 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Statistical Analysis of Quantum State Learning Process in Quantum Neural Networks
Sep 26, 2023
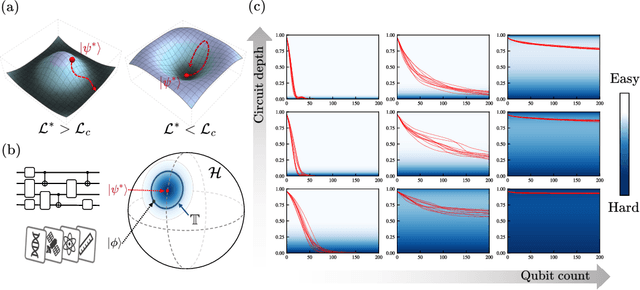
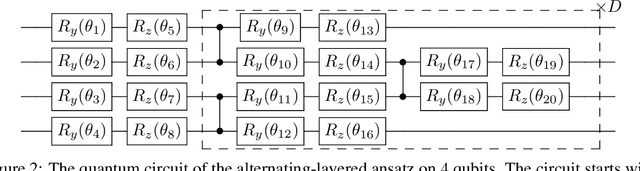
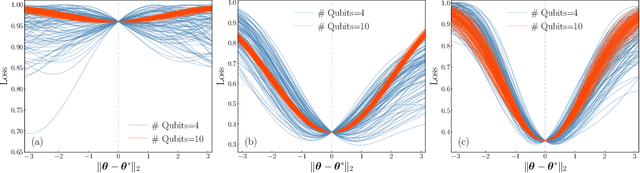
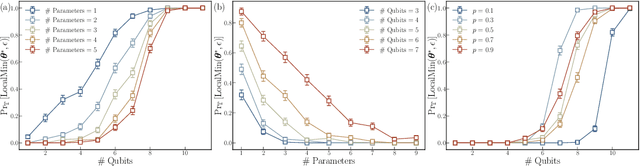
Quantum neural networks (QNNs) have been a promising framework in pursuing near-term quantum advantage in various fields, where many applications can be viewed as learning a quantum state that encodes useful data. As a quantum analog of probability distribution learning, quantum state learning is theoretically and practically essential in quantum machine learning. In this paper, we develop a no-go theorem for learning an unknown quantum state with QNNs even starting from a high-fidelity initial state. We prove that when the loss value is lower than a critical threshold, the probability of avoiding local minima vanishes exponentially with the qubit count, while only grows polynomially with the circuit depth. The curvature of local minima is concentrated to the quantum Fisher information times a loss-dependent constant, which characterizes the sensibility of the output state with respect to parameters in QNNs. These results hold for any circuit structures, initialization strategies, and work for both fixed ansatzes and adaptive methods. Extensive numerical simulations are performed to validate our theoretical results. Our findings place generic limits on good initial guesses and adaptive methods for improving the learnability and scalability of QNNs, and deepen the understanding of prior information's role in QNNs.
