 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Indoor Exploration and Simultaneous Trolley Collection Through Task-Oriented Environment Partitioning
Sep 20, 2023
In this paper, we present a simultaneous exploration and object search framework for the application of autonomous trolley collection. For environment representation, a task-oriented environment partitioning algorithm is presented to extract diverse information for each sub-task. First, LiDAR data is classified as potential objects, walls, and obstacles after outlier removal. Segmented point clouds are then transformed into a hybrid map with the following functional components: object proposals to avoid missing trolleys during exploration; room layouts for semantic space segmentation; and polygonal obstacles containing geometry information for efficient motion planning. For exploration and simultaneous trolley collection, we propose an efficient exploration-based object search method. First, a traveling salesman problem with precedence constraints (TSP-PC) is formulated by grouping frontiers and object proposals. The next target is selected by prioritizing object search while avoiding excessive robot backtracking. Then, feasible trajectories with adequate obstacle clearance are generated by topological graph search. We validate the proposed framework through simulations and demonstrate the system with real-world autonomous trolley collection tasks.
Leveraging Negative Signals with Self-Attention for Sequential Music Recommendation
Sep 20, 2023
Music streaming services heavily rely on their recommendation engines to continuously provide content to their consumers. Sequential recommendation consequently has seen considerable attention in current literature, where state of the art approaches focus on self-attentive models leveraging contextual information such as long and short-term user history and item features; however, most of these studies focus on long-form content domains (retail, movie, etc.) rather than short-form, such as music. Additionally, many do not explore incorporating negative session-level feedback during training. In this study, we investigate the use of transformer-based self-attentive architectures to learn implicit session-level information for sequential music recommendation. We additionally propose a contrastive learning task to incorporate negative feedback (e.g skipped tracks) to promote positive hits and penalize negative hits. This task is formulated as a simple loss term that can be incorporated into a variety of deep learning architectures for sequential recommendation. Our experiments show that this results in consistent performance gains over the baseline architectures ignoring negative user feedback.
A Competition-based Pricing Strategy in Cloud Markets using Regret Minimization Techniques
Sep 20, 2023Cloud computing as a fairly new commercial paradigm, widely investigated by different researchers, already has a great range of challenges. Pricing is a major problem in Cloud computing marketplace; as providers are competing to attract more customers without knowing the pricing policies of each other. To overcome this lack of knowledge, we model their competition by an incomplete-information game. Considering the issue, this work proposes a pricing policy related to the regret minimization algorithm and applies it to the considered incomplete-information game. Based on the competition based marketplace of the Cloud, providers update the distribution of their strategies using the experienced regret. The idea of iteratively applying the algorithm for updating probabilities of strategies causes the regret get minimized faster. The experimental results show much more increase in profits of the providers in comparison with other pricing policies. Besides, the efficiency of a variety of regret minimization techniques in a simulated marketplace of Cloud are discussed which have not been observed in the studied literature. Moreover, return on investment of providers in considered organizations is studied and promising results appeared.
