 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Targeted aspect-based emotion analysis to detect opportunities and precaution in financial Twitter messages
Mar 30, 2024
Microblogging platforms, of which Twitter is a representative example, are valuable information sources for market screening and financial models. In them, users voluntarily provide relevant information, including educated knowledge on investments, reacting to the state of the stock markets in real-time and, often, influencing this state. We are interested in the user forecasts in financial, social media messages expressing opportunities and precautions about assets. We propose a novel Targeted Aspect-Based Emotion Analysis (TABEA) system that can individually discern the financial emotions (positive and negative forecasts) on the different stock market assets in the same tweet (instead of making an overall guess about that whole tweet). It is based on Natural Language Processing (NLP) techniques and Machine Learning streaming algorithms. The system comprises a constituency parsing module for parsing the tweets and splitting them into simpler declarative clauses; an offline data processing module to engineer textual, numerical and categorical features and analyse and select them based on their relevance; and a stream classification module to continuously process tweets on-the-fly. Experimental results on a labelled data set endorse our solution. It achieves over 90% precision for the target emotions, financial opportunity, and precaution on Twitter. To the best of our knowledge, no prior work in the literature has addressed this problem despite its practical interest in decision-making, and we are not aware of any previous NLP nor online Machine Learning approaches to TABEA.
The Shape of Word Embeddings: Recognizing Language Phylogenies through Topological Data Analysis
Mar 30, 2024Word embeddings represent language vocabularies as clouds of $d$-dimensional points. We investigate how information is conveyed by the general shape of these clouds, outside of representing the semantic meaning of each token. Specifically, we use the notion of persistent homology from topological data analysis (TDA) to measure the distances between language pairs from the shape of their unlabeled embeddings. We use these distance matrices to construct language phylogenetic trees over 81 Indo-European languages. Careful evaluation shows that our reconstructed trees exhibit strong similarities to the reference tree.
DataAgent: Evaluating Large Language Models' Ability to Answer Zero-Shot, Natural Language Queries
Mar 29, 2024Conventional processes for analyzing datasets and extracting meaningful information are often time-consuming and laborious. Previous work has identified manual, repetitive coding and data collection as major obstacles that hinder data scientists from undertaking more nuanced labor and high-level projects. To combat this, we evaluated OpenAI's GPT-3.5 as a "Language Data Scientist" (LDS) that can extrapolate key findings, including correlations and basic information, from a given dataset. The model was tested on a diverse set of benchmark datasets to evaluate its performance across multiple standards, including data science code-generation based tasks involving libraries such as NumPy, Pandas, Scikit-Learn, and TensorFlow, and was broadly successful in correctly answering a given data science query related to the benchmark dataset. The LDS used various novel prompt engineering techniques to effectively answer a given question, including Chain-of-Thought reinforcement and SayCan prompt engineering. Our findings demonstrate great potential for leveraging Large Language Models for low-level, zero-shot data analysis.
CCDSReFormer: Traffic Flow Prediction with a Criss-Crossed Dual-Stream Enhanced Rectified Transformer Model
Mar 29, 2024Accurate, and effective traffic forecasting is vital for smart traffic systems, crucial in urban traffic planning and management. Current Spatio-Temporal Transformer models, despite their prediction capabilities, struggle with balancing computational efficiency and accuracy, favoring global over local information, and handling spatial and temporal data separately, limiting insight into complex interactions. We introduce the Criss-Crossed Dual-Stream Enhanced Rectified Transformer model (CCDSReFormer), which includes three innovative modules: Enhanced Rectified Spatial Self-attention (ReSSA), Enhanced Rectified Delay Aware Self-attention (ReDASA), and Enhanced Rectified Temporal Self-attention (ReTSA). These modules aim to lower computational needs via sparse attention, focus on local information for better traffic dynamics understanding, and merge spatial and temporal insights through a unique learning method. Extensive tests on six real-world datasets highlight CCDSReFormer's superior performance. An ablation study also confirms the significant impact of each component on the model's predictive accuracy, showcasing our model's ability to forecast traffic flow effectively.