Probabilistic 3D Multi-Object Cooperative Tracking for Autonomous Driving via Differentiable Multi-Sensor Kalman Filter
Sep 26, 2023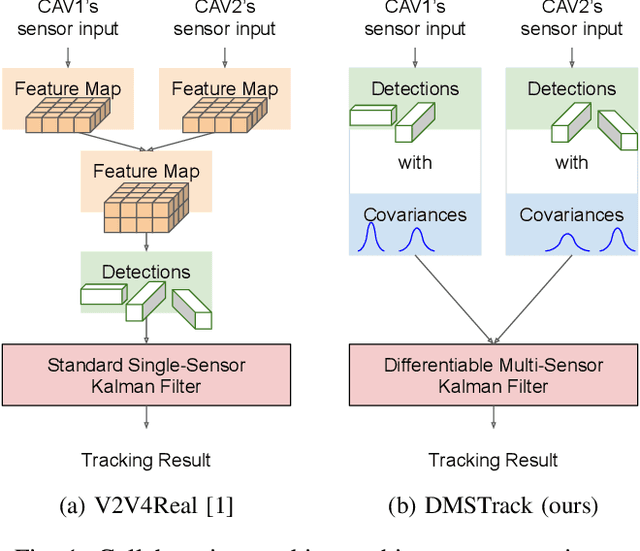
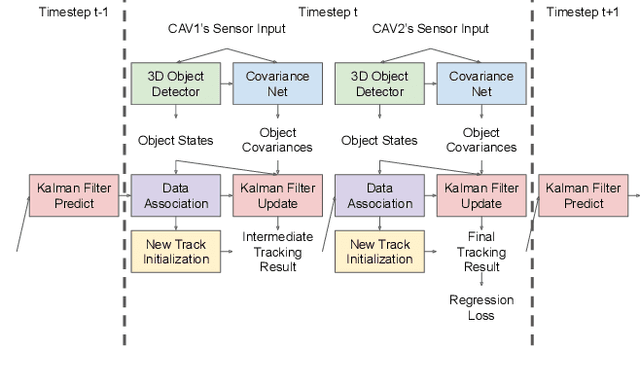
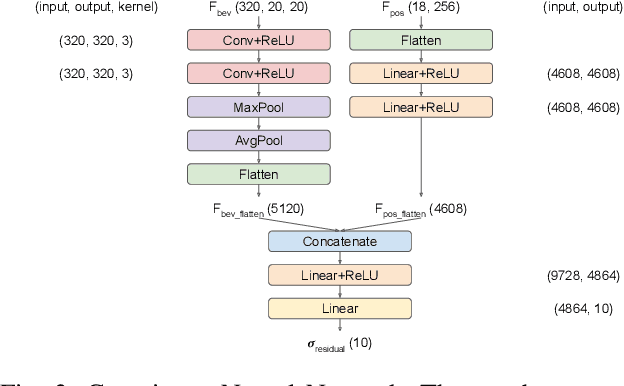
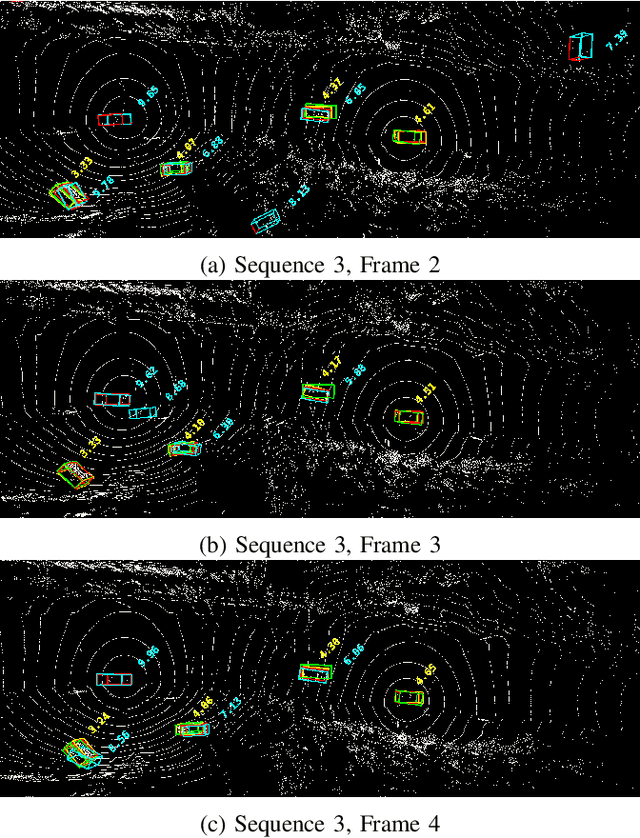
Current state-of-the-art autonomous driving vehicles mainly rely on each individual sensor system to perform perception tasks. Such a framework's reliability could be limited by occlusion or sensor failure. To address this issue, more recent research proposes using vehicle-to-vehicle (V2V) communication to share perception information with others. However, most relevant works focus only on cooperative detection and leave cooperative tracking an underexplored research field. A few recent datasets, such as V2V4Real, provide 3D multi-object cooperative tracking benchmarks. However, their proposed methods mainly use cooperative detection results as input to a standard single-sensor Kalman Filter-based tracking algorithm. In their approach, the measurement uncertainty of different sensors from different connected autonomous vehicles (CAVs) may not be properly estimated to utilize the theoretical optimality property of Kalman Filter-based tracking algorithms. In this paper, we propose a novel 3D multi-object cooperative tracking algorithm for autonomous driving via a differentiable multi-sensor Kalman Filter. Our algorithm learns to estimate measurement uncertainty for each detection that can better utilize the theoretical property of Kalman Filter-based tracking methods. The experiment results show that our algorithm improves the tracking accuracy by 17% with only 0.037x communication costs compared with the state-of-the-art method in V2V4Real.
