 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
Oct 05, 2023

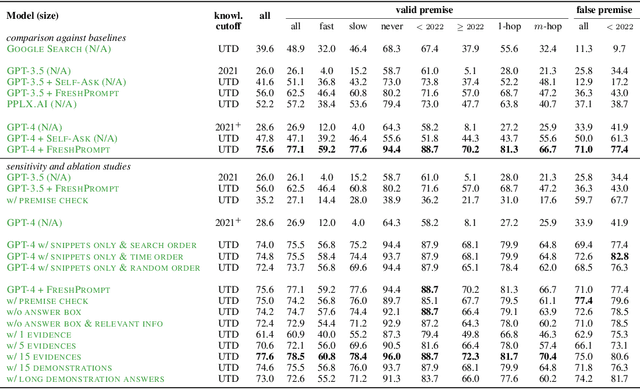
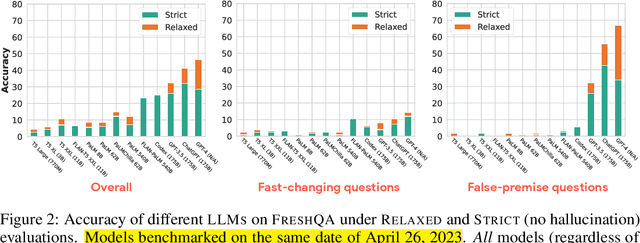

Most large language models (LLMs) are trained once and never updated; thus, they lack the ability to dynamically adapt to our ever-changing world. In this work, we perform a detailed study of the factuality of LLM-generated text in the context of answering questions that test current world knowledge. Specifically, we introduce FreshQA, a novel dynamic QA benchmark encompassing a diverse range of question and answer types, including questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked. We benchmark a diverse array of both closed and open-source LLMs under a two-mode evaluation procedure that allows us to measure both correctness and hallucination. Through human evaluations involving more than 50K judgments, we shed light on limitations of these models and demonstrate significant room for improvement: for instance, all models (regardless of model size) struggle on questions that involve fast-changing knowledge and false premises. Motivated by these results, we present FreshPrompt, a simple few-shot prompting method that substantially boosts the performance of an LLM on FreshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt. Our experiments show that FreshPrompt outperforms both competing search engine-augmented prompting methods such as Self-Ask (Press et al., 2022) as well as commercial systems such as Perplexity.AI. Further analysis of FreshPrompt reveals that both the number of retrieved evidences and their order play a key role in influencing the correctness of LLM-generated answers. Additionally, instructing the LLM to generate concise and direct answers helps reduce hallucination compared to encouraging more verbose answers. To facilitate future work, we release FreshQA at github.com/freshllms/freshqa and commit to updating it at regular intervals.
Ablation Study to Clarify the Mechanism of Object Segmentation in Multi-Object Representation Learning
Oct 05, 2023Multi-object representation learning aims to represent complex real-world visual input using the composition of multiple objects. Representation learning methods have often used unsupervised learning to segment an input image into individual objects and encode these objects into each latent vector. However, it is not clear how previous methods have achieved the appropriate segmentation of individual objects. Additionally, most of the previous methods regularize the latent vectors using a Variational Autoencoder (VAE). Therefore, it is not clear whether VAE regularization contributes to appropriate object segmentation. To elucidate the mechanism of object segmentation in multi-object representation learning, we conducted an ablation study on MONet, which is a typical method. MONet represents multiple objects using pairs that consist of an attention mask and the latent vector corresponding to the attention mask. Each latent vector is encoded from the input image and attention mask. Then, the component image and attention mask are decoded from each latent vector. The loss function of MONet consists of 1) the sum of reconstruction losses between the input image and decoded component image, 2) the VAE regularization loss of the latent vector, and 3) the reconstruction loss of the attention mask to explicitly encode shape information. We conducted an ablation study on these three loss functions to investigate the effect on segmentation performance. Our results showed that the VAE regularization loss did not affect segmentation performance and the others losses did affect it. Based on this result, we hypothesize that it is important to maximize the attention mask of the image region best represented by a single latent vector corresponding to the attention mask. We confirmed this hypothesis by evaluating a new loss function with the same mechanism as the hypothesis.