Negative Label Guided OOD Detection with Pretrained Vision-Language Models
Mar 29, 2024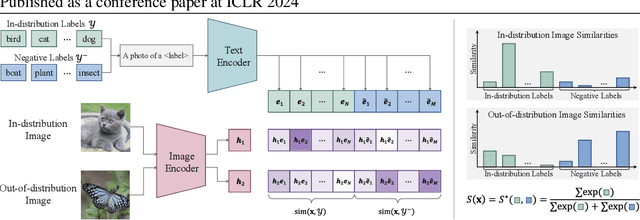
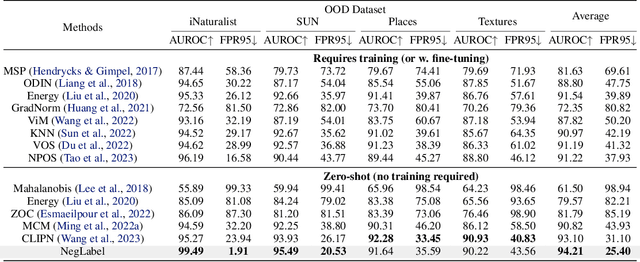

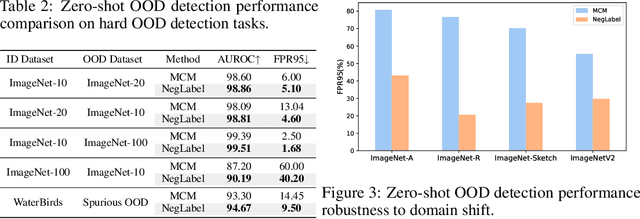
Out-of-distribution (OOD) detection aims at identifying samples from unknown classes, playing a crucial role in trustworthy models against errors on unexpected inputs. Extensive research has been dedicated to exploring OOD detection in the vision modality. Vision-language models (VLMs) can leverage both textual and visual information for various multi-modal applications, whereas few OOD detection methods take into account information from the text modality. In this paper, we propose a novel post hoc OOD detection method, called NegLabel, which takes a vast number of negative labels from extensive corpus databases. We design a novel scheme for the OOD score collaborated with negative labels. Theoretical analysis helps to understand the mechanism of negative labels. Extensive experiments demonstrate that our method NegLabel achieves state-of-the-art performance on various OOD detection benchmarks and generalizes well on multiple VLM architectures. Furthermore, our method NegLabel exhibits remarkable robustness against diverse domain shifts. The codes are available at https://github.com/tmlr-group/NegLabel.
FSMR: A Feature Swapping Multi-modal Reasoning Approach with Joint Textual and Visual Clues
Mar 29, 2024
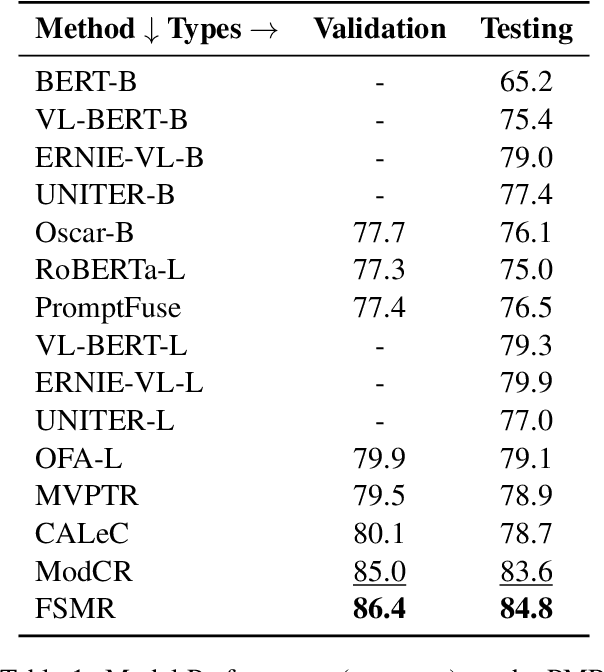
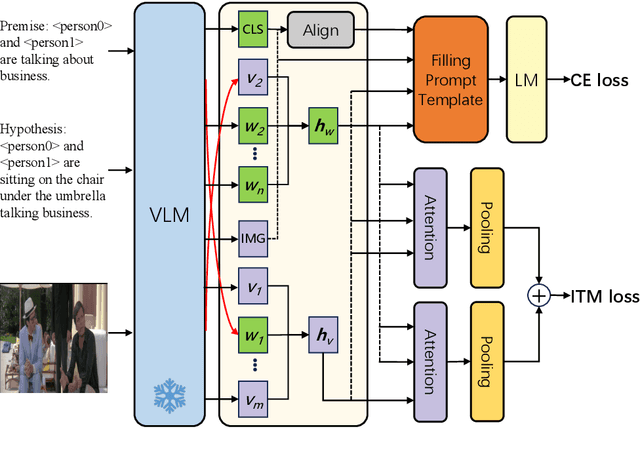
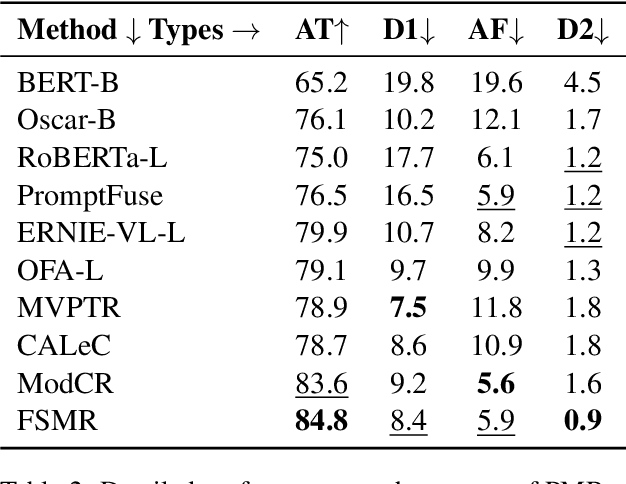
Multi-modal reasoning plays a vital role in bridging the gap between textual and visual information, enabling a deeper understanding of the context. This paper presents the Feature Swapping Multi-modal Reasoning (FSMR) model, designed to enhance multi-modal reasoning through feature swapping. FSMR leverages a pre-trained visual-language model as an encoder, accommodating both text and image inputs for effective feature representation from both modalities. It introduces a unique feature