 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sharp Generalization of Transductive Learning: A Transductive Local Rademacher Complexity Approach
Sep 28, 2023
We introduce a new tool, Transductive Local Rademacher Complexity (TLRC), to analyze the generalization performance of transductive learning methods and motivate new transductive learning algorithms. Our work extends the idea of the popular Local Rademacher Complexity (LRC) to the transductive setting with considerable changes compared to the analysis of typical LRC methods in the inductive setting. We present a localized version of Rademacher complexity based tool wihch can be applied to various transductive learning problems and gain sharp bounds under proper conditions. Similar to the development of LRC, we build TLRC by starting from a sharp concentration inequality for independent variables with variance information. The prediction function class of a transductive learning model is then divided into pieces with a sub-root function being the upper bound for the Rademacher complexity of each piece, and the variance of all the functions in each piece is limited. A carefully designed variance operator is used to ensure that the bound for the test loss on unlabeled test data in the transductive setting enjoys a remarkable similarity to that of the classical LRC bound in the inductive setting. We use the new TLRC tool to analyze the Transductive Kernel Learning (TKL) model, where the labels of test data are generated by a kernel function. The result of TKL lays the foundation for generalization bounds for two types of transductive learning tasks, Graph Transductive Learning (GTL) and Transductive Nonparametric Kernel Regression (TNKR). When the target function is low-dimensional or approximately low-dimensional, we design low rank methods for both GTL and TNKR, which enjoy particularly sharper generalization bounds by TLRC which cannot be achieved by existing learning theory methods, to the best of our knowledge.
Heuristic Satisficing Inferential Decision Making in Human and Robot Active Perception
Sep 14, 2023
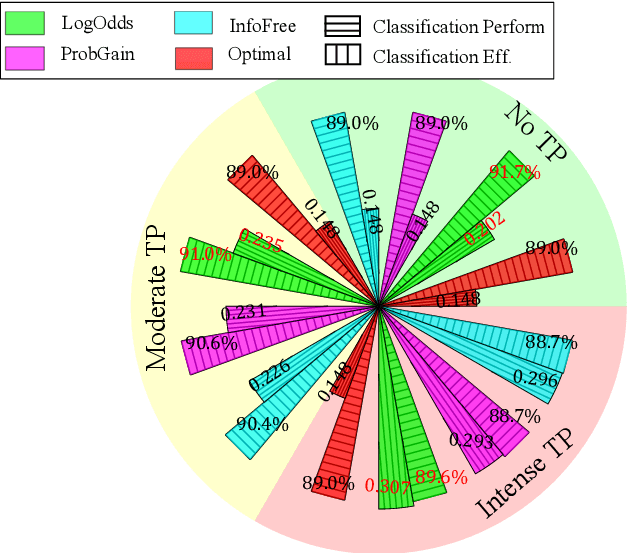
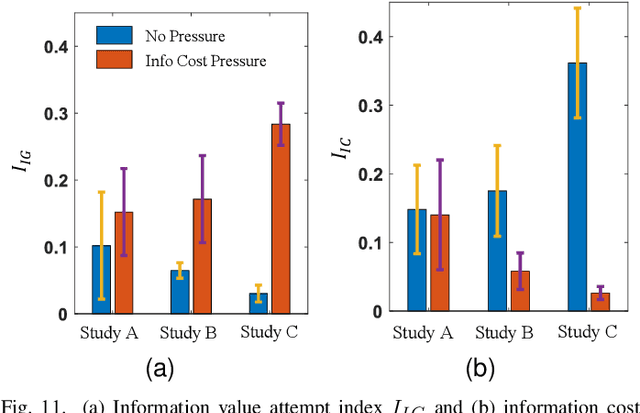
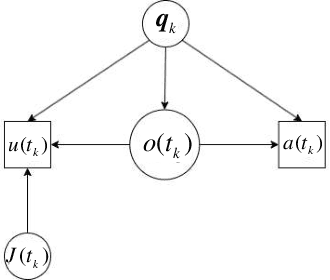
Inferential decision-making algorithms typically assume that an underlying probabilistic model of decision alternatives and outcomes may be learned a priori or online. Furthermore, when applied to robots in real-world settings they often perform unsatisfactorily or fail to accomplish the necessary tasks because this assumption is violated and/or they experience unanticipated external pressures and constraints. Cognitive studies presented in this and other papers show that humans cope with complex and unknown settings by modulating between near-optimal and satisficing solutions, including heuristics, by leveraging information value of available environmental cues that are possibly redundant. Using the benchmark inferential decision problem known as ``treasure hunt", this paper develops a general approach for investigating and modeling active perception solutions under pressure. By simulating treasure hunt problems in virtual worlds, our approach learns generalizable strategies from high performers that, when applied to robots, allow them to modulate between optimal and heuristic solutions on the basis of external pressures and probabilistic models, if and when available. The result is a suite of active perception algorithms for camera-equipped robots that outperform treasure-hunt solutions obtained via cell decomposition, information roadmap, and information potential algorithms, in both high-fidelity numerical simulations and physical experiments. The effectiveness of the new active perception strategies is demonstrated under a broad range of unanticipated conditions that cause existing algorithms to fail to complete the search for treasures, such as unmodelled time constraints, resource constraints, and adverse weather (fog).
