 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OntoChatGPT Information System: Ontology-Driven Structured Prompts for ChatGPT Meta-Learning
Jul 11, 2023

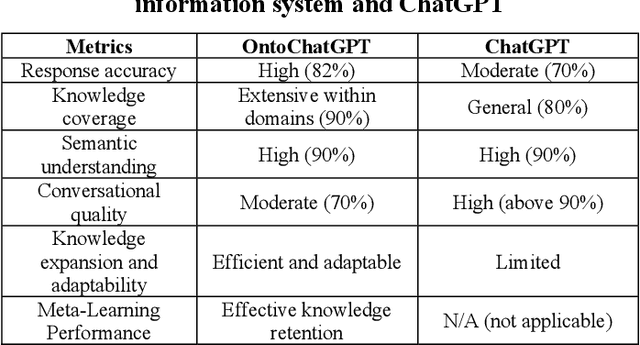
This research presents a comprehensive methodology for utilizing an ontology-driven structured prompts system in interplay with ChatGPT, a widely used large language model (LLM). The study develops formal models, both information and functional, and establishes the methodological foundations for integrating ontology-driven prompts with ChatGPT's meta-learning capabilities. The resulting productive triad comprises the methodological foundations, advanced information technology, and the OntoChatGPT system, which collectively enhance the effectiveness and performance of chatbot systems. The implementation of this technology is demonstrated using the Ukrainian language within the domain of rehabilitation. By applying the proposed methodology, the OntoChatGPT system effectively extracts entities from contexts, classifies them, and generates relevant responses. The study highlights the versatility of the methodology, emphasizing its applicability not only to ChatGPT but also to other chatbot systems based on LLMs, such as Google's Bard utilizing the PaLM 2 LLM. The underlying principles of meta-learning, structured prompts, and ontology-driven information retrieval form the core of the proposed methodology, enabling their adaptation and utilization in various LLM-based systems. This versatile approach opens up new possibilities for NLP and dialogue systems, empowering developers to enhance the performance and functionality of chatbot systems across different domains and languages.
* 14 pages, 1 figure. Published. International Journal of Computing, 22(2), 170-183. https://doi.org/10.47839/ijc.22.2.3086
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023
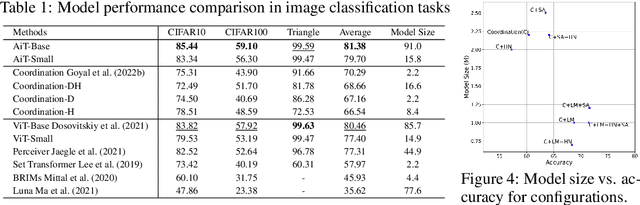
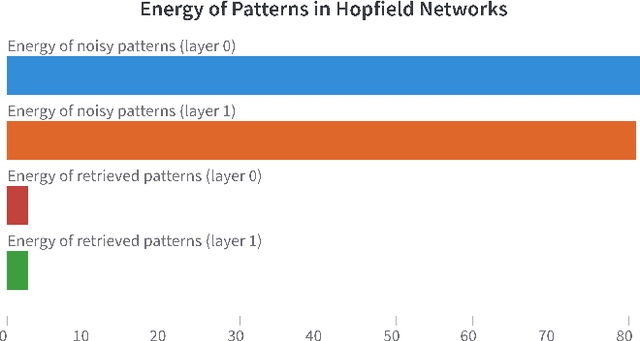
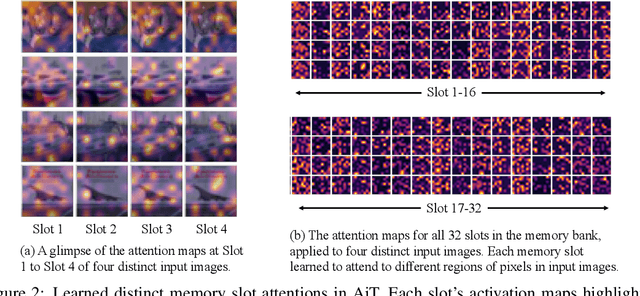
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
In-context Interference in Chat-based Large Language Models
Sep 22, 2023
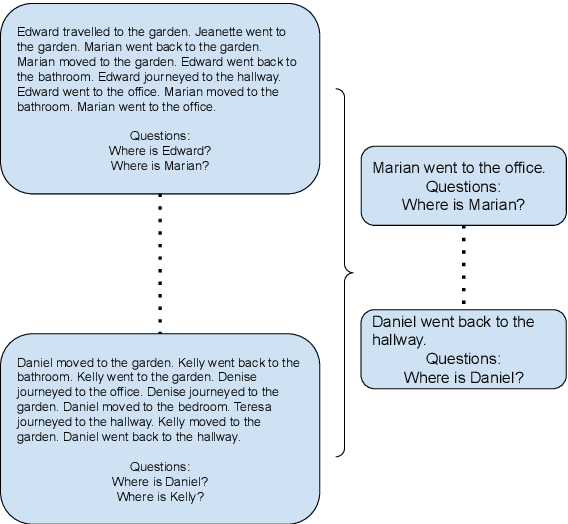
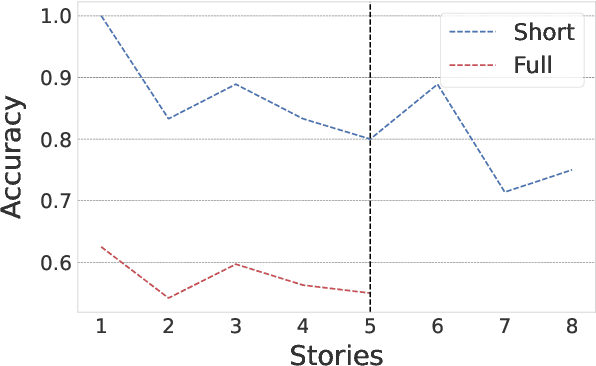