DifAttack: Query-Efficient Black-Box Attack via Disentangled Feature Space
Sep 26, 2023This work investigates efficient score-based black-box adversarial attacks with a high Attack Success Rate (ASR) and good generalizability. We design a novel attack method based on a Disentangled Feature space, called DifAttack, which differs significantly from the existing ones operating over the entire feature space. Specifically, DifAttack firstly disentangles an image's latent feature into an adversarial feature and a visual feature, where the former dominates the adversarial capability of an image, while the latter largely determines its visual appearance. We train an autoencoder for the disentanglement by using pairs of clean images and their Adversarial Examples (AEs) generated from available surrogate models via white-box attack methods. Eventually, DifAttack iteratively optimizes the adversarial feature according to the query feedback from the victim model until a successful AE is generated, while keeping the visual feature unaltered. In addition, due to the avoidance of using surrogate models' gradient information when optimizing AEs for black-box models, our proposed DifAttack inherently possesses better attack capability in the open-set scenario, where the training dataset of the victim model is unknown. Extensive experimental results demonstrate that our method achieves significant improvements in ASR and query efficiency simultaneously, especially in the targeted attack and open-set scenarios. The code will be available at https://github.com/csjunjun/DifAttack.git soon.
Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
Sep 26, 2023Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes. We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.
Towards Robust and Efficient Communications for Urban Air Mobility
Sep 15, 2023For the realization of the future urban air mobility, reliable information exchange based on robust and efficient communication between all airspace participants will be one of the key factors to ensure safe operations. Especially in dense urban scenarios, the direct and fast information exchange between drones based on Drone-to-Drone communications is a promising technology for enabling reliable collision avoidance systems. However, to mitigate collisions and to increase overall reliability, unmanned aircraft still lack a redundant, higher-level safety net to coordinate and monitor traffic, as is common in today's civil aviation. In addition, direct and fast information exchange based on ad hoc communication is needed to cope with the very short reaction times required to avoid collisions and to cope with the the high traffic densities. Therefore, we are developing a \ac{d2d} communication and surveillance system, called DroneCAST, which is specifically tailored to the requirements of a future urban airspace and will be part of a multi-link approach. In this work we discuss challenges and expected safety-critical applications that will have to rely on communications for \ac{uam} and present our communication concept and necessary steps towards DroneCAST. As a first step towards an implementation, we equipped two drones with hardware prototypes of the experimental communication system and performed several flights around the model city to evaluate the performance of the hardware and to demonstrate different applications that will rely on robust and efficient communications.
