 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Talk2Care: Facilitating Asynchronous Patient-Provider Communication with Large-Language-Model
Sep 17, 2023
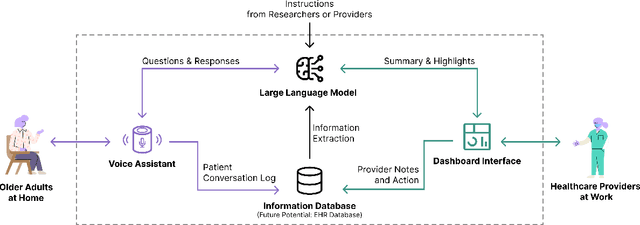
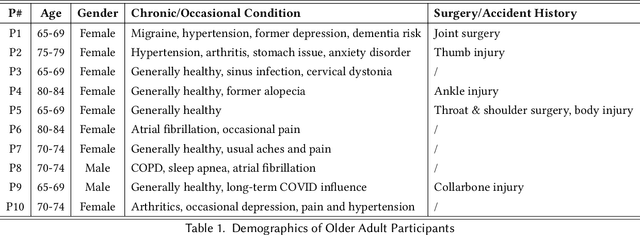
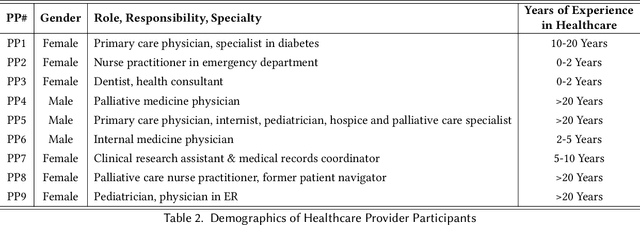
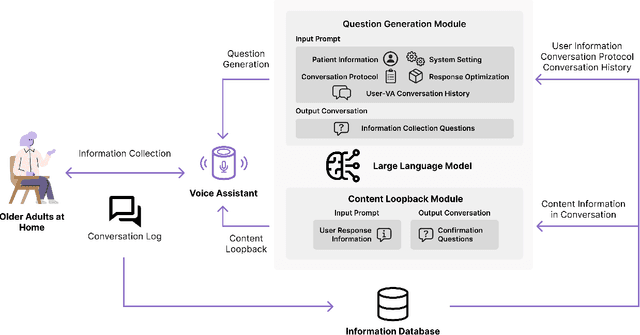
Despite the plethora of telehealth applications to assist home-based older adults and healthcare providers, basic messaging and phone calls are still the most common communication methods, which suffer from limited availability, information loss, and process inefficiencies. One promising solution to facilitate patient-provider communication is to leverage large language models (LLMs) with their powerful natural conversation and summarization capability. However, there is a limited understanding of LLMs' role during the communication. We first conducted two interview studies with both older adults (N=10) and healthcare providers (N=9) to understand their needs and opportunities for LLMs in patient-provider asynchronous communication. Based on the insights, we built an LLM-powered communication system, Talk2Care, and designed interactive components for both groups: (1) For older adults, we leveraged the convenience and accessibility of voice assistants (VAs) and built an LLM-powered VA interface for effective information collection. (2) For health providers, we built an LLM-based dashboard to summarize and present important health information based on older adults' conversations with the VA. We further conducted two user studies with older adults and providers to evaluate the usability of the system. The results showed that Talk2Care could facilitate the communication process, enrich the health information collected from older adults, and considerably save providers' efforts and time. We envision our work as an initial exploration of LLMs' capability in the intersection of healthcare and interpersonal communication.
