 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Near-Field Beam Training: Joint Angle and Range Estimation with DFT Codebook
Sep 21, 2023
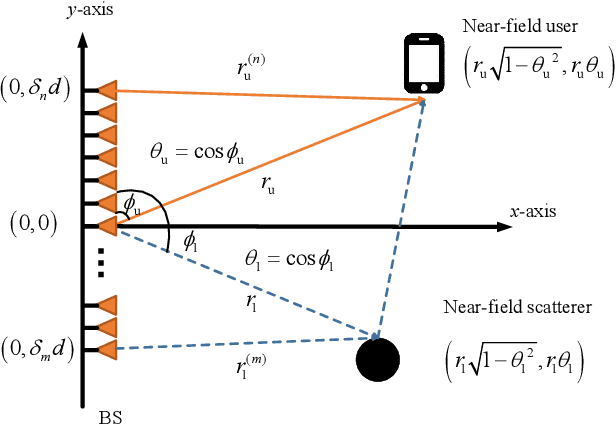
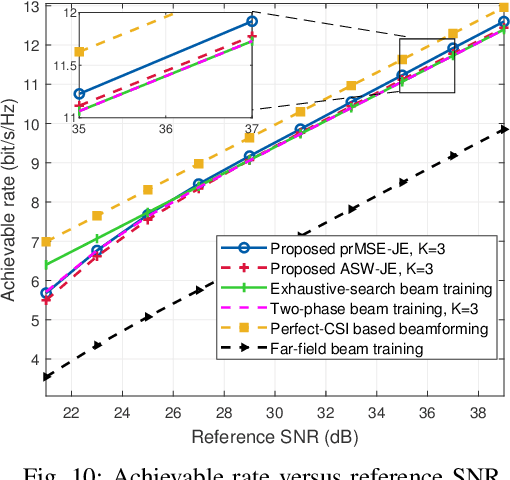
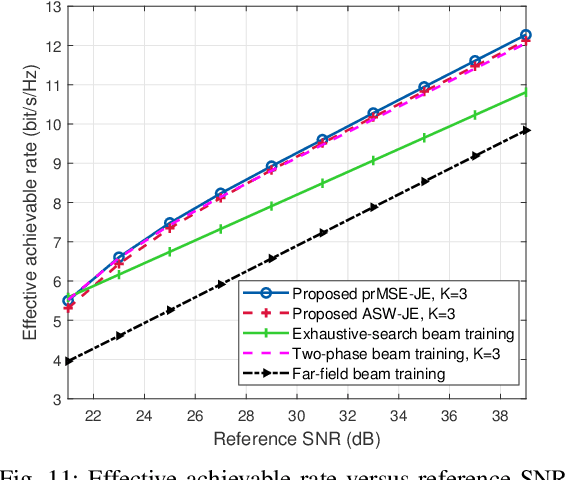
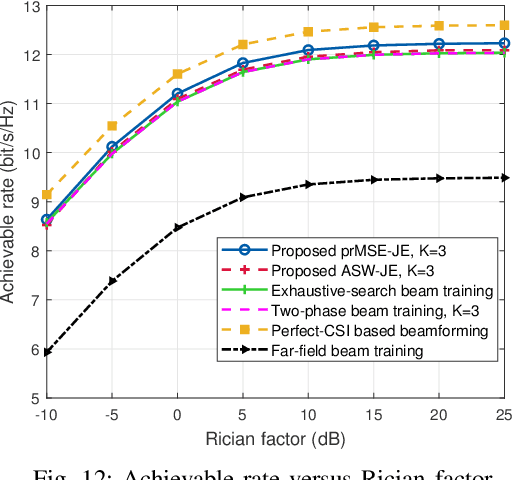
Prior works on near-field beam training have mostly assumed dedicated polar-domain codebook and on-grid range estimation, which, however, may suffer long training overhead and degraded estimation accuracy. To address these issues, we propose in this paper new and efficient beam training schemes with off-grid range estimation by using conventional discrete Fourier transform (DFT) codebook. Specifically, we first analyze the received beam pattern at the user when far-field beamforming vectors are used for beam scanning, and show an interesting result that this beam pattern contains useful user angle and range information. Then, we propose two efficient schemes to jointly estimate the user angle and range with the DFT codebook. The first scheme estimates the user angle based on a defined angular support and resolves the user range by leveraging an approximated angular support width, while the second scheme estimates the user range by minimizing a power ratio mean square error (MSE) to improve the range estimation accuracy. Finally, numerical simulations show that our proposed schemes greatly reduce the near-field beam training overhead and improve the range estimation accuracy as compared to various benchmark schemes.