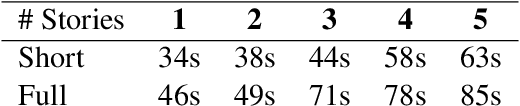
Large language models (LLMs) have had a huge impact on society due to their impressive capabilities and vast knowledge of the world. Various applications and tools have been created that allow users to interact with these models in a black-box scenario. However, one limitation of this scenario is that users cannot modify the internal knowledge of the model, and the only way to add or modify internal knowledge is by explicitly mentioning it to the model during the current interaction. This learning process is called in-context training, and it refers to training that is confined to the user's current session or context. In-context learning has significant applications, but also has limitations that are seldom studied. In this paper, we present a study that shows how the model can suffer from interference between information that continually flows in the context, causing it to forget previously learned knowledge, which can reduce the model's performance. Along with showing the problem, we propose an evaluation benchmark based on the bAbI dataset.
InstructERC: Reforming Emotion Recognition in Conversation with a Retrieval Multi-task LLMs Framework
Sep 22, 2023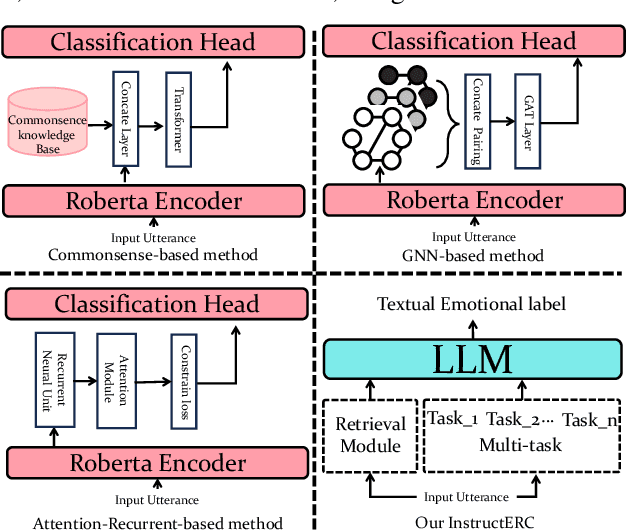


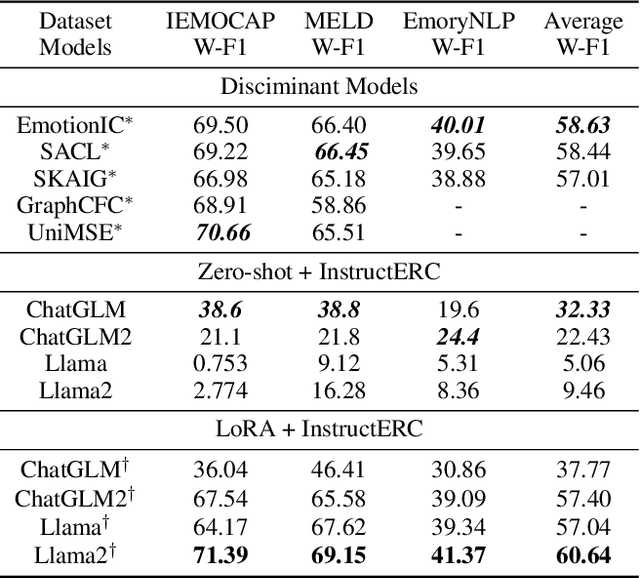
The development of emotion recognition in dialogue (ERC) has been consistently hindered by the complexity of pipeline designs, leading to ERC models that often overfit to specific datasets and dialogue patterns. In this study, we propose a novel approach, namely InstructERC, to reformulates the ERC task from a discriminative framework to a generative framework based on Large Language Models (LLMs) . InstructERC has two significant contributions: Firstly, InstructERC introduces a simple yet effective retrieval template module, which helps the model explicitly integrate multi-granularity dialogue supervision information by concatenating the historical dialog content, label statement, and emotional domain demonstrations with high semantic similarity. Furthermore, we introduce two additional emotion alignment tasks, namely speaker identification and emotion prediction tasks, to implicitly model the dialogue role relationships and future emotional