When Large Language Models Meet Citation: A Survey
Sep 18, 2023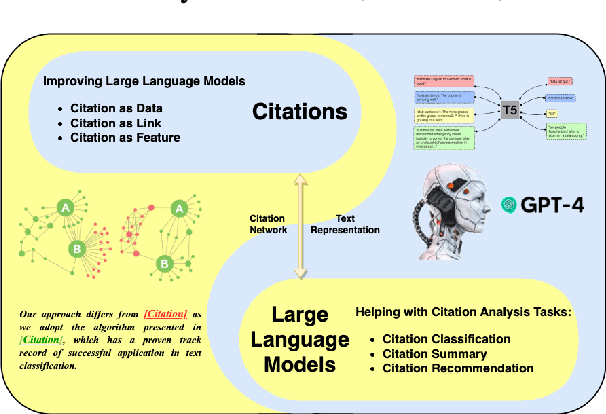


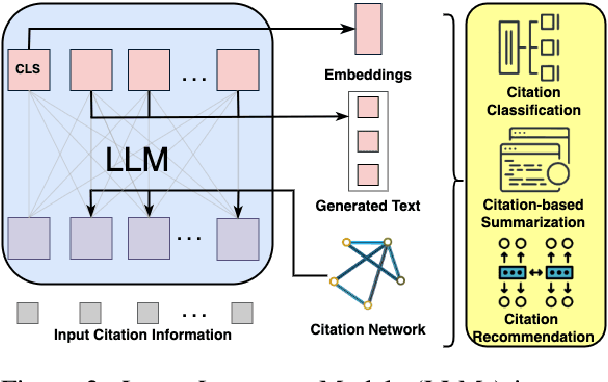
Citations in scholarly work serve the essential purpose of acknowledging and crediting the original sources of knowledge that have been incorporated or referenced. Depending on their surrounding textual context, these citations are used for different motivations and purposes. Large Language Models (LLMs) could be helpful in capturing these fine-grained citation information via the corresponding textual context, thereby enabling a better understanding towards the literature. Furthermore, these citations also establish connections among scientific papers, providing high-quality inter-document relationships and human-constructed knowledge. Such information could be incorporated into LLMs pre-training and improve the text representation in LLMs. Therefore, in this paper, we offer a preliminary review of the mutually beneficial relationship between LLMs and citation analysis. Specifically, we review the application of LLMs for in-text citation analysis tasks, including citation classification, citation-based summarization, and citation recommendation. We then summarize the research pertinent to leveraging citation linkage knowledge to improve text representations of LLMs via citation prediction, network structure information, and inter-document relationship. We finally provide an overview of these contemporary methods and put forth potential promising avenues in combining LLMs and citation analysis for further investigation.
Improved Factorized Neural Transducer Model For text-only Domain Adaptation
Sep 18, 2023End-to-end models, such as the neural Transducer, have been successful in integrating acoustic and linguistic information jointly to achieve excellent recognition performance. However, adapting these models with text-only data is challenging. Factorized neural Transducer (FNT) aims to address this issue by introducing a separate vocabulary decoder to predict the vocabulary, which can effectively perform traditional text data adaptation. Nonetheless, this approach has limitations in fusing acoustic and language information seamlessly. Moreover, a degradation in word error rate (WER) on the general test sets was also observed, leading to doubts about its overall performance. In response to this challenge, we present an improved factorized neural Transducer (IFNT) model structure designed to comprehensively integrate acoustic and language information while enabling effective text adaptation. We evaluate the performance of our proposed methods through in-domain experiments on GigaSpeech and out-of-domain experiments adapting to EuroParl, TED-LIUM, and Medical datasets. After text-only adaptation, IFNT yields 7.9% to 28.5% relative WER improvements over the standard neural Transducer with shallow fusion, and relative WER reductions ranging from 1.6% to 8.2% on the three test sets compared to the FNT model.