swapping module, enabling the exchange of features between identified objects in images and corresponding vocabulary words in text, thereby enhancing the model's comprehension of the interplay between images and text. To further bolster its multi-modal alignment capabilities, FSMR incorporates a multi-modal cross-attention mechanism, facilitating the joint modeling of textual and visual information. During training, we employ image-text matching and cross-entropy losses to ensure semantic consistency between visual and language elements. Extensive experiments on the PMR dataset demonstrate FSMR's superiority over state-of-the-art baseline models across various performance metrics.
A Signature Based Approach Towards Global Channel Charting with Ultra Low Complexity
Mar 29, 2024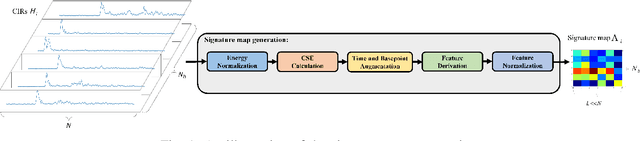
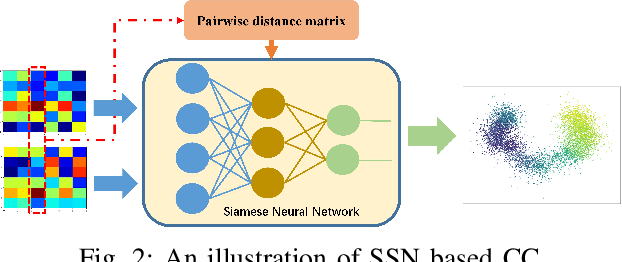
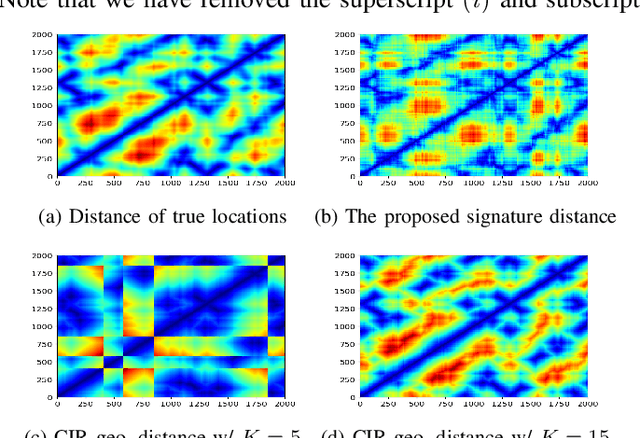
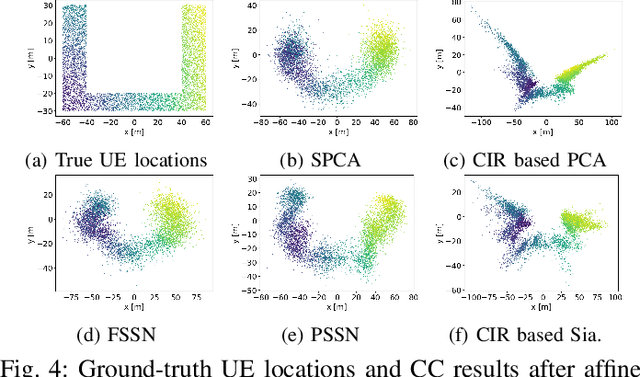
Channel charting, an unsupervised learning method that learns a low-dimensional representation from channel information to preserve geometrical property of physical space of user equipments (UEs), has drawn many attentions from both academic and industrial communities, because it can facilitate many downstream tasks, such as indoor localization, UE handover, beam management, and so on. However, many previous works mainly focus on charting that only preserves local geometry and use raw channel information to learn the chart, which do not consider the global geometry and are often computationally intensive and very time-consuming. Therefore, in this paper, a novel signature based approach for global channel charting with ultra low complexity is proposed. By using an iterated-integral based method called signature transform, a compact feature map and a novel distance metric are proposed, which enable channel charting with ultra low complexity and preserving both local and global geometry. We demonstrate the efficacy of our method using synthetic and open-source real-field datasets.