TPDR: A Novel Two-Step Transformer-based Product and Class Description Match and Retrieval Method
Oct 05, 2023There is a niche of companies responsible for intermediating the purchase of large batches of varied products for other companies, for which the main challenge is to perform product description standardization, i.e., matching an item described by a client with a product described in a catalog. The problem is complex since the client's product description may be: (1) potentially noisy; (2) short and uninformative (e.g., missing information about model and size); and (3) cross-language. In this paper, we formalize this problem as a ranking task: given an initial client product specification (query), return the most appropriate standardized descriptions (response). In this paper, we propose TPDR, a two-step Transformer-based Product and Class Description Retrieval method that is able to explore the semantic correspondence between IS and SD, by exploiting attention mechanisms and contrastive learning. First, TPDR employs the transformers as two encoders sharing the embedding vector space: one for encoding the IS and another for the SD, in which corresponding pairs (IS, SD) must be close in the vector space. Closeness is further enforced by a contrastive learning mechanism leveraging a specialized loss function. TPDR also exploits a (second) re-ranking step based on syntactic features that are very important for the exact matching (model, dimension) of certain products that may have been neglected by the transformers. To evaluate our proposal, we consider 11 datasets from a real company, covering different application contexts. Our solution was able to retrieve the correct standardized product before the 5th ranking position in 71% of the cases and its correct category in the first position in 80% of the situations. Moreover, the effectiveness gains over purely syntactic or semantic baselines reach up to 3.7 times, solving cases that none of the approaches in isolation can do by themselves.
More complex encoder is not all you need
Sep 21, 2023U-Net and its variants have been widely used in medical image segmentation. However, most current U-Net variants confine their improvement strategies to building more complex encoder, while leaving the decoder unchanged or adopting a simple symmetric structure. These approaches overlook the true functionality of the decoder: receiving low-resolution feature maps from the encoder and restoring feature map resolution and lost information through upsampling. As a result, the decoder, especially its upsampling component, plays a crucial role in enhancing segmentation outcomes. However, in 3D medical image segmentation, the commonly used transposed convolution can result in visual artifacts. This issue stems from the absence of direct relationship between adjacent pixels in the output feature map. Furthermore, plain encoder has already possessed sufficient feature extraction capability because downsampling operation leads to the gradual expansion of the receptive field, but the loss of information during downsampling process is unignorable. To address the gap in relevant research, we extend our focus beyond the encoder and introduce neU-Net (i.e., not complex encoder U-Net), which incorporates a novel Sub-pixel Convolution for upsampling to construct a powerful decoder. Additionally, we introduce multi-scale wavelet inputs module on the encoder side to provide additional information. Our model design achieves excellent results, surpassing other state-of-the-art methods on both the Synapse and ACDC datasets.
