 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Designing a Hybrid Neural System to Learn Real-world Crack Segmentation from Fractal-based Simulation
Sep 18, 2023

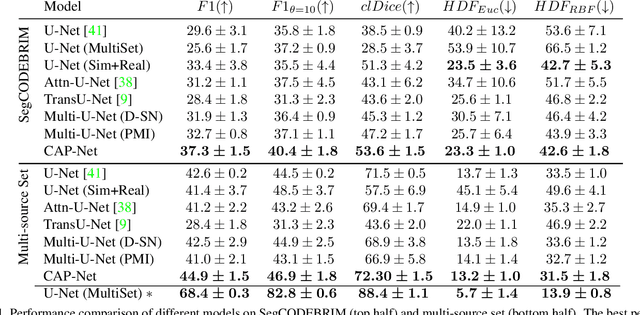
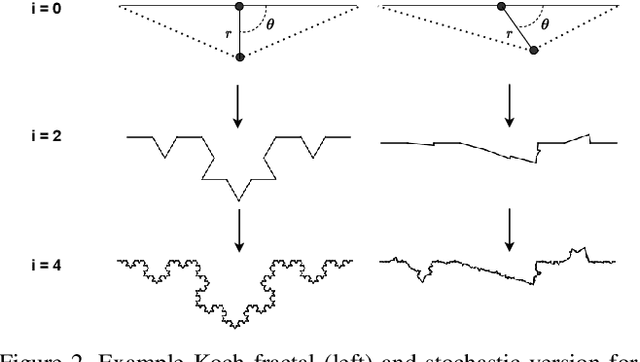
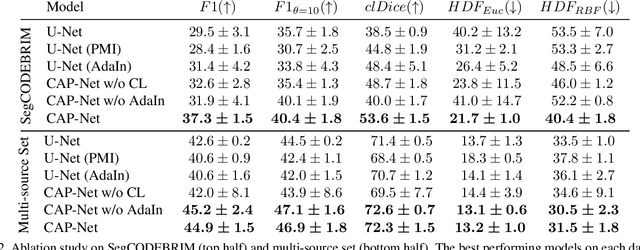
Identification of cracks is essential to assess the structural integrity of concrete infrastructure. However, robust crack segmentation remains a challenging task for computer vision systems due to the diverse appearance of concrete surfaces, variable lighting and weather conditions, and the overlapping of different defects. In particular recent data-driven methods struggle with the limited availability of data, the fine-grained and time-consuming nature of crack annotation, and face subsequent difficulty in generalizing to out-of-distribution samples. In this work, we move past these challenges in a two-fold way. We introduce a high-fidelity crack graphics simulator based on fractals and a corresponding fully-annotated crack dataset. We then complement the latter with a system that learns generalizable representations from simulation, by leveraging both a pointwise mutual information estimate along with adaptive instance normalization as inductive biases. Finally, we empirically highlight how different design choices are symbiotic in bridging the simulation to real gap, and ultimately demonstrate that our introduced system can effectively handle real-world crack segmentation.
Federated PAC-Bayesian Learning on Non-IID data
Sep 13, 2023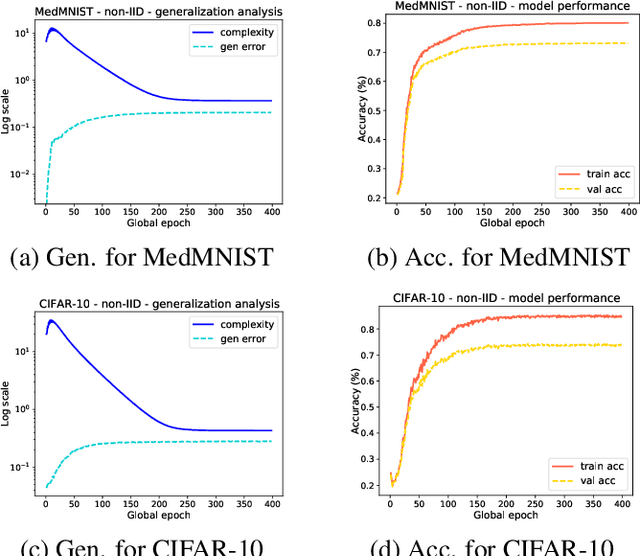
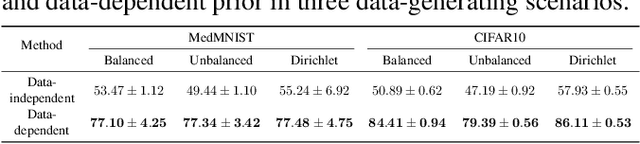
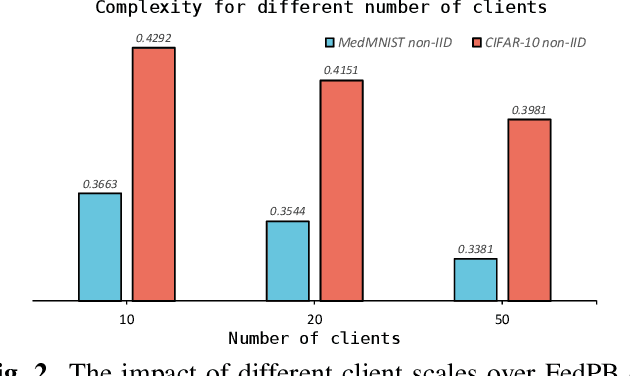
Existing research has either adapted the Probably Approximately Correct (PAC) Bayesian framework for federated learning (FL) or used information-theoretic PAC-Bayesian bounds while introducing their theorems, but few considering the non-IID challenges in FL. Our work presents the first non-vacuous federated PAC-Bayesian bound tailored for non-IID local data. This bound assumes unique prior knowledge for each client and variable aggregation weights. We also introduce an objective function and an innovative Gibbs-based algorithm for the optimization of the derived bound. The results are validated on real-world datasets.
GECTurk: Grammatical Error Correction and Detection Dataset for Turkish