Multi-task View Synthesis with Neural Radiance Fields
Sep 29, 2023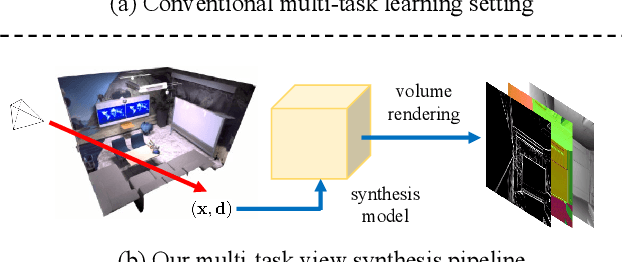
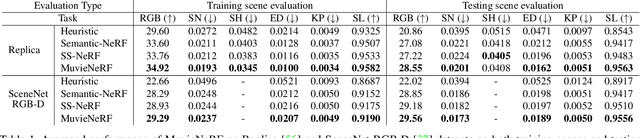
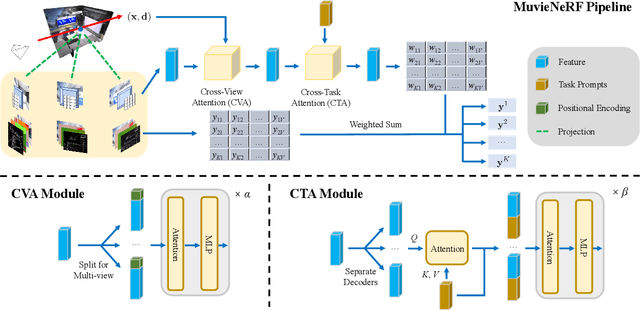
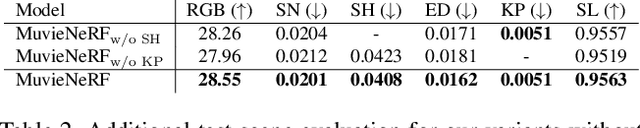
Multi-task visual learning is a critical aspect of computer vision. Current research, however, predominantly concentrates on the multi-task dense prediction setting, which overlooks the intrinsic 3D world and its multi-view consistent structures, and lacks the capability for versatile imagination. In response to these limitations, we present a novel problem setting -- multi-task view synthesis (MTVS), which reinterprets multi-task prediction as a set of novel-view synthesis tasks for multiple scene properties, including RGB. To tackle the MTVS problem, we propose MuvieNeRF, a framework that incorporates both multi-task and cross-view knowledge to simultaneously synthesize multiple scene properties. MuvieNeRF integrates two key modules, the Cross-Task Attention (CTA) and Cross-View Attention (CVA) modules, enabling the efficient use of information across multiple views and tasks. Extensive evaluation on both synthetic and realistic benchmarks demonstrates that MuvieNeRF is capable of simultaneously synthesizing different scene properties with promising visual quality, even outperforming conventional discriminative models in various settings. Notably, we show that MuvieNeRF exhibits universal applicability across a range of NeRF backbones. Our code is available at https://github.com/zsh2000/MuvieNeRF.
An Investigation Into Race Bias in Random Forest Models Based on Breast DCE-MRI Derived Radiomics Features
Sep 29, 2023Recent research has shown that artificial intelligence (AI) models can exhibit bias in performance when trained using data that are imbalanced by protected attribute(s). Most work to date has focused on deep learning models, but classical AI techniques that make use of hand-crafted features may also be susceptible to such bias. In this paper we investigate the potential for race bias in random forest (RF) models trained using radiomics features. Our application is prediction of tumour molecular subtype from dynamic contrast enhanced magnetic resonance imaging (DCE-MRI) of breast cancer patients. Our results show that radiomics features derived from DCE-MRI data do contain race-identifiable information, and that RF models can be trained to predict White and Black race from these data with 60-70% accuracy, depending on the subset of features used. Furthermore, RF models trained to predict tumour molecular subtype using race-imbalanced data seem to produce biased behaviour, exhibiting better performance on test data from the race on which they were trained.
