 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Continual Driving Policy Optimization with Closed-Loop Individualized Curricula
Sep 25, 2023
The safety of autonomous vehicles (AV) has been a long-standing top concern, stemming from the absence of rare and safety-critical scenarios in the long-tail naturalistic driving distribution. To tackle this challenge, a surge of research in scenario-based autonomous driving has emerged, with a focus on generating high-risk driving scenarios and applying them to conduct safety-critical testing of AV models. However, limited work has been explored on the reuse of these extensive scenarios to iteratively improve AV models. Moreover, it remains intractable and challenging to filter through gigantic scenario libraries collected from other AV models with distinct behaviors, attempting to extract transferable information for current AV improvement. Therefore, we develop a continual driving policy optimization framework featuring Closed-Loop Individualized Curricula (CLIC), which we factorize into a set of standardized sub-modules for flexible implementation choices: AV Evaluation, Scenario Selection, and AV Training. CLIC frames AV Evaluation as a collision prediction task, where it estimates the chance of AV failures in these scenarios at each iteration. Subsequently, by re-sampling from historical scenarios based on these failure probabilities, CLIC tailors individualized curricula for downstream training, aligning them with the evaluated capability of AV. Accordingly, CLIC not only maximizes the utilization of the vast pre-collected scenario library for closed-loop driving policy optimization but also facilitates AV improvement by individualizing its training with more challenging cases out of those poorly organized scenarios. Experimental results clearly indicate that CLIC surpasses other curriculum-based training strategies, showing substantial improvement in managing risky scenarios, while still maintaining proficiency in handling simpler cases.
Adapt then Unlearn: Exploiting Parameter Space Semantics for Unlearning in Generative Adversarial Networks
Sep 25, 2023The increased attention to regulating the outputs of deep generative models, driven by growing concerns about privacy and regulatory compliance, has highlighted the need for effective control over these models. This necessity arises from instances where generative models produce outputs containing undesirable, offensive, or potentially harmful content. To tackle this challenge, the concept of machine unlearning has emerged, aiming to forget specific learned information or to erase the influence of undesired data subsets from a trained model. The objective of this work is to prevent the generation of outputs containing undesired features from a pre-trained GAN where the underlying training data set is inaccessible. Our approach is inspired by a crucial observation: the parameter space of GANs exhibits meaningful directions that can be leveraged to suppress specific undesired features. However, such directions usually result in the degradation of the quality of generated samples. Our proposed method, known as 'Adapt-then-Unlearn,' excels at unlearning such undesirable features while also maintaining the quality of generated samples. This method unfolds in two stages: in the initial stage, we adapt the pre-trained GAN using negative samples provided by the user, while in the subsequent stage, we focus on unlearning the undesired feature. During the latter phase, we train the pre-trained GAN using positive samples, incorporating a repulsion regularizer. This regularizer encourages the model's parameters to be away from the parameters associated with the adapted model from the first stage while also maintaining the quality of generated samples. To the best of our knowledge, our approach stands as first method addressing unlearning in GANs. We validate the effectiveness of our method through comprehensive experiments.
