 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Advanced Computing and Related Applications Leveraging Brain-inspired Spiking Neural Networks
Sep 08, 2023
In the rapid evolution of next-generation brain-inspired artificial intelligence and increasingly sophisticated electromagnetic environment, the most bionic characteristics and anti-interference performance of spiking neural networks show great potential in terms of computational speed, real-time information processing, and spatio-temporal information processing. Data processing. Spiking neural network is one of the cores of brain-like artificial intelligence, which realizes brain-like computing by simulating the structure and information transfer mode of biological neural networks. This paper summarizes the strengths, weaknesses and applicability of five neuronal models and analyzes the characteristics of five network topologies; then reviews the spiking neural network algorithms and summarizes the unsupervised learning algorithms based on synaptic plasticity rules and four types of supervised learning algorithms from the perspectives of unsupervised learning and supervised learning; finally focuses on the review of brain-like neuromorphic chips under research at home and abroad. This paper is intended to provide learning concepts and research orientations for the peers who are new to the research field of spiking neural networks through systematic summaries.
Modeling Recommender Ecosystems: Research Challenges at the Intersection of Mechanism Design, Reinforcement Learning and Generative Models
Sep 22, 2023
Modern recommender systems lie at the heart of complex ecosystems that couple the behavior of users, content providers, advertisers, and other actors. Despite this, the focus of the majority of recommender research -- and most practical recommenders of any import -- is on the local, myopic optimization of the recommendations made to individual users. This comes at a significant cost to the long-term utility that recommenders could generate for its users. We argue that explicitly modeling the incentives and behaviors of all actors in the system -- and the interactions among them induced by the recommender's policy -- is strictly necessary if one is to maximize the value the system brings to these actors and improve overall ecosystem "health". Doing so requires: optimization over long horizons using techniques such as reinforcement learning; making inevitable tradeoffs in the utility that can be generated for different actors using the methods of social choice; reducing information asymmetry, while accounting for incentives and strategic behavior, using the tools of mechanism design; better modeling of both user and item-provider behaviors by incorporating notions from behavioral economics and psychology; and exploiting recent advances in generative and foundation models to make these mechanisms interpretable and actionable. We propose a conceptual framework that encompasses these elements, and articulate a number of research challenges that emerge at the intersection of these different disciplines.
PI-RADS v2 Compliant Automated Segmentation of Prostate Zones Using co-training Motivated Multi-task Dual-Path CNN
Sep 22, 2023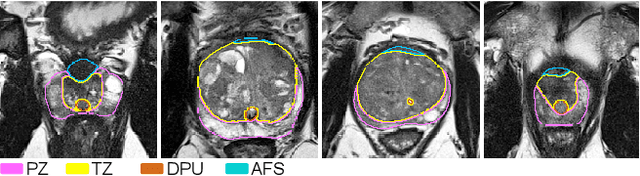

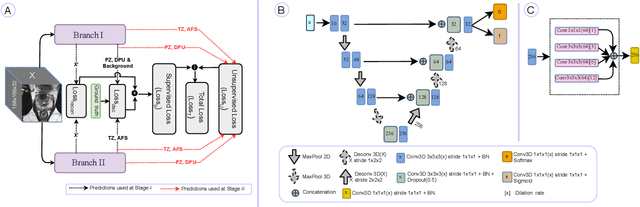
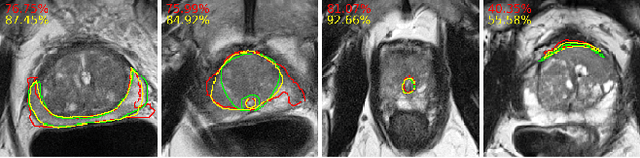
The detailed images produced by Magnetic Resonance Imaging (MRI) provide life-critical information for the diagnosis and treatment of prostate cancer. To provide standardized acquisition, interpretation and usage of the complex MRI images, the PI-RADS v2 guideline was proposed. An automated segmentation following the guideline facilitates consistent and precise lesion detection, staging and treatment. The guideline recommends a division of the prostate into four zones, PZ (peripheral zone), TZ (transition zone), DPU (distal prostatic urethra) and AFS (anterior fibromuscular stroma). Not every zone shares a boundary with the others and is present in every slice. Further, the representations captured by a single model might not suffice for all zones. This motivated us to design a dual-branch convolutional neural network (CNN), where each branch captures the representations of the connected zones separately. Further, the representations from different branches act complementary to each other at the second stage of training, where they are fine-tuned through an unsupervised loss. The loss penalises the difference in predictions from the two branches for the same class. We also incorporate multi-task learning in our framework to further improve the segmentation accuracy. The proposed approach improves the segmentation accuracy of the baseline (mean absolute symmetric distance) by 7.56%, 11.00%, 58.43% and 19.67% for PZ, TZ, DPU and AFS zones respectively.