Uplift vs. predictive modeling: a theoretical analysis
Sep 21, 2023
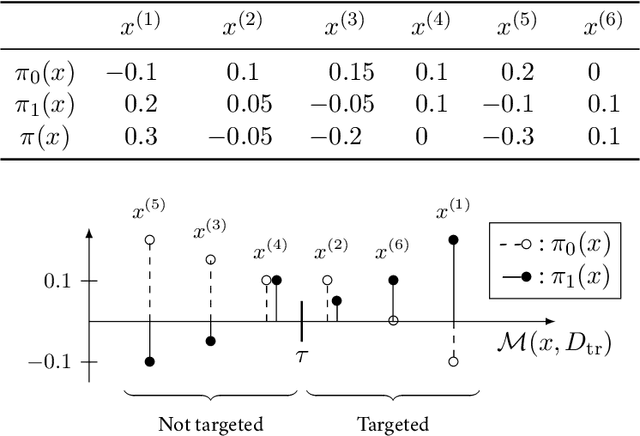
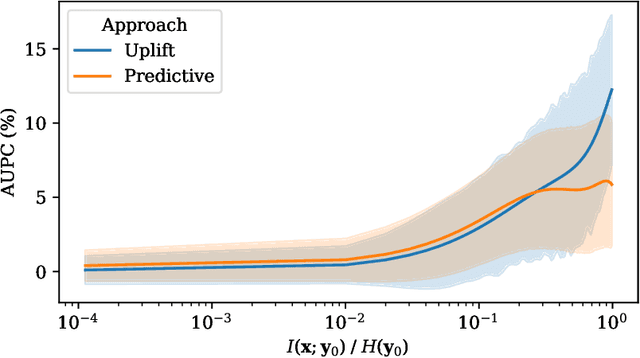
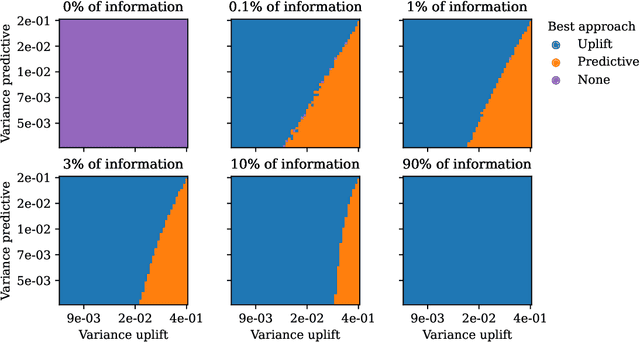
Despite the growing popularity of machine-learning techniques in decision-making, the added value of causal-oriented strategies with respect to pure machine-learning approaches has rarely been quantified in the literature. These strategies are crucial for practitioners in various domains, such as marketing, telecommunications, health care and finance. This paper presents a comprehensive treatment of the subject, starting from firm theoretical foundations and highlighting the parameters that influence the performance of the uplift and predictive approaches. The focus of the paper is on a binary outcome case and a binary action, and the paper presents a theoretical analysis of uplift modeling, comparing it with the classical predictive approach. The main research contributions of the paper include a new formulation of the measure of profit, a formal proof of the convergence of the uplift curve to the measure of profit ,and an illustration, through simulations, of the conditions under which predictive approaches still outperform uplift modeling. We show that the mutual information between the features and the outcome plays a significant role, along with the variance of the estimators, the distribution of the potential outcomes and the underlying costs and benefits of the treatment and the outcome.