Inclusive Design Insights from a Preliminary Image-Based Conversational Search Systems Evaluation
Mar 29, 2024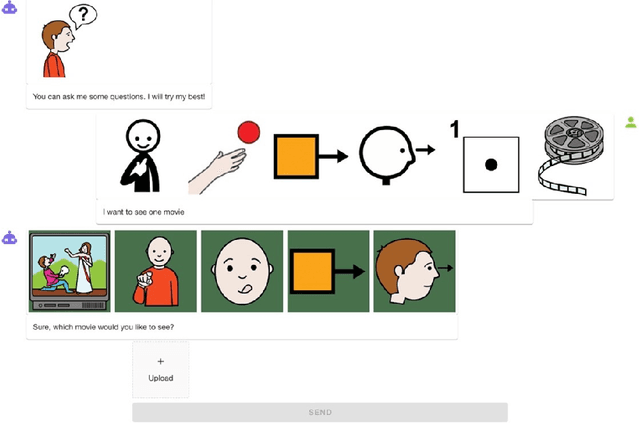
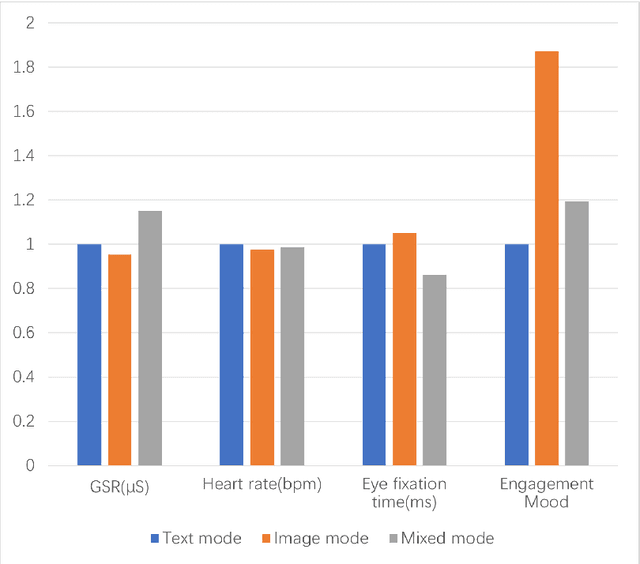
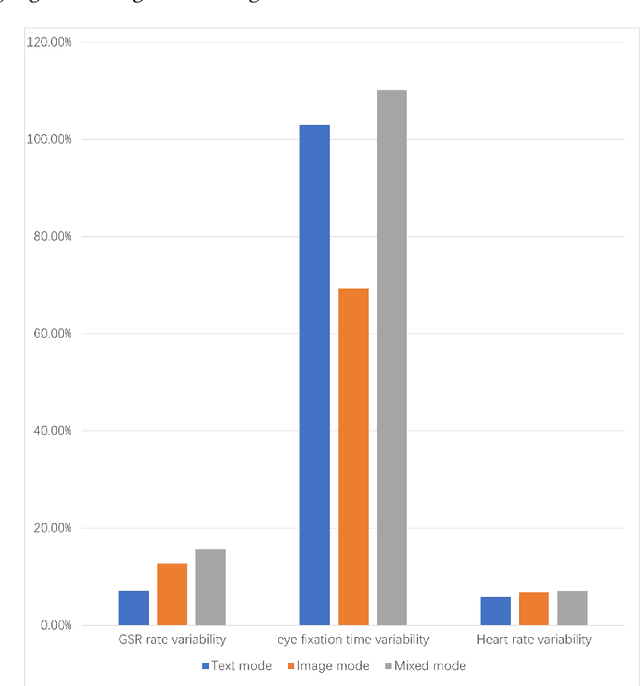
The digital realm has witnessed the rise of various search modalities, among which the Image-Based Conversational Search System stands out. This research delves into the design, implementation, and evaluation of this specific system, juxtaposing it against its text-based and mixed counterparts. A diverse participant cohort ensures a broad evaluation spectrum. Advanced tools facilitate emotion analysis, capturing user sentiments during interactions, while structured feedback sessions offer qualitative insights. Results indicate that while the text-based system minimizes user confusion, the image-based system presents challenges in direct information interpretation. However, the mixed system achieves the highest engagement, suggesting an optimal blend of visual and textual information. Notably, the potential of these systems, especially the image-based modality, to assist individuals with intellectual disabilities is highlighted. The study concludes that the Image-Based Conversational Search System, though challenging in some aspects, holds promise, especially when integrated into a mixed system, offering both clarity and engagement.