Demystifying Local and Global Fairness Trade-offs in Federated Learning Using Partial Information Decomposition
Jul 21, 2023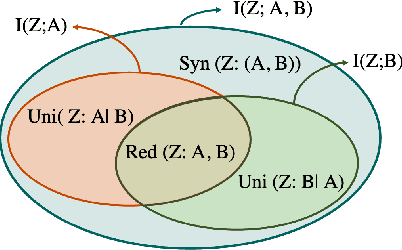
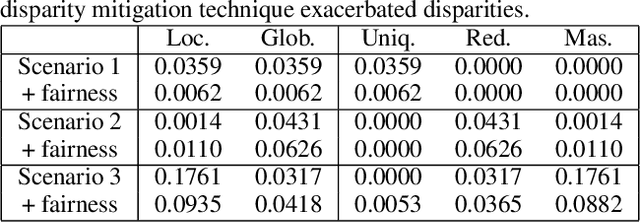
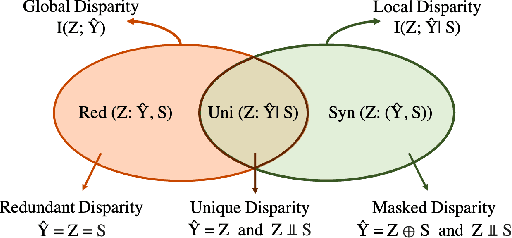
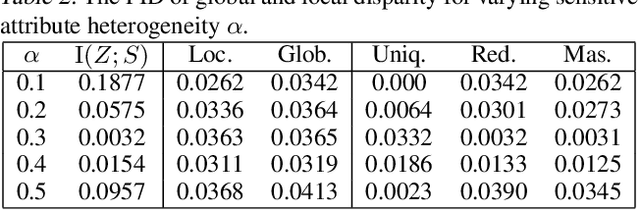
In this paper, we present an information-theoretic perspective to group fairness trade-offs in federated learning (FL) with respect to sensitive attributes, such as gender, race, etc. Existing works mostly focus on either \emph{global fairness} (overall disparity of the model across all clients) or \emph{local fairness} (disparity of the model at each individual client), without always considering their trade-offs. There is a lack of understanding of the interplay between global and local fairness in FL, and if and when one implies the other. To address this gap, we leverage a body of work in information theory called partial information decomposition (PID) which first identifies three sources of unfairness in FL, namely, \emph{Unique Disparity}, \emph{Redundant Disparity}, and \emph{Masked Disparity}. Using canonical examples, we demonstrate how these three disparities contribute to global and local fairness. This decomposition helps us derive fundamental limits and trade-offs between global or local fairness, particularly under data heterogeneity, as well as, derive conditions under which one implies the other. We also present experimental results on benchmark datasets to support our theoretical findings. This work offers a more nuanced understanding of the sources of disparity in FL that can inform the use of local disparity mitigation techniques, and their convergence and effectiveness when deployed in practice.
Learning Minimalistic Tsetlin Machine Clauses with Markov Boundary-Guided Pruning
Sep 12, 2023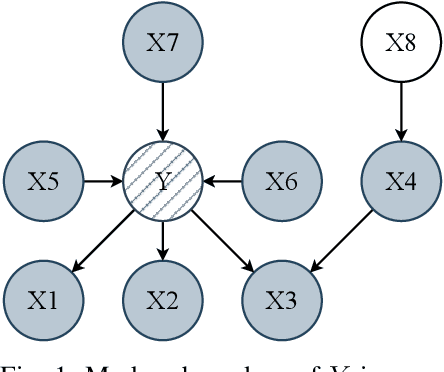


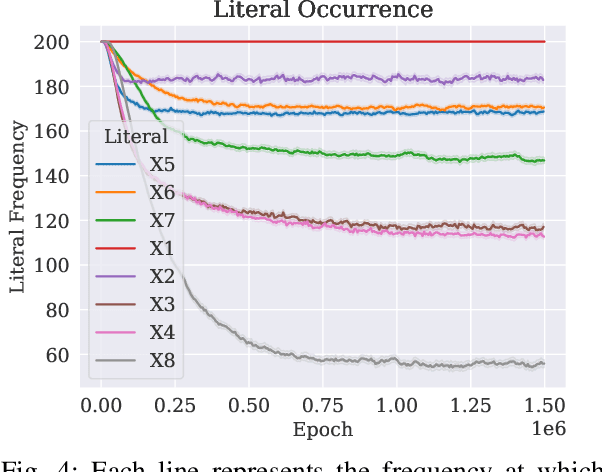
A set of variables is the Markov blanket of a random variable if it contains all the information needed for predicting the variable. If the blanket cannot be reduced without losing useful information, it is called a Markov boundary. Identifying the Markov boundary of a random variable is advantageous because all variables outside the boundary are superfluous. Hence, the Markov boundary provides an optimal feature set. However, learning the Markov boundary from data is challenging for two reasons. If one or more variables are removed from the Markov boundary, variables outside the boundary may start providing information. Conversely, variables within the boundary may stop providing information. The true role of each candidate variable is only manifesting when the Markov boundary has been identified. In this paper, we propose a new Tsetlin Machine (TM) feedback scheme that supplements Type I and Type II feedback. The scheme introduces a novel Finite State Automaton - a Context-Specific Independence Automaton. The automaton learns which features are outside the Markov boundary of the target, allowing them to be pruned from the TM during learning. We investigate the new scheme empirically, showing how it is capable of exploiting context-specific independence to find Markov boundaries. Further, we provide a theoretical analysis of convergence. Our approach thus connects the field of Bayesian networks (BN) with TMs, potentially opening up for synergies when it comes to inference and learning, including TM-produced Bayesian knowledge bases and TM-based Bayesian inference.
