 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Resolving References in Visually-Grounded Dialogue via Text Generation
Sep 23, 2023
Vision-language models (VLMs) have shown to be effective at image retrieval based on simple text queries, but text-image retrieval based on conversational input remains a challenge. Consequently, if we want to use VLMs for reference resolution in visually-grounded dialogue, the discourse processing capabilities of these models need to be augmented. To address this issue, we propose fine-tuning a causal large language model (LLM) to generate definite descriptions that summarize coreferential information found in the linguistic context of references. We then use a pretrained VLM to identify referents based on the generated descriptions, zero-shot. We evaluate our approach on a manually annotated dataset of visually-grounded dialogues and achieve results that, on average, exceed the performance of the baselines we compare against. Furthermore, we find that using referent descriptions based on larger context windows has the potential to yield higher returns.
Domain-Guided Conditional Diffusion Model for Unsupervised Domain Adaptation
Sep 23, 2023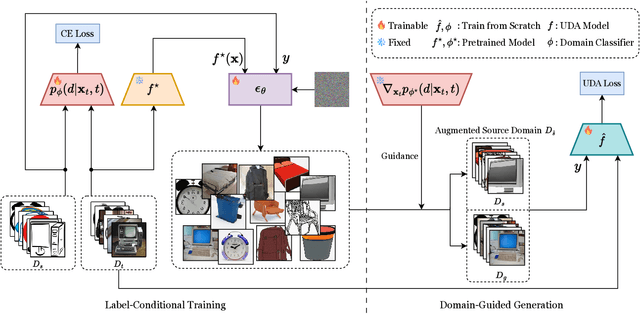
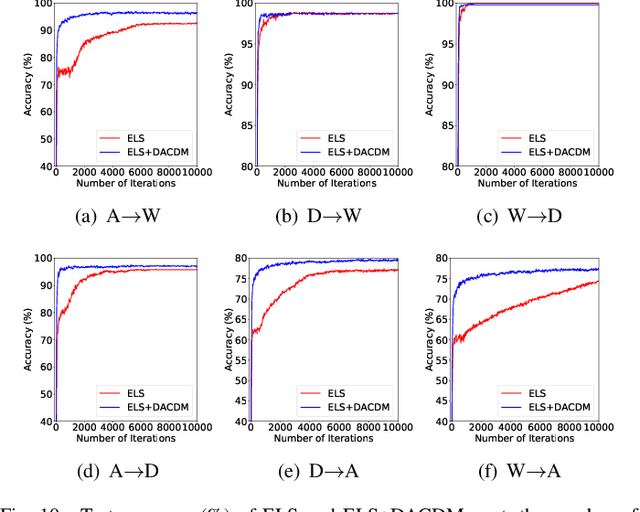
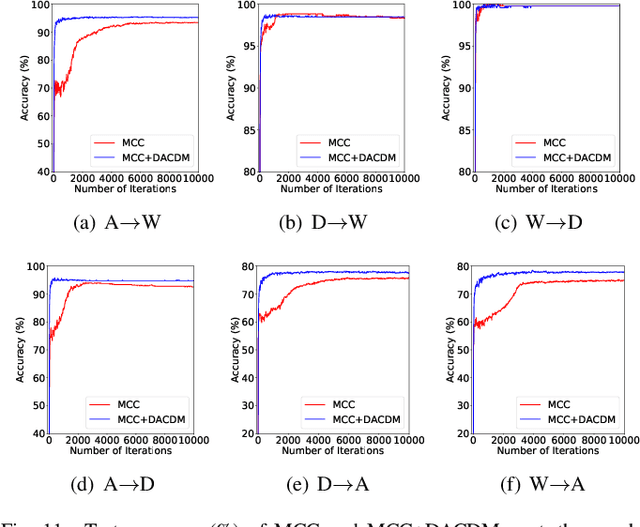
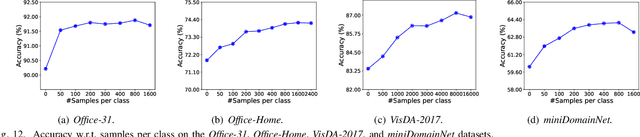
Limited transferability hinders the performance of deep learning models when applied to new application scenarios. Recently, Unsupervised Domain Adaptation (UDA) has achieved significant progress in addressing this issue via learning domain-invariant features. However, the performance of existing UDA methods is constrained by the large domain shift and limited target domain data. To alleviate these issues, we propose DomAin-guided Conditional Diffusion Model (DACDM) to generate high-fidelity and diversity samples for the target domain. In the proposed DACDM, by introducing class information, the labels of generated samples can be controlled, and a domain classifier is further introduced in DACDM to guide the generated samples for the target domain. The generated samples help existing UDA methods transfer from the source domain to the target domain more easily, thus improving the transfer performance. Extensive experiments on various benchmarks demonstrate that DACDM brings a large improvement to the performance of existing UDA methods.