Analysis and Detection of Pathological Voice using Glottal Source Features
Sep 25, 2023Automatic detection of voice pathology enables objective assessment and earlier intervention for the diagnosis. This study provides a systematic analysis of glottal source features and investigates their effectiveness in voice pathology detection. Glottal source features are extracted using glottal flows estimated with the quasi-closed phase (QCP) glottal inverse filtering method, using approximate glottal source signals computed with the zero frequency filtering (ZFF) method, and using acoustic voice signals directly. In addition, we propose to derive mel-frequency cepstral coefficients (MFCCs) from the glottal source waveforms computed by QCP and ZFF to effectively capture the variations in glottal source spectra of pathological voice. Experiments were carried out using two databases, the Hospital Universitario Principe de Asturias (HUPA) database and the Saarbrucken Voice Disorders (SVD) database. Analysis of features revealed that the glottal source contains information that discriminates normal and pathological voice. Pathology detection experiments were carried out using support vector machine (SVM). From the detection experiments it was observed that the performance achieved with the studied glottal source features is comparable or better than that of conventional MFCCs and perceptual linear prediction (PLP) features. The best detection performance was achieved when the glottal source features were combined with the conventional MFCCs and PLP features, which indicates the complementary nature of the features.
Diverse Semantic Image Editing with Style Codes
Sep 25, 2023Semantic image editing requires inpainting pixels following a semantic map. It is a challenging task since this inpainting requires both harmony with the context and strict compliance with the semantic maps. The majority of the previous methods proposed for this task try to encode the whole information from erased images. However, when an object is added to a scene such as a car, its style cannot be encoded from the context alone. On the other hand, the models that can output diverse generations struggle to output images that have seamless boundaries between the generated and unerased parts. Additionally, previous methods do not have a mechanism to encode the styles of visible and partially visible objects differently for better performance. In this work, we propose a framework that can encode visible and partially visible objects with a novel mechanism to achieve consistency in the style encoding and final generations. We extensively compare with previous conditional image generation and semantic image editing algorithms. Our extensive experiments show that our method significantly improves over the state-of-the-art. Our method not only achieves better quantitative results but also provides diverse results. Please refer to the project web page for the released code and demo: https://github.com/hakansivuk/DivSem.
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Sep 25, 2023In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO, and the MindSpore code is available at https://gitee.com/mindspore/models/tree/master/research/cv/Gold_YOLO.