Benchmarking machine learning models for quantum state classification
Sep 14, 2023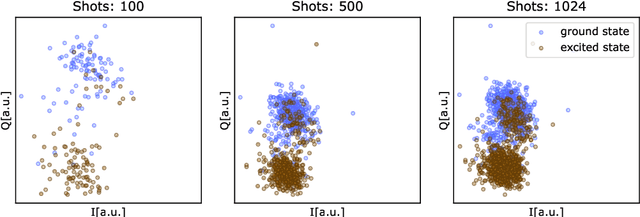
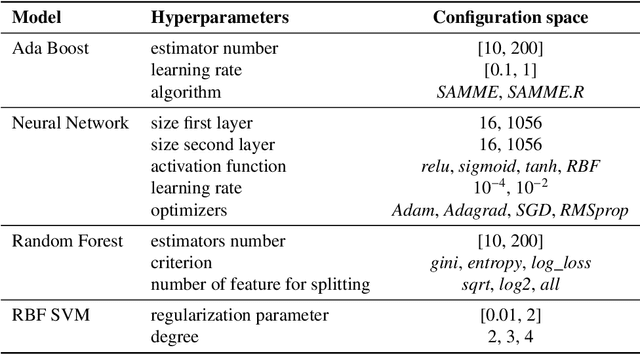
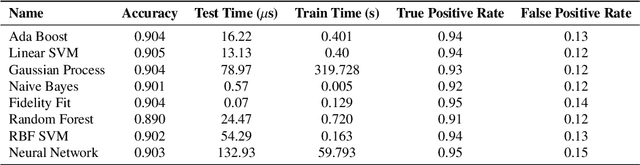
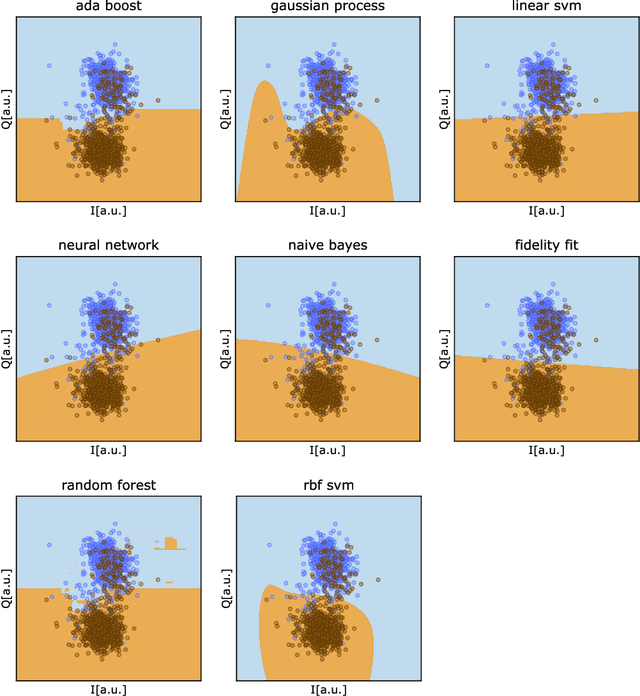
Quantum computing is a growing field where the information is processed by two-levels quantum states known as qubits. Current physical realizations of qubits require a careful calibration, composed by different experiments, due to noise and decoherence phenomena. Among the different characterization experiments, a crucial step is to develop a model to classify the measured state by discriminating the ground state from the excited state. In this proceedings we benchmark multiple classification techniques applied to real quantum devices.
