 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Brief History of Prompt: Leveraging Language Models
Sep 30, 2023
This paper presents a comprehensive exploration of the evolution of prompt engineering and generation in the field of natural language processing (NLP). Starting from the early language models and information retrieval systems, we trace the key developments that have shaped prompt engineering over the years. The introduction of attention mechanisms in 2015 revolutionized language understanding, leading to advancements in controllability and context-awareness. Subsequent breakthroughs in reinforcement learning techniques further enhanced prompt engineering, addressing issues like exposure bias and biases in generated text. We examine the significant contributions in 2018 and 2019, focusing on fine-tuning strategies, control codes, and template-based generation. The paper also discusses the growing importance of fairness, human-AI collaboration, and low-resource adaptation. In 2020 and 2021, contextual prompting and transfer learning gained prominence, while 2022 and 2023 witnessed the emergence of advanced techniques like unsupervised pre-training and novel reward shaping. Throughout the paper, we reference specific research studies that exemplify the impact of various developments on prompt engineering. The journey of prompt engineering continues, with ethical considerations being paramount for the responsible and inclusive future of AI systems.
The Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes
Sep 30, 2023
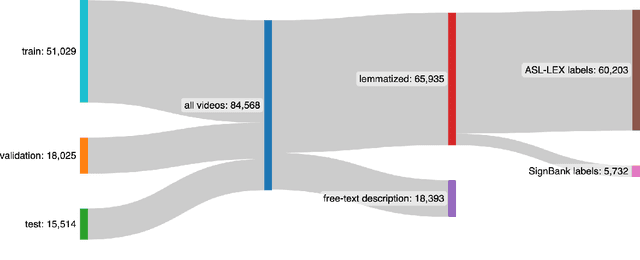
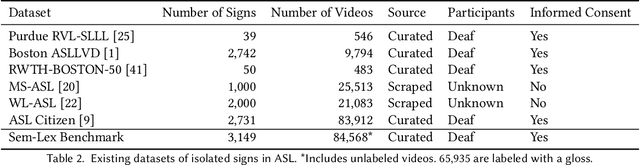
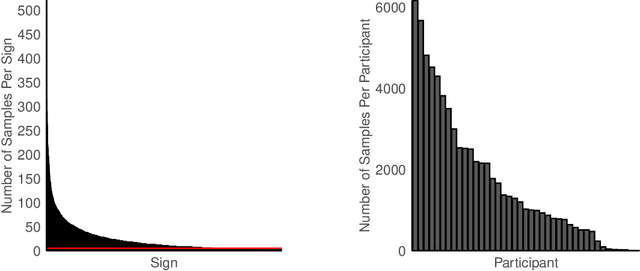
Sign language recognition and translation technologies have the potential to increase access and inclusion of deaf signing communities, but research progress is bottlenecked by a lack of representative data. We introduce a new resource for American Sign Language (ASL) modeling, the Sem-Lex Benchmark. The Benchmark is the current largest of its kind, consisting of over 84k videos of isolated sign productions from deaf ASL signers who gave informed consent and received compensation. Human experts aligned these videos with other sign language resources including ASL-LEX, SignBank, and ASL Citizen, enabling useful expansions for sign and phonological feature recognition. We present a suite of experiments which make use of the linguistic information in ASL-LEX, evaluating the practicality and fairness of the Sem-Lex Benchmark for isolated sign recognition (ISR). We use an SL-GCN model to show that the phonological features are recognizable with 85% accuracy, and that they are effective as an auxiliary target to ISR. Learning to recognize phonological features alongside gloss results in a 6% improvement for few-shot ISR accuracy and a 2% improvement for ISR accuracy overall. Instructions for downloading the data can be found at https://github.com/leekezar/SemLex.
Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
Sep 20, 2023
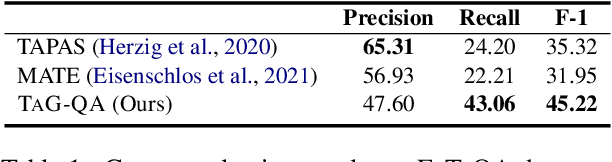
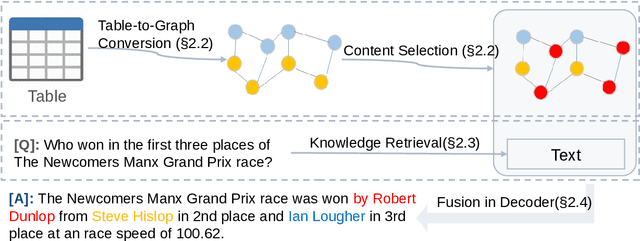
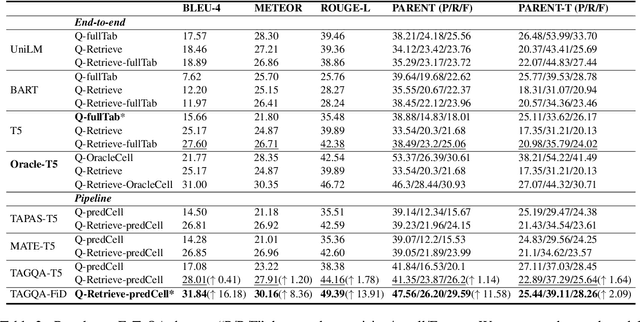
Question answering on tabular data (TableQA), which aims at generating answers to questions grounded on a given table, has attracted increasing attention in recent years. Existing work tends to generate factual short-form answers by extracting information from one or a few table cells without reasoning over selected table cells. However, the free-form TableQA, requiring a more complex relevant table cell selection strategy and the complex integration and inference of separate pieces of information, has been under-explored. To this end, this paper proposes a generalized three-stage approach: Table-to-Graph conversion and cell localizing, external knowledge retrieval and table-text fusion (called TAG-QA), addressing the challenge of inferring long free-form answer for generative TableQA. In particular, TAG-QA (1) locates relevant table cells using a graph neural network to gather intersecting cells between relevant rows and columns; (2) leverages external knowledge from Wikipedia and (3) generates answers by integrating both tabular data and natural linguistic information. Experiments with a human evaluation demonstrate that TAG-QA is capable of generating more faithful and coherent sentence when compared with several state-of-the-art baselines. Especially, TAG-QA outperforms the strong pipeline-based baseline TAPAS by 17% and 14%, in terms of BLEU-4 and PARENT F-score, respectively. Moreover, TAG-QA outperforms end-to-end model T5 by 16% and 12% on BLEU-4 and PARENT F-score.
"AI enhances our performance, I have no doubt this one will do the same": The Placebo effect is robust to negative descriptions of AI
Sep 28, 2023Heightened AI expectations facilitate performance in human-AI interactions through placebo effects. While lowering expectations to control for placebo effects is advisable, overly negative expectations could induce nocebo effects. In a letter discrimination task, we informed participants that an AI would either increase or decrease their performance by adapting the interface, but in reality, no AI was present in any condition. A Bayesian analysis showed that participants had high expectations and performed descriptively better irrespective of the AI description when a sham-AI was present. Using cognitive modeling, we could trace this advantage back to participants gathering more information. A replication study verified that negative AI descriptions do not alter expectations, suggesting that performance expectations with AI are biased and robust to negative verbal descriptions. We discuss the impact of user expectations on AI interactions and evaluation and provide a behavioral placebo marker for human-AI interaction
Constructing Synthetic Treatment Groups without the Mean Exchangeability Assumption
Sep 28, 2023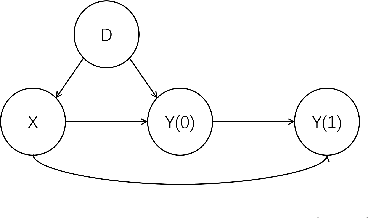


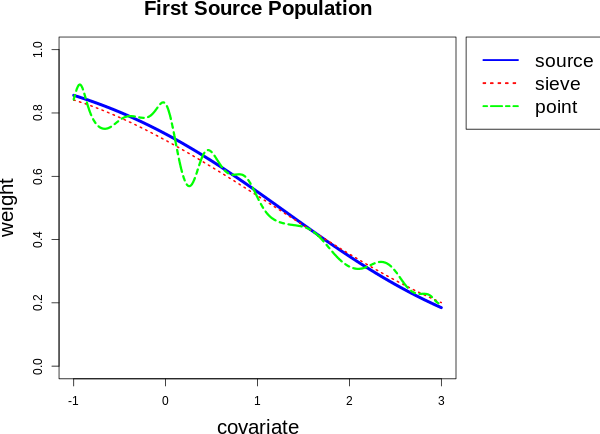
The purpose of this work is to transport the information from multiple randomized controlled trials to the target population where we only have the control group data. Previous works rely critically on the mean exchangeability assumption. However, as pointed out by many current studies, the mean exchangeability assumption might be violated. Motivated by the synthetic control method, we construct a synthetic treatment group for the target population by a weighted mixture of treatment groups of source populations. We estimate the weights by minimizing the conditional maximum mean discrepancy between the weighted control groups of source populations and the target population. We establish the asymptotic normality of the synthetic treatment group estimator based on the sieve semiparametric theory. Our method can serve as a novel complementary approach when the mean exchangeability assumption is violated. Experiments are conducted on synthetic and real-world datasets to demonstrate the effectiveness of our methods.