Online Resource Allocation for Semantic-Aware Edge Computing Systems
Sep 25, 2023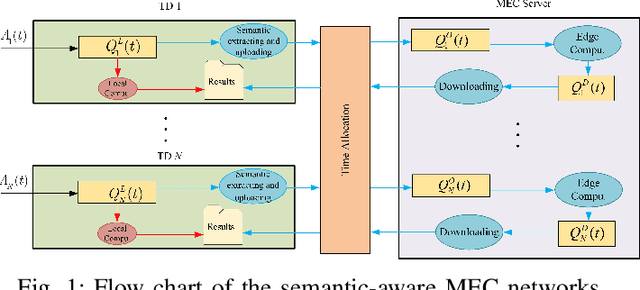
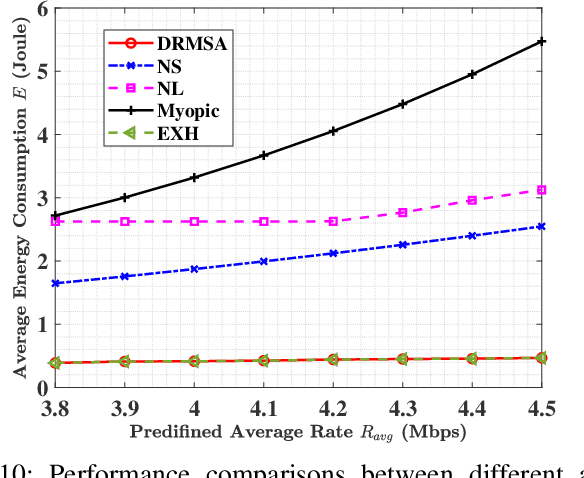
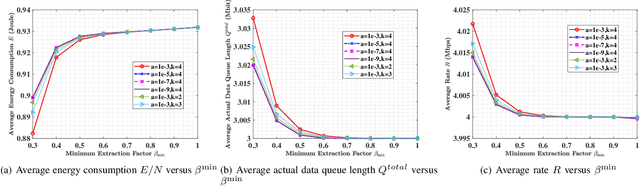
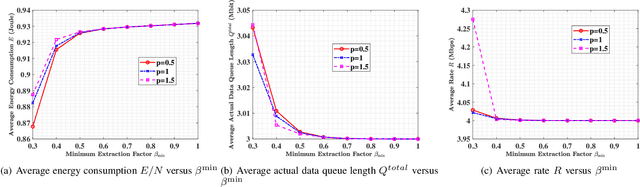
In this paper, we propose a semantic-aware joint communication and computation resource allocation framework for MEC systems. In the considered system, random tasks arrive at each terminal device (TD), which needs to be computed locally or offloaded to the MEC server. To further release the transmission burden, each TD sends the small-size extracted semantic information of tasks to the server instead of the original large-size raw data. An optimization problem of joint semanticaware division factor, communication and computation resource management is formulated. The problem aims to minimize the energy consumption of the whole system, while satisfying longterm delay and processing rate constraints. To solve this problem, an online low-complexity algorithm is proposed. In particular, Lyapunov optimization is utilized to decompose the original coupled long-term problem into a series of decoupled deterministic problems without requiring the realizations of future task arrivals and channel gains. Then, the block coordinate descent method and successive convex approximation algorithm are adopted to solve the current time slot deterministic problem by observing the current system states. Moreover, the closed-form optimal solution of each optimization variable is provided. Simulation results show that the proposed algorithm yields up to 41.8% energy reduction compared to its counterpart without semantic-aware allocation.
