 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Constructing a Knowledge Graph for Vietnamese Legal Cases with Heterogeneous Graphs
Sep 16, 2023
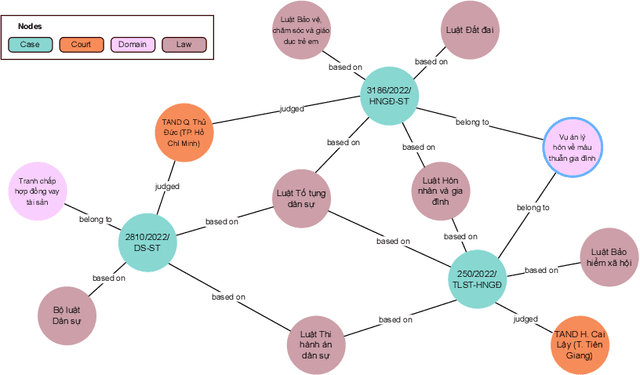

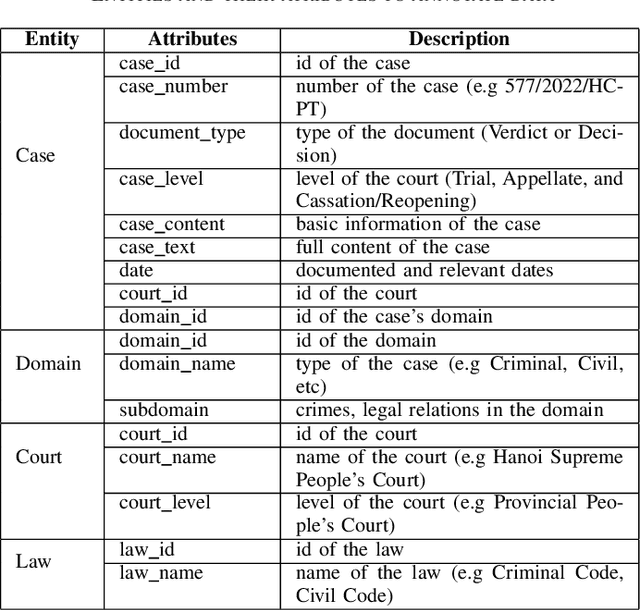
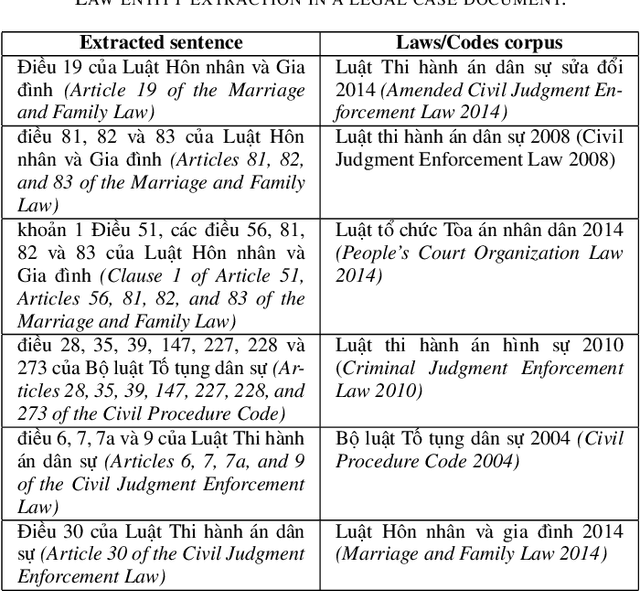
This paper presents a knowledge graph construction method for legal case documents and related laws, aiming to organize legal information efficiently and enhance various downstream tasks. Our approach consists of three main steps: data crawling, information extraction, and knowledge graph deployment. First, the data crawler collects a large corpus of legal case documents and related laws from various sources, providing a rich database for further processing. Next, the information extraction step employs natural language processing techniques to extract entities such as courts, cases, domains, and laws, as well as their relationships from the unstructured text. Finally, the knowledge graph is deployed, connecting these entities based on their extracted relationships, creating a heterogeneous graph that effectively represents legal information and caters to users such as lawyers, judges, and scholars. The established baseline model leverages unsupervised learning methods, and by incorporating the knowledge graph, it demonstrates the ability to identify relevant laws for a given legal case. This approach opens up opportunities for various applications in the legal domain, such as legal case analysis, legal recommendation, and decision support.