Sep 20, 2023Grammatical Error Detection and Correction (GEC) tools have proven useful for native speakers and second language learners. Developing such tools requires a large amount of parallel, annotated data, which is unavailable for most languages. Synthetic data generation is a common practice to overcome the scarcity of such data. However, it is not straightforward for morphologically rich languages like Turkish due to complex writing rules that require phonological, morphological, and syntactic information. In this work, we present a flexible and extensible synthetic data generation pipeline for Turkish covering more than 20 expert-curated grammar and spelling rules (a.k.a., writing rules) implemented through complex transformation functions. Using this pipeline, we derive 130,000 high-quality parallel sentences from professionally edited articles. Additionally, we create a more realistic test set by manually annotating a set of movie reviews. We implement three baselines formulating the task as i) neural machine translation, ii) sequence tagging, and iii) prefix tuning with a pretrained decoder-only model, achieving strong results. Furthermore, we perform exhaustive experiments on out-of-domain datasets to gain insights on the transferability and robustness of the proposed approaches. Our results suggest that our corpus, GECTurk, is high-quality and allows knowledge transfer for the out-of-domain setting. To encourage further research on Turkish GEC, we release our datasets, baseline models, and the synthetic data generation pipeline at https://github.com/GGLAB-KU/gecturk.
Decision-Directed Hybrid RIS Channel Estimation with Minimal Pilot Overhead
Sep 20, 2023To reap the benefits of reconfigurable intelligent surfaces (RIS), channel state information (CSI) is generally required. However, CSI acquisition in RIS systems is challenging and often results in very large pilot overhead, especially in unstructured channel environments. Consequently, the RIS channel estimation problem has attracted a lot of interest and also been a subject of intense study in recent years. In this paper, we propose a decision-directed RIS channel estimation framework for general unstructured channel models. The employed RIS contains some hybrid elements that can simultaneously reflect and sense the incoming signal. We show that with the help of the hybrid RIS elements, it is possible to accurately recover the CSI with a pilot overhead proportional to the number of users. Therefore, the proposed framework substantially improves the system spectral efficiency compared to systems with passive RIS arrays since the pilot overhead in passive RIS systems is proportional to the number of RIS elements times the number of users. We also perform a detailed spectral efficiency analysis for both the pilot-directed and decision-directed frameworks. Our analysis takes into account both the channel estimation and data detection errors at both the RIS and the BS. Finally, we present numerous simulation results to verify the accuracy of the analysis as well as to show the benefits of the proposed decision-directed framework.
