 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CINFormer: Transformer network with multi-stage CNN feature injection for surface defect segmentation
Sep 22, 2023
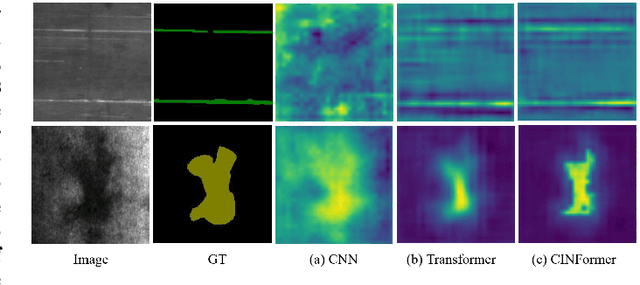
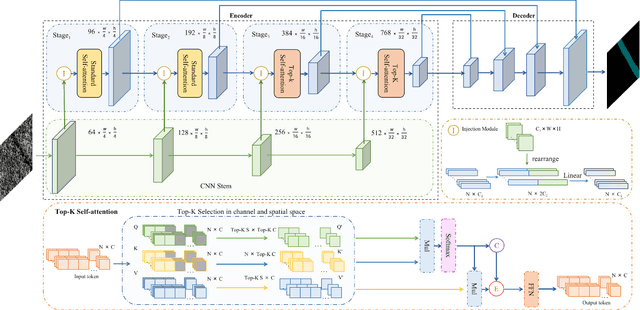

Surface defect inspection is of great importance for industrial manufacture and production. Though defect inspection methods based on deep learning have made significant progress, there are still some challenges for these methods, such as indistinguishable weak defects and defect-like interference in the background. To address these issues, we propose a transformer network with multi-stage CNN (Convolutional Neural Network) feature injection for surface defect segmentation, which is a UNet-like structure named CINFormer. CINFormer presents a simple yet effective feature integration mechanism that injects the multi-level CNN features of the input image into different stages of the transformer network in the encoder. This can maintain the merit of CNN capturing detailed features and that of transformer depressing noises in the background, which facilitates accurate defect detection. In addition, CINFormer presents a Top-K self-attention module to focus on tokens with more important information about the defects, so as to further reduce the impact of the redundant background. Extensive experiments conducted on the surface defect datasets DAGM 2007, Magnetic tile, and NEU show that the proposed CINFormer achieves state-of-the-art performance in defect detection.
Enhancing Graph Representation of the Environment through Local and Cloud Computation
Sep 22, 2023Enriching the robot representation of the operational environment is a challenging task that aims at bridging the gap between low-level sensor readings and high-level semantic understanding. Having a rich representation often requires computationally demanding architectures and pure point cloud based detection systems that struggle when dealing with everyday objects that have to be handled by the robot. To overcome these issues, we propose a graph-based representation that addresses this gap by providing a semantic representation of robot environments from multiple sources. In fact, to acquire information from the environment, the framework combines classical computer vision tools with modern computer vision cloud services, ensuring computational feasibility on onboard hardware. By incorporating an ontology hierarchy with over 800 object classes, the framework achieves cross-domain adaptability, eliminating the need for environment-specific tools. The proposed approach allows us to handle also small objects and integrate them into the semantic representation of the environment. The approach is implemented in the Robot Operating System (ROS) using the RViz visualizer for environment representation. This work is a first step towards the development of a general-purpose framework, to facilitate intuitive interaction and navigation across different domains.