X-PDNet: Accurate Joint Plane Instance Segmentation and Monocular Depth Estimation with Cross-Task Distillation and Boundary Correction
Sep 24, 2023Segmentation of planar regions from a single RGB image is a particularly important task in the perception of complex scenes. To utilize both visual and geometric properties in images, recent approaches often formulate the problem as a joint estimation of planar instances and dense depth through feature fusion mechanisms and geometric constraint losses. Despite promising results, these methods do not consider cross-task feature distillation and perform poorly in boundary regions. To overcome these limitations, we propose X-PDNet, a framework for the multitask learning of plane instance segmentation and depth estimation with improvements in the following two aspects. Firstly, we construct the cross-task distillation design which promotes early information sharing between dual-tasks for specific task improvements. Secondly, we highlight the current limitations of using the ground truth boundary to develop boundary regression loss, and propose a novel method that exploits depth information to support precise boundary region segmentation. Finally, we manually annotate more than 3000 images from Stanford 2D-3D-Semantics dataset and make available for evaluation of plane instance segmentation. Through the experiments, our proposed methods prove the advantages, outperforming the baseline with large improvement margins in the quantitative results on the ScanNet and the Stanford 2D-3D-S dataset, demonstrating the effectiveness of our proposals.
Text Classification: A Perspective of Deep Learning Methods
Sep 24, 2023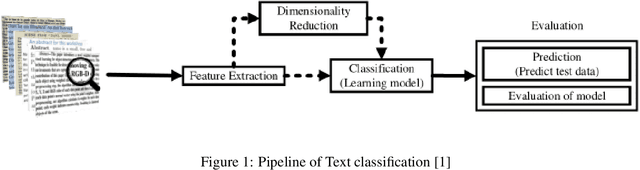
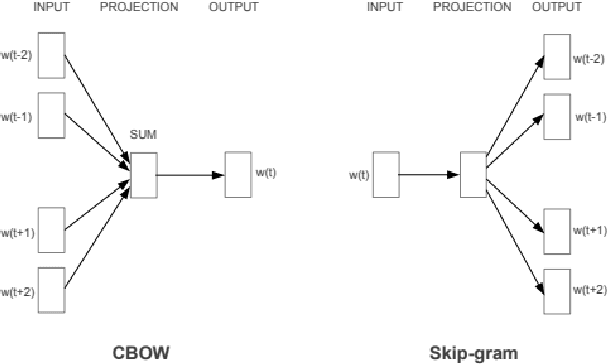
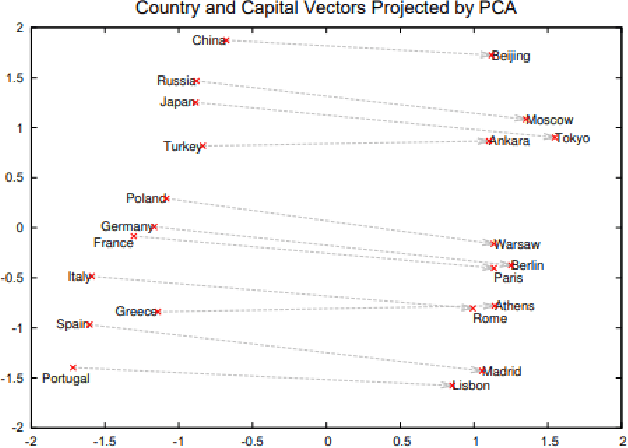
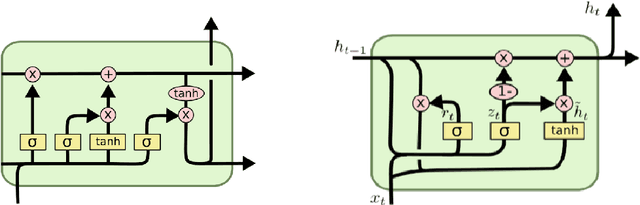
In recent years, with the rapid development of information on the Internet, the number of complex texts and documents has increased exponentially, which requires a deeper understanding of deep learning methods in order to accurately classify texts using deep learning techniques, and thus deep learning methods have become increasingly important in text classification. Text classification is a class of tasks that automatically classifies a set of documents into multiple predefined categories based on their content and subject matter. Thus, the main goal of text classification is to enable users to extract information from textual resources and process processes such as retrieval, classification, and machine learning techniques together in order to classify different categories. Many new techniques of deep learning have already achieved excellent results in natural language processing. The success of these learning algorithms relies on their ability to understand complex models and non-linear relationships in data. However, finding the right structure, architecture, and techniques for text classification is a challenge for researchers. This paper introduces deep learning-based text classification algorithms, including important steps required for text classification tasks such as feature extraction, feature reduction, and evaluation strategies and methods. At the end of the article, different deep learning text classification methods are compared and summarized.