OceanBench: The Sea Surface Height Edition
Sep 27, 2023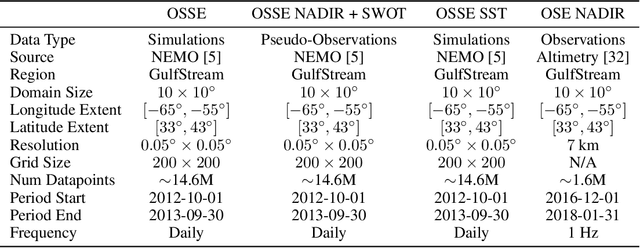
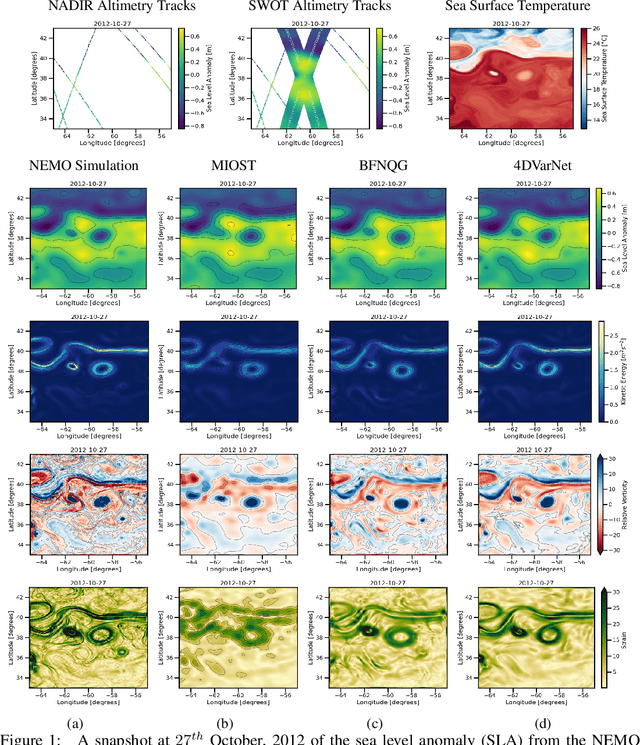
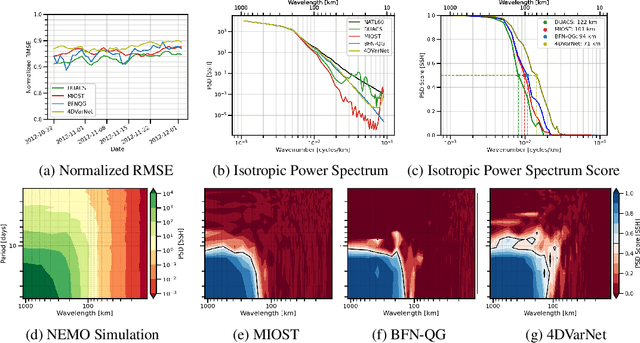

The ocean profoundly influences human activities and plays a critical role in climate regulation. Our understanding has improved over the last decades with the advent of satellite remote sensing data, allowing us to capture essential quantities over the globe, e.g., sea surface height (SSH). However, ocean satellite data presents challenges for information extraction due to their sparsity and irregular sampling, signal complexity, and noise. Machine learning (ML) techniques have demonstrated their capabilities in dealing with large-scale, complex signals. Therefore we see an opportunity for ML models to harness the information contained in ocean satellite data. However, data representation and relevant evaluation metrics can be the defining factors when determining the success of applied ML. The processing steps from the raw observation data to a ML-ready state and from model outputs to interpretable quantities require domain expertise, which can be a significant barrier to entry for ML researchers. OceanBench is a unifying framework that provides standardized processing steps that comply with domain-expert standards. It provides plug-and-play data and pre-configured pipelines for ML researchers to benchmark their models and a transparent configurable framework for researchers to customize and extend the pipeline for their tasks. In this work, we demonstrate the OceanBench framework through a first edition dedicated to SSH interpolation challenges. We provide datasets and ML-ready benchmarking pipelines for the long-standing problem of interpolating observations from simulated ocean satellite data, multi-modal and multi-sensor fusion issues, and transfer-learning to real ocean satellite observations. The OceanBench framework is available at github.com/jejjohnson/oceanbench and the dataset registry is available at github.com/quentinf00/oceanbench-data-registry.
