 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
One-Bit Channel Estimation for IRS-aided Millimeter-Wave Massive MU-MISO System
Sep 29, 2023
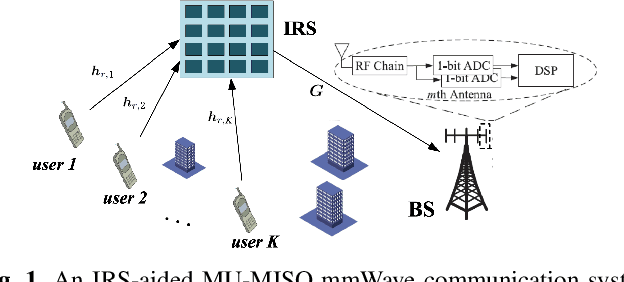
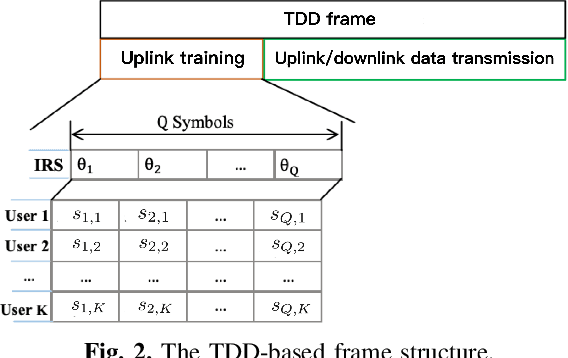
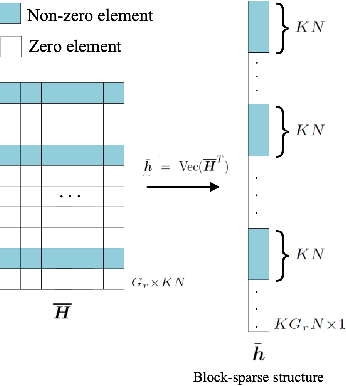
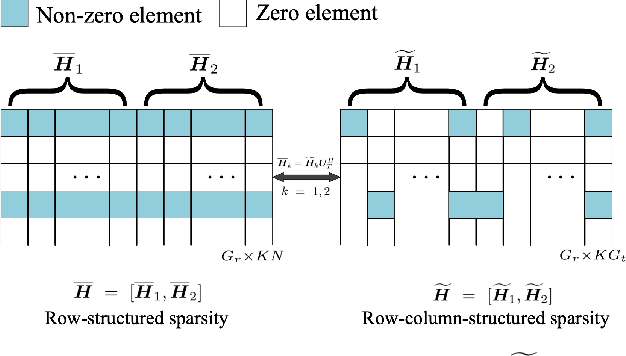
Recently, intelligent reflecting surface (IRS)-assisted communication has gained considerable attention due to its advantage in extending the coverage and compensating the path loss with low-cost passive metasurface. This paper considers the uplink channel estimation for IRS-aided multiuser massive MISO communications with one-bit ADCs at the base station (BS). The use of one-bit ADC is impelled by the low-cost and power efficient implementation of massive antennas techniques. However, the passiveness of IRS and the lack of signal level information after one-bit quantization make the IRS channel estimation challenging. To tackle this problem, we exploit the structured sparsity of the user-IRS-BS cascaded channels and develop three channel estimators, each of which utilizes the structured sparsity at different levels. Specifically, the first estimator exploits the elementwise sparsity of the cascaded channel and employs the sparse Bayesian learning (SBL) to infer the channel responses via the type-II maximum likelihood (ML) estimation. However, due to the one-bit quantization, the type-II ML in general is intractable. As such, a variational expectation-maximization (EM) algorithm is custom-derived to iteratively compute an ML solution. The second estimator utilizes the common row-structured sparsity induced by the IRS-to-BS channel shared among the users, and develops another type-II ML solution via the block SBL (BSBL) and the variational EM. To further improve the performance of BSBL, a third two-stage estimator is proposed, which can utilize both the common row-structured sparsity and the column-structured sparsity arising from the limited scattering around the users. Simulation results show that the more diverse structured sparsity is exploited, the better estimation performance is achieved, and that the proposed estimators are superior to state-of-the-art one-bit estimators.