UnitedHuman: Harnessing Multi-Source Data for High-Resolution Human Generation
Sep 25, 2023
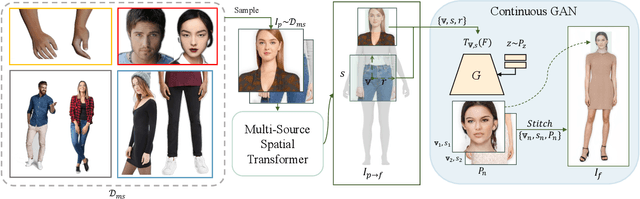

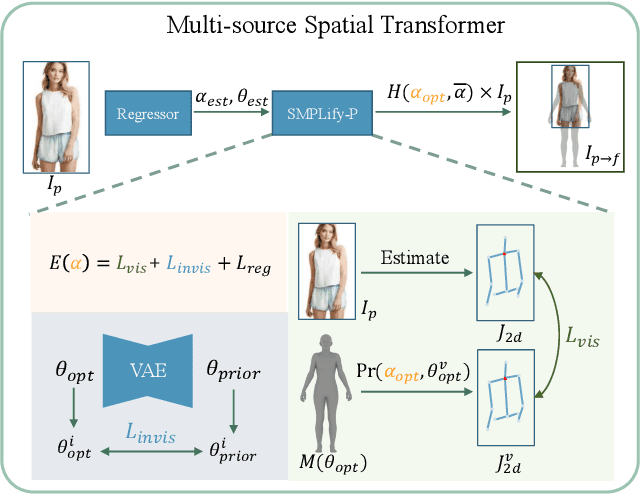
Human generation has achieved significant progress. Nonetheless, existing methods still struggle to synthesize specific regions such as faces and hands. We argue that the main reason is rooted in the training data. A holistic human dataset inevitably has insufficient and low-resolution information on local parts. Therefore, we propose to use multi-source datasets with various resolution images to jointly learn a high-resolution human generative model. However, multi-source data inherently a) contains different parts that do not spatially align into a coherent human, and b) comes with different scales. To tackle these challenges, we propose an end-to-end framework, UnitedHuman, that empowers continuous GAN with the ability to effectively utilize multi-source data for high-resolution human generation. Specifically, 1) we design a Multi-Source Spatial Transformer that spatially aligns multi-source images to full-body space with a human parametric model. 2) Next, a continuous GAN is proposed with global-structural guidance and CutMix consistency. Patches from different datasets are then sampled and transformed to supervise the training of this scale-invariant generative model. Extensive experiments demonstrate that our model jointly learned from multi-source data achieves superior quality than those learned from a holistic dataset.
Multi-perspective Information Fusion Res2Net with RandomSpecmix for Fake Speech Detection
Jun 27, 2023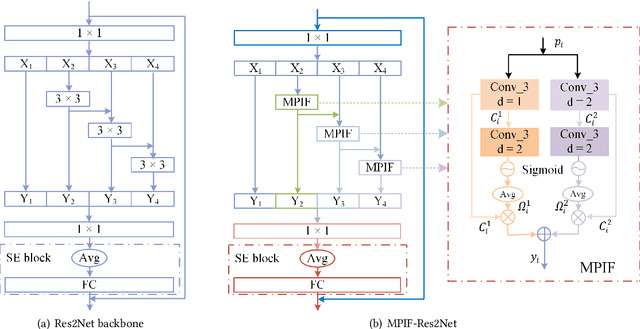

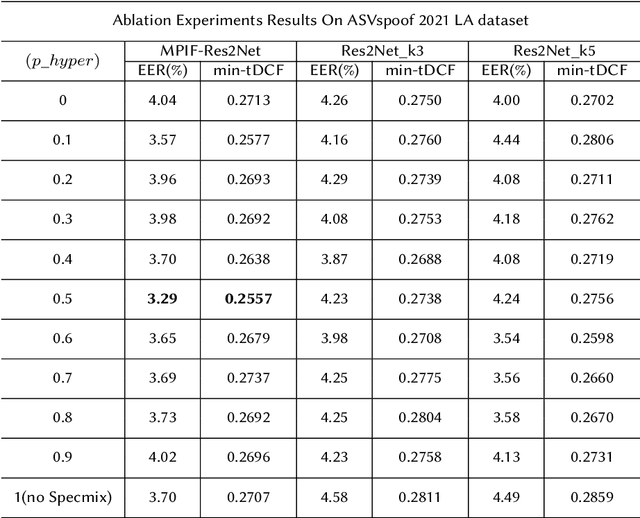
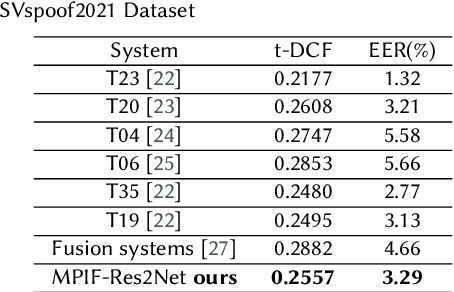
In this paper, we propose the multi-perspective information fusion (MPIF) Res2Net with random Specmix for fake speech detection (FSD). The main purpose of this system is to improve the model's ability to learn precise forgery information for FSD task in low-quality scenarios. The task of random Specmix, a data augmentation, is to improve the generalization ability of the model and enhance the model's ability to locate discriminative information. Specmix cuts and pastes the frequency dimension information of the spectrogram in the same batch of samples without introducing other data, which helps the model to locate the really useful information. At the same time, we randomly select samples for augmentation to reduce the impact of data augmentation directly changing all the data. Once the purpose of helping the model to locate information is achieved, it is also