Explainable Machine Learning for ICU Readmission Prediction
Sep 27, 2023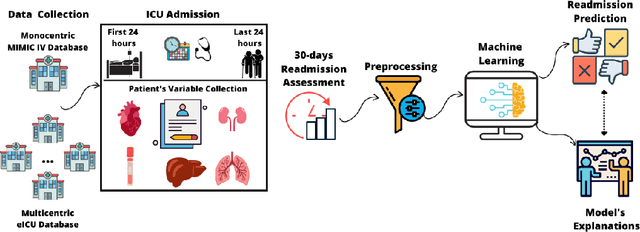
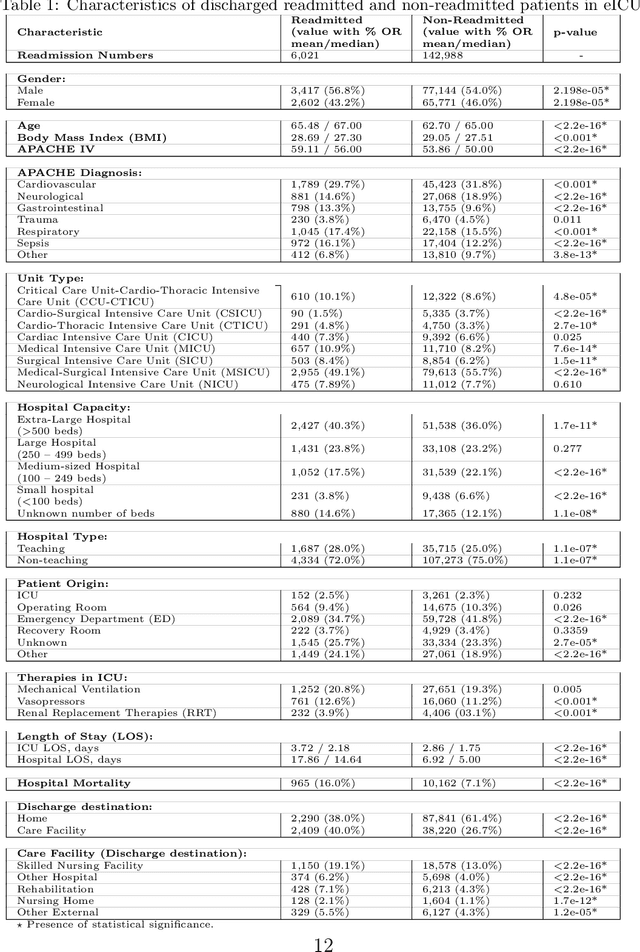
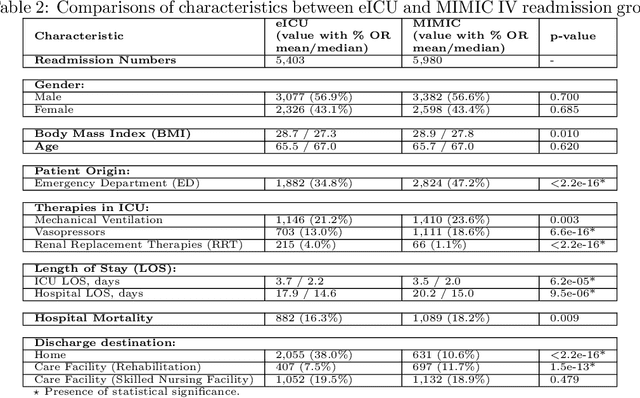
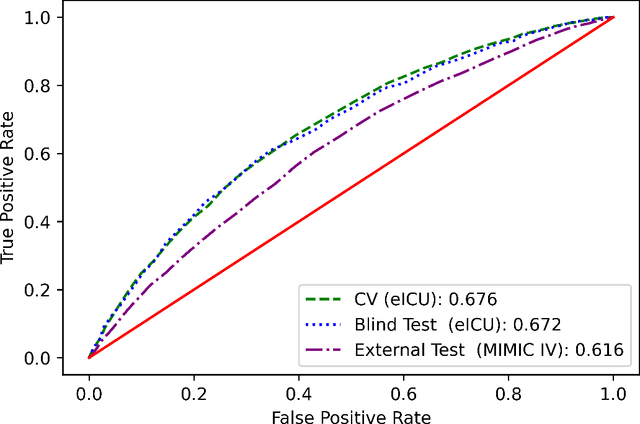
The intensive care unit (ICU) comprises a complex hospital environment, where decisions made by clinicians have a high level of risk for the patients' lives. A comprehensive care pathway must then be followed to reduce p complications. Uncertain, competing and unplanned aspects within this environment increase the difficulty in uniformly implementing the care pathway. Readmission contributes to this pathway's difficulty, occurring when patients are admitted again to the ICU in a short timeframe, resulting in high mortality rates and high resource utilisation. Several works have tried to predict readmission through patients' medical information. Although they have some level of success while predicting readmission, those works do not properly assess, characterise and understand readmission prediction. This work proposes a standardised and explainable machine learning pipeline to model patient readmission on a multicentric database (i.e., the eICU cohort with 166,355 patients, 200,859 admissions and 6,021 readmissions) while validating it on monocentric (i.e., the MIMIC IV cohort with 382,278 patients, 523,740 admissions and 5,984 readmissions) and multicentric