridmaps and Octomaps. At the same time, the perception model is designed to accommodate the robot's inclined orientation and the potential presence of ground as an obstacle, besides usual structural and dynamic obstacles. We have developed and rigorously validated our approach within Nav2, and esteemed open-source framework renowned for robot navigation. Our findings demonstrate that our methodology represents a viable and effective alternative for mobile robots operating in challenging outdoor environments or intrincate terrains.
CrossSinger: A Cross-Lingual Multi-Singer High-Fidelity Singing Voice Synthesizer Trained on Monolingual Singers
Sep 22, 2023It is challenging to build a multi-singer high-fidelity singing voice synthesis system with cross-lingual ability by only using monolingual singers in the training stage. In this paper, we propose CrossSinger, which is a cross-lingual singing voice synthesizer based on Xiaoicesing2. Specifically, we utilize International Phonetic Alphabet to unify the representation for all languages of the training data. Moreover, we leverage conditional layer normalization to incorporate the language information into the model for better pronunciation when singers meet unseen languages. Additionally, gradient reversal layer (GRL) is utilized to remove singer biases included in lyrics since all singers are monolingual, which indicates singer's identity is implicitly associated with the text. The experiment is conducted on a combination of three singing voice datasets containing Japanese Kiritan dataset, English NUS-48E dataset, and one internal Chinese dataset. The result shows CrossSinger can synthesize high-fidelity songs for various singers with cross-lingual ability, including code-switch cases.