Towards Robust and Efficient Communications for Urban Air Mobility
Sep 15, 2023For the realization of the future urban air mobility, reliable information exchange based on robust and efficient communication between all airspace participants will be one of the key factors to ensure safe operations. Especially in dense urban scenarios, the direct and fast information exchange between drones based on Drone-to-Drone communications is a promising technology for enabling reliable collision avoidance systems. However, to mitigate collisions and to increase overall reliability, unmanned aircraft still lack a redundant, higher-level safety net to coordinate and monitor traffic, as is common in today's civil aviation. In addition, direct and fast information exchange based on ad hoc communication is needed to cope with the very short reaction times required to avoid collisions and to cope with the the high traffic densities. Therefore, we are developing a \ac{d2d} communication and surveillance system, called DroneCAST, which is specifically tailored to the requirements of a future urban airspace and will be part of a multi-link approach. In this work we discuss challenges and expected safety-critical applications that will have to rely on communications for \ac{uam} and present our communication concept and necessary steps towards DroneCAST. As a first step towards an implementation, we equipped two drones with hardware prototypes of the experimental communication system and performed several flights around the model city to evaluate the performance of the hardware and to demonstrate different applications that will rely on robust and efficient communications.
Semantically Redundant Training Data Removal and Deep Model Classification Performance: A Study with Chest X-rays
Sep 18, 2023


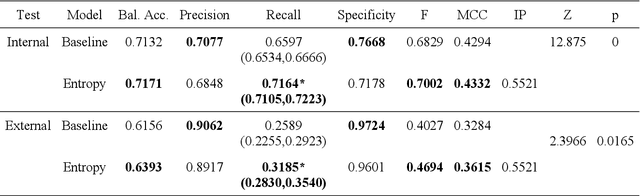
Deep learning (DL) has demonstrated its innate capacity to independently learn hierarchical features from complex and multi-dimensional data. A common understanding is that its performance scales up with the amount of training data. Another data attribute is the inherent variety. It follows, therefore, that semantic redundancy, which is the presence of similar or repetitive information, would tend to lower performance and limit generalizability to unseen data. In medical imaging data, semantic redundancy can occur due to the presence of multiple images that have highly similar presentations for the disease of interest. Further, the common use of augmentation methods to generate variety in DL training may be limiting performance when applied to semantically redundant data. We propose an entropy-based sample scoring approach to identify and remove semantically redundant training data. We demonstrate using the publicly available NIH chest X-ray dataset that the model trained on the resulting informative subset of training data significantly outperforms the model trained on the full training set, during both internal (recall: 0.7164 vs 0.6597, p<0.05) and external testing (recall: 0.3185 vs 0.2589, p<0.05). Our findings emphasize the importance of information-oriented training sample selection as opposed to the conventional practice of using all available training data.