A Sentence Speaks a Thousand Images: Domain Generalization through Distilling CLIP with Language Guidance
Sep 21, 2023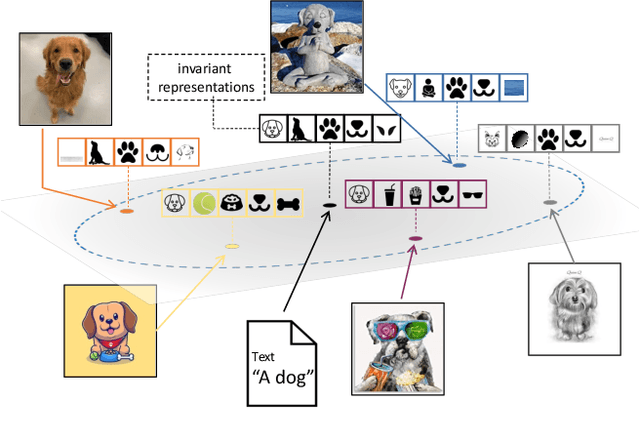
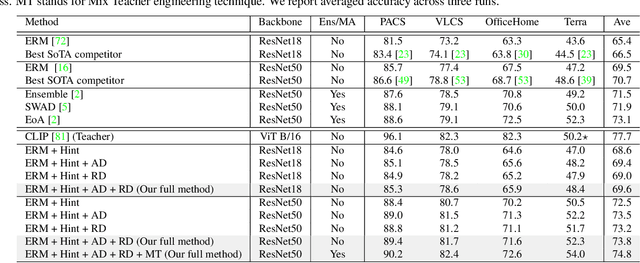
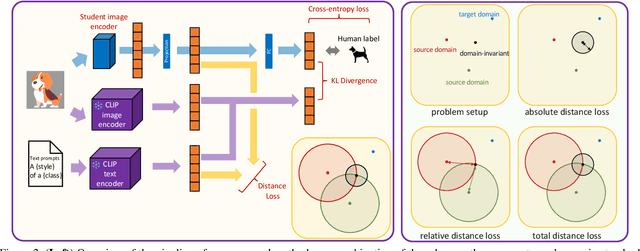

Domain generalization studies the problem of training a model with samples from several domains (or distributions) and then testing the model with samples from a new, unseen domain. In this paper, we propose a novel approach for domain generalization that leverages recent advances in large vision-language models, specifically a CLIP teacher model, to train a smaller model that generalizes to unseen domains. The key technical contribution is a new type of regularization that requires the student's learned image representations to be close to the teacher's learned text representations obtained from encoding the corresponding text descriptions of images. We introduce two designs of the loss function, absolute and relative distance, which provide specific guidance on how the training process of the student model should be regularized. We evaluate our proposed method, dubbed RISE (Regularized Invariance with Semantic Embeddings), on various benchmark datasets and show that it outperforms several state-of-the-art domain generalization methods. To our knowledge, our work is the first to leverage knowledge distillation using a large vision-language model for domain generalization. By incorporating text-based information, RISE improves the generalization capability of machine learning models.
Methods for generating and evaluating synthetic longitudinal patient data: a systematic review
Sep 21, 2023The proliferation of data in recent years has led to the advancement and utilization of various statistical and deep learning techniques, thus expediting research and development activities. However, not all industries have benefited equally from the surge in data availability, partly due to legal restrictions on data usage and privacy regulations, such as in medicine. To address this issue, various statistical disclosure and privacy-preserving methods have been proposed, including the use of synthetic data generation. Synthetic data are generated based on some existing data, with the aim of replicating them as closely as possible and acting as a proxy for real sensitive data. This paper presents a systematic review of methods for generating and evaluating synthetic longitudinal patient data, a prevalent data type in medicine. The review adheres to the PRISMA guidelines and covers literature from five databases until the end of 2022. The paper describes 17 methods, ranging from traditional simulation techniques to modern deep learning methods. The collected information includes, but is not limited to, method type, source code availability, and approaches used to assess resemblance, utility, and privacy. Furthermore, the paper discusses practical guidelines and key considerations for developing synthetic longitudinal data generation methods.