Unlocking Model Insights: A Dataset for Automated Model Card Generation
Sep 22, 2023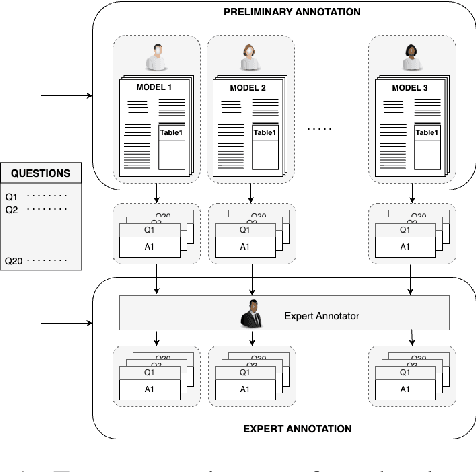


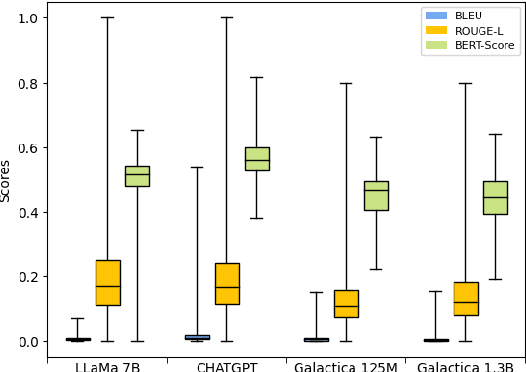
Language models (LMs) are no longer restricted to ML community, and instruction-tuned LMs have led to a rise in autonomous AI agents. As the accessibility of LMs grows, it is imperative that an understanding of their capabilities, intended usage, and development cycle also improves. Model cards are a popular practice for documenting detailed information about an ML model. To automate model card generation, we introduce a dataset of 500 question-answer pairs for 25 ML models that cover crucial aspects of the model, such as its training configurations, datasets, biases, architecture details, and training resources. We employ annotators to extract the answers from the original paper. Further, we explore the capabilities of LMs in generating model cards by answering questions. Our initial experiments with ChatGPT-3.5, LLaMa, and Galactica showcase a significant gap in the understanding of research papers by these aforementioned LMs as well as generating factual textual responses. We posit that our dataset can be used to train models to automate the generation of model cards from paper text and reduce human effort in the model card curation process. The complete dataset is available on https://osf.io/hqt7p/?view_only=3b9114e3904c4443bcd9f5c270158d37
Normalized mutual information is a biased measure for classification and community detection
Jul 03, 2023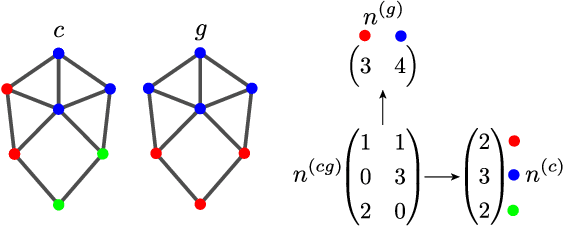
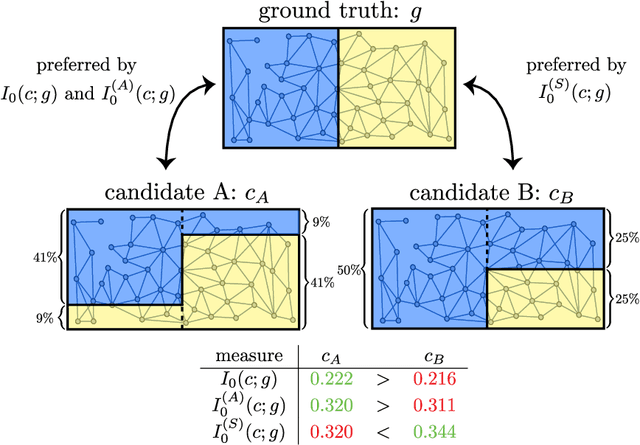
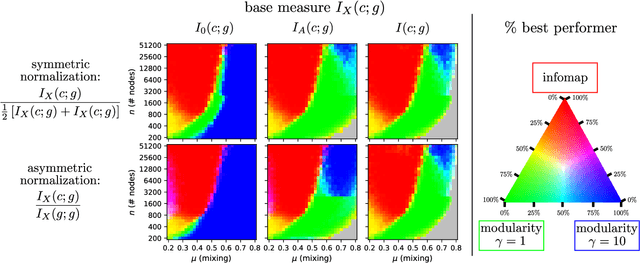
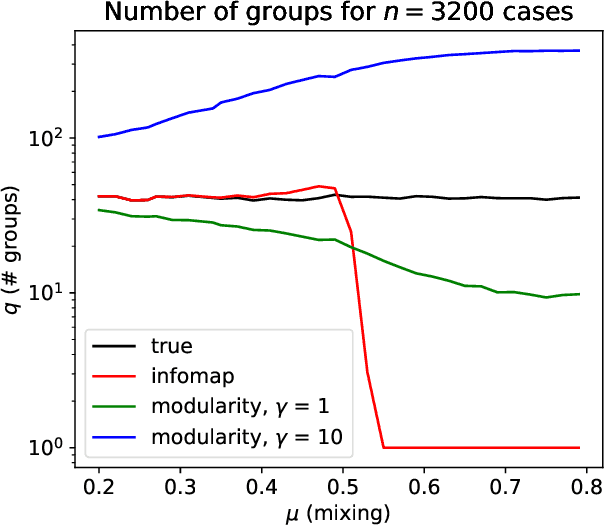
Normalized mutual information is widely used as a similarity measure for evaluating the performance of clustering and classification algorithms. In this paper, we show that results returned by the normalized mutual information are biased for two reasons: first, because they ignore the information content of the contingency table and, second, because their symmetric normalization introduces spurious dependence on algorithm output. We introduce a modified version of the mutual information that remedies both of these shortcomings. As a practical demonstration of the importance of using an unbiased measure, we perform extensive numerical tests on a basket of popular algorithms for network community detection and show that one's conclusions about which algorithm is best are significantly affected by the biases in the traditional mutual information.