Heterogeneous Entity Matching with Complex Attribute Associations using BERT and Neural Networks
Sep 20, 2023Across various domains, data from different sources such as Baidu Baike and Wikipedia often manifest in distinct forms. Current entity matching methodologies predominantly focus on homogeneous data, characterized by attributes that share the same structure and concise attribute values. However, this orientation poses challenges in handling data with diverse formats. Moreover, prevailing approaches aggregate the similarity of attribute values between corresponding attributes to ascertain entity similarity. Yet, they often overlook the intricate interrelationships between attributes, where one attribute may have multiple associations. The simplistic approach of pairwise attribute comparison fails to harness the wealth of information encapsulated within entities.To address these challenges, we introduce a novel entity matching model, dubbed Entity Matching Model for Capturing Complex Attribute Relationships(EMM-CCAR),built upon pre-trained models. Specifically, this model transforms the matching task into a sequence matching problem to mitigate the impact of varying data formats. Moreover, by introducing attention mechanisms, it identifies complex relationships between attributes, emphasizing the degree of matching among multiple attributes rather than one-to-one correspondences. Through the integration of the EMM-CCAR model, we adeptly surmount the challenges posed by data heterogeneity and intricate attribute interdependencies. In comparison with the prevalent DER-SSM and Ditto approaches, our model achieves improvements of approximately 4% and 1% in F1 scores, respectively. This furnishes a robust solution for addressing the intricacies of attribute complexity in entity matching.
ConDA: Contrastive Domain Adaptation for AI-generated Text Detection
Sep 20, 2023
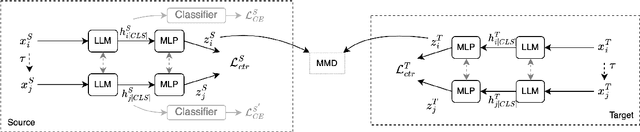
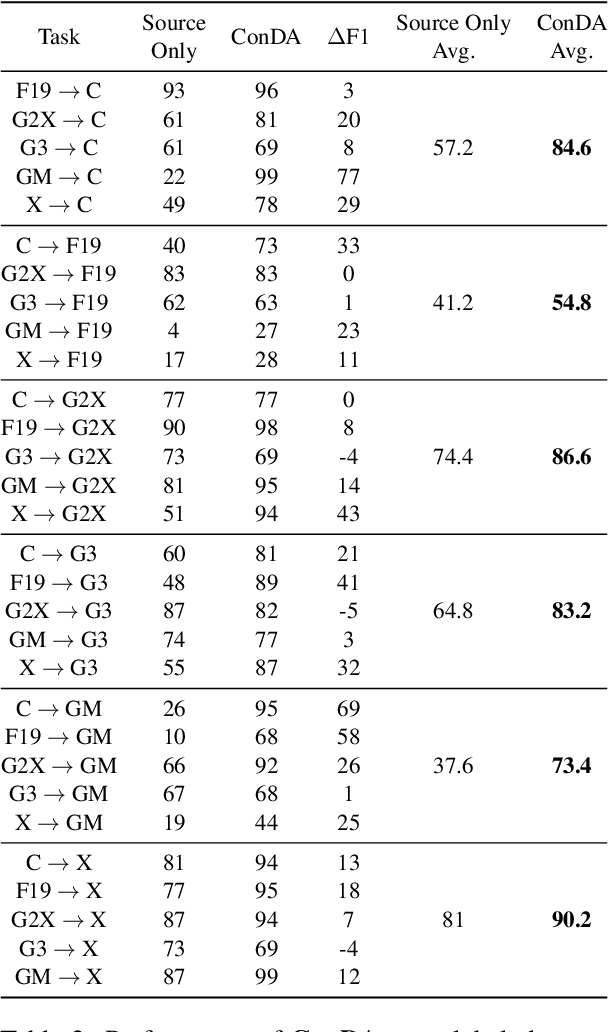
Large language models (LLMs) are increasingly being used for generating text in a variety of use cases, including journalistic news articles. Given the potential malicious nature in which these LLMs can be used to generate disinformation at scale, it is important to build effective detectors for such AI-generated text. Given the surge in development of new LLMs, acquiring labeled training data for supervised detectors is a bottleneck. However, there might be plenty of unlabeled text data available, without information on which generator it came from. In this work we tackle this data problem, in detecting AI-generated news text, and frame the problem as an unsupervised domain adaptation task. Here the domains are the different text generators, i.e. LLMs, and we assume we have access to only the labeled source data and unlabeled target data. We develop a Contrastive Domain Adaptation framework, called ConDA, that blends standard domain adaptation techniques with the representation power of contrastive learning to learn domain invariant representations that are effective for the final unsupervised detection task. Our experiments demonstrate the effectiveness of our framework, resulting in average performance gains of 31.7% from the best performing baselines, and within 0.8% margin of a fully supervised detector. All our code and data is available at https://github.com/AmritaBh/ConDA-gen-text-detection.
