 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sparse and Privacy-enhanced Representation for Human Pose Estimation
Sep 18, 2023
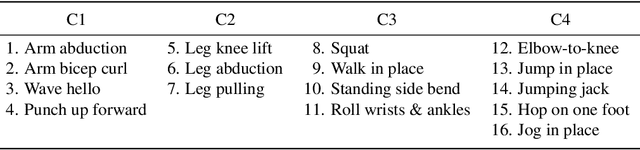
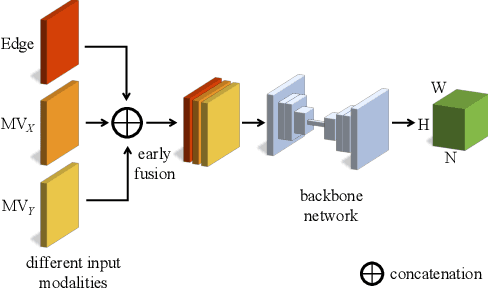
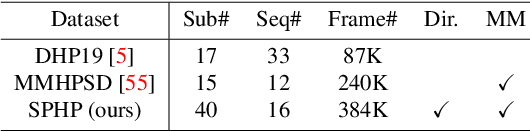
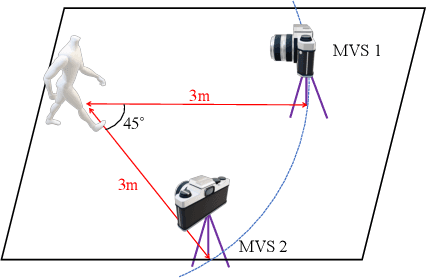
We propose a sparse and privacy-enhanced representation for Human Pose Estimation (HPE). Given a perspective camera, we use a proprietary motion vector sensor(MVS) to extract an edge image and a two-directional motion vector image at each time frame. Both edge and motion vector images are sparse and contain much less information (i.e., enhancing human privacy). We advocate that edge information is essential for HPE, and motion vectors complement edge information during fast movements. We propose a fusion network leveraging recent advances in sparse convolution used typically for 3D voxels to efficiently process our proposed sparse representation, which achieves about 13x speed-up and 96% reduction in FLOPs. We collect an in-house edge and motion vector dataset with 16 types of actions by 40 users using the proprietary MVS. Our method outperforms individual modalities using only edge or motion vector images. Finally, we validate the privacy-enhanced quality of our sparse representation through face recognition on CelebA (a large face dataset) and a user study on our in-house dataset.
Discovering Sounding Objects by Audio Queries for Audio Visual Segmentation
Sep 18, 2023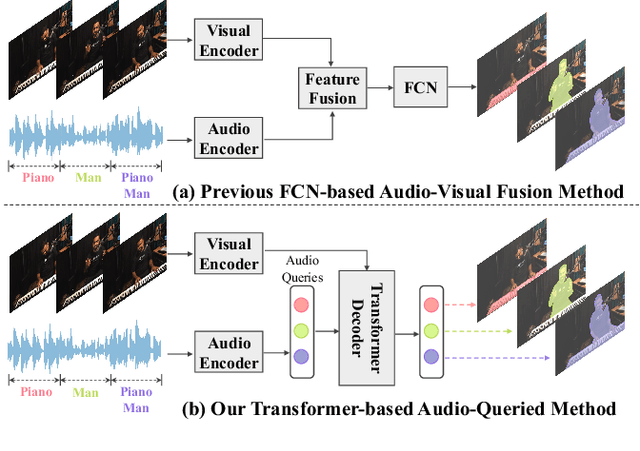
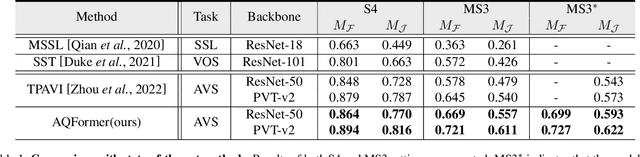
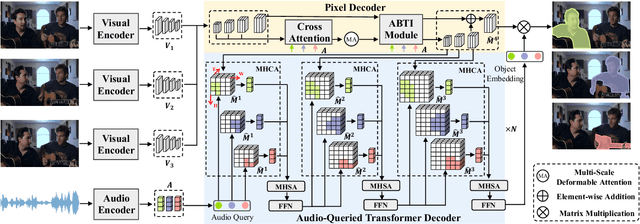

Audio visual segmentation (AVS) aims to segment the sounding objects for each frame of a given video. To distinguish the sounding objects from silent ones, both audio-visual semantic correspondence and temporal interaction are required. The previous method applies multi-frame cross-modal attention to conduct pixel-level interactions between audio features and visual features of multiple frames simultaneously, which is both redundant and implicit. In this paper, we propose an Audio-Queried Transformer architecture, AQFormer, where we define a set of object queries conditioned on audio information and associate each of them to particular sounding objects. Explicit object-level semantic correspondence between audio and visual modalities is established by gathering object information from visual features with predefined audio queries. Besides, an Audio-Bridged Temporal Interaction module is proposed to exchange sounding object-relevant information among multiple frames with the bridge of audio features. Extensive experiments are conducted on two AVS benchmarks to show that our method achieves state-of-the-art performances, especially 7.1% M_J and 7.6% M_F gains on the MS3 setting.