Hierarchical Multi-Agent Reinforcement Learning for Air Combat Maneuvering
Sep 20, 2023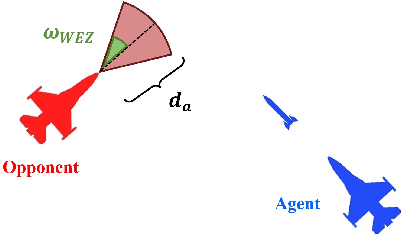
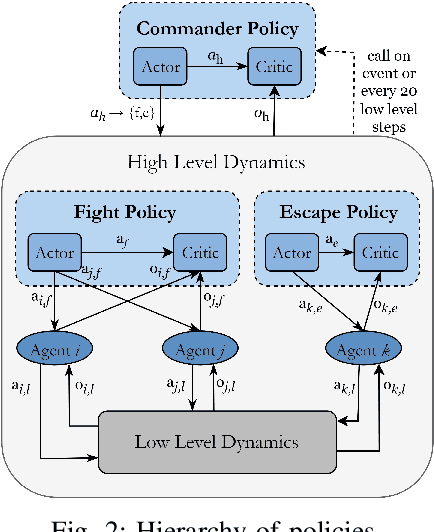
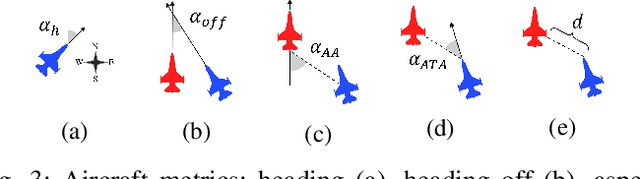
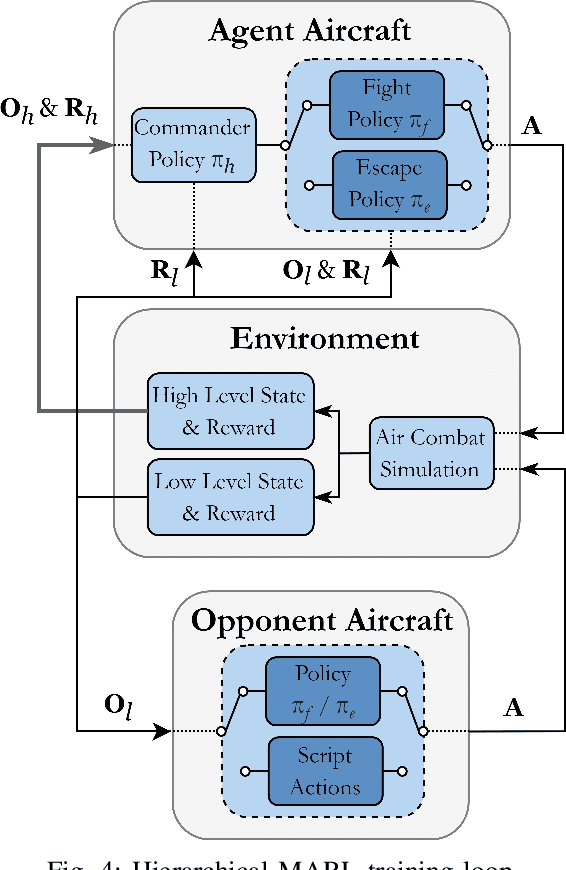
The application of artificial intelligence to simulate air-to-air combat scenarios is attracting increasing attention. To date the high-dimensional state and action spaces, the high complexity of situation information (such as imperfect and filtered information, stochasticity, incomplete knowledge about mission targets) and the nonlinear flight dynamics pose significant challenges for accurate air combat decision-making. These challenges are exacerbated when multiple heterogeneous agents are involved. We propose a hierarchical multi-agent reinforcement learning framework for air-to-air combat with multiple heterogeneous agents. In our framework, the decision-making process is divided into two stages of abstraction, where heterogeneous low-level policies control the action of individual units, and a high-level commander policy issues macro commands given the overall mission targets. Low-level policies are trained for accurate unit combat control. Their training is organized in a learning curriculum with increasingly complex training scenarios and league-based self-play. The commander policy is trained on mission targets given pre-trained low-level policies. The empirical validation advocates the advantages of our design choices.
Telescope: An Automated Hybrid Forecasting Approach on a Level-Playing Field
Sep 26, 2023In many areas of decision-making, forecasting is an essential pillar. Consequently, many different forecasting methods have been proposed. From our experience, recently presented forecasting methods are computationally intensive, poorly automated, tailored to a particular data set, or they lack a predictable time-to-result. To this end, we introduce Telescope, a novel machine learning-based forecasting approach that automatically retrieves relevant information from a given time series and splits it into parts, handling each of them separately. In contrast to deep learning methods, our approach doesn't require parameterization or the need to train and fit a multitude of parameters. It operates with just one time series and provides forecasts within seconds without any additional setup. Our experiments show that Telescope outperforms recent methods by providing accurate and reliable forecasts while making no assumptions about the analyzed time series.
Face Cartoonisation For Various Poses Using StyleGAN
Sep 26, 2023This paper presents an innovative approach to achieve face cartoonisation while preserving the original identity and accommodating various poses. Unlike previous methods in this field that relied on conditional-GANs, which posed challenges related to dataset requirements and pose training, our approach leverages the expressive latent space of StyleGAN. We achieve this by introducing an encoder that captures both pose and identity information from images and generates a corresponding embedding within the StyleGAN latent space. By subsequently passing this embedding through a pre-trained generator, we obtain the desired cartoonised output. While many other approaches based on StyleGAN necessitate a dedicated and fine-tuned StyleGAN model, our method stands out by utilizing an already-trained StyleGAN designed to produce realistic facial images. We show by extensive experimentation how our encoder adapts the StyleGAN output to better preserve identity when the objective is cartoonisation.