settings. Our machine learning pipeline achieved predictive performance in terms of the area of the receiver operating characteristic curve (AUC) up to 0.7 with a Random Forest classification model, yielding an overall good calibration and consistency on validation sets. From explanations provided by the constructed models, we could also derive a set of insightful conclusions, primarily on variables related to vital signs and blood tests (e.g., albumin, blood urea nitrogen and hemoglobin levels), demographics (e.g., age, and admission height and weight), and ICU-associated variables (e.g., unit type). These insights provide an invaluable source of information during clinicians' decision-making while discharging ICU patients.
Hierarchy Builder: Organizing Textual Spans into a Hierarchy to Facilitate Navigation
Sep 18, 2023
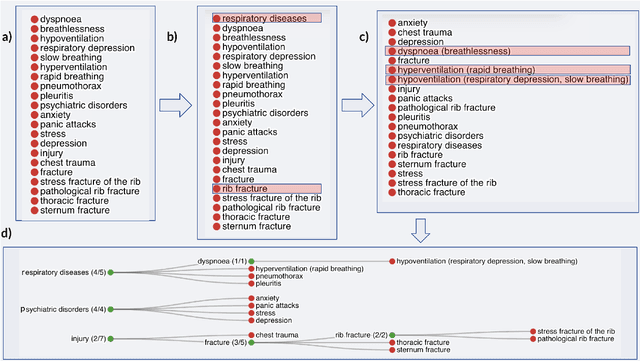
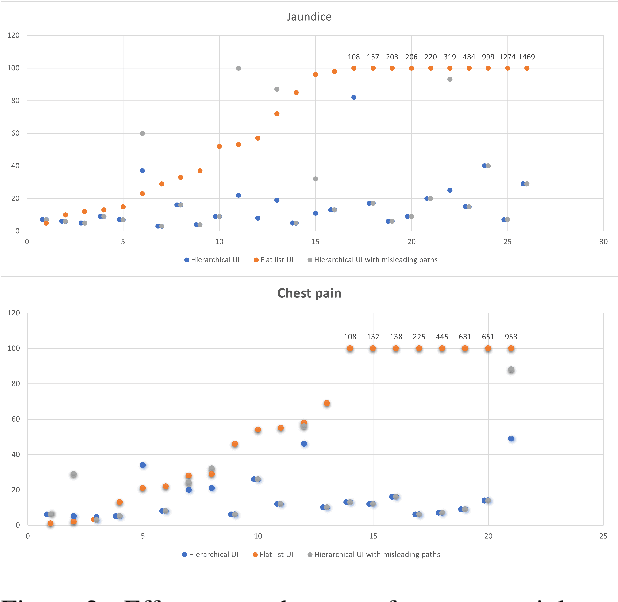
Information extraction systems often produce hundreds to thousands of strings on a specific topic. We present a method that facilitates better consumption of these strings, in an exploratory setting in which a user wants to both get a broad overview of what's available, and a chance to dive deeper on some aspects. The system works by grouping similar items together and arranging the remaining items into a hierarchical navigable DAG structure. We apply the method to medical information extraction.