important to reduce unnecessary information. The role of MPIF-Res2Net is to reduce redundant interference information. Deceptive information from a single perspective is always similar, so the model learning this similar information will produce redundant spoofing clues and interfere with truly discriminative information. The proposed MPIF-Res2Net fuses information from different perspectives, making the information learned by the model more diverse, thereby reducing the redundancy caused by similar information and avoiding interference with the learning of discriminative information. The results on the ASVspoof 2021 LA dataset demonstrate the effectiveness of our proposed method, achieving EER and min-tDCF of 3.29% and 0.2557, respectively.
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase
Sep 11, 2023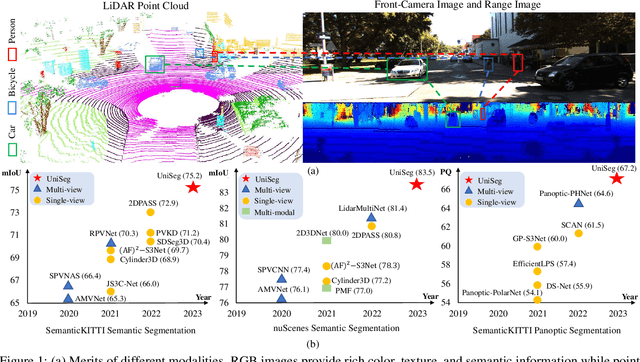

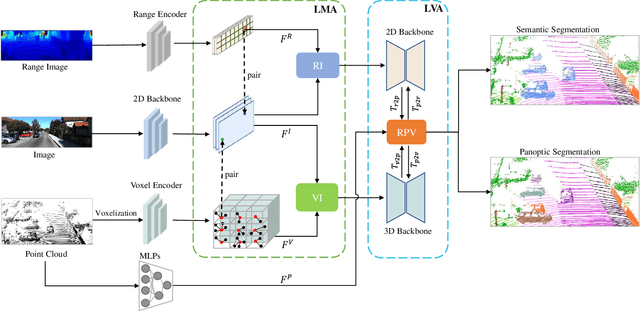
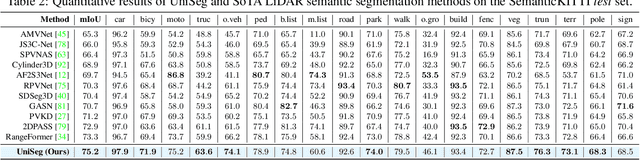
Point-, voxel-, and range-views are three representative forms of point clouds. All of them have accurate 3D measurements but lack color and texture information. RGB images are a natural complement to these point cloud views and fully utilizing the comprehensive information of them benefits more robust perceptions. In this paper, we present a unified multi-modal LiDAR segmentation network, termed UniSeg, which leverages the information of RGB images and three views of the point cloud, and accomplishes semantic segmentation and panoptic segmentation simultaneously. Specifically, we first design the Learnable cross-Modal Association (LMA) module to automatically fuse voxel-view and range-view features with image features, which fully utilize the rich semantic information of images and are robust to calibration errors. Then, the enhanced voxel-view and range-view features are transformed to the point space,where three views of point cloud features are further fused adaptively by the Learnable cross-View Association module (LVA). Notably, UniSeg achieves promising results in three public benchmarks, i.e., SemanticKITTI, nuScenes, and Waymo Open Dataset (WOD); it ranks 1st on two challenges of two benchmarks, including the LiDAR semantic segmentation challenge of nuScenes and panoptic segmentation challenges of SemanticKITTI. Besides, we construct the OpenPCSeg codebase, which is the largest and most comprehensive outdoor LiDAR segmentation codebase. It contains most of the popular outdoor LiDAR segmentation algorithms and provides reproducible implementations. The OpenPCSeg codebase will be made publicly available at https://github.com/PJLab-ADG/PCSeg.
Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures
Sep 17, 2023
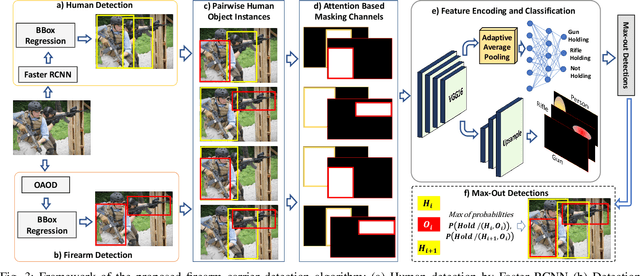
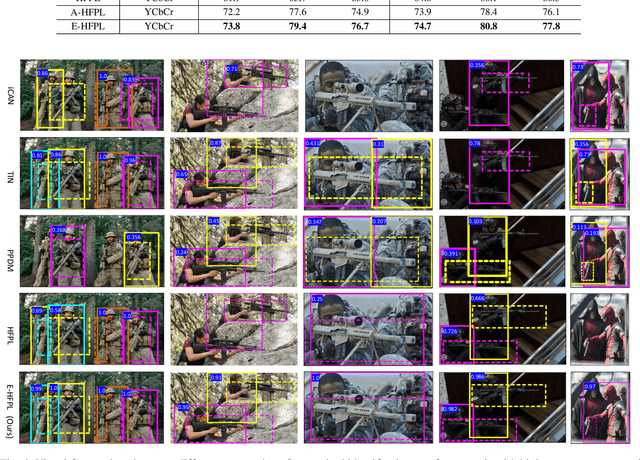

Detecting firearms and accurately localizing individuals carrying them in images or videos is of paramount importance in security, surveillance, and content customization. However, this task presents significant challenges in complex environments due to clutter and the diverse shapes of firearms. To address this problem, we propose a novel approach that leverages human-firearm interaction information, which provides valuable clues for localizing firearm carriers. Our approach incorporates an attention mechanism that effectively distinguishes humans and firearms from the background by focusing on relevant areas. Additionally, we introduce a saliency-driven locality-preserving constraint to learn essential features while preserving foreground information in the input image. By combining these components, our approach achieves exceptional results on a newly proposed dataset. To handle inputs of varying sizes, we pass paired human-firearm instances with attention masks as channels through a deep network for feature computation, utilizing an adaptive average pooling layer. We extensively evaluate our approach against existing methods in human-object interaction detection and achieve significant results (AP=77.8\%) compared to the baseline approach (AP=63.1\%). This demonstrates the effectiveness of leveraging attention mechanisms and saliency-driven locality preservation for accurate human-firearm interaction detection. Our findings contribute to advancing the fields of security and surveillance, enabling more efficient firearm localization and identification in diverse scenarios.