Vulnerability of 3D Face Recognition Systems to Morphing Attacks
Sep 21, 2023
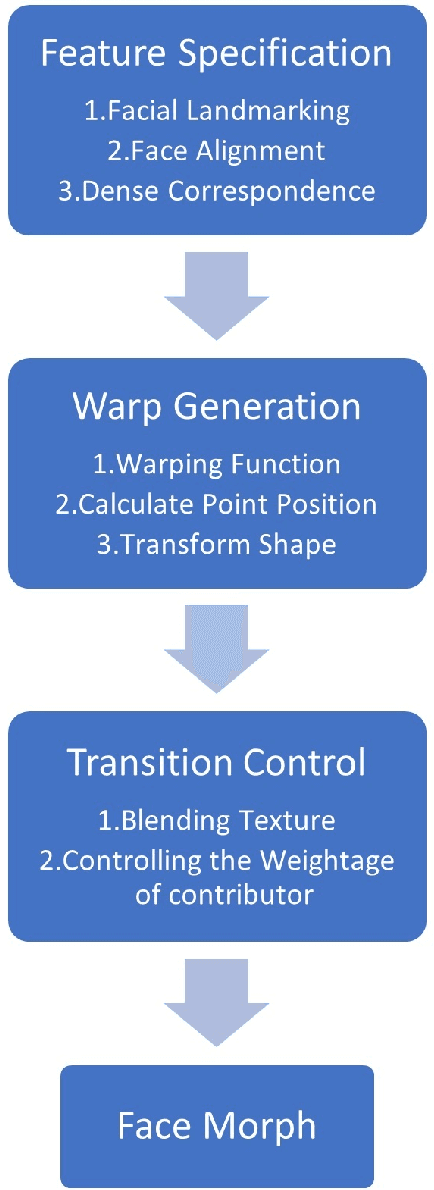


In recent years face recognition systems have been brought to the mainstream due to development in hardware and software. Consistent efforts are being made to make them better and more secure. This has also brought developments in 3D face recognition systems at a rapid pace. These 3DFR systems are expected to overcome certain vulnerabilities of 2DFR systems. One such problem that the domain of 2DFR systems face is face image morphing. A substantial amount of research is being done for generation of high quality face morphs along with detection of attacks from these morphs. Comparatively the understanding of vulnerability of 3DFR systems against 3D face morphs is less. But at the same time an expectation is set from 3DFR systems to be more robust against such attacks. This paper attempts to research and gain more information on this matter. The paper describes a couple of methods that can be used to generate 3D face morphs. The face morphs that are generated using this method are then compared to the contributing faces to obtain similarity scores. The highest MMPMR is obtained around 40% with RMMR of 41.76% when 3DFRS are attacked with look-a-like morphs.
Bridging the Gap: Learning Pace Synchronization for Open-World Semi-Supervised Learning
Sep 21, 2023In open-world semi-supervised learning, a machine learning model is tasked with uncovering novel categories from unlabeled data while maintaining performance on seen categories from labeled data. The central challenge is the substantial learning gap between seen and novel categories, as the model learns the former faster due to accurate supervisory information. To address this, we introduce 1) an adaptive margin loss based on estimated class distribution, which encourages a large negative margin for samples in seen classes, to synchronize learning paces, and 2) pseudo-label contrastive clustering, which pulls together samples which are likely from the same class in the output space, to enhance novel class discovery. Our extensive evaluations on multiple datasets demonstrate that existing models still hinder novel class learning, whereas our approach strikingly balances both seen and novel classes, achieving a remarkable 3% average accuracy increase on the ImageNet dataset compared to the prior state-of-the-art. Additionally, we find that fine-tuning the self-supervised pre-trained backbone significantly boosts performance over the default in prior literature. After our paper is accepted, we will release the code.