Intelligent machines work in unstructured environments by differential neural computing
Sep 16, 2023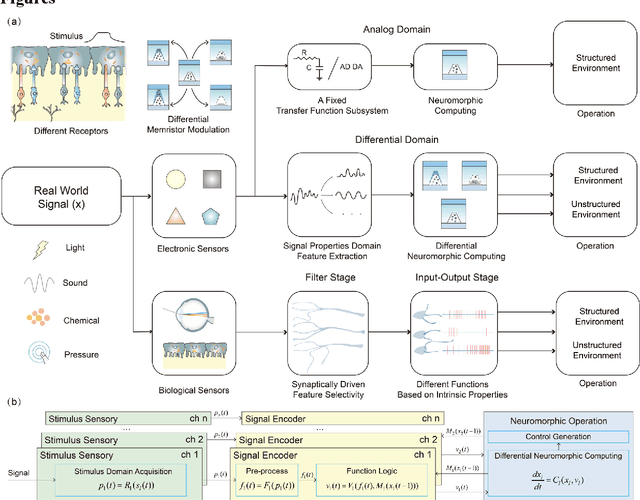
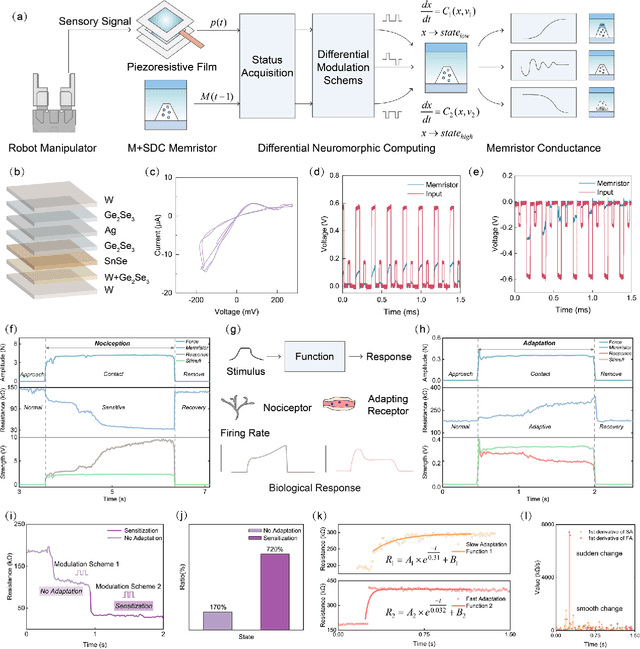
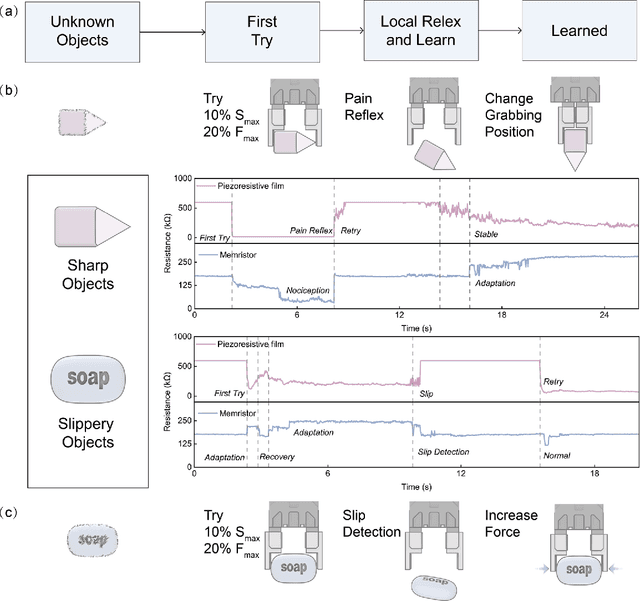
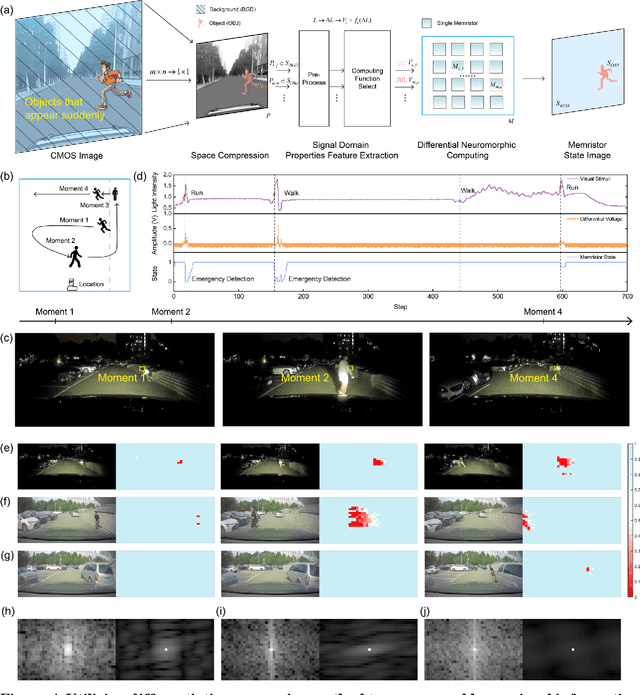
Expecting intelligent machines to efficiently work in real world requires a new method to understand unstructured information in unknown environments with good accuracy, scalability and generalization, like human. Here, a memristive neural computing based perceptual signal differential processing and learning method for intelligent machines is presented, via extracting main features of environmental information and applying associated encoded stimuli to memristors, we successfully obtain human-like ability in processing unstructured environmental information, such as amplification (>720%) and adaptation (<50%) of mechanical stimuli. The method also exhibits good scalability and generalization, validated in two typical applications of intelligent machines: object grasping and autonomous driving. In the former, a robot hand experimentally realizes safe and stable grasping, through learning unknown object features (e.g., sharp corner and smooth surface) with a single memristor in 1 ms. In the latter, the decision-making information of 10 unstructured environments in autonomous driving (e.g., overtaking cars, pedestrians) are accurately (94%) extracted with a 40x25 memristor array. By mimicking the intrinsic nature of human low-level perception mechanisms in electronic memristive neural circuits, the proposed method is adaptable to diverse sensing technologies, helping intelligent machines to generate smart high-level decisions in real world.