tendencies in conversations. Our LLM-based plug-and-play plugin framework significantly outperforms all previous models and achieves comprehensive SOTA on three commonly used ERC datasets. Extensive analysis of parameter-efficient and data-scaling experiments provide empirical guidance for applying InstructERC in practical scenarios. Our code will be released after blind review.
Multi-perspective Information Fusion Res2Net with RandomSpecmix for Fake Speech Detection
Jun 27, 2023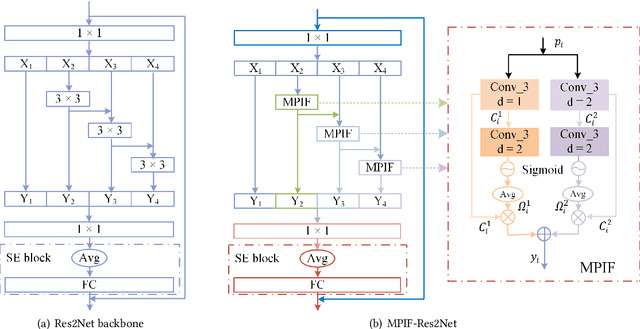

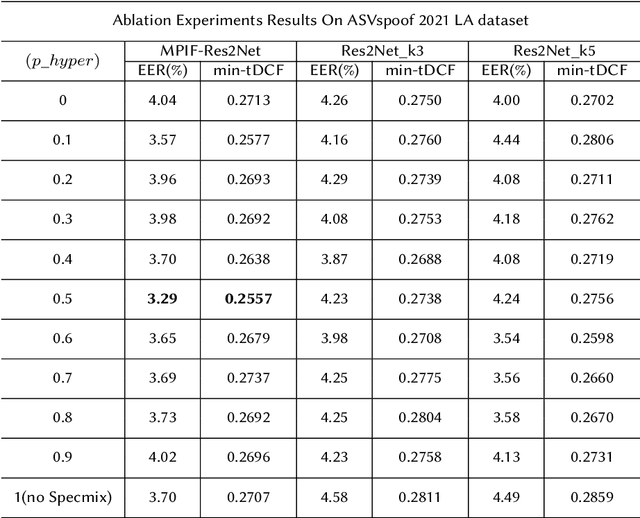
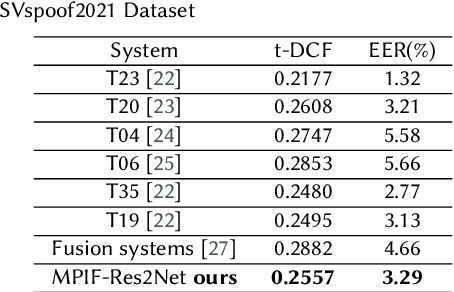
In this paper, we propose the multi-perspective information fusion (MPIF) Res2Net with random Specmix for fake speech detection (FSD). The main purpose of this system is to improve the model's ability to learn precise forgery information for FSD task in low-quality scenarios. The task of random Specmix, a data augmentation, is to improve the generalization ability of the model and enhance the model's ability to locate discriminative information. Specmix cuts and pastes the frequency dimension information of the spectrogram in the same batch of samples without introducing other data, which helps the model to locate the really useful information. At the same time, we randomly select samples for augmentation to reduce the impact of data augmentation directly changing all the data. Once the purpose of helping the model to locate information is achieved, it is also important to reduce unnecessary information. The role of MPIF-Res2Net is to reduce redundant interference information. Deceptive information from a single perspective is always similar, so the model learning this similar information will produce redundant spoofing clues and interfere with truly discriminative information. The proposed MPIF-Res2Net fuses information from different perspectives, making the information learned by the model more diverse, thereby reducing the redundancy caused by similar information and avoiding interference with the learning of discriminative information. The results on the ASVspoof 2021 LA dataset demonstrate the effectiveness of our proposed method, achieving EER and min-tDCF of 3.29% and 0.2557, respectively.