Phase-Specific Augmented Reality Guidance for Microscopic Cataract Surgery Using Long-Short Spatiotemporal Aggregation Transformer
Sep 11, 2023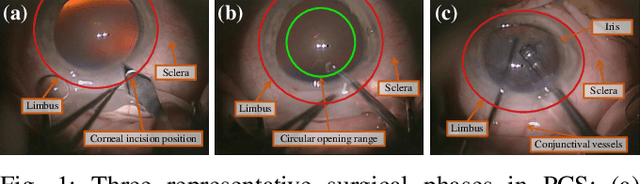
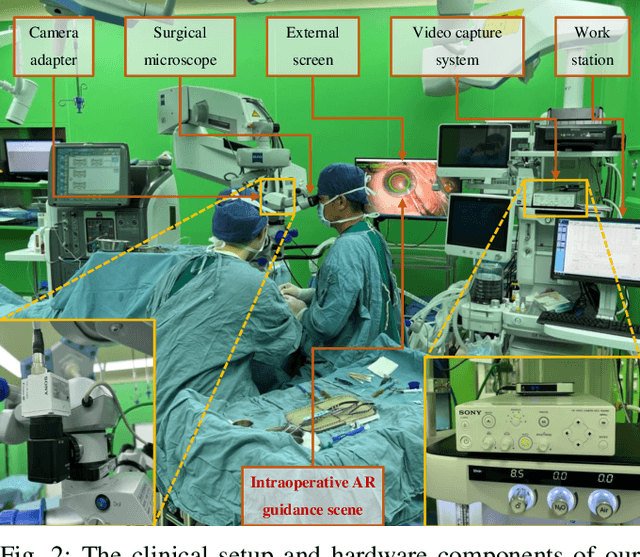
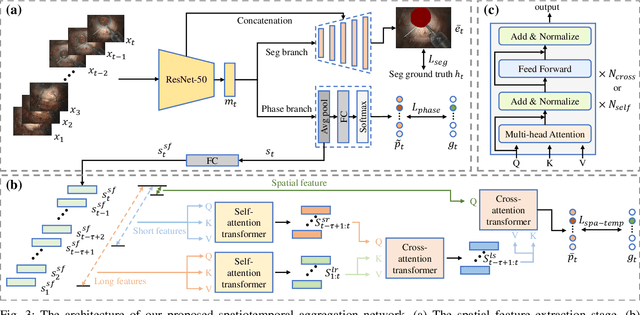
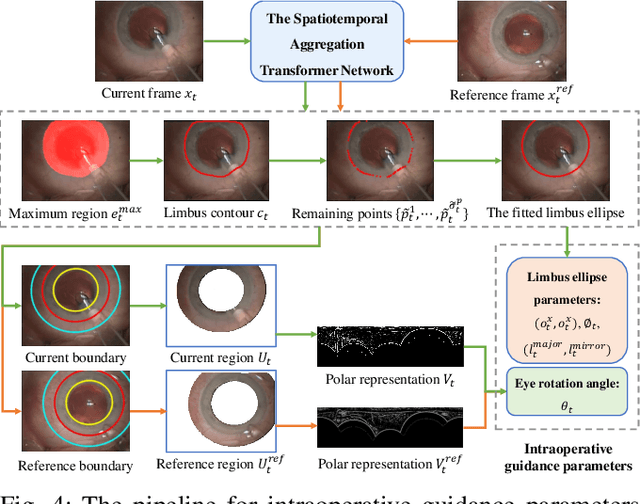
Phacoemulsification cataract surgery (PCS) is a routine procedure conducted using a surgical microscope, heavily reliant on the skill of the ophthalmologist. While existing PCS guidance systems extract valuable information from surgical microscopic videos to enhance intraoperative proficiency, they suffer from non-phasespecific guidance, leading to redundant visual information. In this study, our major contribution is the development of a novel phase-specific augmented reality (AR) guidance system, which offers tailored AR information corresponding to the recognized surgical phase. Leveraging the inherent quasi-standardized nature of PCS procedures, we propose a two-stage surgical microscopic video recognition network. In the first stage, we implement a multi-task learning structure to segment the surgical limbus region and extract limbus region-focused spatial feature for each frame. In the second stage, we propose the long-short spatiotemporal aggregation transformer (LS-SAT) network to model local fine-grained and global temporal relationships, and combine the extracted spatial features to recognize the current surgical phase. Additionally, we collaborate closely with ophthalmologists to design AR visual cues by utilizing techniques such as limbus ellipse fitting and regional restricted normal cross-correlation rotation computation. We evaluated the network on publicly available and in-house datasets, with comparison results demonstrating its superior performance compared to related works. Ablation results further validated the effectiveness of the limbus region-focused spatial feature extractor and the combination of temporal features. Furthermore, the developed system was evaluated in a clinical setup, with results indicating remarkable accuracy and real-time performance. underscoring its potential for clinical applications.
MA-SAM: Modality-agnostic SAM Adaptation for 3D Medical Image Segmentation
Sep 16, 2023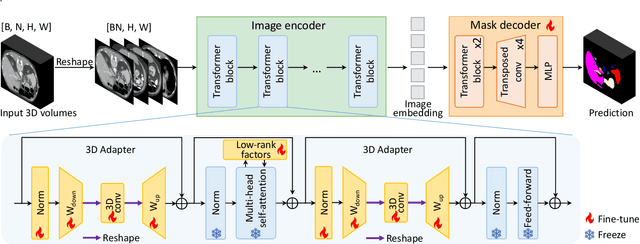