BitCoin: Bidirectional Tagging and Supervised Contrastive Learning based Joint Relational Triple Extraction Framework
Sep 21, 2023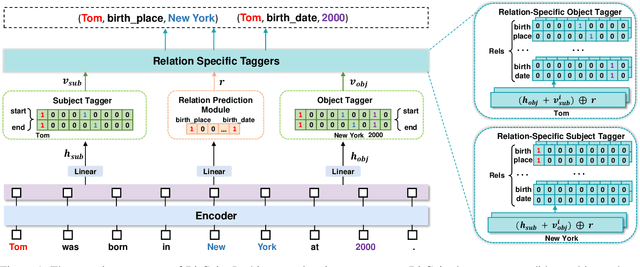
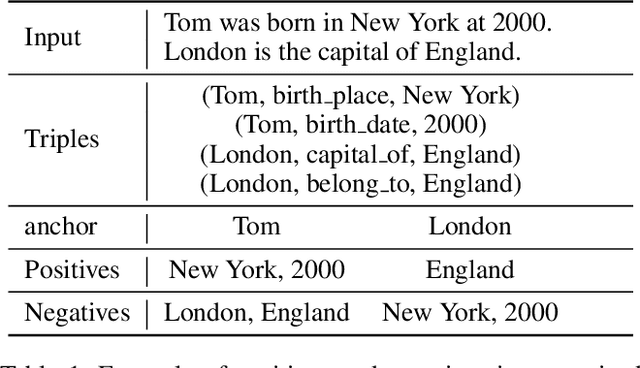

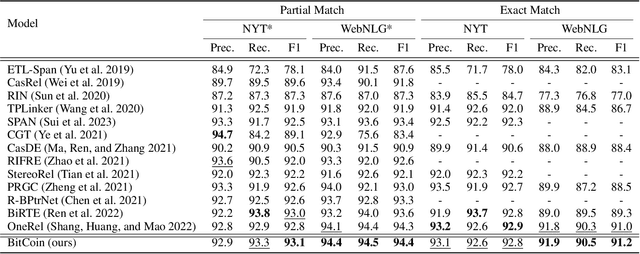
Relation triple extraction (RTE) is an essential task in information extraction and knowledge graph construction. Despite recent advancements, existing methods still exhibit certain limitations. They just employ generalized pre-trained models and do not consider the specificity of RTE tasks. Moreover, existing tagging-based approaches typically decompose the RTE task into two subtasks, initially identifying subjects and subsequently identifying objects and relations. They solely focus on extracting relational triples from subject to object, neglecting that once the extraction of a subject fails, it fails in extracting all triples associated with that subject. To address these issues, we propose BitCoin, an innovative Bidirectional tagging and supervised Contrastive learning based joint relational triple extraction framework. Specifically, we design a supervised contrastive learning method that considers multiple positives per anchor rather than restricting it to just one positive. Furthermore, a penalty term is introduced to prevent excessive similarity between the subject and object. Our framework implements taggers in two directions, enabling triples extraction from subject to object and object to subject. Experimental results show that BitCoin achieves state-of-the-art results on the benchmark datasets and significantly improves the F1 score on Normal, SEO, EPO, and multiple relation extraction tasks.