FLDNet: A Foreground-Aware Network for Polyp Segmentation Leveraging Long-Distance Dependencies
Sep 12, 2023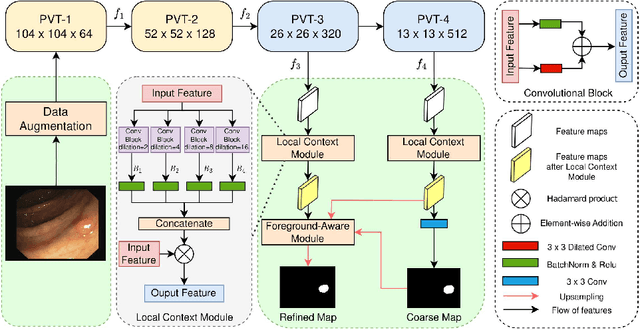
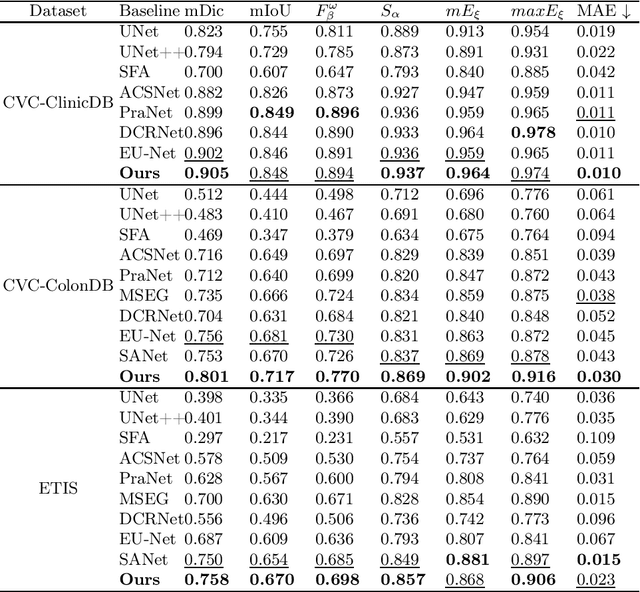
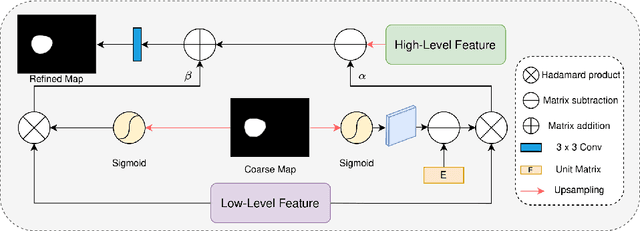
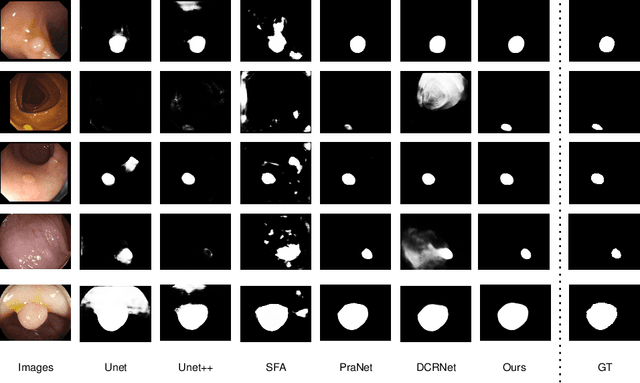
Given the close association between colorectal cancer and polyps, the diagnosis and identification of colorectal polyps play a critical role in the detection and surgical intervention of colorectal cancer. In this context, the automatic detection and segmentation of polyps from various colonoscopy images has emerged as a significant problem that has attracted broad attention. Current polyp segmentation techniques face several challenges: firstly, polyps vary in size, texture, color, and pattern; secondly, the boundaries between polyps and mucosa are usually blurred, existing studies have focused on learning the local features of polyps while ignoring the long-range dependencies of the features, and also ignoring the local context and global contextual information of the combined features. To address these challenges, we propose FLDNet (Foreground-Long-Distance Network), a Transformer-based neural network that captures long-distance dependencies for accurate polyp segmentation. Specifically, the proposed model consists of three main modules: a pyramid-based Transformer encoder, a local context module, and a foreground-Aware module. Multilevel features with long-distance dependency information are first captured by the pyramid-based transformer encoder. On the high-level features, the local context module obtains the local characteristics related to the polyps by constructing different local context information. The coarse map obtained by decoding the reconstructed highest-level features guides the feature fusion process in the foreground-Aware module of the high-level features to achieve foreground enhancement of the polyps. Our proposed method, FLDNet, was evaluated using seven metrics on common datasets and demonstrated superiority over state-of-the-art methods on widely-used evaluation measures.