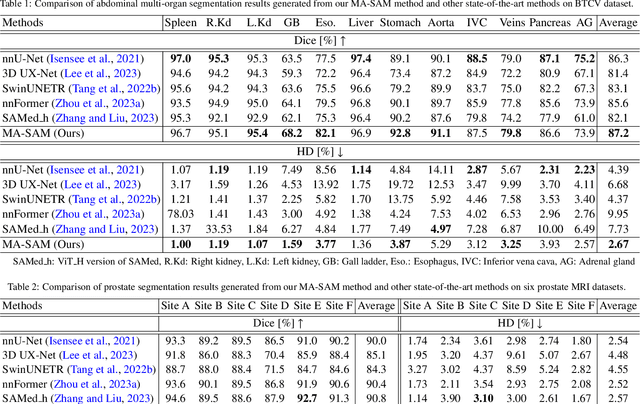
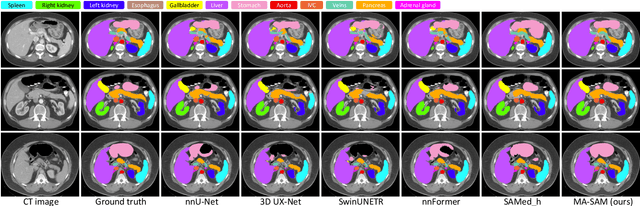
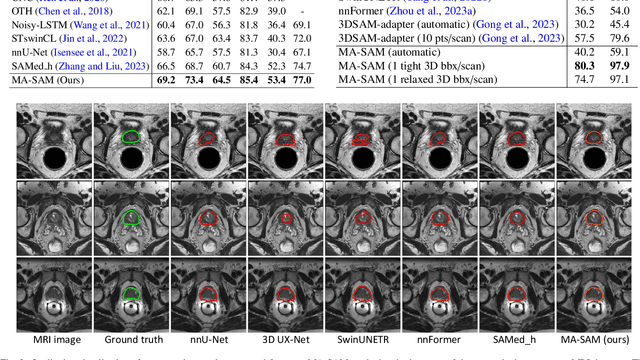
The Segment Anything Model (SAM), a foundation model for general image segmentation, has demonstrated impressive zero-shot performance across numerous natural image segmentation tasks. However, SAM's performance significantly declines when applied to medical images, primarily due to the substantial disparity between natural and medical image domains. To effectively adapt SAM to medical images, it is important to incorporate critical third-dimensional information, i.e., volumetric or temporal knowledge, during fine-tuning. Simultaneously, we aim to harness SAM's pre-trained weights within its original 2D backbone to the fullest extent. In this paper, we introduce a modality-agnostic SAM adaptation framework, named as MA-SAM, that is applicable to various volumetric and video medical data. Our method roots in the parameter-efficient fine-tuning strategy to update only a small portion of weight increments while preserving the majority of SAM's pre-trained weights. By injecting a series of 3D adapters into the transformer blocks of the image encoder, our method enables the pre-trained 2D backbone to extract third-dimensional information from input data. The effectiveness of our method has been comprehensively evaluated on four medical image segmentation tasks, by using 10 public datasets across CT, MRI, and surgical video data. Remarkably, without using any prompt, our method consistently outperforms various state-of-the-art 3D approaches, surpassing nnU-Net by 0.9%, 2.6%, and 9.9% in Dice for CT multi-organ segmentation, MRI prostate segmentation, and surgical scene segmentation respectively. Our model also demonstrates strong generalization, and excels in challenging tumor segmentation when prompts are used. Our code is available at: https://github.com/cchen-cc/MA-SAM.
Semantic Text Compression for Classification
Sep 19, 2023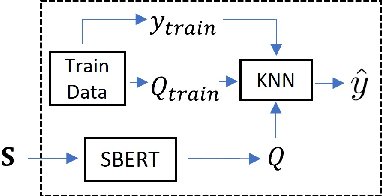
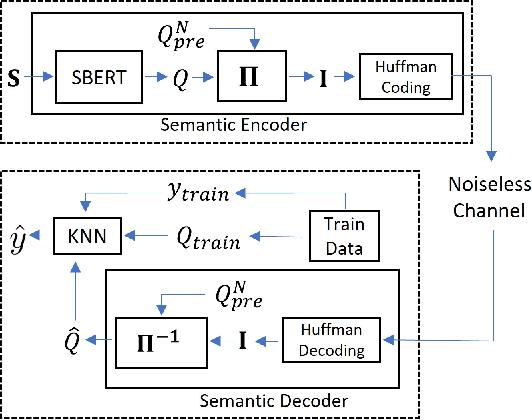
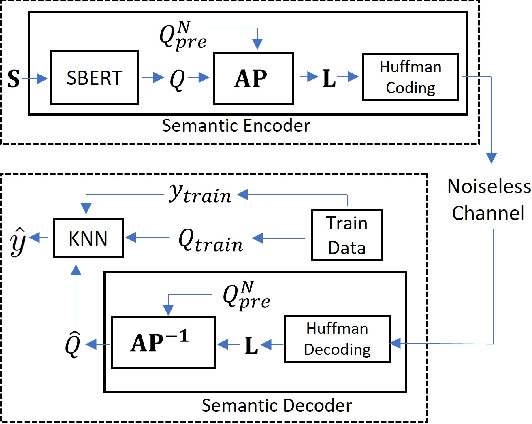
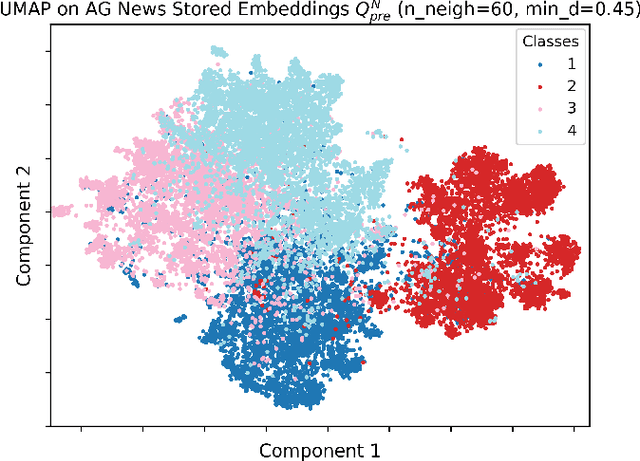