Semantically Redundant Training Data Removal and Deep Model Classification Performance: A Study with Chest X-rays
Sep 18, 2023


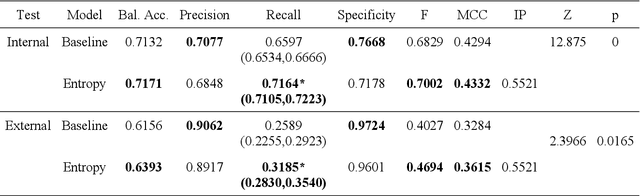
Deep learning (DL) has demonstrated its innate capacity to independently learn hierarchical features from complex and multi-dimensional data. A common understanding is that its performance scales up with the amount of training data. Another data attribute is the inherent variety. It follows, therefore, that semantic redundancy, which is the presence of similar or repetitive information, would tend to lower performance and limit generalizability to unseen data. In medical imaging data, semantic redundancy can occur due to the presence of multiple images that have highly similar presentations for the disease of interest. Further, the common use of augmentation methods to generate variety in DL training may be limiting performance when applied to semantically redundant data. We propose an entropy-based sample scoring approach to identify and remove semantically redundant training data. We demonstrate using the publicly available NIH chest X-ray dataset that the model trained on the resulting informative subset of training data significantly outperforms the model trained on the full training set, during both internal (recall: 0.7164 vs 0.6597, p<0.05) and external testing (recall: 0.3185 vs 0.2589, p<0.05). Our findings emphasize the importance of information-oriented training sample selection as opposed to the conventional practice of using all available training data.
Resolving References in Visually-Grounded Dialogue via Text Generation
Sep 23, 2023Vision-language models (VLMs) have shown to be effective at image retrieval based on simple text queries, but text-image retrieval based on conversational input remains a challenge. Consequently, if we want to use VLMs for reference resolution in visually-grounded dialogue, the discourse processing capabilities of these models need to be augmented. To address this issue, we propose fine-tuning a causal large language model (LLM) to generate definite descriptions that summarize coreferential information found in the linguistic context of references. We then use a pretrained VLM to identify referents based on the generated descriptions, zero-shot. We evaluate our approach on a manually annotated dataset of visually-grounded dialogues and achieve results that, on average, exceed the performance of the baselines we compare against. Furthermore, we find that using referent descriptions based on larger context windows has the potential to yield higher returns.