GBE-MLZSL: A Group Bi-Enhancement Framework for Multi-Label Zero-Shot Learning
Sep 14, 2023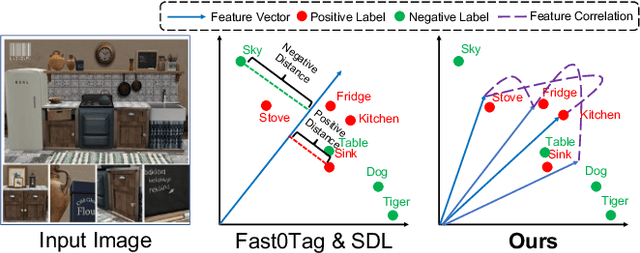
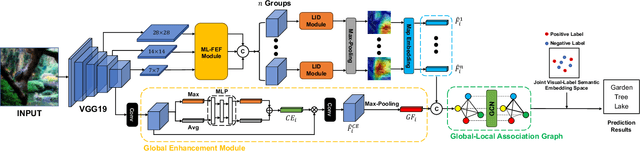
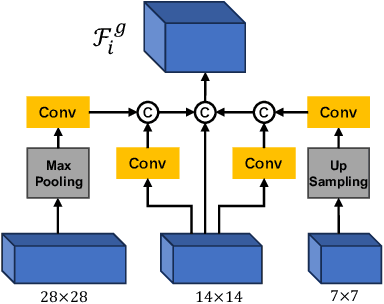
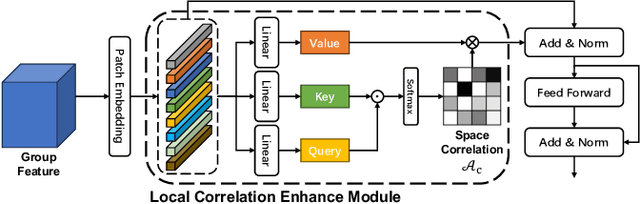
This paper investigates a challenging problem of zero-shot learning in the multi-label scenario (MLZSL), wherein, the model is trained to recognize multiple unseen classes within a sample (e.g., an image) based on seen classes and auxiliary knowledge, e.g., semantic information. Existing methods usually resort to analyzing the relationship of various seen classes residing in a sample from the dimension of spatial or semantic characteristics, and transfer the learned model to unseen ones. But they ignore the effective integration of local and global features. That is, in the process of inferring unseen classes, global features represent the principal direction of the image in the feature space, while local features should maintain uniqueness within a certain range. This integrated neglect will make the model lose its grasp of the main components of the image. Relying only on the local existence of seen classes during the inference stage introduces unavoidable bias. In this paper, we propose a novel and effective group bi-enhancement framework for MLZSL, dubbed GBE-MLZSL, to fully make use of such properties and enable a more accurate and robust visual-semantic projection. Specifically, we split the feature maps into several feature groups, of which each feature group can be trained independently with the Local Information Distinguishing Module (LID) to ensure uniqueness. Meanwhile, a Global Enhancement Module (GEM) is designed to preserve the principal direction. Besides, a static graph structure is designed to construct the correlation of local features. Experiments on large-scale MLZSL benchmark datasets NUS-WIDE and Open-Images-v4 demonstrate that the proposed GBE-MLZSL outperforms other state-of-the-art methods with large margins.