Navigating Healthcare Insights: A Birds Eye View of Explainability with Knowledge Graphs
Sep 28, 2023Knowledge graphs (KGs) are gaining prominence in Healthcare AI, especially in drug discovery and pharmaceutical research as they provide a structured way to integrate diverse information sources, enhancing AI system interpretability. This interpretability is crucial in healthcare, where trust and transparency matter, and eXplainable AI (XAI) supports decision making for healthcare professionals. This overview summarizes recent literature on the impact of KGs in healthcare and their role in developing explainable AI models. We cover KG workflow, including construction, relationship extraction, reasoning, and their applications in areas like Drug-Drug Interactions (DDI), Drug Target Interactions (DTI), Drug Development (DD), Adverse Drug Reactions (ADR), and bioinformatics. We emphasize the importance of making KGs more interpretable through knowledge-infused learning in healthcare. Finally, we highlight research challenges and provide insights for future directions.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 19, 2023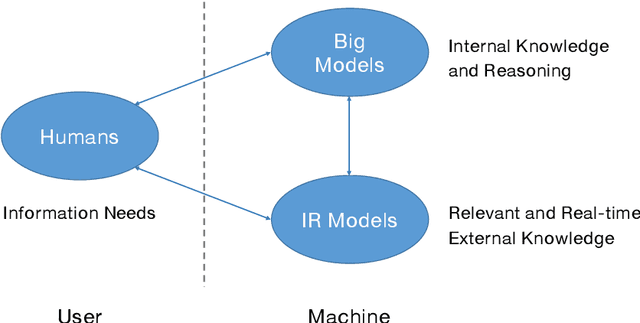
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
Local and Global Information in Obstacle Detection on Railway Tracks
Jul 28, 2023


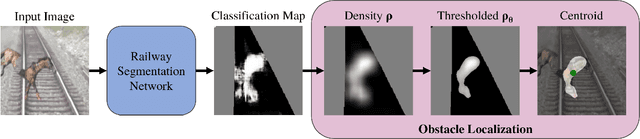
Reliable obstacle detection on railways could help prevent collisions that result in injuries and potentially damage or derail the train. Unfortunately, generic object detectors do not have enough classes to account for all possible scenarios, and datasets featuring objects on railways are challenging to obtain. We propose utilizing a shallow network to learn railway segmentation from normal railway images. The limited receptive field of the network prevents overconfident predictions and allows the network to focus on the locally very distinct and repetitive patterns of the railway environment. Additionally, we explore the controlled inclusion of global information by learning to hallucinate obstacle-free images. We evaluate our method on a custom dataset featuring railway images with artificially augmented obstacles. Our proposed method outperforms other learning-based baseline methods.