SG-Bot: Object Rearrangement via Coarse-to-Fine Robotic Imagination on Scene Graphs
Sep 21, 2023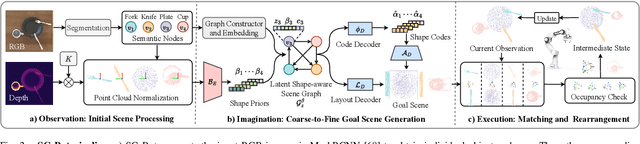
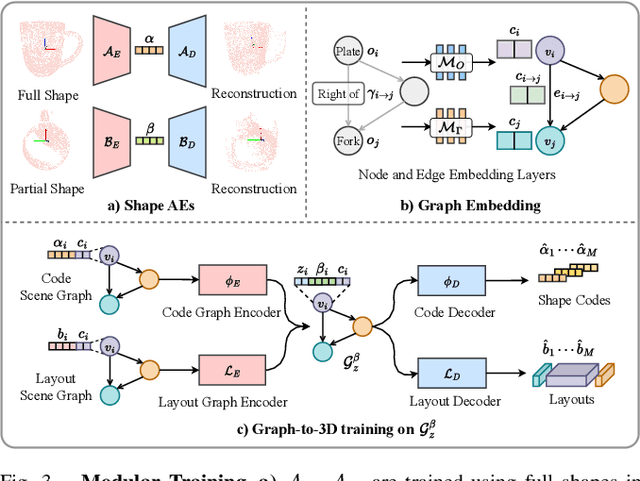
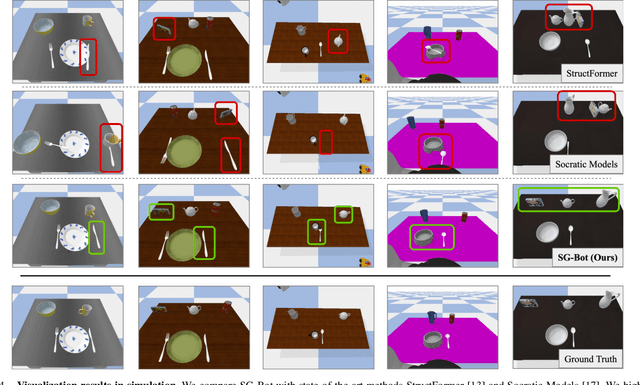

Object rearrangement is pivotal in robotic-environment interactions, representing a significant capability in embodied AI. In this paper, we present SG-Bot, a novel rearrangement framework that utilizes a coarse-to-fine scheme with a scene graph as the scene representation. Unlike previous methods that rely on either known goal priors or zero-shot large models, SG-Bot exemplifies lightweight, real-time, and user-controllable characteristics, seamlessly blending the consideration of commonsense knowledge with automatic generation capabilities. SG-Bot employs a three-fold procedure--observation, imagination, and execution--to adeptly address the task. Initially, objects are discerned and extracted from a cluttered scene during the observation. These objects are first coarsely organized and depicted within a scene graph, guided by either commonsense or user-defined criteria. Then, this scene graph subsequently informs a generative model, which forms a fine-grained goal scene considering the shape information from the initial scene and object semantics. Finally, for execution, the initial and envisioned goal scenes are matched to formulate robotic action policies. Experimental results demonstrate that SG-Bot outperforms competitors by a large margin.