Glancing Future for Simultaneous Machine Translation
Sep 12, 2023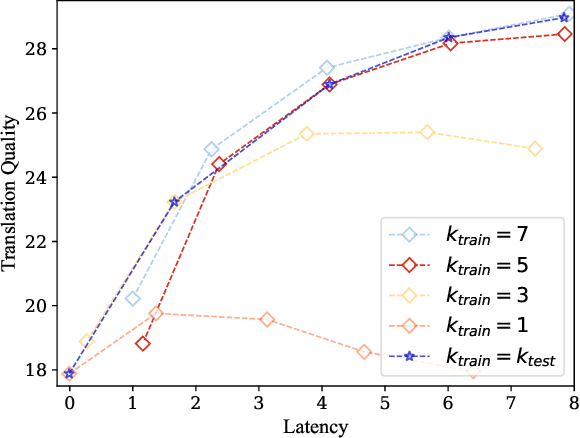

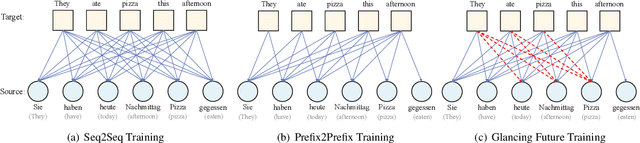

Simultaneous machine translation (SiMT) outputs translation while reading the source sentence. Unlike conventional sequence-to-sequence (seq2seq) training, existing SiMT methods adopt the prefix-to-prefix (prefix2prefix) training, where the model predicts target tokens based on partial source tokens. However, the prefix2prefix training diminishes the ability of the model to capture global information and introduces forced predictions due to the absence of essential source information. Consequently, it is crucial to bridge the gap between the prefix2prefix training and seq2seq training to enhance the translation capability of the SiMT model. In this paper, we propose a novel method that glances future in curriculum learning to achieve the transition from the seq2seq training to prefix2prefix training. Specifically, we gradually reduce the available source information from the whole sentence to the prefix corresponding to that latency. Our method is applicable to a wide range of SiMT methods and experiments demonstrate that our method outperforms strong baselines.
Perceptual Factors for Environmental Modeling in Robotic Active Perception
Sep 19, 2023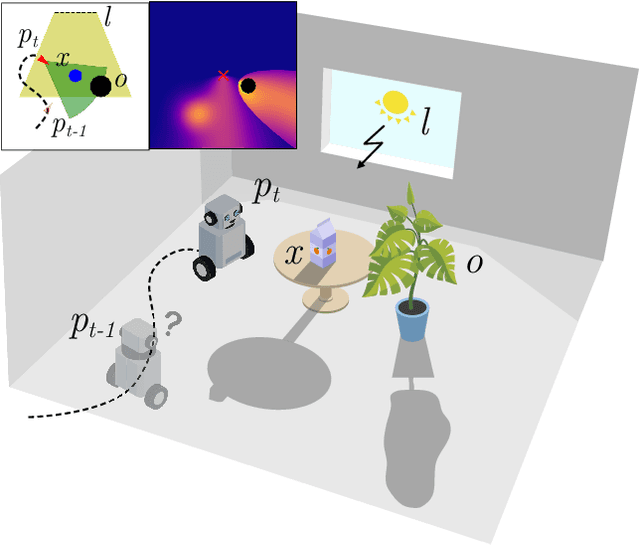
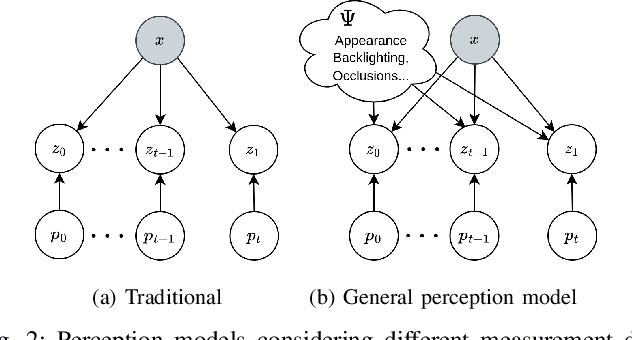
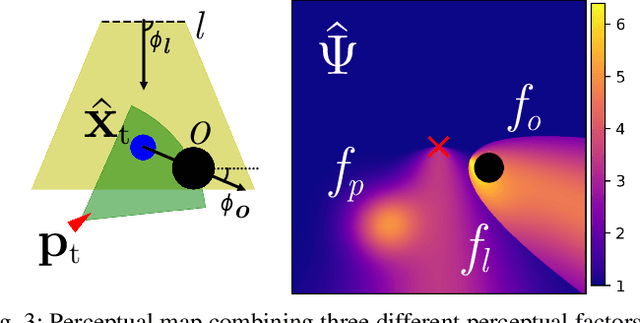
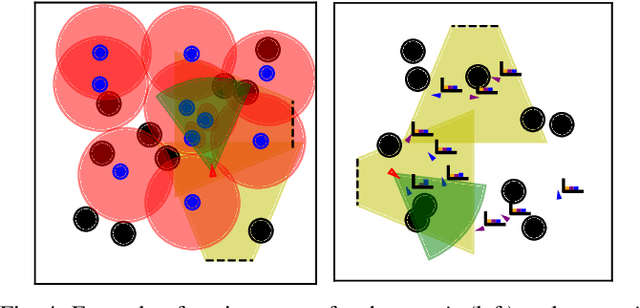
Accurately assessing the potential value of new sensor observations is a critical aspect of planning for active perception. This task is particularly challenging when reasoning about high-level scene understanding using measurements from vision-based neural networks. Due to appearance-based reasoning, the measurements are susceptible to several environmental effects such as the presence of occluders, variations in lighting conditions, and redundancy of information due to similarity in appearance between nearby viewpoints. To address this, we propose a new active perception