Graph Neural Network Based Method for Path Planning Problem
Sep 26, 2023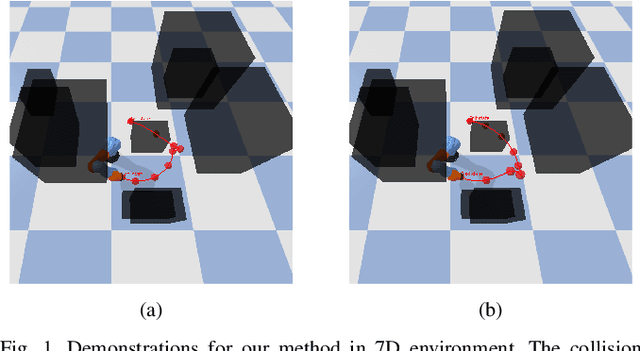
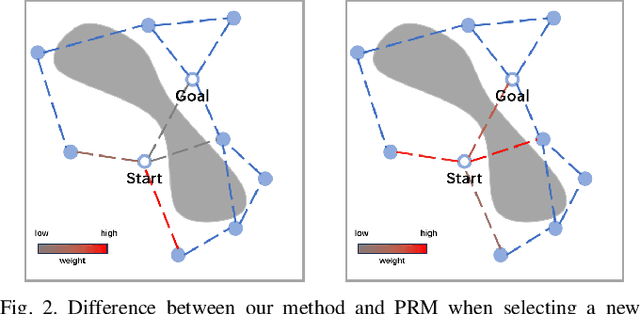
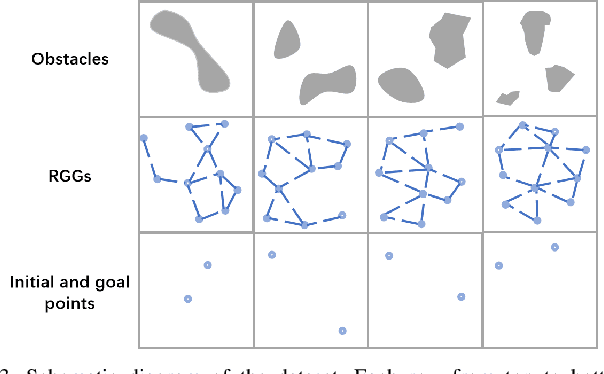
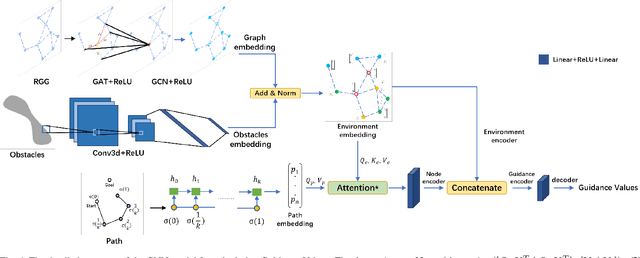
Sampling-based path planning is a widely used method in robotics, particularly in high-dimensional state space. Among the whole process of the path planning, collision detection is the most time-consuming operation. In this paper, we propose a learning-based path planning method that aims to reduce the number of collision detection. We develop an efficient neural network model based on Graph Neural Networks (GNN) and use the environment map as input. The model outputs weights for each neighbor based on the input and current vertex information, which are used to guide the planner in avoiding obstacles. We evaluate the proposed method's efficiency through simulated random worlds and real-world experiments, respectively. The results demonstrate that the proposed method significantly reduces the number of collision detection and improves the path planning speed in high-dimensional environments.