American Family Cohort, a data resource description
Sep 22, 2023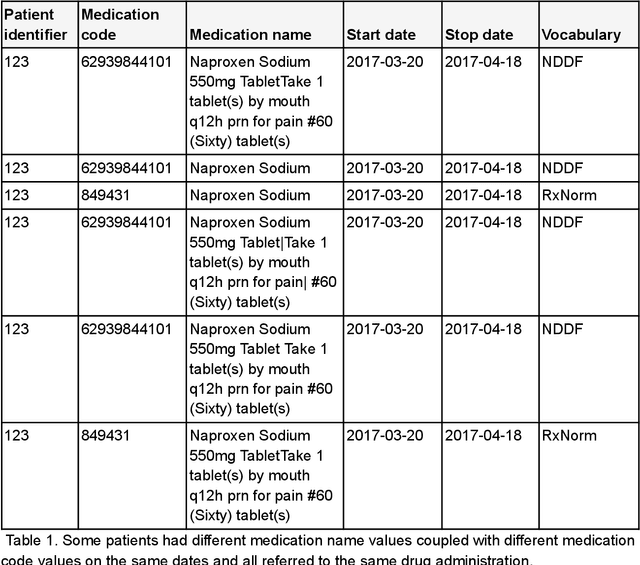

This manuscript is a research resource description and presents a large and novel Electronic Health Records (EHR) data resource, American Family Cohort (AFC). The AFC data is derived from Centers for Medicare and Medicaid Services (CMS) certified American Board of Family Medicine (ABFM) PRIME registry. The PRIME registry is the largest national Qualified Clinical Data Registry (QCDR) for Primary Care. The data is converted to a popular common data model, the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM). The resource presents approximately 90 million encounters for 7.5 million patients. All 100% of the patients present age, gender, and address information, and 73% report race. Nealy 93% of patients have lab data in LOINC, 86% have medication data in RxNorm, 93% have diagnosis in SNOWMED and ICD, 81% have procedures in HCPCS or CPT, and 61% have insurance information. The richness, breadth, and diversity of this research accessible and research ready data is expected to accelerate observational studies in many diverse areas. We expect this resource to facilitate research in many years to come.
Class Incremental Learning via Likelihood Ratio Based Task Prediction
Oct 01, 2023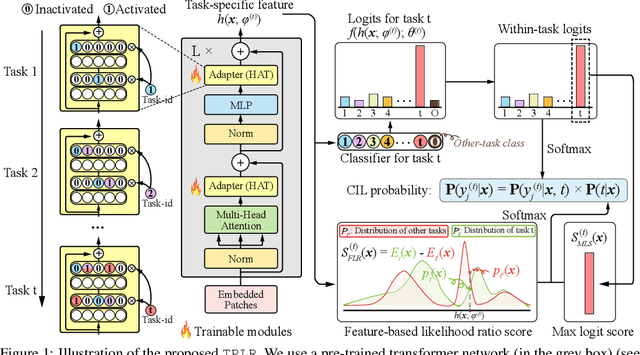
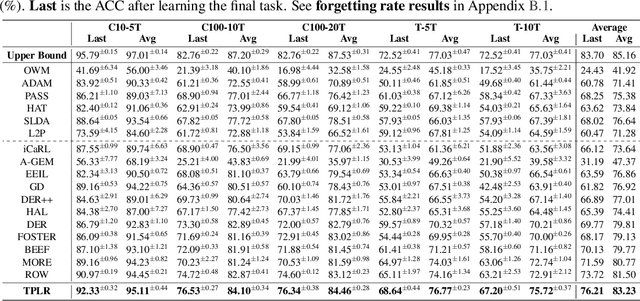
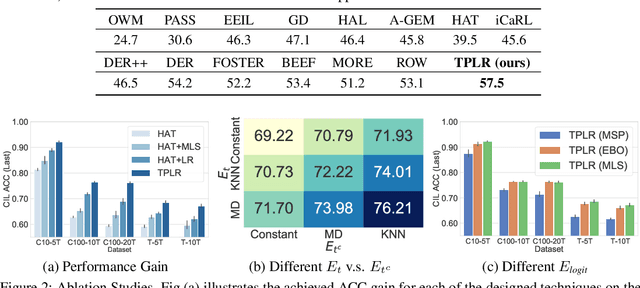
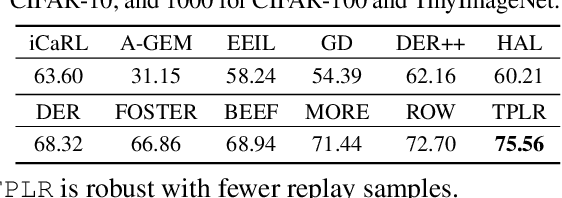
Class incremental learning (CIL) is a challenging setting of continual learning, which learns a series of tasks sequentially. Each task consists of a set of unique classes. The key feature of CIL is that no task identifier (or task-id) is provided at test time for each test sample. Predicting the task-id for each test sample is a challenging problem. An emerging theoretically justified and effective approach is to train a task-specific model for each task in a shared network for all tasks based on a task-incremental learning (TIL) method to deal with forgetting. The model for each task in this approach is an out-of-distribution (OOD) detector rather than a conventional classifier. The OOD detector can perform both within-task (in-distribution (IND)) class prediction and OOD detection. The OOD detection capability is the key for task-id prediction during inference for each test sample. However, this paper argues that using a traditional OOD detector for task-id prediction is sub-optimal because additional information (e.g., the replay data and the learned tasks) available in CIL can be exploited to design a better and principled method for task-id prediction. We call the new method TPLR (Task-id Prediction based on Likelihood Ratio}). TPLR markedly outperforms strong CIL baselines.