When Automated Assessment Meets Automated Content Generation: Examining Text Quality in the Era of GPTs
Sep 25, 2023
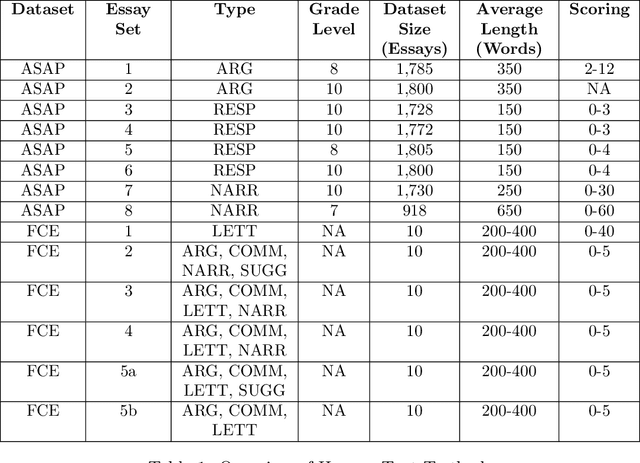
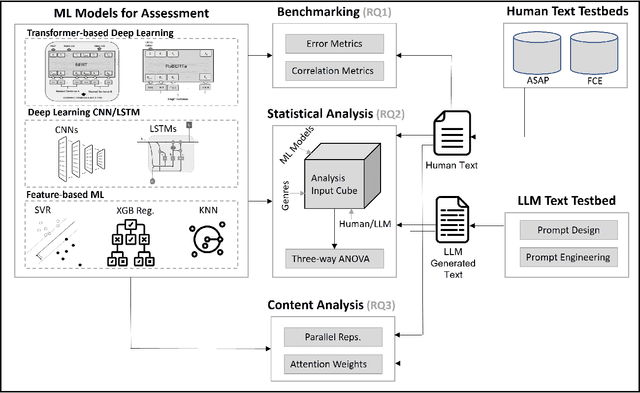
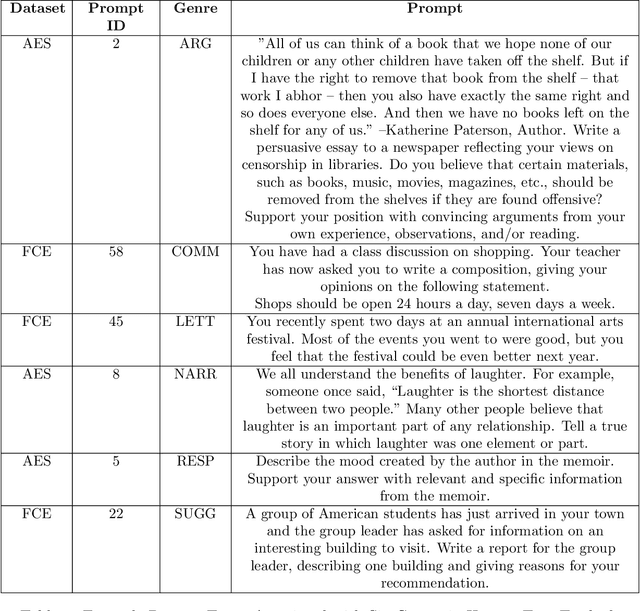
The use of machine learning (ML) models to assess and score textual data has become increasingly pervasive in an array of contexts including natural language processing, information retrieval, search and recommendation, and credibility assessment of online content. A significant disruption at the intersection of ML and text are text-generating large-language models such as generative pre-trained transformers (GPTs). We empirically assess the differences in how ML-based scoring models trained on human content assess the quality of content generated by humans versus GPTs. To do so, we propose an analysis framework that encompasses essay scoring ML-models, human and ML-generated essays, and a statistical model that parsimoniously considers the impact of type of respondent, prompt genre, and the ML model used for assessment model. A rich testbed is utilized that encompasses 18,460 human-generated and GPT-based essays. Results of our benchmark analysis reveal that transformer pretrained language models (PLMs) more accurately score human essay quality as compared to CNN/RNN and feature-based ML methods. Interestingly, we find that the transformer PLMs tend to score GPT-generated text 10-15\% higher on average, relative to human-authored documents. Conversely, traditional deep learning and feature-based ML models score human text considerably higher. Further analysis reveals that although the transformer PLMs are exclusively fine-tuned on human text, they more prominently attend to certain tokens appearing only in GPT-generated text, possibly due to familiarity/overlap in pre-training. Our framework and results have implications for text classification settings where automated scoring of text is likely to be disrupted by generative AI.