Elevating Skeleton-Based Action Recognition with Efficient Multi-Modality Self-Supervision
Sep 21, 2023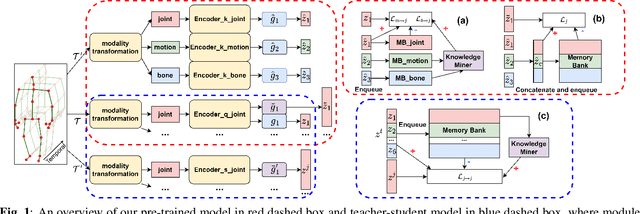
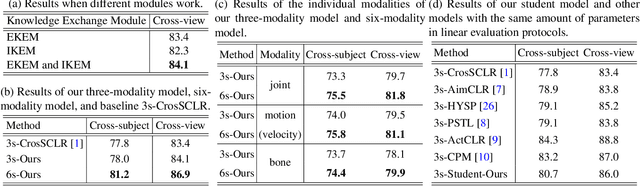
Self-supervised representation learning for human action recognition has developed rapidly in recent years. Most of the existing works are based on skeleton data while using a multi-modality setup. These works overlooked the differences in performance among modalities, which led to the propagation of erroneous knowledge between modalities while only three fundamental modalities, i.e., joints, bones, and motions are used, hence no additional modalities are explored. In this work, we first propose an Implicit Knowledge Exchange Module (IKEM) which alleviates the propagation of erroneous knowledge between low-performance modalities. Then, we further propose three new modalities to enrich the complementary information between modalities. Finally, to maintain efficiency when introducing new modalities, we propose a novel teacher-student framework to distill the knowledge from the secondary modalities into the mandatory modalities considering the relationship constrained by anchors, positives, and negatives, named relational cross-modality knowledge distillation. The experimental results demonstrate the effectiveness of our approach, unlocking the efficient use of skeleton-based multi-modality data. Source code will be made publicly available at https://github.com/desehuileng0o0/IKEM.
Convolution and Attention Mixer for Synthetic Aperture Radar Image Change Detection
Sep 21, 2023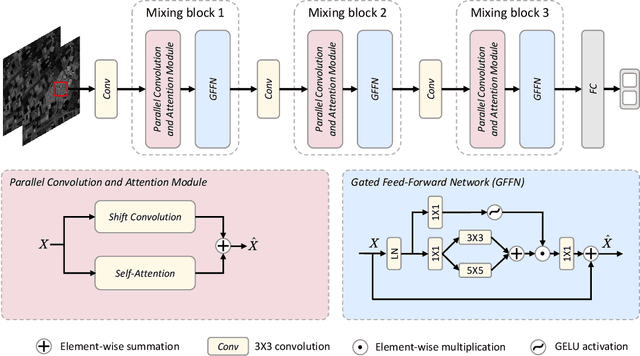
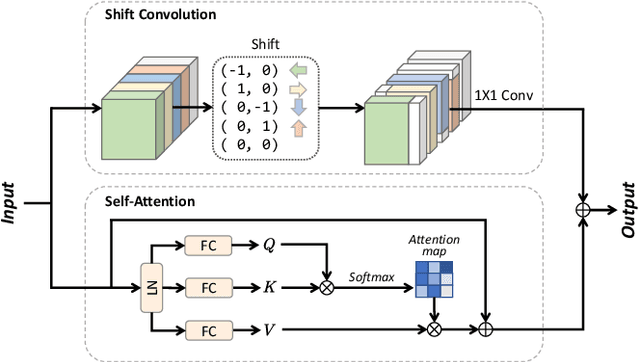
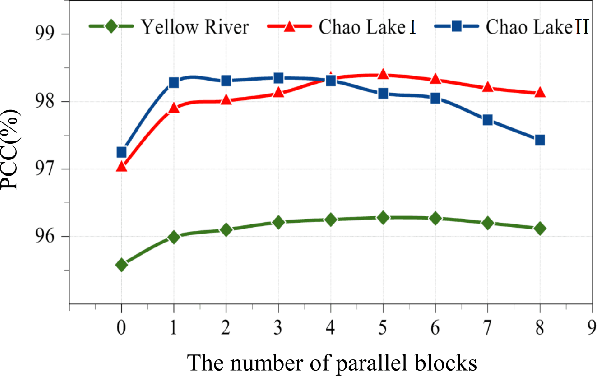
Synthetic aperture radar (SAR) image change detection is a critical task and has received increasing attentions in the remote sensing community. However, existing SAR change detection methods are mainly based on convolutional neural networks (CNNs), with limited consideration of global attention mechanism. In this letter, we explore Transformer-like architecture for SAR change detection to incorporate global attention. To this end, we propose a convolution and attention mixer (CAMixer). First, to compensate the inductive bias for Transformer, we combine self-attention with shift convolution in a parallel way. The parallel design effectively captures the global semantic information via the self-attention and performs local feature extraction through shift convolution simultaneously. Second, we adopt a gating mechanism in the feed-forward network to enhance the non-linear feature transformation. The gating mechanism is formulated as the element-wise multiplication of two parallel linear layers. Important features can be highlighted, leading to high-quality representations against speckle noise. Extensive experiments conducted on three SAR datasets verify the superior performance of the proposed CAMixer. The source codes will be publicly available at https://github.com/summitgao/CAMixer .
Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer -- Current Trends and Research Perspectives
Sep 21, 2023Action scene understanding in soccer is a challenging task due to the complex and dynamic nature of the game, as well as the interactions between players. This article provides a comprehensive overview of this task divided into action recognition, spotting, and spatio-temporal action localization, with a particular emphasis on the modalities used and multimodal methods. We explore the publicly available data sources and metrics used to evaluate models' performance. The article reviews recent state-of-the-art methods that leverage deep learning techniques and traditional methods. We focus on multimodal methods, which integrate information from multiple sources, such as video and audio data, and also those that represent one source in various ways. The advantages and limitations of methods are discussed, along with their potential for improving the accuracy and robustness of models. Finally, the article highlights some of the open research questions and future directions in the field of soccer action recognition, including the potential for multimodal methods to advance this field. Overall, this survey provides a valuable resource for researchers interested in the field of action scene understanding in soccer.
SPICED: News Similarity Detection Dataset with Multiple Topics and Complexity Levels
Sep 21, 2023Nowadays, the use of intelligent systems to detect redundant information in news articles has become especially prevalent with the proliferation of news media outlets in order to enhance user experience. However, the heterogeneous nature of news can lead to spurious findings in these systems: Simple heuristics such as whether a pair of news are both about politics can provide strong but deceptive downstream performance. Segmenting news similarity datasets into topics improves the training of these models by forcing them to learn how to distinguish salient characteristics under more narrow domains. However, this requires the existence of topic-specific datasets, which are currently lacking. In this article, we propose a new dataset of similar news, SPICED, which includes seven topics: Crime & Law, Culture & Entertainment, Disasters & Accidents, Economy & Business, Politics & Conflicts, Science & Technology, and Sports. Futhermore, we present four distinct approaches for generating news pairs, which are used in the creation of datasets specifically designed for news similarity detection task. We benchmarked the created datasets using MinHash, BERT, SBERT, and SimCSE models.
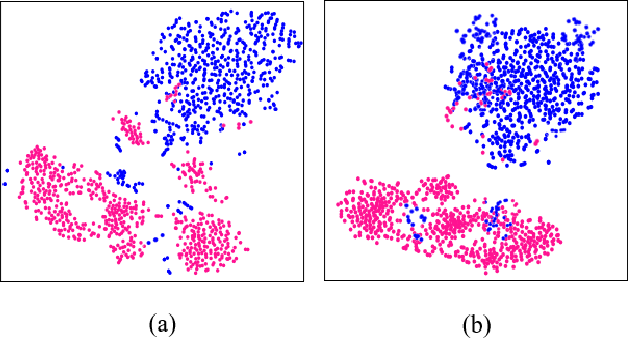
Leveraging SE(3) Equivariance for Learning 3D Geometric Shape Assembly
Sep 13, 2023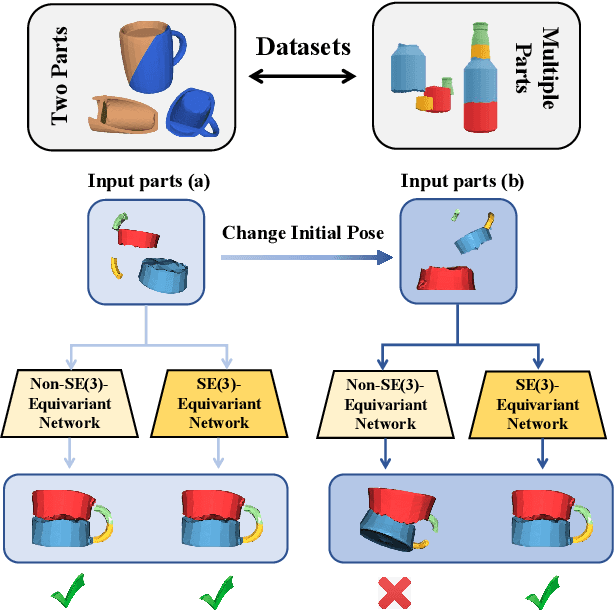
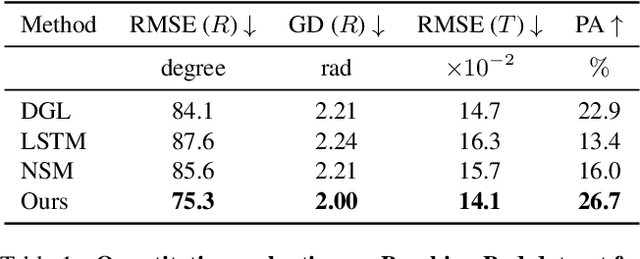
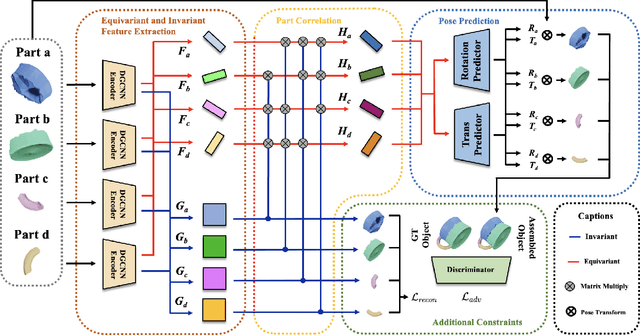
Shape assembly aims to reassemble parts (or fragments) into a complete object, which is a common task in our daily life. Different from the semantic part assembly (e.g., assembling a chair's semantic parts like legs into a whole chair), geometric part assembly (e.g., assembling bowl fragments into a complete bowl) is an emerging task in computer vision and robotics. Instead of semantic information, this task focuses on geometric information of parts. As the both geometric and pose space of fractured parts are exceptionally large, shape pose disentanglement of part representations is beneficial to geometric shape