Resource Allocation for Semantic-Aware Mobile Edge Computing Systems
Sep 21, 2023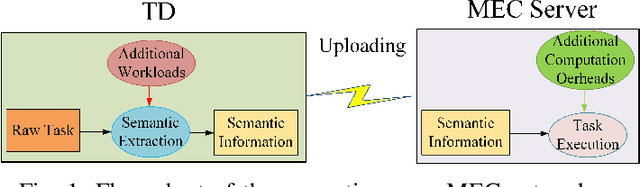
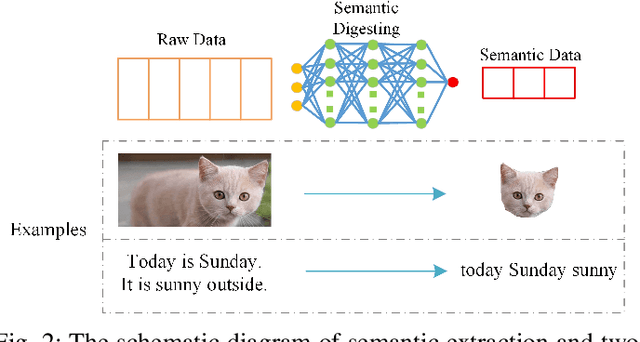
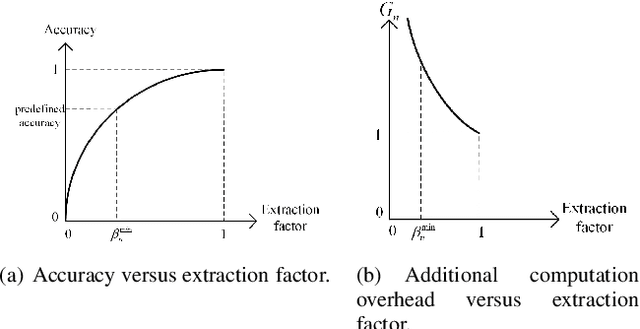
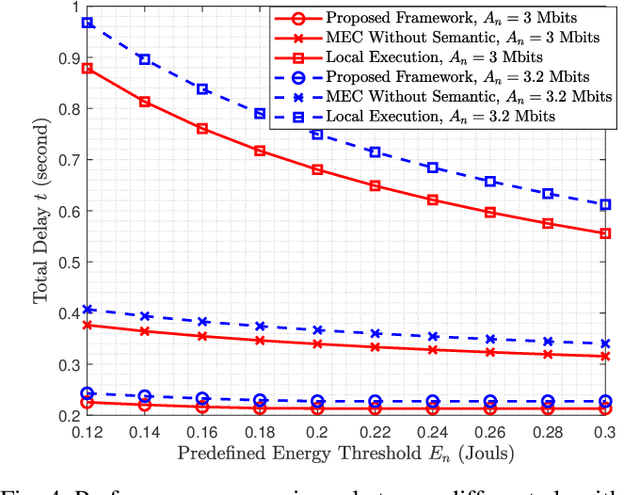
In this paper, a semantic-aware joint communication and computation resource allocation framework is proposed for mobile edge computing (MEC) systems. In the considered system, each terminal device (TD) has a computation task, which needs to be executed by offloading to the MEC server. To further decrease the transmission burden, each TD sends the small-size extracted semantic information of tasks to the server instead of the large-size raw data. An optimization problem of joint semantic-aware division factor, communication and computation resource management is formulated. The problem aims to minimize the maximum execution delay of all TDs while satisfying energy consumption constraints. The original non-convex problem is transformed into a convex one based on the geometric programming and the optimal solution is obtained by the alternating optimization algorithm. Moreover, the closed-form optimal solution of the semantic extraction factor is derived. Simulation results show that the proposed algorithm yields up to 37.10% delay reduction compared with the benchmark algorithm without semantic-aware allocation. Furthermore, small semantic extraction factors are preferred in the case of large task sizes and poor channel conditions.