A Weighted Prognostic Covariate Adjustment Method for Efficient and Powerful Treatment Effect Inferences in Randomized Controlled Trials
Sep 25, 2023A crucial task for a randomized controlled trial (RCT) is to specify a statistical method that can yield an efficient estimator and powerful test for the treatment effect. A novel and effective strategy to obtain efficient and powerful treatment effect inferences is to incorporate predictions from generative artificial intelligence (AI) algorithms into covariate adjustment for the regression analysis of a RCT. Training a generative AI algorithm on historical control data enables one to construct a digital twin generator (DTG) for RCT participants, which utilizes a participant's baseline covariates to generate a probability distribution for their potential control outcome. Summaries of the probability distribution from the DTG are highly predictive of the trial outcome, and adjusting for these features via regression can thus improve the quality of treatment effect inferences, while satisfying regulatory guidelines on statistical analyses, for a RCT. However, a critical assumption in this strategy is homoskedasticity, or constant variance of the outcome conditional on the covariates. In the case of heteroskedasticity, existing covariate adjustment methods yield inefficient estimators and underpowered tests. We propose to address heteroskedasticity via a weighted prognostic covariate adjustment methodology (Weighted PROCOVA) that adjusts for both the mean and variance of the regression model using information obtained from the DTG. We prove that our method yields unbiased treatment effect estimators, and demonstrate via comprehensive simulation studies and case studies from Alzheimer's disease that it can reduce the variance of the treatment effect estimator, maintain the Type I error rate, and increase the power of the test for the treatment effect from 80% to 85%~90% when the variances from the DTG can explain 5%~10% of the variation in the RCT participants' outcomes.
Continual Driving Policy Optimization with Closed-Loop Individualized Curricula
Sep 25, 2023The safety of autonomous vehicles (AV) has been a long-standing top concern, stemming from the absence of rare and safety-critical scenarios in the long-tail naturalistic driving distribution. To tackle this challenge, a surge of research in scenario-based autonomous driving has emerged, with a focus on generating high-risk driving scenarios and applying them to conduct safety-critical testing of AV models. However, limited work has been explored on the reuse of these extensive scenarios to iteratively improve AV models. Moreover, it remains intractable and challenging to filter through gigantic scenario libraries collected from other AV models with distinct behaviors, attempting to extract transferable information for current AV improvement. Therefore, we develop a continual driving policy optimization framework featuring Closed-Loop Individualized Curricula (CLIC), which we factorize into a set of standardized sub-modules for flexible implementation choices: AV Evaluation, Scenario Selection, and AV Training. CLIC frames AV Evaluation as a collision prediction task, where it estimates the chance of AV failures in these scenarios at each iteration. Subsequently, by re-sampling from historical scenarios based on these failure probabilities, CLIC tailors individualized curricula for downstream training, aligning them with the evaluated capability of AV. Accordingly, CLIC not only maximizes the utilization of the vast pre-collected scenario library for closed-loop driving policy optimization but also facilitates AV improvement by individualizing its training with more challenging cases out of those poorly organized scenarios. Experimental results clearly indicate that CLIC surpasses other curriculum-based training strategies, showing substantial improvement in managing risky scenarios, while still maintaining proficiency in handling simpler cases.