AutoAM: An End-To-End Neural Model for Automatic and Universal Argument Mining
Sep 17, 2023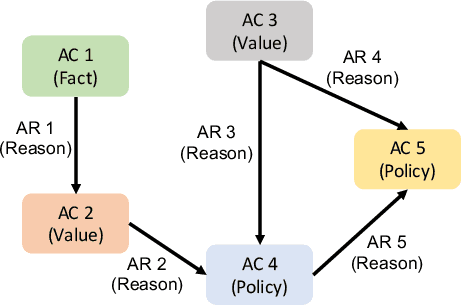
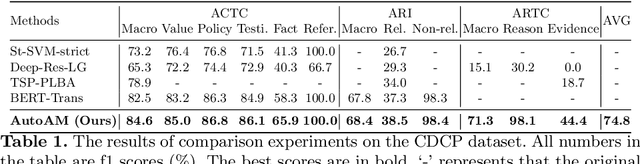
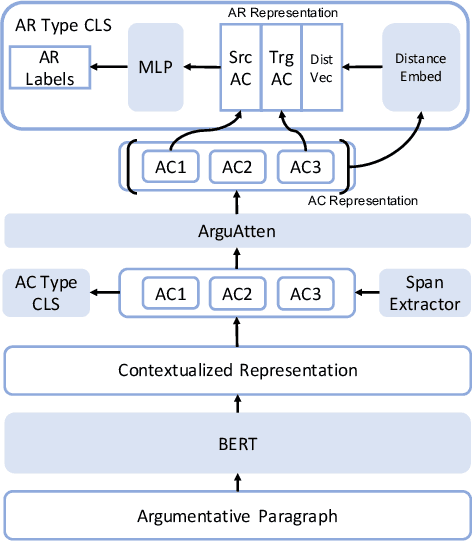
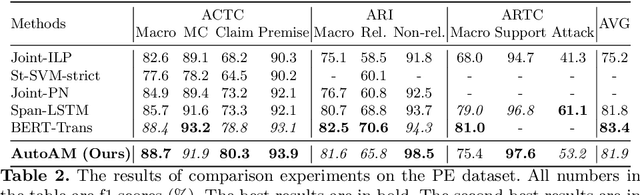
Argument mining is to analyze argument structure and extract important argument information from unstructured text. An argument mining system can help people automatically gain causal and logical information behind the text. As argumentative corpus gradually increases, like more people begin to argue and debate on social media, argument mining from them is becoming increasingly critical. However, argument mining is still a big challenge in natural language tasks due to its difficulty, and relative techniques are not mature. For example, research on non-tree argument mining needs to be done more. Most works just focus on extracting tree structure argument information. Moreover, current methods cannot accurately describe and capture argument relations and do not predict their types. In this paper, we propose a novel neural model called AutoAM to solve these problems. We first introduce the argument component attention mechanism in our model. It can capture the relevant information between argument components, so our model can better perform argument mining. Our model is a universal end-to-end framework, which can analyze argument structure without constraints like tree structure and complete three subtasks of argument mining in one model. The experiment results show that our model outperforms the existing works on several metrics in two public datasets.
WFTNet: Exploiting Global and Local Periodicity in Long-term Time Series Forecasting
Sep 20, 2023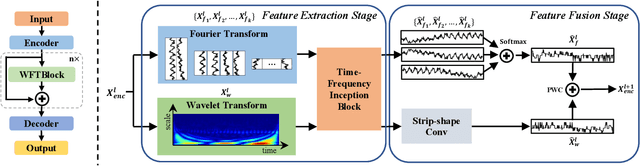
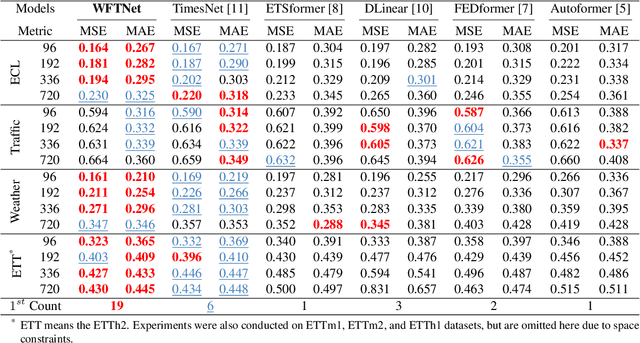
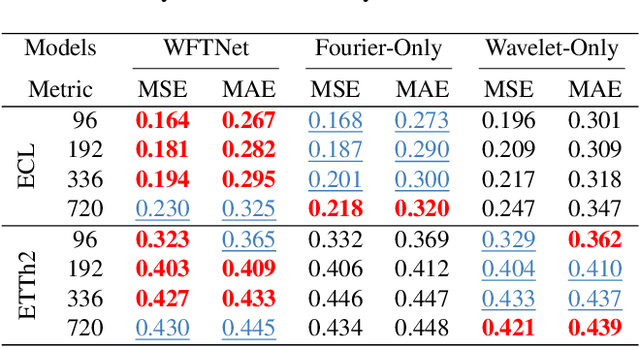
Recent CNN and Transformer-based models tried to utilize frequency and periodicity information for long-term time series forecasting. However, most existing work is based on Fourier transform, which cannot capture fine-grained and local frequency structure. In this paper, we propose a Wavelet-Fourier Transform Network (WFTNet) for long-term time series forecasting. WFTNet utilizes both Fourier and wavelet transforms to extract comprehensive temporal-frequency information from the signal, where Fourier transform captures the global periodic patterns and wavelet transform captures the local ones. Furthermore, we introduce a Periodicity-Weighted Coefficient (PWC) to adaptively balance the importance of global and local frequency patterns. Extensive experiments on various time series datasets show that WFTNet consistently outperforms other state-of-the-art baseline.