GhostEncoder: Stealthy Backdoor Attacks with Dynamic Triggers to Pre-trained Encoders in Self-supervised Learning
Oct 01, 2023

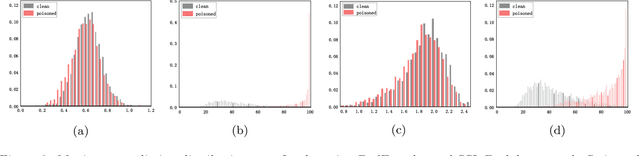
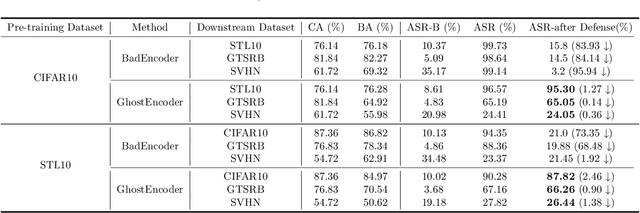
Within the realm of computer vision, self-supervised learning (SSL) pertains to training pre-trained image encoders utilizing a substantial quantity of unlabeled images. Pre-trained image encoders can serve as feature extractors, facilitating the construction of downstream classifiers for various tasks. However, the use of SSL has led to an increase in security research related to various backdoor attacks. Currently, the trigger patterns used in backdoor attacks on SSL are mostly visible or static (sample-agnostic), making backdoors less covert and significantly affecting the attack performance. In this work, we propose GhostEncoder, the first dynamic invisible backdoor attack on SSL. Unlike existing backdoor attacks on SSL, which use visible or static trigger patterns, GhostEncoder utilizes image steganography techniques to encode hidden information into benign images and generate backdoor samples. We then fine-tune the pre-trained image encoder on a manipulation dataset to inject the backdoor, enabling downstream classifiers built upon the backdoored encoder to inherit the backdoor behavior for target downstream tasks. We evaluate GhostEncoder on three downstream tasks and results demonstrate that GhostEncoder provides practical stealthiness on images and deceives the victim model with a high attack success rate without compromising its utility. Furthermore, GhostEncoder withstands state-of-the-art defenses, including STRIP, STRIP-Cl, and SSL-Cleanse.
FELM: Benchmarking Factuality Evaluation of Large Language Models
Oct 01, 2023Assessing factuality of text generated by large language models (LLMs) is an emerging yet crucial research area, aimed at alerting users to potential errors and guiding the development of more reliable LLMs. Nonetheless, the evaluators assessing factuality necessitate suitable evaluation themselves to gauge progress and foster advancements. This direction remains under-explored, resulting in substantial impediments to the progress of factuality evaluators. To mitigate this issue, we introduce a benchmark for Factuality Evaluation of large Language Models, referred to as felm. In this benchmark, we collect responses generated from LLMs and annotate factuality labels in a fine-grained manner. Contrary to previous studies that primarily concentrate on the factuality of world knowledge (e.g.~information from Wikipedia), felm focuses on factuality across diverse domains, spanning from world knowledge to math and reasoning. Our annotation is based on text segments, which can help pinpoint specific factual errors. The factuality annotations are further supplemented by predefined error types and reference links that either support or contradict the statement. In our experiments, we investigate the performance of several LLM-based factuality evaluators on felm, including both vanilla LLMs and those augmented with retrieval mechanisms and chain-of-thought processes. Our findings reveal that while retrieval aids factuality evaluation, current LLMs are far from satisfactory to faithfully detect factual errors.