Adapt then Unlearn: Exploiting Parameter Space Semantics for Unlearning in Generative Adversarial Networks
Sep 25, 2023The increased attention to regulating the outputs of deep generative models, driven by growing concerns about privacy and regulatory compliance, has highlighted the need for effective control over these models. This necessity arises from instances where generative models produce outputs containing undesirable, offensive, or potentially harmful content. To tackle this challenge, the concept of machine unlearning has emerged, aiming to forget specific learned information or to erase the influence of undesired data subsets from a trained model. The objective of this work is to prevent the generation of outputs containing undesired features from a pre-trained GAN where the underlying training data set is inaccessible. Our approach is inspired by a crucial observation: the parameter space of GANs exhibits meaningful directions that can be leveraged to suppress specific undesired features. However, such directions usually result in the degradation of the quality of generated samples. Our proposed method, known as 'Adapt-then-Unlearn,' excels at unlearning such undesirable features while also maintaining the quality of generated samples. This method unfolds in two stages: in the initial stage, we adapt the pre-trained GAN using negative samples provided by the user, while in the subsequent stage, we focus on unlearning the undesired feature. During the latter phase, we train the pre-trained GAN using positive samples, incorporating a repulsion regularizer. This regularizer encourages the model's parameters to be away from the parameters associated with the adapted model from the first stage while also maintaining the quality of generated samples. To the best of our knowledge, our approach stands as first method addressing unlearning in GANs. We validate the effectiveness of our method through comprehensive experiments.
Oracle Complexity Reduction for Model-free LQR: A Stochastic Variance-Reduced Policy Gradient Approach