In-IDE Generation-based Information Support with a Large Language Model
Jul 17, 2023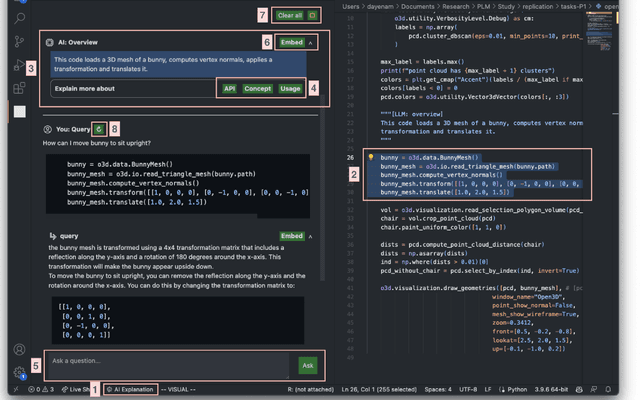

Developers often face challenges in code understanding, which is crucial for building and maintaining high-quality software systems. Code comments and documentation can provide some context for the code, but are often scarce or missing. This challenge has become even more pressing with the rise of large language model (LLM) based code generation tools. To understand unfamiliar code, most software developers rely on general-purpose search engines to search through various programming information resources, which often requires multiple iterations of query rewriting and information foraging. More recently, developers have turned to online chatbots powered by LLMs, such as ChatGPT, which can provide more customized responses but also incur more overhead as developers need to communicate a significant amount of context to the LLM via a textual interface. In this study, we provide the investigation of an LLM-based conversational UI in the IDE. We aim to understand the promises and obstacles for tools powered by LLMs that are contextually aware, in that they automatically leverage the developer's programming context to answer queries. To this end, we develop an IDE Plugin that allows users to query back-ends such as OpenAI's GPT-3.5 and GPT-4 with high-level requests, like: explaining a highlighted section of code, explaining key domain-specific terms, or providing usage examples for an API. We conduct an exploratory user study with 32 participants to understand the usefulness and effectiveness, as well as individual preferences in the usage of, this LLM-powered information support tool. The study confirms that this approach can aid code understanding more effectively than web search, but the degree of the benefit differed by participants' experience levels.
A Multi-Robot Task Assignment Framework for Search and Rescue with Heterogeneous Teams
Sep 22, 2023
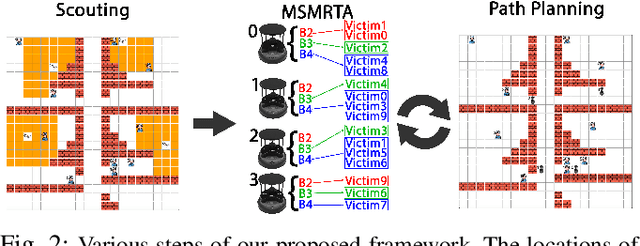
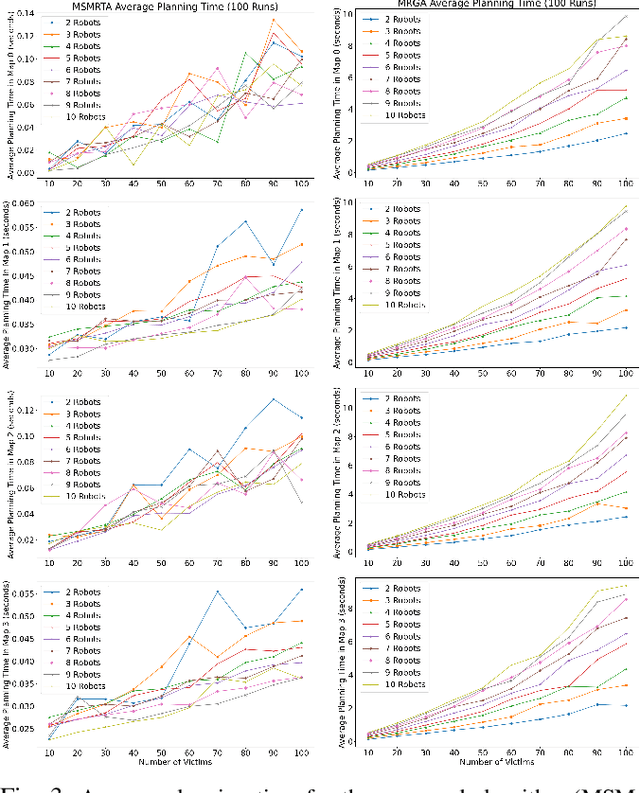

In post-disaster scenarios, efficient search and rescue operations involve collaborative efforts between robots and humans. Existing planning approaches focus on specific aspects but overlook crucial elements like information gathering, task assignment, and planning. Furthermore, previous methods considering robot capabilities and victim requirements suffer from time complexity due to repetitive planning steps. To overcome these challenges, we introduce a comprehensive framework__the Multi-Stage Multi-Robot Task Assignment. This framework integrates scouting, task assignment, and path-planning stages, optimizing task allocation based on robot capabilities, victim requirements, and past robot performance. Our iterative approach ensures objective fulfillment within problem constraints. Evaluation across four maps, comparing with a state-of-the-art baseline, demonstrates our algorithm's superiority with a remarkable 97 percent performance increase. Our code is open-sourced to enable result replication.