* 9 pages including citations; Presented at the ACL 2023 DEMO track, pages 282-290
Synthetic Latent Fingerprint Generation Using Style Transfer
Sep 27, 2023Limited data availability is a challenging problem in the latent fingerprint domain. Synthetically generated fingerprints are vital for training data-hungry neural network-based algorithms. Conventional methods distort clean fingerprints to generate synthetic latent fingerprints. We propose a simple and effective approach using style transfer and image blending to synthesize realistic latent fingerprints. Our evaluation criteria and experiments demonstrate that the generated synthetic latent fingerprints preserve the identity information from the input contact-based fingerprints while possessing similar characteristics as real latent fingerprints. Additionally, we show that the generated fingerprints exhibit several qualities and styles, suggesting that the proposed method can generate multiple samples from a single fingerprint.
LivDet2023 -- Fingerprint Liveness Detection Competition: Advancing Generalization
Sep 27, 2023The International Fingerprint Liveness Detection Competition (LivDet) is a biennial event that invites academic and industry participants to prove their advancements in Fingerprint Presentation Attack Detection (PAD). This edition, LivDet2023, proposed two challenges, Liveness Detection in Action and Fingerprint Representation, to evaluate the efficacy of PAD embedded in verification systems and the effectiveness and compactness of feature sets. A third, hidden challenge is the inclusion of two subsets in the training set whose sensor information is unknown, testing participants ability to generalize their models. Only bona fide fingerprint samples were provided to participants, and the competition reports and assesses the performance of their algorithms suffering from this limitation in data availability.
Latent Graph Powered Semi-Supervised Learning on Biomedical Tabular Data
Sep 28, 2023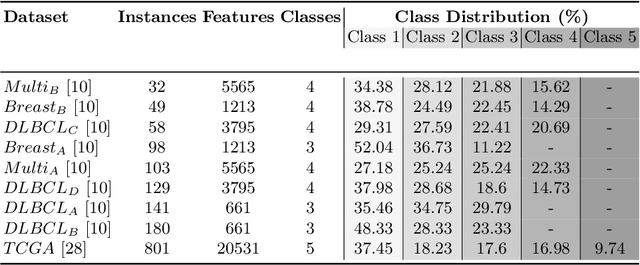

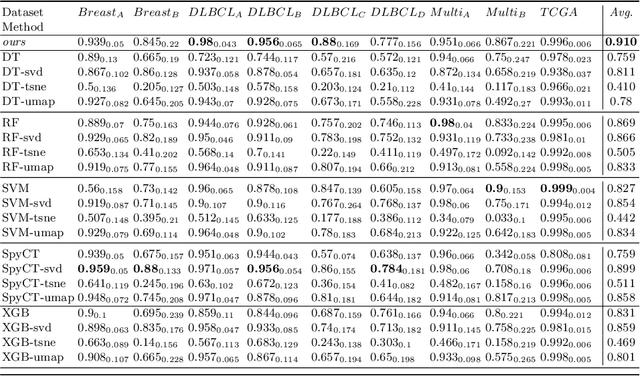

In the domain of semi-supervised learning, the current approaches insufficiently exploit the potential of considering inter-instance relationships among (un)labeled data. In this work, we address this limitation by providing an approach for inferring latent graphs that capture the intrinsic data relationships. By leveraging graph-based representations, our approach facilitates the seamless propagation of information throughout the graph, enabling the effective incorporation of global and local knowledge. Through evaluations on biomedical tabular datasets, we compare the capabilities of our approach to other contemporary methods. Our work demonstrates the significance of inter-instance relationship discovery as practical means for constructing robust latent graphs to enhance semi-supervised learning techniques. Our method achieves state-of-the-art results on three biomedical datasets.