Sep 19, 2023We investigate the problem of learning an $\epsilon$-approximate solution for the discrete-time Linear Quadratic Regulator (LQR) problem via a Stochastic Variance-Reduced Policy Gradient (SVRPG) approach. Whilst policy gradient methods have proven to converge linearly to the optimal solution of the model-free LQR problem, the substantial requirement for two-point cost queries in gradient estimations may be intractable, particularly in applications where obtaining cost function evaluations at two distinct control input configurations is exceptionally costly. To this end, we propose an oracle-efficient approach. Our method combines both one-point and two-point estimations in a dual-loop variance-reduced algorithm. It achieves an approximate optimal solution with only $O\left(\log\left(1/\epsilon\right)^{\beta}\right)$ two-point cost information for $\beta \in (0,1)$.
Hierarchical Annotated Skeleton-Guided Tree-based Motion Planning
Sep 19, 2023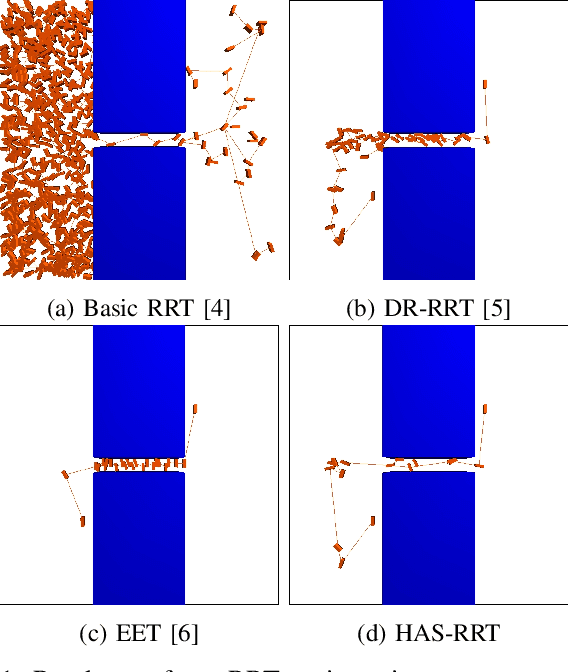
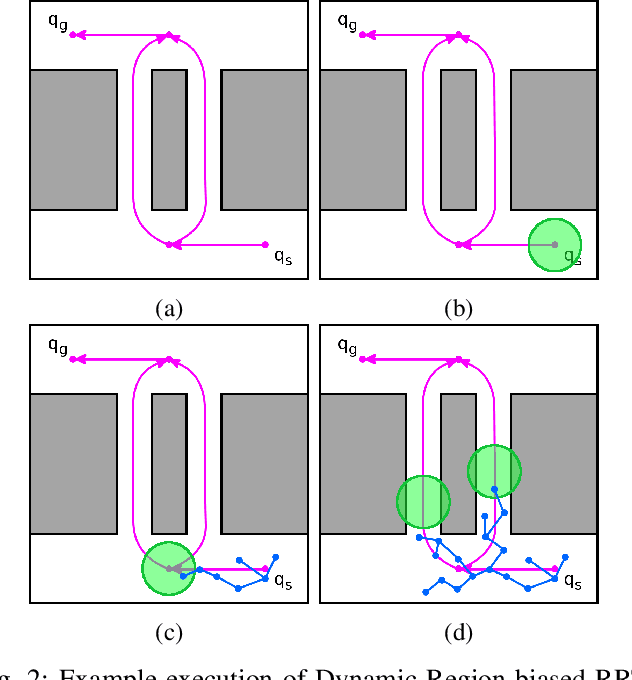
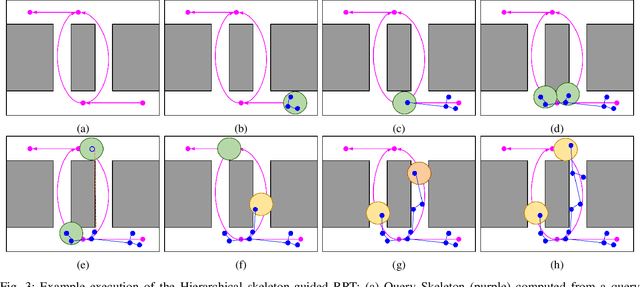
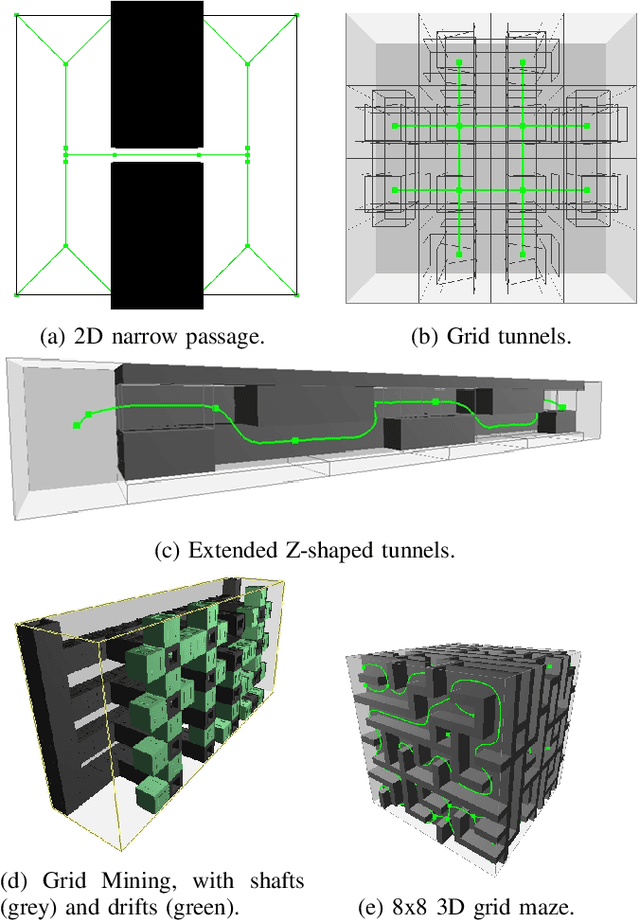
We present a hierarchical tree-based motion planning strategy, HAS-RRT, guided by the workspace skeleton to solve motion planning problems in robotics and computational biology. Relying on the information about the connectivity of the workspace and the ranking of available paths in the workspace, the strategy prioritizes paths indicated by the workspace guidance to find a valid motion plan for the moving object efficiently. In instances of suboptimal guidance, the strategy adapts its reliance on the guidance by hierarchically reverting to local exploration of the planning space. We offer an extensive comparative analysis against other tree-based planning strategies and demonstrate that HAS-RRT reliably and efficiently finds low-cost paths. In contrast to methods prone to inconsistent performance across different environments or reliance on specific parameters, HAS-RRT is robust to workspace variability.