MARL: Multi-scale Archetype Representation Learning for Urban Building Energy Modeling
Sep 29, 2023Building archetypes, representative models of building stock, are crucial for precise energy simulations in Urban Building Energy Modeling. The current widely adopted building archetypes are developed on a nationwide scale, potentially neglecting the impact of local buildings' geometric specificities. We present Multi-scale Archetype Representation Learning (MARL), an approach that leverages representation learning to extract geometric features from a specific building stock. Built upon VQ-AE, MARL encodes building footprints and purifies geometric information into latent vectors constrained by multiple architectural downstream tasks. These tailored representations are proven valuable for further clustering and building energy modeling. The advantages of our algorithm are its adaptability with respect to the different building footprint sizes, the ability for automatic generation across multi-scale regions, and the preservation of geometric features across neighborhoods and local ecologies. In our study spanning five regions in LA County, we show MARL surpasses both conventional and VQ-AE extracted archetypes in performance. Results demonstrate that geometric feature embeddings significantly improve the accuracy and reliability of energy consumption estimates. Code, dataset and trained models are publicly available: https://github.com/ZixunHuang1997/MARL-BuildingEnergyEstimation
WASA: WAtermark-based Source Attribution for Large Language Model-Generated Data
Oct 01, 2023

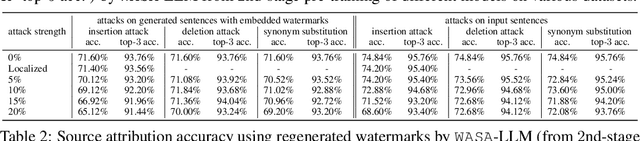
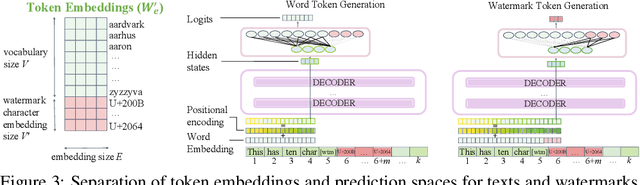
The impressive performances of large language models (LLMs) and their immense potential for commercialization have given rise to serious concerns over the intellectual property (IP) of their training data. In particular, the synthetic texts generated by LLMs may infringe the IP of the data being used to train the LLMs. To this end, it is imperative to be able to (a) identify the data provider who contributed to the generation of a synthetic text by an LLM (source attribution) and (b) verify whether the text data from a data provider has been used to train an LLM (data provenance). In this paper, we show that both problems can be solved by watermarking, i.e., by enabling an LLM to generate synthetic texts with embedded watermarks that contain information about their source(s). We identify the key properties of such watermarking frameworks (e.g., source attribution accuracy, robustness against adversaries), and propose a WAtermarking for Source Attribution (WASA) framework that satisfies these key properties due to our algorithmic designs. Our WASA framework enables an LLM to learn an accurate mapping from the texts of different data providers to their corresponding unique watermarks, which sets the foundation for effective source attribution (and hence data provenance). Extensive empirical evaluations show that our WASA framework achieves effective source attribution and data provenance.
Contextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023
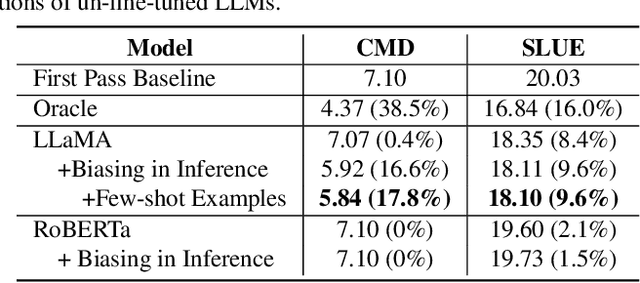
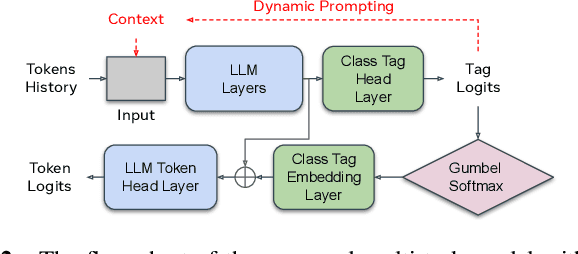
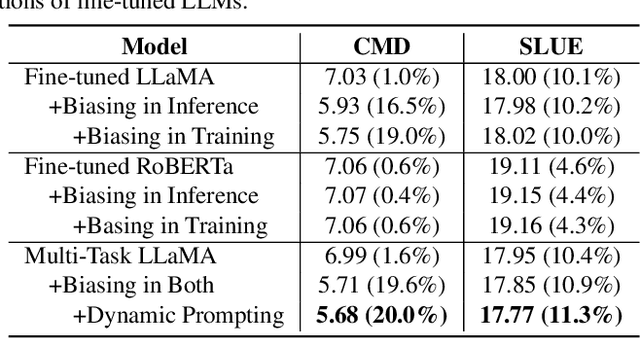
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Deep3DSketch+: Rapid 3D Modeling from Single Free-hand Sketches
Sep 22, 2023The rapid development of AR/VR brings tremendous demands for 3D content. While the widely-used Computer-Aided Design (CAD) method requires a time-consuming and labor-intensive modeling process, sketch-based 3D modeling offers a potential solution as a natural form of computer-human interaction. However, the sparsity and ambiguity of sketches make it challenging to generate high-fidelity content reflecting creators' ideas. Precise drawing from multiple views or strategic step-by-step drawings is often required to tackle the challenge but is not friendly to novice users. In this work, we introduce a novel end-to-end approach, Deep3DSketch+, which performs 3D modeling using only a single free-hand sketch without inputting multiple sketches or view information. Specifically, we introduce a lightweight generation network for efficient inference in real-time and a structural-aware adversarial training approach with a Stroke Enhancement Module (SEM) to capture the structural information to facilitate learning of the realistic and fine-detailed shape structures for high-fidelity performance. Extensive experiments demonstrated the effectiveness of our approach with the state-of-the-art (SOTA) performance on both synthetic and real datasets.
PanoVOS: Bridging Non-panoramic and Panoramic Views with Transformer for Video Segmentation
Sep 22, 2023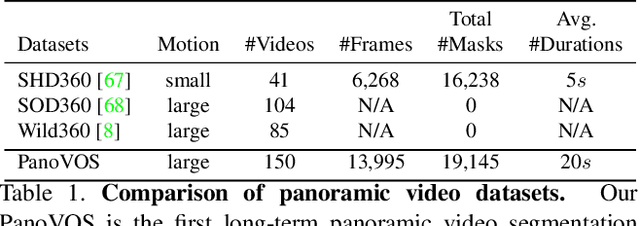

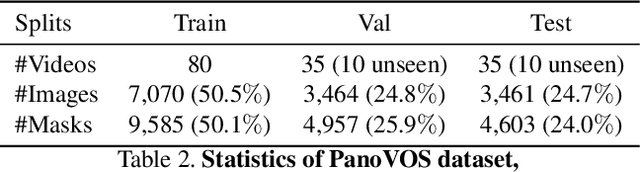
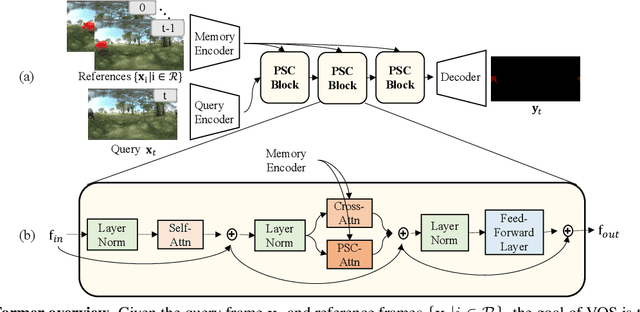
Panoramic videos contain richer spatial information and have attracted tremendous amounts of attention due to their exceptional experience in some fields such as autonomous driving and virtual reality. However, existing datasets for video segmentation only focus on conventional planar images. To address the challenge, in this paper, we present a panoramic video dataset, PanoVOS. The dataset provides 150 videos with high video resolutions and diverse motions. To quantify the domain gap between 2D planar videos and panoramic videos, we evaluate 15 off-the-shelf video object segmentation (VOS) models on PanoVOS. Through error analysis, we found that all of them fail to tackle pixel-level content discontinues of panoramic videos. Thus, we present a Panoramic Space Consistency Transformer (PSCFormer), which can effectively utilize the semantic boundary information of the previous frame for pixel-level matching with the current frame. Extensive experiments demonstrate that compared with the previous SOTA models, our PSCFormer network exhibits a great advantage in terms of segmentation results under the panoramic setting. Our dataset poses new challenges in panoramic VOS and we hope that our PanoVOS can advance the development of panoramic segmentation/tracking.