framework incorporating an arbitrary number of perceptual effects in planning and fusion. Our method models the correlation with the environment by a set of general functions termed perceptual factors to construct a perceptual map, which quantifies the aggregated influence of the environment on candidate viewpoints. This information is seamlessly incorporated into the planning and fusion processes by adjusting the uncertainty associated with measurements to weigh their contributions. We evaluate our perceptual maps in a simulated environment that reproduces environmental conditions common in robotics applications. Our results show that, by accounting for environmental effects within our perceptual maps, we improve in the state estimation by correctly selecting the viewpoints and considering the measurement noise correctly when affected by environmental factors. We furthermore deploy our approach on a ground robot to showcase its applicability for real-world active perception missions.
FastGraphTTS: An Ultrafast Syntax-Aware Speech Synthesis Framework
Sep 16, 2023This paper integrates graph-to-sequence into an end-to-end text-to-speech framework for syntax-aware modelling with syntactic information of input text. Specifically, the input text is parsed by a dependency parsing module to form a syntactic graph. The syntactic graph is then encoded by a graph encoder to extract the syntactic hidden information, which is concatenated with phoneme embedding and input to the alignment and flow-based decoding modules to generate the raw audio waveform. The model is experimented on two languages, English and Mandarin, using single-speaker, few samples of target speakers, and multi-speaker datasets, respectively. Experimental results show better prosodic consistency performance between input text and generated audio, and also get higher scores in the subjective prosodic evaluation, and show the ability of voice conversion. Besides, the efficiency of the model is largely boosted through the design of the AI chip operator with 5x acceleration.