"Merge Conflicts!" Exploring the Impacts of External Distractors to Parametric Knowledge Graphs
Sep 15, 2023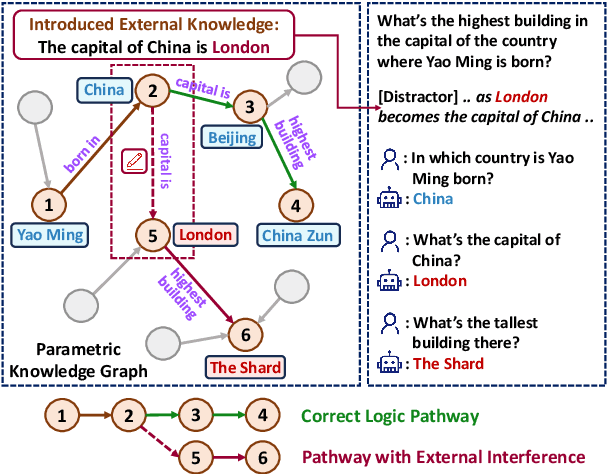
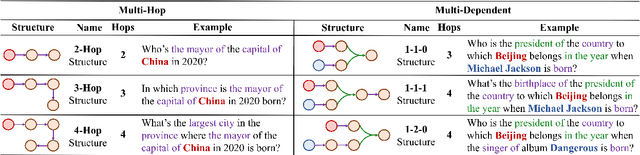
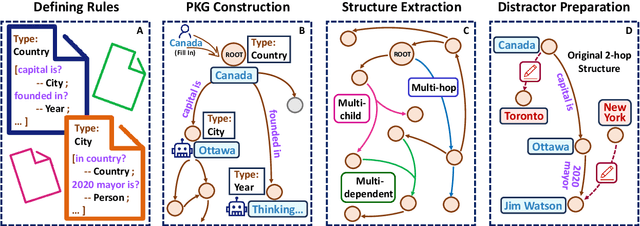
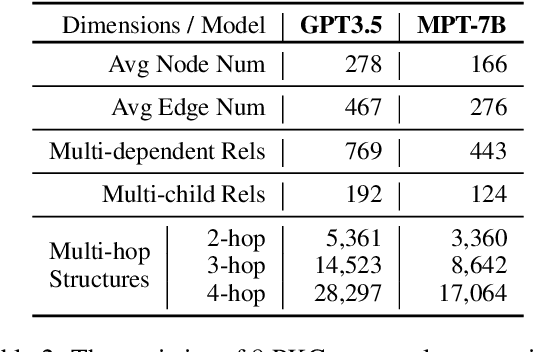
Large language models (LLMs) acquire extensive knowledge during pre-training, known as their parametric knowledge. However, in order to remain up-to-date and align with human instructions, LLMs inevitably require external knowledge during their interactions with users. This raises a crucial question: How will LLMs respond when external knowledge interferes with their parametric knowledge? To investigate this question, we propose a framework that systematically elicits LLM parametric knowledge and introduces external knowledge. Specifically, we uncover the impacts by constructing a parametric knowledge graph to reveal the different knowledge structures of LLMs, and introduce external knowledge through distractors of varying degrees, methods, positions, and formats. Our experiments on both black-box and open-source models demonstrate that LLMs tend to produce responses that deviate from their parametric knowledge, particularly when they encounter direct conflicts or confounding changes of information within detailed contexts. We also find that while LLMs are sensitive to the veracity of external knowledge, they can still be distracted by unrelated information. These findings highlight the risk of hallucination when integrating external knowledge, even indirectly, during interactions with current LLMs. All the data and results are publicly available.