FishMOT: A Simple and Effective Method for Fish Tracking Based on IoU Matching
Sep 22, 2023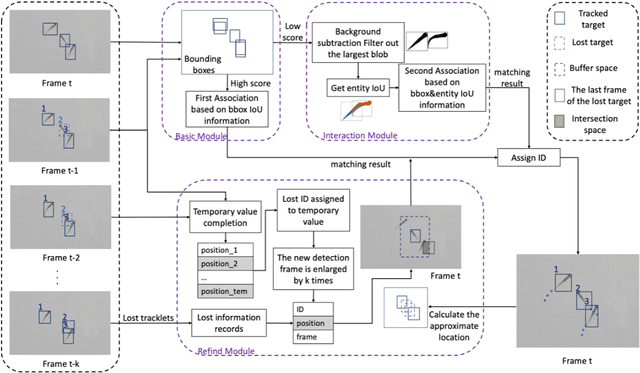

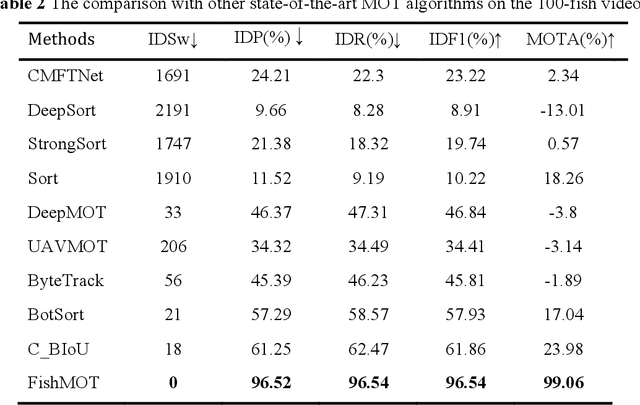
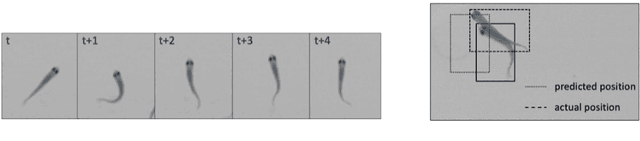
Fish tracking plays a vital role in understanding fish behavior and ecology. However, existing tracking methods face challenges in accuracy and robustness dues to morphological change of fish, occlusion and complex environment. This paper proposes FishMOT(Multiple Object Tracking for Fish), a novel fish tracking approach combining object detection and IoU matching, including basic module, interaction module and refind module. Wherein, a basic module performs target association based on IoU of detection boxes between successive frames to deal with morphological change of fish; an interaction module combines IoU of detection boxes and IoU of fish entity to handle occlusions; a refind module use spatio-temporal information uses spatio-temporal information to overcome the tracking failure resulting from the missed detection by the detector under complex environment. FishMOT reduces the computational complexity and memory consumption since it does not require complex feature extraction or identity assignment per fish, and does not need Kalman filter to predict the detection boxes of successive frame. Experimental results demonstrate FishMOT outperforms state-of-the-art multi-object trackers and specialized fish tracking tools in terms of MOTA, accuracy, computation time, memory consumption, etc.. Furthermore, the method exhibits excellent robustness and generalizability for varying environments and fish numbers. The simplified workflow and strong performance make FishMOT as a highly effective fish tracking approach. The source codes and pre-trained models are available at: https://github.com/gakkistar/FishMOT
Insights from an OTTR-centric Ontology Engineering Methodology
Sep 22, 2023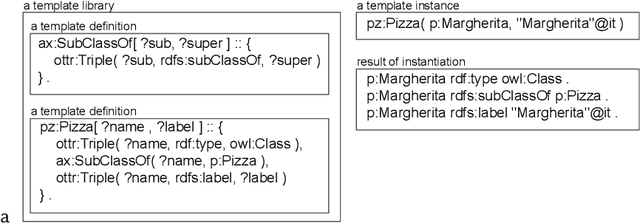
OTTR is a language for representing ontology modeling patterns, which enables to build ontologies or knowledge bases by instantiating templates. Thereby, particularities of the ontological representation language are hidden from the domain experts, and it enables ontology engineers to, to some extent, separate the processes of deciding about what information to model from deciding about how to model the information, e.g., which design patterns to use. Certain decisions can thus be postponed for the benefit of focusing on one of these processes. To date, only few works on ontology engineering where ontology templates are applied are described in the literature. In this paper, we outline our methodology and report findings from our ontology engineering activities in the domain of Material Science. In these activities, OTTR templates play a key role. Our ontology engineering process is bottom-up, as we begin modeling activities from existing data that is then, via templates, fed into a knowledge graph, and it is top-down, as we first focus on which data to model and postpone the decision of how to model the data. We find, among other things, that OTTR templates are especially useful as a means of communication with domain experts. Furthermore, we find that because OTTR templates encapsulate modeling decisions, the engineering process becomes flexible, meaning that design decisions can be changed at little cost.