Deep Neighbor Layer Aggregation for Lightweight Self-Supervised Monocular Depth Estimation
Sep 17, 2023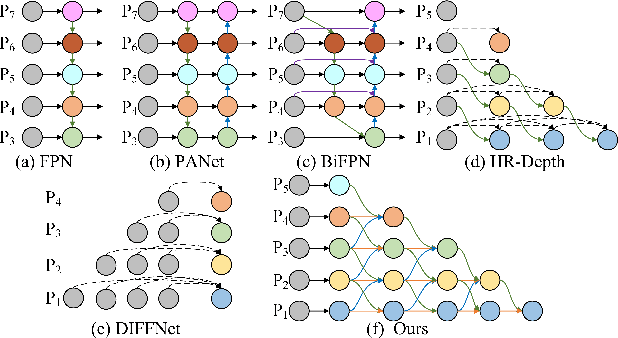
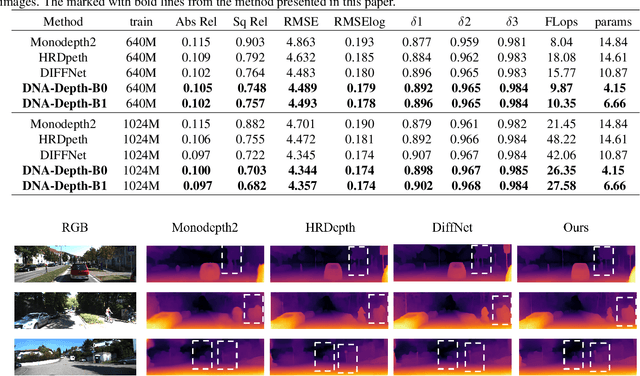
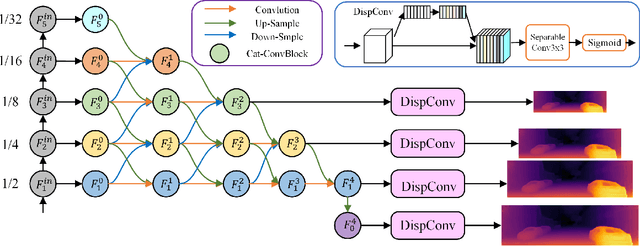
With the frequent use of self-supervised monocular depth estimation in robotics and autonomous driving, the model's efficiency is becoming increasingly important. Most current approaches apply much larger and more complex networks to improve the precision of depth estimation. Some researchers incorporated Transformer into self-supervised monocular depth estimation to achieve better performance. However, this method leads to high parameters and high computation. We present a fully convolutional depth estimation network using contextual feature fusion. Compared to UNet++ and HRNet, we use high-resolution and low-resolution features to reserve information on small targets and fast-moving objects instead of long-range fusion. We further promote depth estimation results employing lightweight channel attention based on convolution in the decoder stage. Our method reduces the parameters without sacrificing accuracy. Experiments on the KITTI benchmark show that our method can get better results than many large models, such as Monodepth2, with only 30 parameters. The source code is available at https://github.com/boyagesmile/DNA-Depth.
Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendation
Sep 05, 2023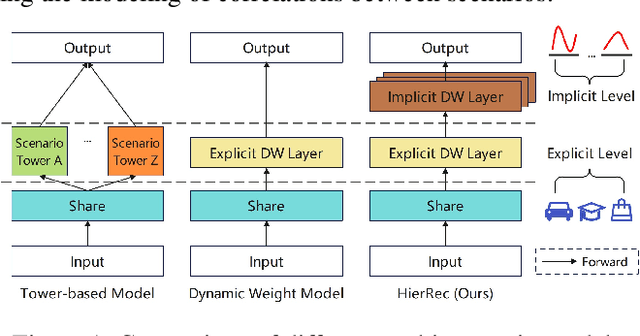

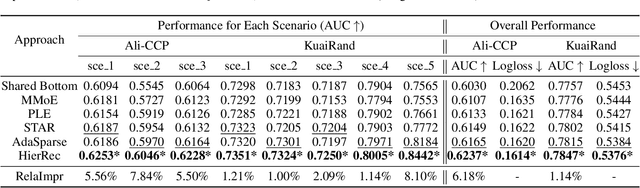
Click-Through Rate (CTR) prediction is a fundamental technique in recommendation and advertising systems. Recent studies have shown that implementing multi-scenario recommendations contributes to strengthening information sharing and improving overall performance. However, existing multi-scenario models only consider coarse-grained explicit scenario modeling that depends on pre-defined scenario identification from manual prior rules, which is biased and sub-optimal. To address these limitations, we propose a Scenario-Aware Hierarchical Dynamic Network for Multi-Scenario Recommendations (HierRec), which perceives implicit patterns adaptively and conducts explicit and implicit scenario modeling jointly. In particular, HierRec designs a basic scenario-oriented module based on the dynamic weight to capture scenario-specific information. Then the hierarchical explicit and implicit scenario-aware modules are proposed to model hybrid-grained scenario information. The multi-head implicit modeling design contributes to perceiving distinctive patterns from different perspectives. Our experiments on two public datasets and real-world industrial applications on a mainstream online advertising platform demonstrate that our HierRec outperforms existing models significantly.