Forgetting Private Textual Sequences in Language Models via Leave-One-Out Ensemble
Sep 28, 2023Recent research has shown that language models have a tendency to memorize rare or unique token sequences in the training corpus. After deploying a model, practitioners might be asked to delete any personal information from the model by individuals' requests. Re-training the underlying model every time individuals would like to practice their rights to be forgotten is computationally expensive. We employ a teacher-student framework and propose a novel leave-one-out ensemble method to unlearn the targeted textual sequences that need to be forgotten from the model. In our approach, multiple teachers are trained on disjoint sets; for each targeted sequence to be removed, we exclude the teacher trained on the set containing this sequence and aggregate the predictions from remaining teachers to provide supervision during fine-tuning. Experiments on LibriSpeech and WikiText-103 datasets show that the proposed method achieves superior privacy-utility trade-offs than other counterparts.
SUIT: Learning Significance-guided Information for 3D Temporal Detection
Jul 04, 2023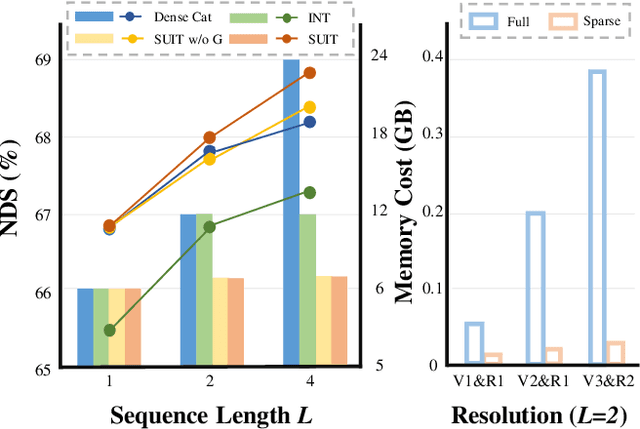
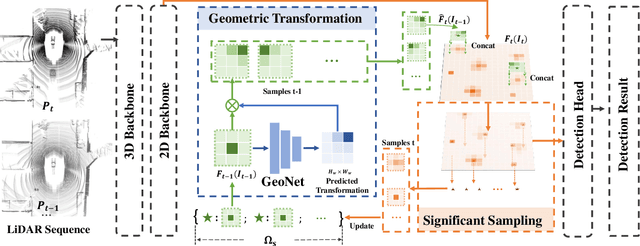
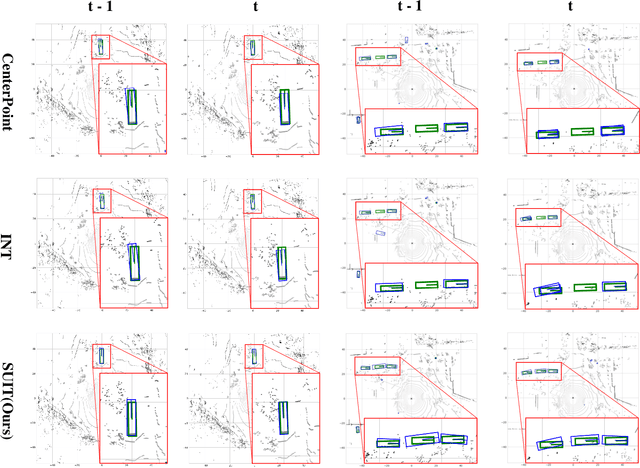

3D object detection from LiDAR point cloud is of critical importance for autonomous driving and robotics. While sequential point cloud has the potential to enhance 3D perception through temporal information, utilizing these temporal features effectively and efficiently remains a challenging problem. Based on the observation that the foreground information is sparsely distributed in LiDAR scenes, we believe sufficient knowledge can be provided by sparse format rather than dense maps. To this end, we propose to learn Significance-gUided Information for 3D Temporal detection (SUIT), which simplifies temporal information as sparse features for information fusion across frames. Specifically, we first introduce a significant sampling mechanism that extracts information-rich yet sparse features based on predicted object centroids. On top of that, we present an explicit geometric transformation learning technique, which learns the object-centric transformations among sparse features across frames. We evaluate our method on large-scale nuScenes and Waymo dataset, where our SUIT not only significantly reduces the memory and computation cost of temporal fusion, but also performs well over the state-of-the-art baselines.
Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird's-Eye View
Sep 27, 2023By exploiting complementary sensor information, radar and camera fusion systems have the potential to provide a highly robust and reliable perception system for advanced driver assistance systems and automated driving functions. Recent advances in camera-based object detection offer new radar-camera fusion possibilities with bird's eye view feature maps. In this work, we propose a novel and flexible fusion network and evaluate its performance on two datasets: nuScenes and View-of-Delft. Our experiments reveal that while the camera branch needs large and diverse training data, the radar branch benefits more from a high-performance radar. Using transfer learning, we improve the camera's performance on the smaller dataset. Our results further demonstrate that the radar-camera fusion approach significantly outperforms the camera-only and radar-only baselines.