A Study on the Implementation of Generative AI Services Using an Enterprise Data-Based LLM Application Architecture
Sep 18, 2023

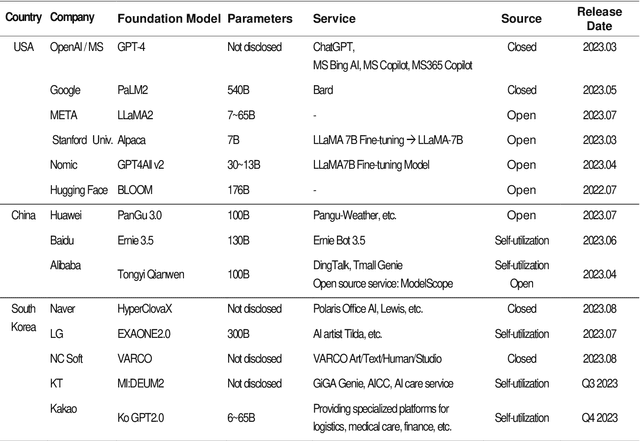
This study presents a method for implementing generative AI services by utilizing the Large Language Models (LLM) application architecture. With recent advancements in generative AI technology, LLMs have gained prominence across various domains. In this context, the research addresses the challenge of information scarcity and proposes specific remedies by harnessing LLM capabilities. The investigation delves into strategies for mitigating the issue of inadequate data, offering tailored solutions. The study delves into the efficacy of employing fine-tuning techniques and direct document integration to alleviate data insufficiency. A significant contribution of this work is the development of a Retrieval-Augmented Generation (RAG) model, which tackles the aforementioned challenges. The RAG model is carefully designed to enhance information storage and retrieval processes, ensuring improved content generation. The research elucidates the key phases of the information storage and retrieval methodology underpinned by the RAG model. A comprehensive analysis of these steps is undertaken, emphasizing their significance in addressing the scarcity of data. The study highlights the efficacy of the proposed method, showcasing its applicability through illustrative instances. By implementing the RAG model for information storage and retrieval, the research not only contributes to a deeper comprehension of generative AI technology but also facilitates its practical usability within enterprises utilizing LLMs. This work holds substantial value in advancing the field of generative AI, offering insights into enhancing data-driven content generation and fostering active utilization of LLM-based services within corporate settings.
Asynchronous Perception-Action-Communication with Graph Neural Networks
Sep 18, 2023Collaboration in large robot swarms to achieve a common global objective is a challenging problem in large environments due to limited sensing and communication capabilities. The robots must execute a Perception-Action-Communication (PAC) loop -- they perceive their local environment, communicate with other robots, and take actions in real time. A fundamental challenge in decentralized PAC systems is to decide what information to communicate with the neighboring robots and how to take actions while utilizing the information shared by the neighbors. Recently, this has been addressed using Graph Neural Networks (GNNs) for applications such as flocking and coverage control. Although conceptually, GNN policies are fully decentralized, the evaluation and deployment of such policies have primarily remained centralized or restrictively decentralized. Furthermore, existing frameworks assume sequential execution of perception and action inference, which is very restrictive in real-world applications. This paper proposes a framework for asynchronous PAC in robot swarms, where decentralized GNNs are used to compute navigation actions and generate messages for communication. In particular, we use aggregated GNNs, which enable the exchange of hidden layer information between robots for computational efficiency and decentralized inference of actions. Furthermore, the modules in the framework are asynchronous, allowing robots to perform sensing, extracting information, communication, action inference, and control execution at different frequencies. We demonstrate the effectiveness of GNNs executed in the proposed framework in navigating large robot swarms for collaborative coverage of large environments.