 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Difficulties of Attention Factorization through Shared Memory
Mar 31, 2024
Transformers have revolutionized deep learning in numerous fields, including natural language processing, computer vision, and audio processing. Their strength lies in their attention mechanism, which allows for the discovering of complex input relationships. However, this mechanism's quadratic time and memory complexity pose challenges for larger inputs. Researchers are now investigating models like Linear Unified Nested Attention (Luna) or Memory Augmented Transformer, which leverage external learnable memory to either reduce the attention computation complexity down to linear, or to propagate information between chunks in chunk-wise processing. Our findings challenge the conventional thinking on these models, revealing that interfacing with the memory directly through an attention operation is suboptimal, and that the performance may be considerably improved by filtering the input signal before communicating with memory.
Logits of API-Protected LLMs Leak Proprietary Information
Mar 15, 2024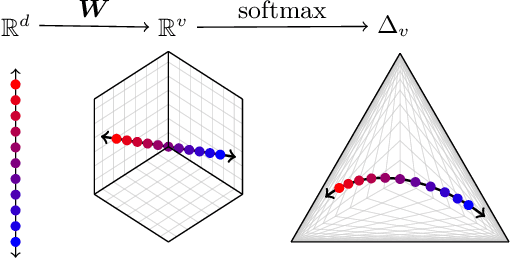

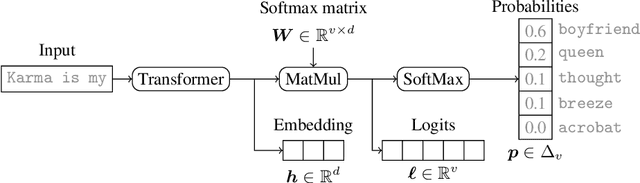

The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption about the model architecture, it is possible to learn a surprisingly large amount of non-public information about an API-protected LLM from a relatively small number of API queries (e.g., costing under $1,000 for OpenAI's gpt-3.5-turbo). Our findings are centered on one key observation: most modern LLMs suffer from a softmax bottleneck, which restricts the model outputs to a linear subspace of the full output space. We show that this lends itself to a model image or a model signature which unlocks several capabilities with affordable cost: efficiently discovering the LLM's hidden size, obtaining full-vocabulary outputs, detecting and disambiguating different model updates, identifying the source LLM given a single full LLM output, and even estimating the output layer parameters. Our empirical investigations show the effectiveness of our methods, which allow us to estimate the embedding size of OpenAI's gpt-3.5-turbo to be about 4,096. Lastly, we discuss ways that LLM providers can guard against these attacks, as well as how these capabilities can be viewed as a feature (rather than a bug) by allowing for greater transparency and accountability.
From "um" to "yeah": Producing, predicting, and regulating information flow in human conversation
Mar 13, 2024
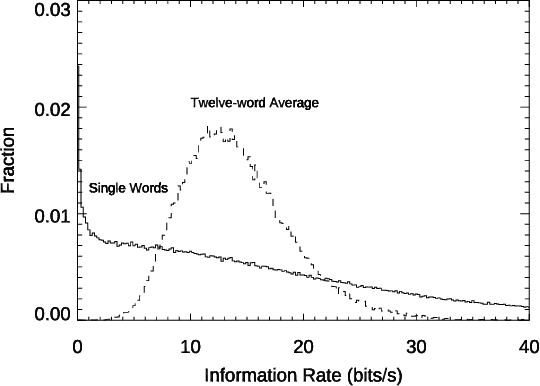
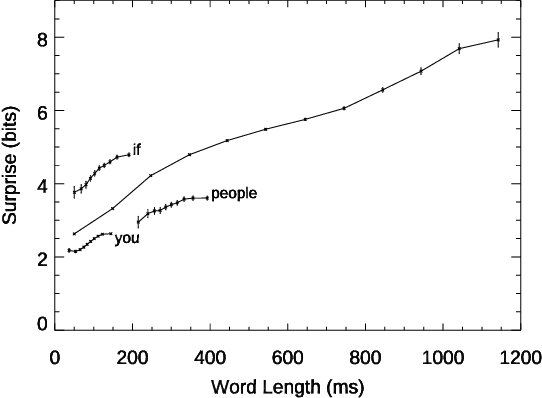
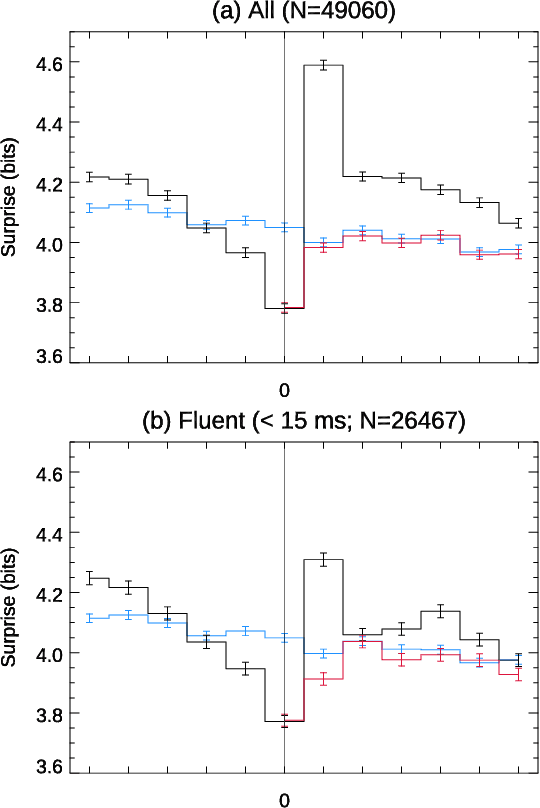