PDE Discovery for Soft Sensors Using Coupled Physics-Informed Neural Network with Akaike's Information Criterion
Aug 11, 2023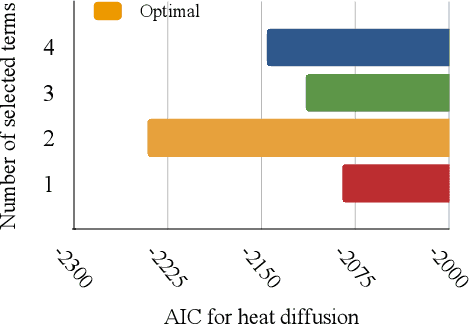
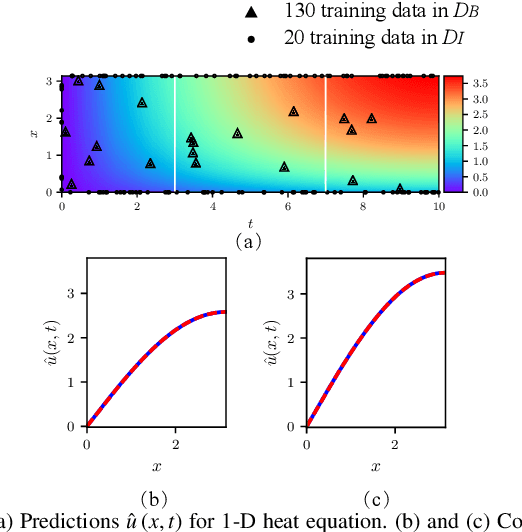
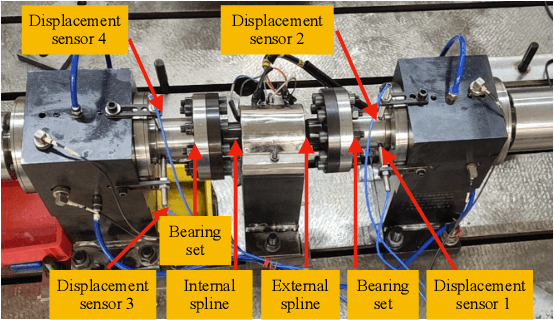
Soft sensors have been extensively used to monitor key variables using easy-to-measure variables and mathematical models. Partial differential equations (PDEs) are model candidates for soft sensors in industrial processes with spatiotemporal dependence. However, gaps often exist between idealized PDEs and practical situations. Discovering proper structures of PDEs, including the differential operators and source terms, can remedy the gaps. To this end, a coupled physics-informed neural network with Akaike's criterion information (CPINN-AIC) is proposed for PDE discovery of soft sensors. First, CPINN is adopted for obtaining solutions and source terms satisfying PDEs. Then, we propose a data-physics-hybrid loss function for training CPINN, in which undetermined combinations of differential operators are involved. Consequently, AIC is used to discover the proper combination of differential operators. Finally, the artificial and practical datasets are used to verify the feasibility and effectiveness of CPINN-AIC for soft sensors. The proposed CPINN-AIC is a data-driven method to discover proper PDE structures and neural network-based solutions for soft sensors.
CvFormer: Cross-view transFormers with Pre-training for fMRI Analysis of Human Brain
Sep 14, 2023In recent years, functional magnetic resonance imaging (fMRI) has been widely utilized to diagnose neurological disease, by exploiting the region of interest (RoI) nodes as well as their connectivities in human brain. However, most of existing works only rely on either RoIs or connectivities, neglecting the potential for complementary information between them. To address this issue, we study how to discover the rich cross-view information in fMRI data of human brain. This paper presents a novel method for cross-view analysis of fMRI data of the human brain, called Cross-view transFormers (CvFormer). CvFormer employs RoI and connectivity encoder modules to generate two separate views of the human brain, represented as RoI and sub-connectivity tokens. Then, basic transformer modules can be used to process the RoI and sub-connectivity tokens, and cross-view modules integrate the complement information across two views. Furthermore, CvFormer uses a global token for each branch as a query to exchange information with other branches in cross-view modules, which only requires linear time for both computational and memory complexity instead of quadratic time. To enhance the robustness of the proposed CvFormer, we propose a two-stage strategy to train its parameters. To be specific, RoI and connectivity views can be firstly utilized as self-supervised information to pre-train the CvFormer by combining it with contrastive learning and then fused to finetune the CvFormer using label information. Experiment results on two public ABIDE and ADNI datasets can show clear improvements by the proposed CvFormer, which can validate its effectiveness and superiority.