Memory-augmented conformer for improved end-to-end long-form ASR
Sep 22, 2023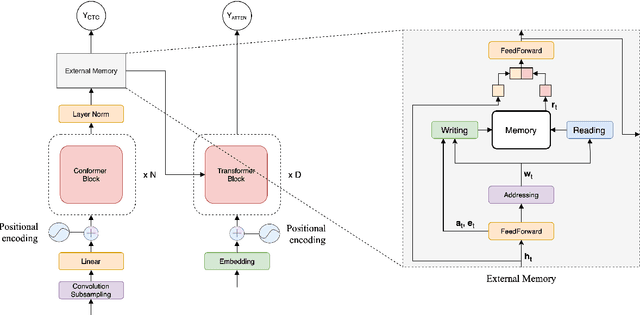
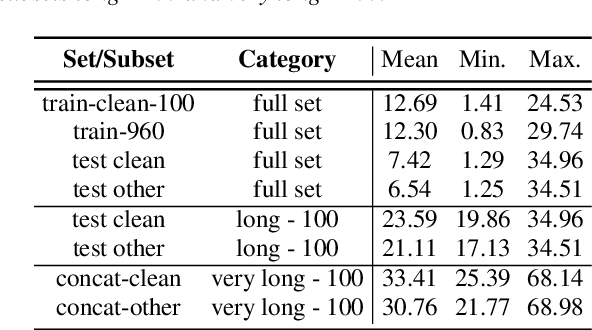
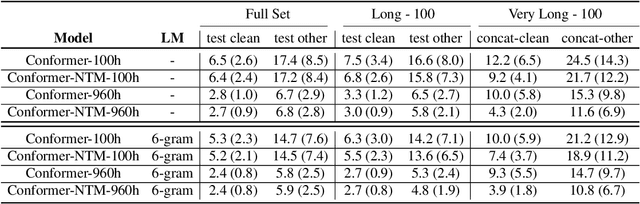
Conformers have recently been proposed as a promising modelling approach for automatic speech recognition (ASR), outperforming recurrent neural network-based approaches and transformers. Nevertheless, in general, the performance of these end-to-end models, especially attention-based models, is particularly degraded in the case of long utterances. To address this limitation, we propose adding a fully-differentiable memory-augmented neural network between the encoder and decoder of a conformer. This external memory can enrich the generalization for longer utterances since it allows the system to store and retrieve more information recurrently. Notably, we explore the neural Turing machine (NTM) that results in our proposed Conformer-NTM model architecture for ASR. Experimental results using Librispeech train-clean-100 and train-960 sets show that the proposed system outperforms the baseline conformer without memory for long utterances.
Streamlined Data Fusion: Unleashing the Power of Linear Combination with Minimal Relevance Judgments
Sep 21, 2023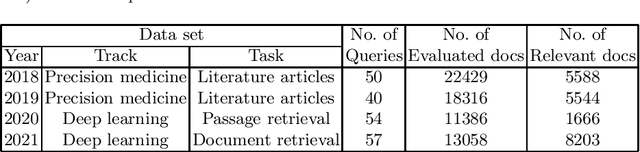
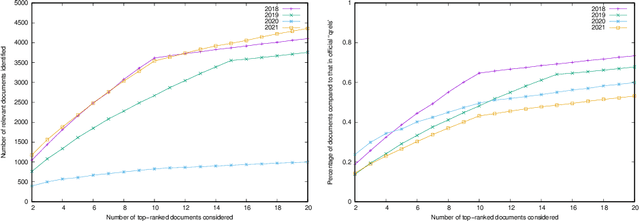
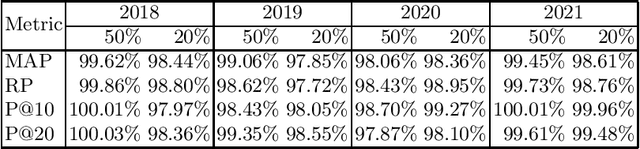
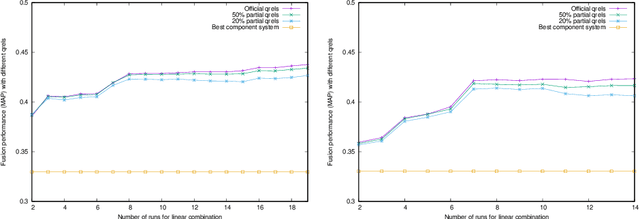
Linear combination is a potent data fusion method in information retrieval tasks, thanks to its ability to adjust weights for diverse scenarios. However, achieving optimal weight training has traditionally required manual relevance judgments on a large percentage of documents, a labor-intensive and expensive process. In this study, we investigate the feasibility of obtaining near-optimal weights using a mere 20\%-50\% of relevant documents. Through experiments on four TREC datasets, we find that weights trained with multiple linear regression using this reduced set closely rival those obtained with TREC's official "qrels." Our findings unlock the potential for more efficient and affordable data fusion, empowering researchers and practitioners to reap its full benefits with significantly less effort.