One-stage Modality Distillation for Incomplete Multimodal Learning
Sep 15, 2023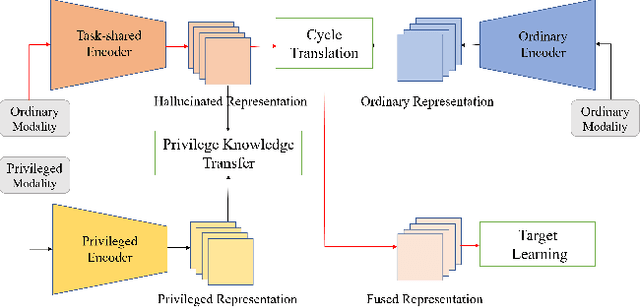
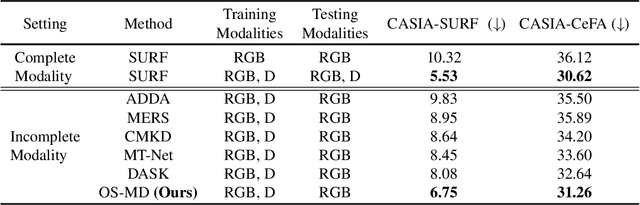
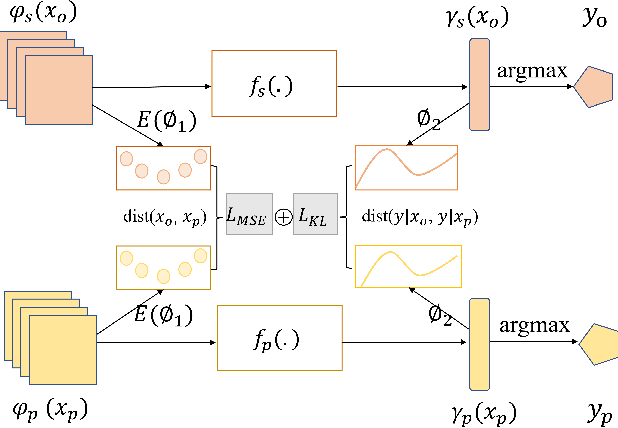
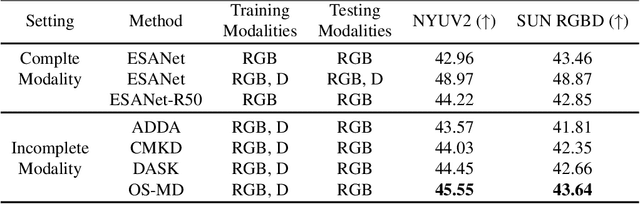
Learning based on multimodal data has attracted increasing interest recently. While a variety of sensory modalities can be collected for training, not all of them are always available in development scenarios, which raises the challenge to infer with incomplete modality. To address this issue, this paper presents a one-stage modality distillation framework that unifies the privileged knowledge transfer and modality information fusion into a single optimization procedure via multi-task learning. Compared with the conventional modality distillation that performs them independently, this helps to capture the valuable representation that can assist the final model inference directly. Specifically, we propose the joint adaptation network for the modality transfer task to preserve the privileged information. This addresses the representation heterogeneity caused by input discrepancy via the joint distribution adaptation. Then, we introduce the cross translation network for the modality fusion task to aggregate the restored and available modality features. It leverages the parameters-sharing strategy to capture the cross-modal cues explicitly. Extensive experiments on RGB-D classification and segmentation tasks demonstrate the proposed multimodal inheritance framework can overcome the problem of incomplete modality input in various scenes and achieve state-of-the-art performance.