Conversation demands attention. Speakers must call words to mind, listeners must make sense of them, and both together must negotiate this flow of information, all in fractions of a second. We used large language models to study how this works in a large-scale dataset of English-language conversation, the CANDOR corpus. We provide a new estimate of the information density of unstructured conversation, of approximately 13 bits/second, and find significant effects associated with the cognitive load of both retrieving, and presenting, that information. We also reveal a role for backchannels -- the brief yeahs, uh-huhs, and mhmms that listeners provide -- in regulating the production of novelty: the lead-up to a backchannel is associated with declining information rate, while speech downstream rebounds to previous rates. Our results provide new insights into long-standing theories of how we respond to fluctuating demands on cognitive resources, and how we negotiate those demands in partnership with others.
2D Ego-Motion with Yaw Estimation using Only mmWave Radars via Two-Way weighted ICP
Mar 31, 2024The interest in single-chip mmWave Radar is driven by their compact form factor, cost-effectiveness, and robustness under harsh environmental conditions. Despite its promising attributes, the principal limitation of mmWave radar lies in its capacity for autonomous yaw rate estimation. Conventional solutions have often resorted to integrating inertial measurement unit (IMU) or deploying multiple radar units to circumvent this shortcoming. This paper introduces an innovative methodology for two-dimensional ego-motion estimation, focusing on yaw rate deduction, utilizing solely mmWave radar sensors. By applying a weighted Iterated Closest Point (ICP) algorithm to register processed points derived from heatmap data, our method facilitates 2D ego-motion estimation devoid of prior information. Through experimental validation, we verified the effectiveness and promise of our technique for ego-motion estimation using exclusively radar data.
Enhancing Real-World Active Speaker Detection with Multi-Modal Extraction Pre-Training
Apr 01, 2024Audio-visual active speaker detection (AV-ASD) aims to identify which visible face is speaking in a scene with one or more persons. Most existing AV-ASD methods prioritize capturing speech-lip correspondence. However, there is a noticeable gap in addressing the challenges from real-world AV-ASD scenarios. Due to the presence of low-quality noisy videos in such cases, AV-ASD systems without a selective listening ability are short of effectively filtering out disruptive voice components from mixed audio inputs. In this paper, we propose a Multi-modal Speaker Extraction-to-Detection framework named `MuSED', which is pre-trained with audio-visual target speaker extraction to learn the denoising ability, then it is fine-tuned with the AV-ASD task. Meanwhile, to better capture the multi-modal information and deal with real-world problems such as missing modality, MuSED is modelled on the time domain directly and integrates the multi-modal plus-and-minus augmentation strategy. Our experiments demonstrate that MuSED substantially outperforms the state-of-the-art AV-ASD methods and achieves 95.6% mAP on the AVA-ActiveSpeaker dataset, 98.3% AP on the ASW dataset, and 97.9% F1 on the Columbia AV-ASD dataset, respectively. We will publicly release the code in due course.