We study semantic compression for text where meanings contained in the text are conveyed to a source decoder, e.g., for classification. The main motivator to move to such an approach of recovering the meaning without requiring exact reconstruction is the potential resource savings, both in storage and in conveying the information to another node. Towards this end, we propose semantic quantization and compression approaches for text where we utilize sentence embeddings and the semantic distortion metric to preserve the meaning. Our results demonstrate that the proposed semantic approaches result in substantial (orders of magnitude) savings in the required number of bits for message representation at the expense of very modest accuracy loss compared to the semantic agnostic baseline. We compare the results of proposed approaches and observe that resource savings enabled by semantic quantization can be further amplified by semantic clustering. Importantly, we observe the generalizability of the proposed methodology which produces excellent results on many benchmark text classification datasets with a diverse array of contexts.
Artificial Intelligence-Enabled Intelligent Assistant for Personalized and Adaptive Learning in Higher Education
Sep 19, 2023This paper presents a novel framework, Artificial Intelligence-Enabled Intelligent Assistant (AIIA), for personalized and adaptive learning in higher education. The AIIA system leverages advanced AI and Natural Language Processing (NLP) techniques to create an interactive and engaging learning platform. This platform is engineered to reduce cognitive load on learners by providing easy access to information, facilitating knowledge assessment, and delivering personalized learning support tailored to individual needs and learning styles. The AIIA's capabilities include understanding and responding to student inquiries, generating quizzes and flashcards, and offering personalized learning pathways. The research findings have the potential to significantly impact the design, implementation, and evaluation of AI-enabled Virtual Teaching Assistants (VTAs) in higher education, informing the development of innovative educational tools that can enhance student learning outcomes, engagement, and satisfaction. The paper presents the methodology, system architecture, intelligent services, and integration with Learning Management Systems (LMSs) while discussing the challenges, limitations, and future directions for the development of AI-enabled intelligent assistants in education.