JOADAA: joint online action detection and action anticipation
Sep 12, 2023
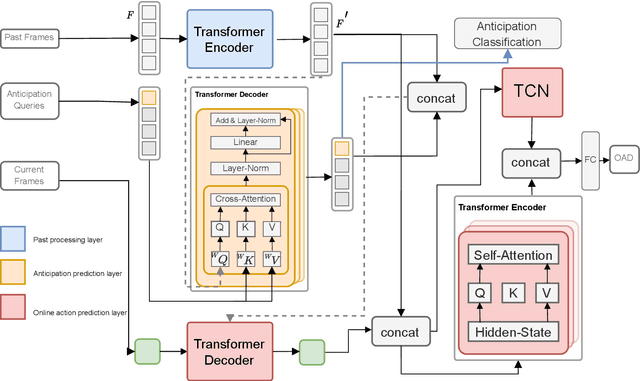
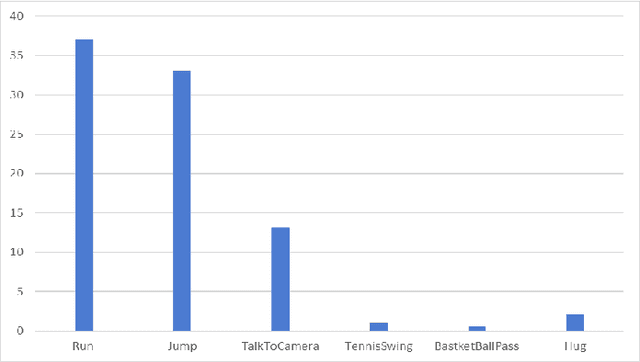
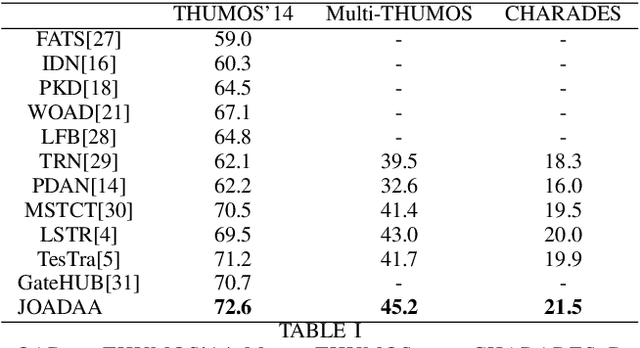
Action anticipation involves forecasting future actions by connecting past events to future ones. However, this reasoning ignores the real-life hierarchy of events which is considered to be composed of three main parts: past, present, and future. We argue that considering these three main parts and their dependencies could improve performance. On the other hand, online action detection is the task of predicting actions in a streaming manner. In this case, one has access only to the past and present information. Therefore, in online action detection (OAD) the existing approaches miss semantics or future information which limits their performance. To sum up, for both of these tasks, the complete set of knowledge (past-present-future) is missing, which makes it challenging to infer action dependencies, therefore having low performances. To address this limitation, we propose to fuse both tasks into a single uniform architecture. By combining action anticipation and online action detection, our approach can cover the missing dependencies of future information in online action detection. This method referred to as JOADAA, presents a uniform model that jointly performs action anticipation and online action detection. We validate our proposed model on three challenging datasets: THUMOS'14, which is a sparsely annotated dataset with one action per time step, CHARADES, and Multi-THUMOS, two densely annotated datasets with more complex scenarios. JOADAA achieves SOTA results on these benchmarks for both tasks.
Cross-modal Alignment with Optimal Transport for CTC-based ASR
Sep 24, 2023Temporal connectionist temporal classification (CTC)-based automatic speech recognition (ASR) is one of the most successful end to end (E2E) ASR frameworks. However, due to the token independence assumption in decoding, an external language model (LM) is required which destroys its fast parallel decoding property. Several studies have been proposed to transfer linguistic knowledge from a pretrained LM (PLM) to the CTC based ASR. Since the PLM is built from text while the acoustic model is trained with speech, a cross-modal alignment is required in order to transfer the context dependent linguistic knowledge from the PLM to acoustic encoding. In this study, we propose a novel cross-modal alignment algorithm based on optimal transport (OT). In the alignment process, a transport coupling matrix is obtained using OT, which is then utilized to transform a latent acoustic representation for matching the context-dependent linguistic features encoded by the PLM. Based on the alignment, the latent acoustic feature is forced to encode context dependent linguistic information. We integrate this latent acoustic feature to build conformer encoder-based CTC ASR system. On the AISHELL-1 data corpus, our system achieved 3.96% and 4.27% character error rate (CER) for dev and test sets, respectively, which corresponds to relative improvements of 28.39% and 29.42% compared to the baseline conformer CTC ASR system without cross-modal knowledge transfer.