Domain-Guided Conditional Diffusion Model for Unsupervised Domain Adaptation
Sep 23, 2023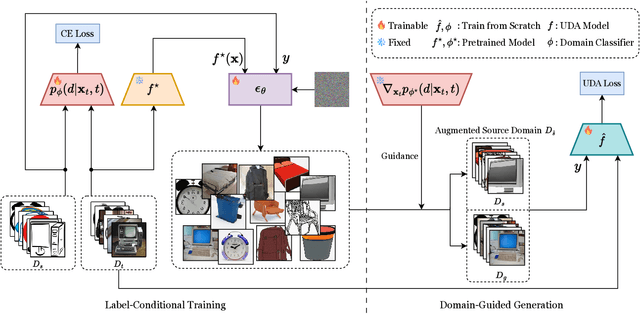
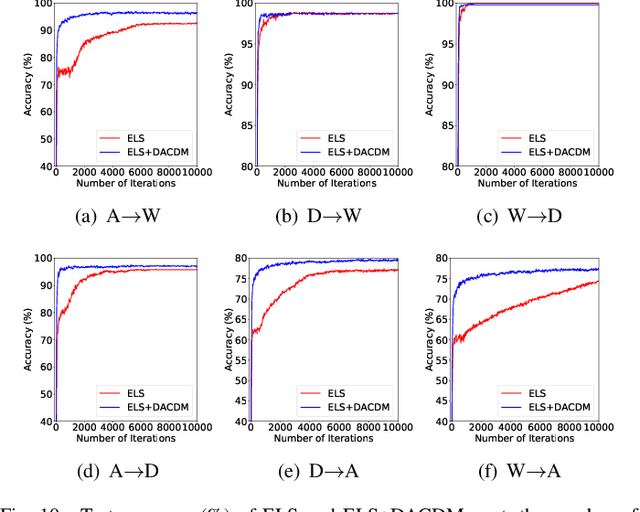
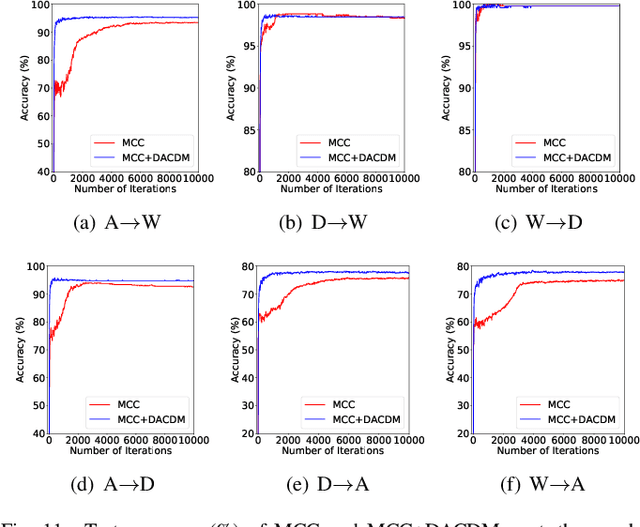
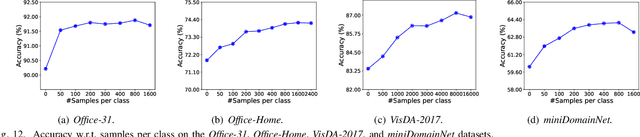
Limited transferability hinders the performance of deep learning models when applied to new application scenarios. Recently, Unsupervised Domain Adaptation (UDA) has achieved significant progress in addressing this issue via learning domain-invariant features. However, the performance of existing UDA methods is constrained by the large domain shift and limited target domain data. To alleviate these issues, we propose DomAin-guided Conditional Diffusion Model (DACDM) to generate high-fidelity and diversity samples for the target domain. In the proposed DACDM, by introducing class information, the labels of generated samples can be controlled, and a domain classifier is further introduced in DACDM to guide the generated samples for the target domain. The generated samples help existing UDA methods transfer from the source domain to the target domain more easily, thus improving the transfer performance. Extensive experiments on various benchmarks demonstrate that DACDM brings a large improvement to the performance of existing UDA methods.