A novel approach to measuring patent claim scope based on probabilities obtained from (large) language models
Sep 17, 2023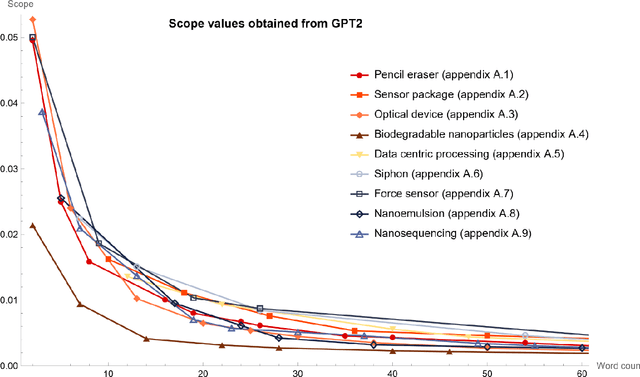
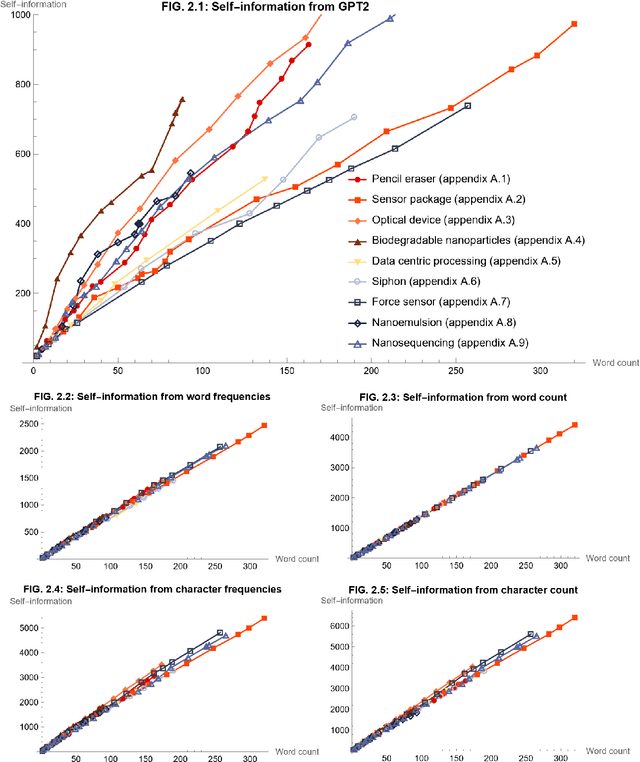
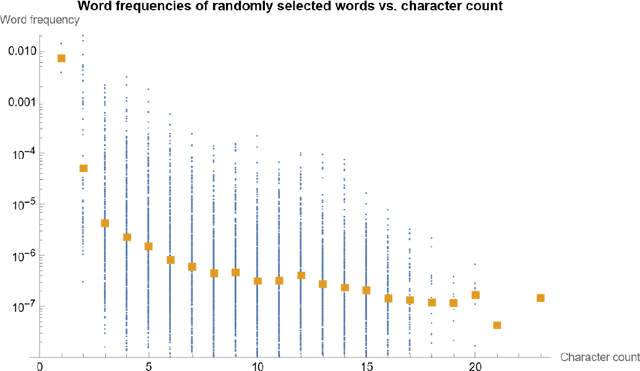
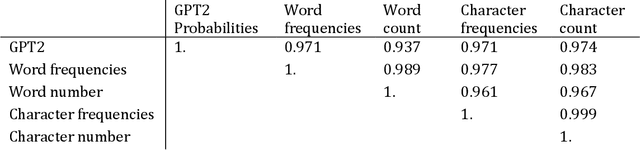
This work proposes to measure the scope of a patent claim as the reciprocal of the self-information contained in this claim. Grounded in information theory, this approach is based on the assumption that a rare concept is more informative than a usual concept, inasmuch as it is more surprising. The self-information is calculated from the probability of occurrence of that claim, where the probability is calculated in accordance with a language model. Five language models are considered, ranging from the simplest models (each word or character is drawn from a uniform distribution) to intermediate models (using average word or character frequencies), to a large language model (GPT2). Interestingly, the simplest language models reduce the scope measure to the reciprocal of the word or character count, a metric already used in previous works. Application is made to nine series of patent claims directed to distinct inventions, where the claims in each series have a gradually decreasing scope. The performance of the language models is then assessed with respect to several ad hoc tests. The more sophisticated the model, the better the results. The GPT2 model outperforms models based on word and character frequencies, which are themselves ahead of models based on word and character counts.