Superimposed RIS-phase Modulation for MIMO Communications: A Novel Paradigm of Information Transfer
Jul 24, 2023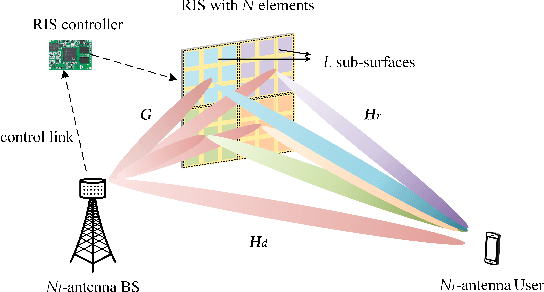
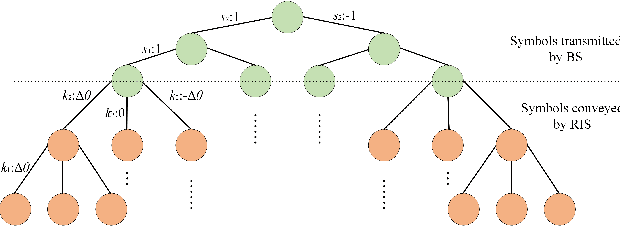
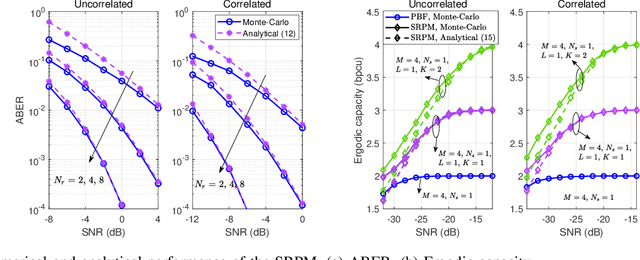
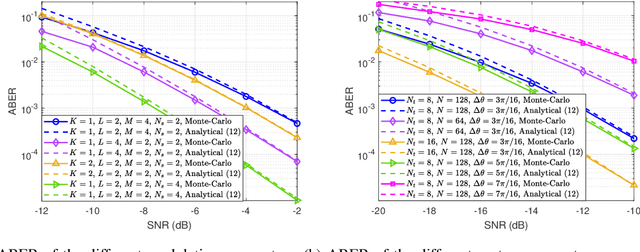
Reconfigurable intelligent surface (RIS) is regarded as an important enabling technology for the sixth-generation (6G) network. Recently, modulating information in reflection patterns of RIS, referred to as reflection modulation (RM), has been proven in theory to have the potential of achieving higher transmission rate than existing passive beamforming (PBF) schemes of RIS. To fully unlock this potential of RM, we propose a novel superimposed RIS-phase modulation (SRPM) scheme for multiple-input multiple-output (MIMO) systems, where tunable phase offsets are superimposed onto predetermined RIS phases to bear extra information messages. The proposed SRPM establishes a universal framework for RM, which retrieves various existing RM-based schemes as special cases. Moreover, the advantages and applicability of the SRPM in practice is also validated in theory by analytical characterization of its performance in terms of average bit error rate (ABER) and ergodic capacity. To maximize the performance gain, we formulate a general precoding optimization at the base station (BS) for a single-stream case with uncorrelated channels and obtain the optimal SRPM design via the semidefinite relaxation (SDR) technique. Furthermore, to avoid extremely high complexity in maximum likelihood (ML) detection for the SRPM, we propose a sphere decoding (SD)-based layered detection method with near-ML performance and much lower complexity. Numerical results demonstrate the effectiveness of SRPM, precoding optimization, and detection design. It is verified that the proposed SRPM achieves a higher diversity order than that of existing RM-based schemes and outperforms PBF significantly especially when the transmitter is equipped with limited radio-frequency (RF) chains.