More Synergy, Less Redundancy: Exploiting Joint Mutual Information for Self-Supervised Learning
Jul 02, 2023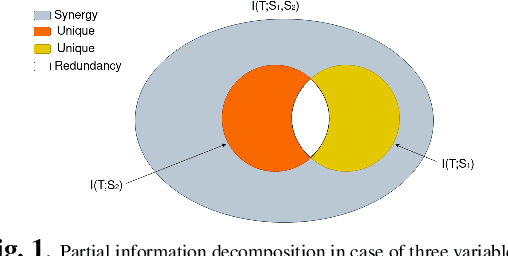
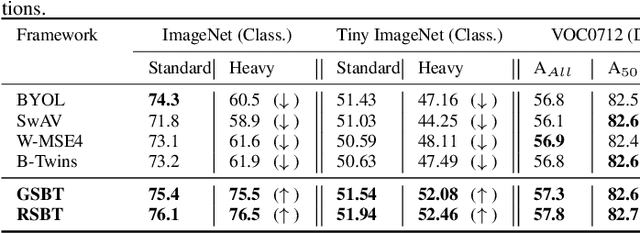
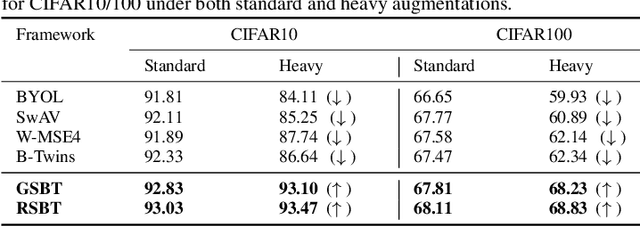
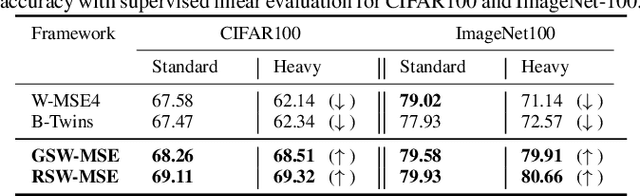
Self-supervised learning (SSL) is now a serious competitor for supervised learning, even though it does not require data annotation. Several baselines have attempted to make SSL models exploit information about data distribution, and less dependent on the augmentation effect. However, there is no clear consensus on whether maximizing or minimizing the mutual information between representations of augmentation views practically contribute to improvement or degradation in performance of SSL models. This paper is a fundamental work where, we investigate role of mutual information in SSL, and reformulate the problem of SSL in the context of a new perspective on mutual information. To this end, we consider joint mutual information from the perspective of partial information decomposition (PID) as a key step in \textbf{reliable multivariate information measurement}. PID enables us to decompose joint mutual information into three important components, namely, unique information, redundant information and synergistic information. Our framework aims for minimizing the redundant information between views and the desired target representation while maximizing the synergistic information at the same time. Our experiments lead to a re-calibration of two redundancy reduction baselines, and a proposal for a new SSL training protocol. Extensive experimental results on multiple datasets and two downstream tasks show the effectiveness of this framework.
AsQM: Audio streaming Quality Metric based on Network Impairments and User Preferences
Sep 26, 2023There are many users of audio streaming services because of the proliferation of cloud-based audio streaming services for different content. The complex networks that support these services do not always guarantee an acceptable quality on the end-user side. In this paper, the impact of temporal interruptions on the reproduction of audio streaming and the users preference in relation to audio contents are studied. In order to determine the key parameters in the audio streaming service, subjective tests were conducted, and their results show that users Quality-of-Experience (QoE) is highly correlated with the following application parameters, the number of temporal interruptions or stalls, its frequency and length, and the temporal location in which they occur. However, most important, experimental results demonstrated that users preference for audio content plays an important role in users QoE. Thus, a Preference Factor (PF) function is defined and considered in the formulation of the proposed metric named Audio streaming Quality Metric (AsQM). Considering that multimedia service providers are based on web servers, a framework to obtain user information is proposed. Furthermore, results show that the AsQM implemented in the audio player of an end users device presents a low impact on energy, processing and memory consumption.