A spectrum of physics-informed Gaussian processes for regression in engineering
Sep 19, 2023Despite the growing availability of sensing and data in general, we remain unable to fully characterise many in-service engineering systems and structures from a purely data-driven approach. The vast data and resources available to capture human activity are unmatched in our engineered world, and, even in cases where data could be referred to as ``big,'' they will rarely hold information across operational windows or life spans. This paper pursues the combination of machine learning technology and physics-based reasoning to enhance our ability to make predictive models with limited data. By explicitly linking the physics-based view of stochastic processes with a data-based regression approach, a spectrum of possible Gaussian process models are introduced that enable the incorporation of different levels of expert knowledge of a system. Examples illustrate how these approaches can significantly reduce reliance on data collection whilst also increasing the interpretability of the model, another important consideration in this context.
Rigorously Assessing Natural Language Explanations of Neurons
Sep 19, 2023Natural language is an appealing medium for explaining how large language models process and store information, but evaluating the faithfulness of such explanations is challenging. To help address this, we develop two modes of evaluation for natural language explanations that claim individual neurons represent a concept in a text input. In the observational mode, we evaluate claims that a neuron $a$ activates on all and only input strings that refer to a concept picked out by the proposed explanation $E$. In the intervention mode, we construe $E$ as a claim that the neuron $a$ is a causal mediator of the concept denoted by $E$. We apply our framework to the GPT-4-generated explanations of GPT-2 XL neurons of Bills et al. (2023) and show that even the most confident explanations have high error rates and little to no causal efficacy. We close the paper by critically assessing whether natural language is a good choice for explanations and whether neurons are the best level of analysis.