Fast Satellite Tensorial Radiance Field for Multi-date Satellite Imagery of Large Size
Sep 21, 2023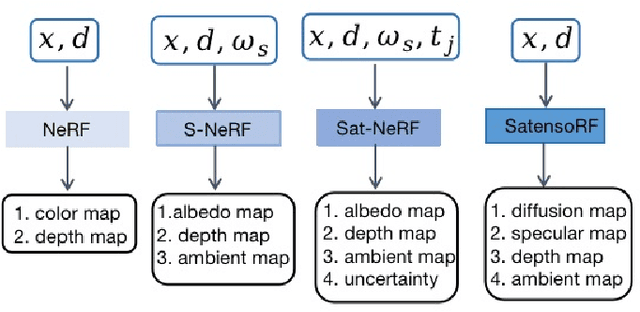
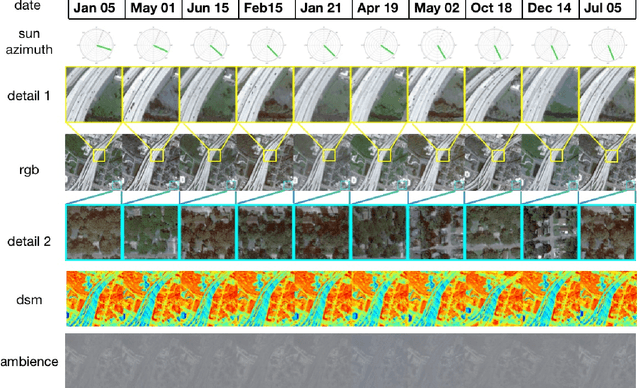
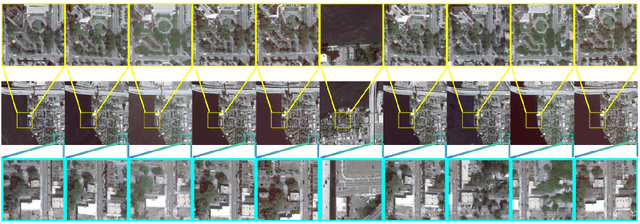

Existing NeRF models for satellite images suffer from slow speeds, mandatory solar information as input, and limitations in handling large satellite images. In response, we present SatensoRF, which significantly accelerates the entire process while employing fewer parameters for satellite imagery of large size. Besides, we observed that the prevalent assumption of Lambertian surfaces in neural radiance fields falls short for vegetative and aquatic elements. In contrast to the traditional hierarchical MLP-based scene representation, we have chosen a multiscale tensor decomposition approach for color, volume density, and auxiliary variables to model the lightfield with specular color. Additionally, to rectify inconsistencies in multi-date imagery, we incorporate total variation loss to restore the density tensor field and treat the problem as a denosing task.To validate our approach, we conducted assessments of SatensoRF using subsets from the spacenet multi-view dataset, which includes both multi-date and single-date multi-view RGB images. Our results clearly demonstrate that SatensoRF surpasses the state-of-the-art Sat-NeRF series in terms of novel view synthesis performance. Significantly, SatensoRF requires fewer parameters for training, resulting in faster training and inference speeds and reduced computational demands.
Extracting Information from Twitter Screenshots
Jun 14, 2023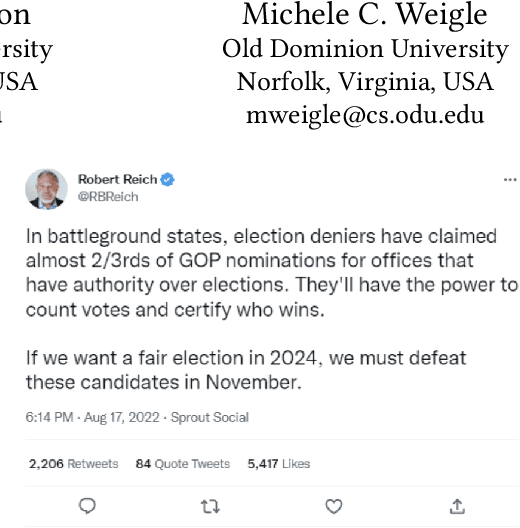

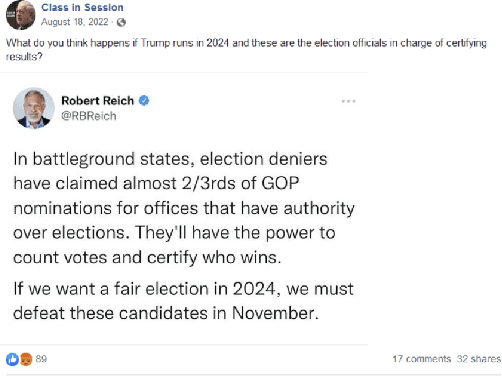

Screenshots are prevalent on social media as a common approach for information sharing. Users rarely verify before sharing a screenshot whether the post it contains is fake or real. Information sharing through fake screenshots can be highly responsible for misinformation and disinformation spread on social media. Our ultimate goal is to develop a tool that could take a screenshot of a tweet and provide a probability that the tweet is real, using resources found on the live web and in web archives. This paper provides methods for extracting the tweet text, timestamp, and Twitter handle from a screenshot of a tweet.