Generating Content for HDR Deghosting from Frequency View
Apr 01, 2024Recovering ghost-free High Dynamic Range (HDR) images from multiple Low Dynamic Range (LDR) images becomes challenging when the LDR images exhibit saturation and significant motion. Recent Diffusion Models (DMs) have been introduced in HDR imaging field, demonstrating promising performance, particularly in achieving visually perceptible results compared to previous DNN-based methods. However, DMs require extensive iterations with large models to estimate entire images, resulting in inefficiency that hinders their practical application. To address this challenge, we propose the Low-Frequency aware Diffusion (LF-Diff) model for ghost-free HDR imaging. The key idea of LF-Diff is implementing the DMs in a highly compacted latent space and integrating it into a regression-based model to enhance the details of reconstructed images. Specifically, as low-frequency information is closely related to human visual perception we propose to utilize DMs to create compact low-frequency priors for the reconstruction process. In addition, to take full advantage of the above low-frequency priors, the Dynamic HDR Reconstruction Network (DHRNet) is carried out in a regression-based manner to obtain final HDR images. Extensive experiments conducted on synthetic and real-world benchmark datasets demonstrate that our LF-Diff performs favorably against several state-of-the-art methods and is 10$\times$ faster than previous DM-based methods.
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models
Apr 01, 2024Diffusion Models are vulnerable to backdoor attacks, where malicious attackers inject backdoors by poisoning some parts of the training samples during the training stage. This poses a serious threat to the downstream users, who query the diffusion models through the API or directly download them from the internet. To mitigate the threat of backdoor attacks, there have been a plethora of investigations on backdoor detections. However, none of them designed a specialized backdoor detection method for diffusion models, rendering the area much under-explored. Moreover, these prior methods mainly focus on the traditional neural networks in the classification task, which cannot be adapted to the backdoor detections on the generative task easily. Additionally, most of the prior methods require white-box access to model weights and architectures, or the probability logits as additional information, which are not always practical. In this paper, we propose a Unified Framework for Input-level backdoor Detection (UFID) on the diffusion models, which is motivated by observations in the diffusion models and further validated with a theoretical causality analysis. Extensive experiments across different datasets on both conditional and unconditional diffusion models show that our method achieves a superb performance on detection effectiveness and run-time efficiency. The code is available at https://github.com/GuanZihan/official_UFID.
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
MaGRITTe: Manipulative and Generative 3D Realization from Image, Topview and Text
Mar 30, 2024The generation of 3D scenes from user-specified conditions offers a promising avenue for alleviating the production burden in 3D applications. Previous studies required significant effort to realize the desired scene, owing to limited control conditions. We propose a method for controlling and generating 3D scenes under multimodal conditions using partial images, layout information represented in the top view, and text prompts. Combining these conditions to generate a 3D scene involves the following significant difficulties: (1) the creation of large datasets, (2) reflection on the interaction of multimodal conditions, and (3) domain dependence of the layout conditions. We decompose the process of 3D scene generation into 2D image generation from the given conditions and 3D scene generation from 2D images. 2D image generation is achieved by fine-tuning a pretrained text-to-image model with a small artificial dataset of partial images and layouts, and 3D scene generation is achieved by layout-conditioned depth estimation and neural radiance fields (NeRF), thereby avoiding the creation of large datasets. The use of a common representation of spatial information using 360-degree images allows for the consideration of multimodal condition interactions and reduces the domain dependence of the layout control. The experimental results qualitatively and quantitatively demonstrated that the proposed method can generate 3D scenes in diverse domains, from indoor to outdoor, according to multimodal conditions.
Dependability Evaluation of Stable Diffusion with Soft Errors on the Model Parameters
Mar 30, 2024Stable Diffusion is a popular Transformer-based model for image generation from text; it applies an image information creator to the input text and the visual knowledge is added in a step-by-step fashion to create an image that corresponds to the input text. However, this diffusion process can be corrupted by errors from the underlying hardware, which are especially relevant for implementations at the nanoscales. In this paper, the dependability of Stable Diffusion is studied focusing on soft errors in the memory that stores the model parameters; specifically, errors are injected into some critical layers of the Transformer in different blocks of the image information creator, to evaluate their impact on model performance. The simulations results reveal several conclusions: 1) errors on the down blocks of the creator have a larger impact on the quality of the generated images than those on the up blocks, while the errors on middle block have negligible effect; 2) errors on the self-attention (SA) layers have larger impact on the results than those on the cross-attention (CA) layers; 3) for CA layers, errors on deeper levels result in a larger impact; 4) errors on blocks at the first levels tend to introduce noise in the image, and those on deep layers tend to introduce large colored blocks. These results provide an initial understanding of the impact of errors on Stable Diffusion.