* 11 pages
Statistical Analysis of Quantum State Learning Process in Quantum Neural Networks
Sep 26, 2023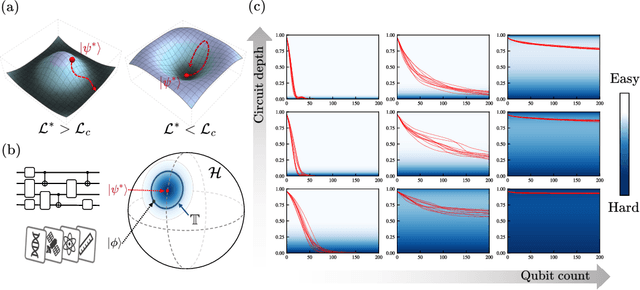
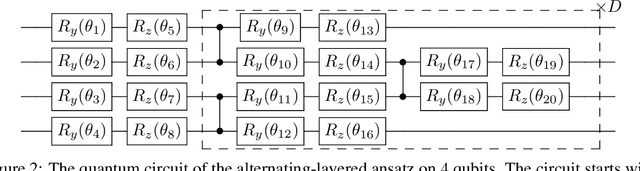
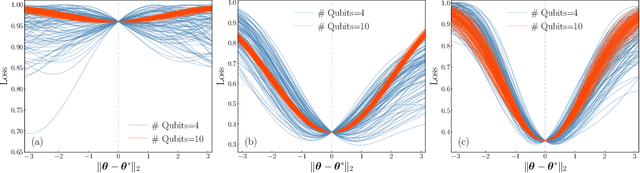
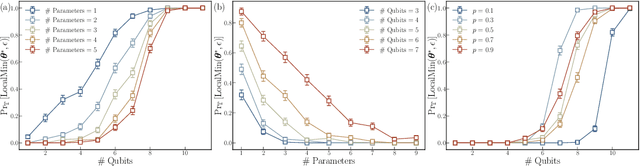
Quantum neural networks (QNNs) have been a promising framework in pursuing near-term quantum advantage in various fields, where many applications can be viewed as learning a quantum state that encodes useful data. As a quantum analog of probability distribution learning, quantum state learning is theoretically and practically essential in quantum machine learning. In this paper, we develop a no-go theorem for learning an unknown quantum state with QNNs even starting from a high-fidelity initial state. We prove that when the loss value is lower than a critical threshold, the probability of avoiding local minima vanishes exponentially with the qubit count, while only grows polynomially with the circuit depth. The curvature of local minima is concentrated to the quantum Fisher information times a loss-dependent constant, which characterizes the sensibility of the output state with respect to parameters in QNNs. These results hold for any circuit structures, initialization strategies, and work for both fixed ansatzes and adaptive methods. Extensive numerical simulations are performed to validate our theoretical results. Our findings place generic limits on good initial guesses and adaptive methods for improving the learnability and scalability of QNNs, and deepen the understanding of prior information's role in QNNs.
Probabilistic 3D Multi-Object Cooperative Tracking for Autonomous Driving via Differentiable Multi-Sensor Kalman Filter
Sep 26, 2023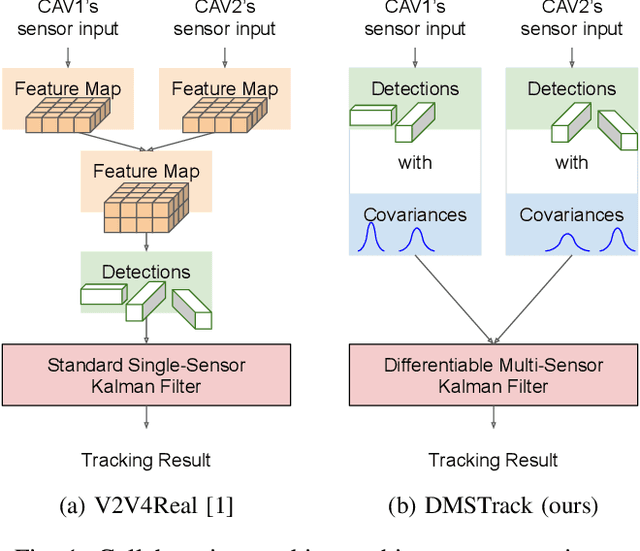
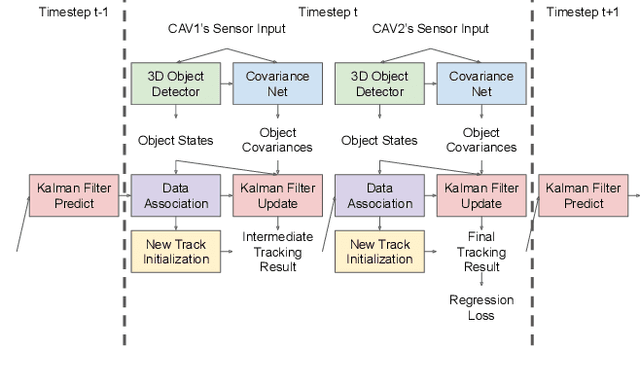
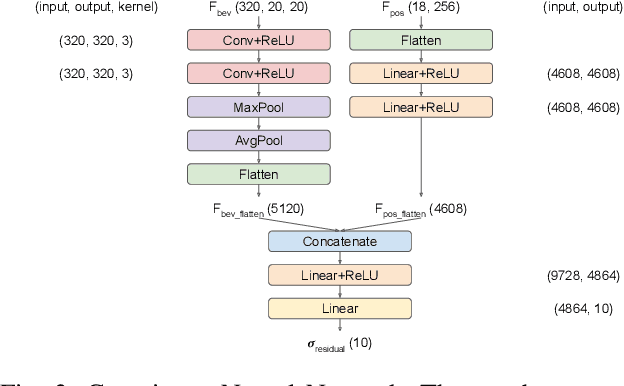
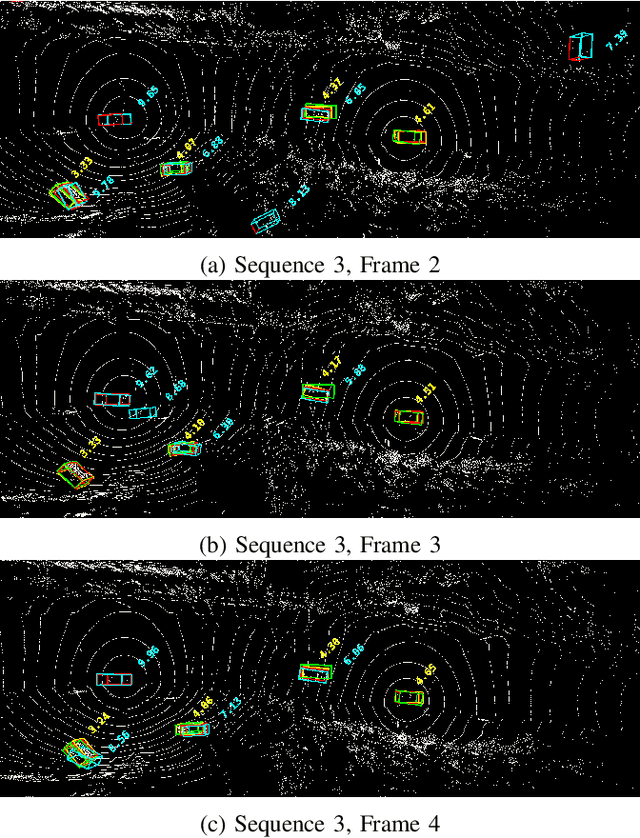
Current state-of-the-art autonomous driving vehicles mainly rely on each individual sensor system to perform perception tasks. Such a framework's reliability could be limited by occlusion or sensor failure. To address this issue, more recent research proposes using vehicle-to-vehicle (V2V) communication to share perception information with others. However, most relevant works focus only on cooperative detection and leave cooperative tracking an underexplored