Uncertainty-aware hybrid paradigm of nonlinear MPC and model-based RL for offroad navigation: Exploration of transformers in the predictive model
Oct 01, 2023
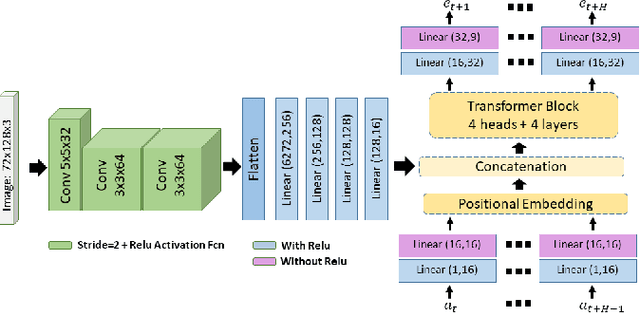
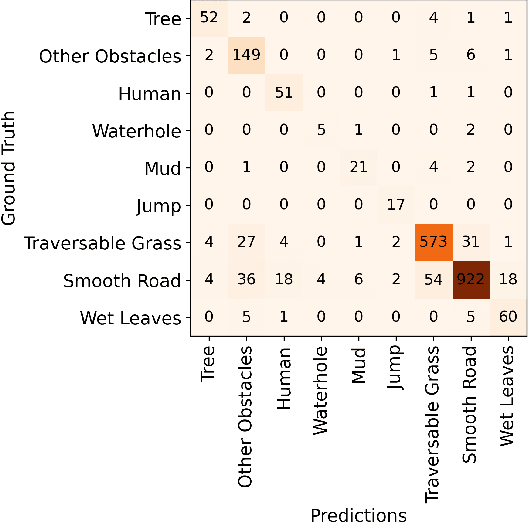
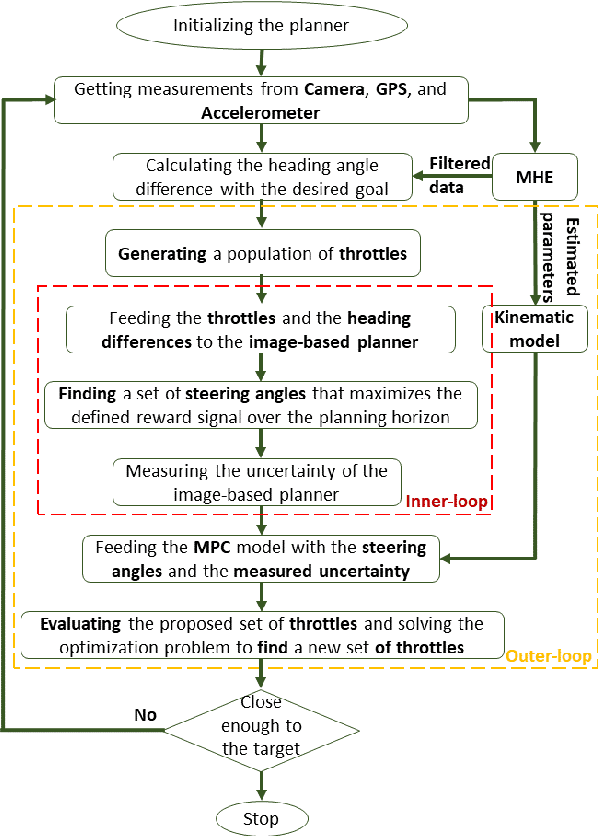
In this paper, we investigate a hybrid scheme that combines nonlinear model predictive control (MPC) and model-based reinforcement learning (RL) for navigation planning of an autonomous model car across offroad, unstructured terrains without relying on predefined maps. Our innovative approach takes inspiration from BADGR, an LSTM-based network that primarily concentrates on environment modeling, but distinguishes itself by substituting LSTM modules with transformers to greatly elevate the performance our model. Addressing uncertainty within the system, we train an ensemble of predictive models and estimate the mutual information between model weights and outputs, facilitating dynamic horizon planning through the introduction of variable speeds. Further enhancing our methodology, we incorporate a nonlinear MPC controller that accounts for the intricacies of the vehicle's model and states. The model-based RL facet produces steering angles and quantifies inherent uncertainty. At the same time, the nonlinear MPC suggests optimal throttle settings, striking a balance between goal attainment speed and managing model uncertainty influenced by velocity. In the conducted studies, our approach excels over the existing baseline by consistently achieving higher metric values in predicting future events and seamlessly integrating the vehicle's kinematic model for enhanced decision-making. The code and the evaluation data are available at https://github.com/FARAZLOTFI/offroad_autonomous_navigation/).