A General Method to Incorporate Spatial Information into Loss Functions for GAN-based Super-resolution Models
Mar 15, 2024

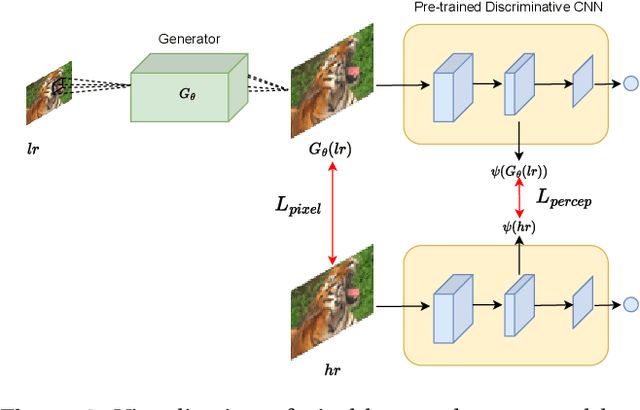
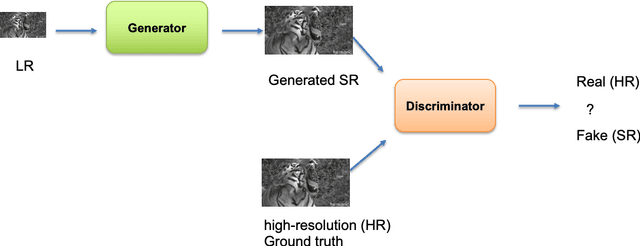
Generative Adversarial Networks (GANs) have shown great performance on super-resolution problems since they can generate more visually realistic images and video frames. However, these models often introduce side effects into the outputs, such as unexpected artifacts and noises. To reduce these artifacts and enhance the perceptual quality of the results, in this paper, we propose a general method that can be effectively used in most GAN-based super-resolution (SR) models by introducing essential spatial information into the training process. We extract spatial information from the input data and incorporate it into the training loss, making the corresponding loss a spatially adaptive (SA) one. After that, we utilize it to guide the training process. We will show that the proposed approach is independent of the methods used to extract the spatial information and independent of the SR tasks and models. This method consistently guides the training process towards generating visually pleasing SR images and video frames, substantially mitigating artifacts and noise, ultimately leading to enhanced perceptual quality.
Fluid Antenna Relay Assisted Communication Systems Through Antenna Location Optimization
Mar 31, 2024In this paper, we investigate the problem of resource allocation for fluid antenna relay (FAR) system with antenna location optimization. In the considered model, each user transmits information to a base station (BS) with help of FAR. The antenna location of the FAR is flexible and can be adapted to dynamic location distribution of the users. We formulate a sum rate maximization problem through jointly optimizing the antenna location and bandwidth allocation with meeting the minimum rate requirements, total bandwidth budget, and feasible antenna region constraints. To solve this problem, we obtain the optimal bandwidth in closed form. Based on the optimal bandwidth, the original problem is reduced to the antenna location optimization problem and an alternating algorithm is proposed. Simulation results verify the effectiveness of the proposed algorithm and the sum rate can be increased by up to 125% compared to the conventional schemes.