research field. A few recent datasets, such as V2V4Real, provide 3D multi-object cooperative tracking benchmarks. However, their proposed methods mainly use cooperative detection results as input to a standard single-sensor Kalman Filter-based tracking algorithm. In their approach, the measurement uncertainty of different sensors from different connected autonomous vehicles (CAVs) may not be properly estimated to utilize the theoretical optimality property of Kalman Filter-based tracking algorithms. In this paper, we propose a novel 3D multi-object cooperative tracking algorithm for autonomous driving via a differentiable multi-sensor Kalman Filter. Our algorithm learns to estimate measurement uncertainty for each detection that can better utilize the theoretical property of Kalman Filter-based tracking methods. The experiment results show that our algorithm improves the tracking accuracy by 17% with only 0.037x communication costs compared with the state-of-the-art method in V2V4Real.
DifAttack: Query-Efficient Black-Box Attack via Disentangled Feature Space
Sep 26, 2023This work investigates efficient score-based black-box adversarial attacks with a high Attack Success Rate (ASR) and good generalizability. We design a novel attack method based on a Disentangled Feature space, called DifAttack, which differs significantly from the existing ones operating over the entire feature space. Specifically, DifAttack firstly disentangles an image's latent feature into an adversarial feature and a visual feature, where the former dominates the adversarial capability of an image, while the latter largely determines its visual appearance. We train an autoencoder for the disentanglement by using pairs of clean images and their Adversarial Examples (AEs) generated from available surrogate models via white-box attack methods. Eventually, DifAttack iteratively optimizes the adversarial feature according to the query feedback from the victim model until a successful AE is generated, while keeping the visual feature unaltered. In addition, due to the avoidance of using surrogate models' gradient information when optimizing AEs for black-box models, our proposed DifAttack inherently possesses better attack capability in the open-set scenario, where the training dataset of the victim model is unknown. Extensive experimental results demonstrate that our method achieves significant improvements in ASR and query efficiency simultaneously, especially in the targeted attack and open-set scenarios. The code will be available at https://github.com/csjunjun/DifAttack.git soon.
Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
Sep 26, 2023Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes. We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.