Towards using Cough for Respiratory Disease Diagnosis by leveraging Artificial Intelligence: A Survey
Sep 24, 2023
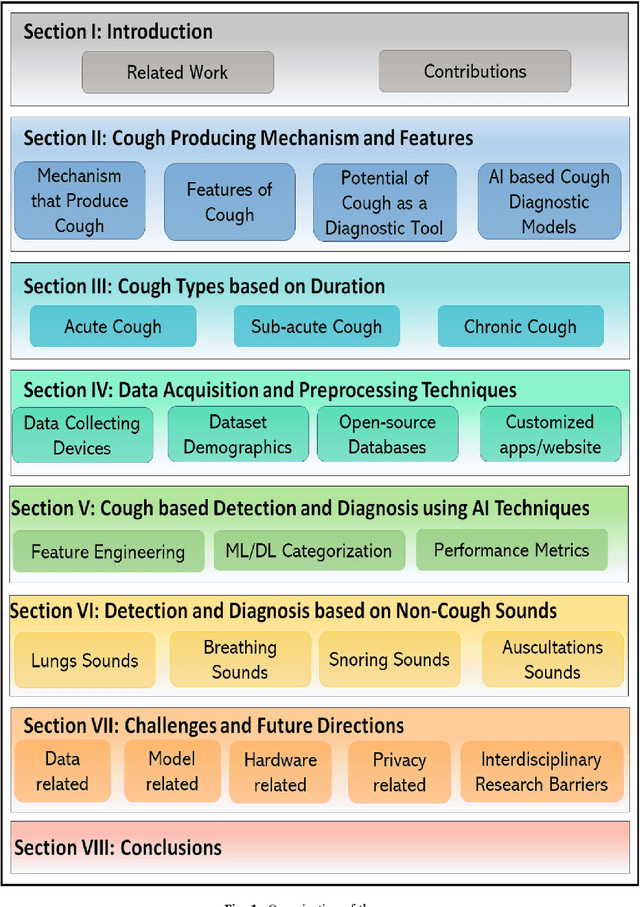
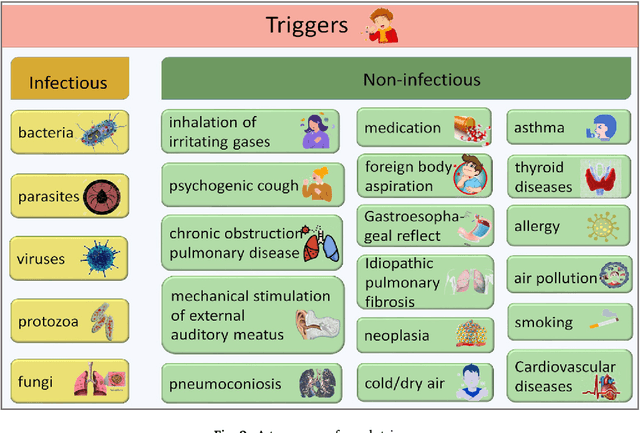
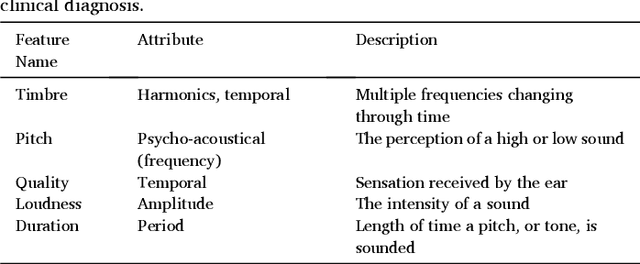
Cough acoustics contain multitudes of vital information about pathomorphological alterations in the respiratory system. Reliable and accurate detection of cough events by investigating the underlying cough latent features and disease diagnosis can play an indispensable role in revitalizing the healthcare practices. The recent application of Artificial Intelligence (AI) and advances of ubiquitous computing for respiratory disease prediction has created an auspicious trend and myriad of future possibilities in the medical domain. In particular, there is an expeditiously emerging trend of Machine learning (ML) and Deep Learning (DL)-based diagnostic algorithms exploiting cough signatures. The enormous body of literature on cough-based AI algorithms demonstrate that these models can play a significant role for detecting the onset of a specific respiratory disease. However, it is pertinent to collect the information from all relevant studies in an exhaustive manner for the medical experts and AI scientists to analyze the decisive role of AI/ML. This survey offers a comprehensive overview of the cough data-driven ML/DL detection and preliminary diagnosis frameworks, along with a detailed list of significant features. We investigate the mechanism that causes cough and the latent cough features of the respiratory modalities. We also analyze the customized cough monitoring application, and their AI-powered recognition algorithms. Challenges and prospective future research directions to develop practical, robust, and ubiquitous solutions are also discussed in detail.