assembly. In our paper, we propose to leverage SE(3) equivariance for such shape pose disentanglement. Moreover, while previous works in vision and robotics only consider SE(3) equivariance for the representations of single objects, we move a step forward and propose leveraging SE(3) equivariance for representations considering multi-part correlations, which further boosts the performance of the multi-part assembly. Experiments demonstrate the significance of SE(3) equivariance and our proposed method for geometric shape assembly. Project page: https://crtie.github.io/SE-3-part-assembly/
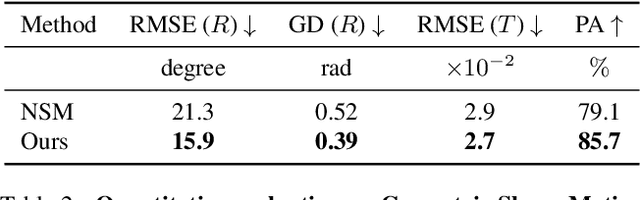
Geometric Pooling: maintaining more useful information
Jun 21, 2023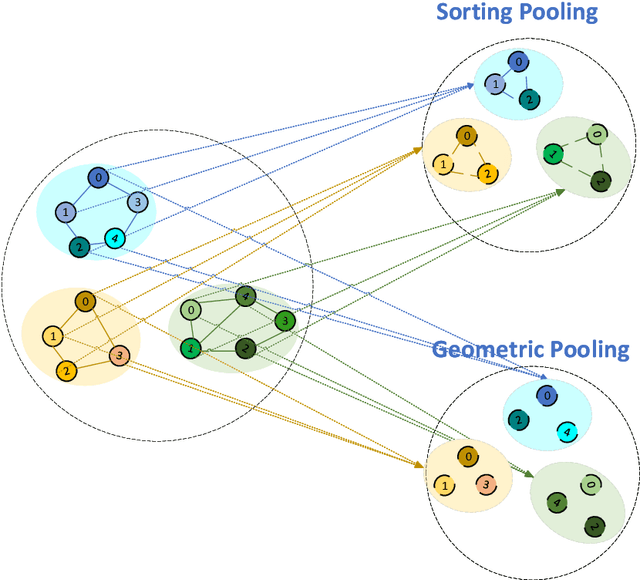
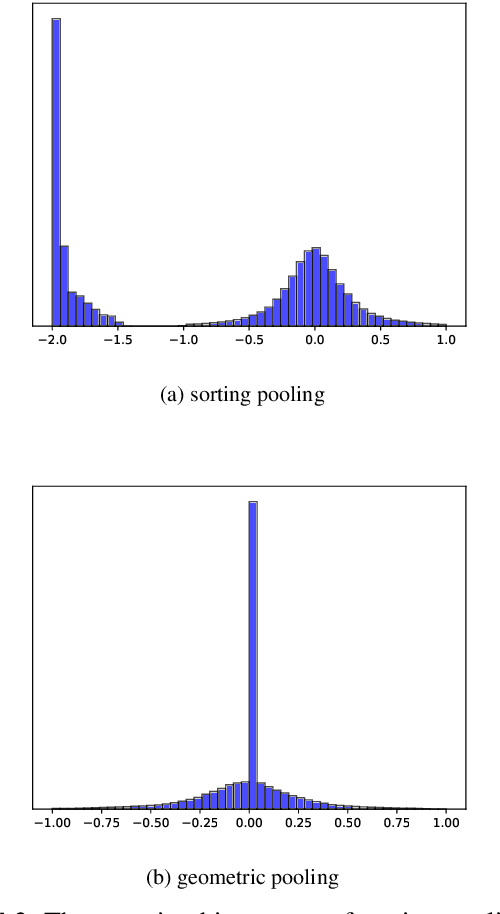
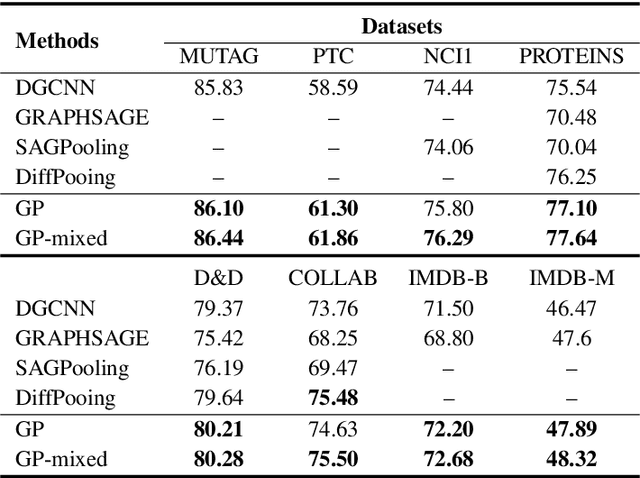
Graph Pooling technology plays an important role in graph node classification tasks. Sorting pooling technologies maintain large-value units for pooling graphs of varying sizes. However, by analyzing the statistical characteristic of activated units after pooling, we found that a large number of units dropped by sorting pooling are negative-value units that contain useful information and can contribute considerably to the final decision. To maintain more useful information, a novel pooling technology, called Geometric Pooling (GP), was proposed to contain the unique node features with negative values by measuring the similarity of all node features. We reveal the effectiveness of GP from the entropy reduction view. The experiments were conducted on TUdatasets to show the effectiveness of GP. The results showed that the proposed GP outperforms the SOTA graph pooling technologies by 1%\sim5% with fewer parameters.