Learning Minimalistic Tsetlin Machine Clauses with Markov Boundary-Guided Pruning
Sep 12, 2023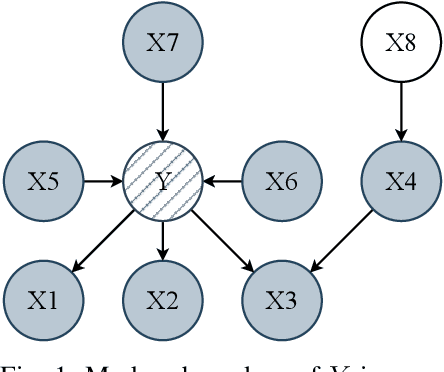


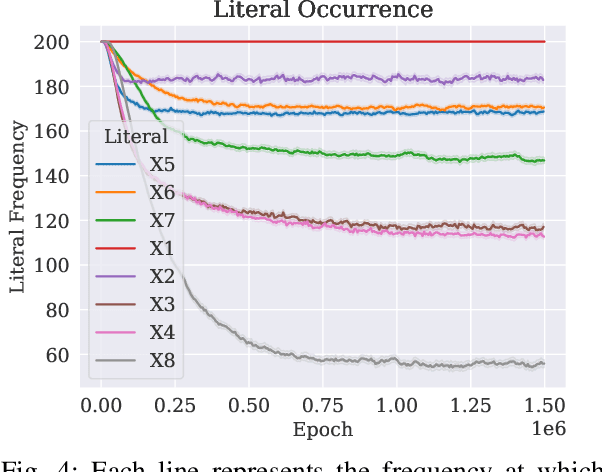
A set of variables is the Markov blanket of a random variable if it contains all the information needed for predicting the variable. If the blanket cannot be reduced without losing useful information, it is called a Markov boundary. Identifying the Markov boundary of a random variable is advantageous because all variables outside the boundary are superfluous. Hence, the Markov boundary provides an optimal feature set. However, learning the Markov boundary from data is challenging for two reasons. If one or more variables are removed from the Markov boundary, variables outside the boundary may start providing information. Conversely, variables within the boundary may stop providing information. The true role of each candidate variable is only manifesting when the Markov boundary has been identified. In this paper, we propose a new Tsetlin Machine (TM) feedback scheme that supplements Type I and Type II feedback. The scheme introduces a novel Finite State Automaton - a Context-Specific Independence Automaton. The automaton learns which features are outside the Markov boundary of the target, allowing them to be pruned from the TM during learning. We investigate the new scheme empirically, showing how it is capable of exploiting context-specific independence to find Markov boundaries. Further, we provide a theoretical analysis of convergence. Our approach thus connects the field of Bayesian networks (BN) with TMs, potentially opening up for synergies when it comes to inference and learning, including TM-produced Bayesian knowledge bases and TM-based Bayesian inference.
VoiceLDM: Text-to-Speech with Environmental Context
Sep 24, 2023This paper presents VoiceLDM, a model designed to produce audio that accurately follows two distinct natural language text prompts: the description prompt and the content prompt. The former provides information about the overall environmental context of the audio, while the latter conveys the linguistic content. To achieve this, we adopt a text-to-audio (TTA) model based on latent diffusion models and extend its functionality to incorporate an additional content prompt as a conditional input. By utilizing pretrained contrastive language-audio pretraining (CLAP) and Whisper, VoiceLDM is trained on large amounts of real-world audio without manual annotations or transcriptions. Additionally, we employ dual classifier-free guidance to further enhance the controllability of VoiceLDM. Experimental results demonstrate that VoiceLDM is capable of generating plausible audio that aligns well with both input conditions, even surpassing the speech intelligibility of the ground truth audio on the AudioCaps test set. Furthermore, we explore the text-to-speech (TTS) and zero-shot text-to-audio capabilities of VoiceLDM and show that it achieves competitive results. Demos and code are available at https://voiceldm.github.io.