SUIT: Learning Significance-guided Information for 3D Temporal Detection
Jul 04, 2023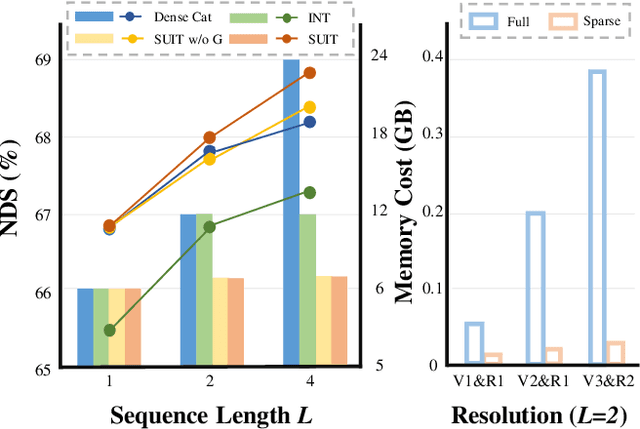
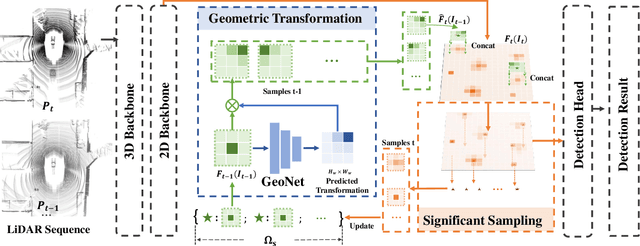
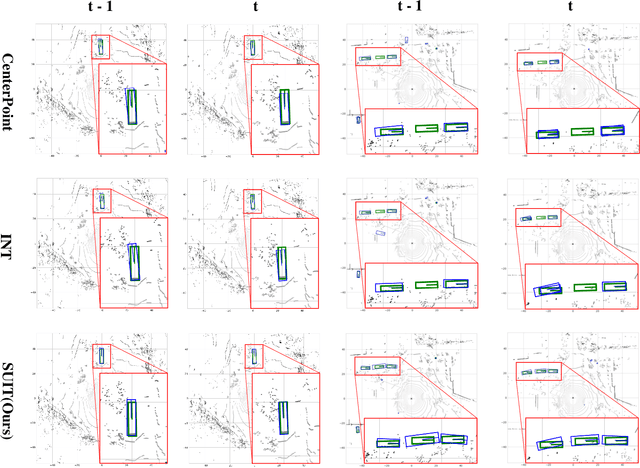

3D object detection from LiDAR point cloud is of critical importance for autonomous driving and robotics. While sequential point cloud has the potential to enhance 3D perception through temporal information, utilizing these temporal features effectively and efficiently remains a challenging problem. Based on the observation that the foreground information is sparsely distributed in LiDAR scenes, we believe sufficient knowledge can be provided by sparse format rather than dense maps. To this end, we propose to learn Significance-gUided Information for 3D Temporal detection (SUIT), which simplifies temporal information as sparse features for information fusion across frames. Specifically, we first introduce a significant sampling mechanism that extracts information-rich yet sparse features based on predicted object centroids. On top of that, we present an explicit geometric transformation learning technique, which learns the object-centric transformations among sparse features across frames. We evaluate our method on large-scale nuScenes and Waymo dataset, where our SUIT not only significantly reduces the memory and computation cost of temporal fusion, but also performs well over the state-of-the-art baselines.