Revisiting File Context for Source Code Summarization
Sep 05, 2023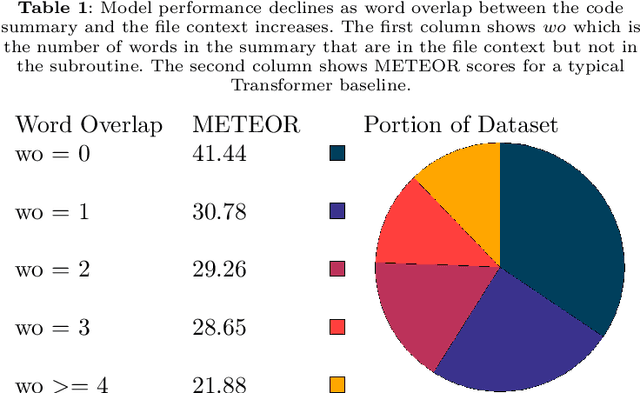
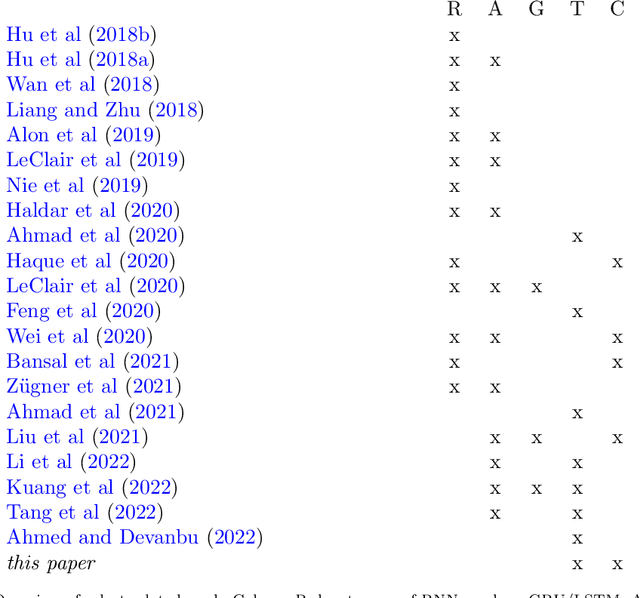
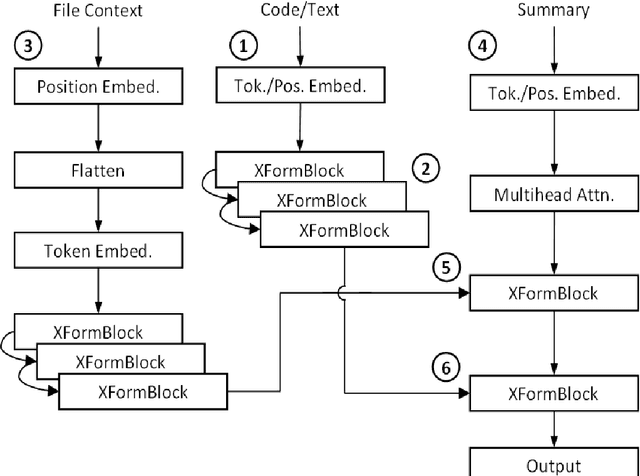
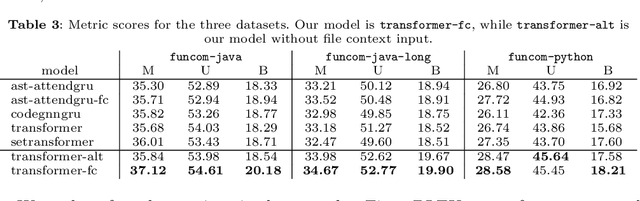
Source code summarization is the task of writing natural language descriptions of source code. A typical use case is generating short summaries of subroutines for use in API documentation. The heart of almost all current research into code summarization is the encoder-decoder neural architecture, and the encoder input is almost always a single subroutine or other short code snippet. The problem with this setup is that the information needed to describe the code is often not present in the code itself -- that information often resides in other nearby code. In this paper, we revisit the idea of ``file context'' for code summarization. File context is the idea of encoding select information from other subroutines in the same file. We propose a novel modification of the Transformer architecture that is purpose-built to encode file context and demonstrate its improvement over several baselines. We find that file context helps on a subset of challenging examples where traditional approaches struggle.