 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SCT: A Simple Baseline for Parameter-Efficient Fine-Tuning via Salient Channels
Sep 18, 2023
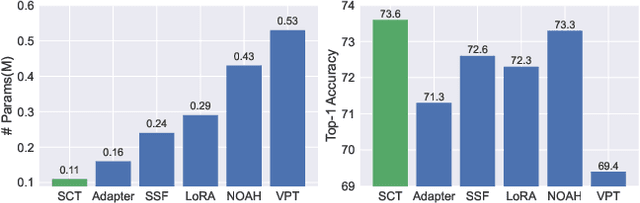
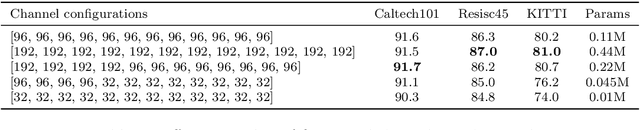
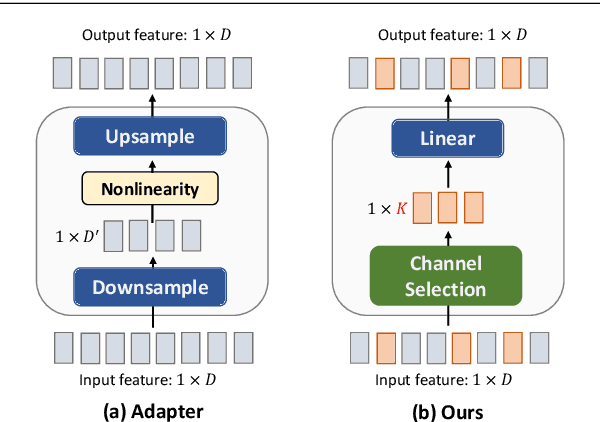

Pre-trained vision transformers have strong representation benefits to various downstream tasks. Recently, many parameter-efficient fine-tuning (PEFT) methods have been proposed, and their experiments demonstrate that tuning only 1% of extra parameters could surpass full fine-tuning in low-data resource scenarios. However, these methods overlook the task-specific information when fine-tuning diverse downstream tasks. In this paper, we propose a simple yet effective method called "Salient Channel Tuning" (SCT) to leverage the task-specific information by forwarding the model with the task images to select partial channels in a feature map that enables us to tune only 1/8 channels leading to significantly lower parameter costs. Experiments outperform full fine-tuning on 18 out of 19 tasks in the VTAB-1K benchmark by adding only 0.11M parameters of the ViT-B, which is 780$\times$ fewer than its full fine-tuning counterpart. Furthermore, experiments on domain generalization and few-shot learning surpass other PEFT methods with lower parameter costs, demonstrating our proposed tuning technique's strong capability and effectiveness in the low-data regime.
Machine Learning Technique Based Fake News Detection
Sep 18, 2023
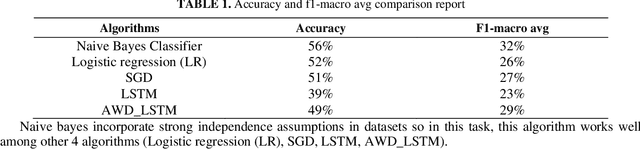
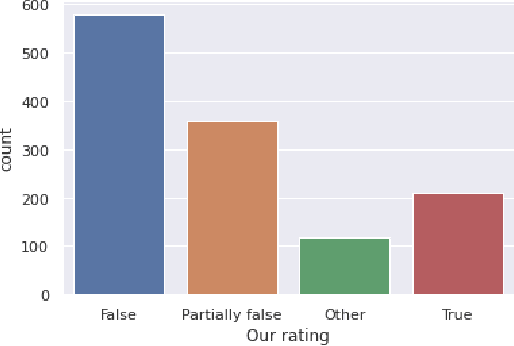
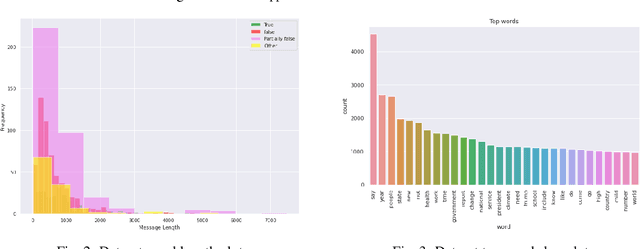
False news has received attention from both the general public and the scholarly world. Such false information has the ability to affect public perception, giving nefarious groups the chance to influence the results of public events like elections. Anyone can share fake news or facts about anyone or anything for their personal gain or to cause someone trouble. Also, information varies depending on the part of the world it is shared on. Thus, in this paper, we have trained a model to classify fake and true news by utilizing the 1876 news data from our collected dataset. We have preprocessed the data to get clean and filtered texts by following the Natural Language Processing approaches. Our research conducts 3 popular Machine Learning (Stochastic gradient descent, Na\"ive Bayes, Logistic Regression,) and 2 Deep Learning (Long-Short Term Memory, ASGD Weight-Dropped LSTM, or AWD-LSTM) algorithms. After we have found our best Naive Bayes classifier with 56% accuracy and an F1-macro score of an average of 32%.
Enhancing Cardiac MRI Segmentation via Classifier-Guided Two-Stage Network and All-Slice Information Fusion Transformer
Sep 02, 2023Cardiac Magnetic Resonance imaging (CMR) is the gold standard for assessing cardiac function. Segmenting the left ventricle (LV), right ventricle (RV), and LV myocardium (MYO) in CMR images is crucial but time-consuming. Deep learning-based segmentation methods have emerged as effective tools for automating this process. However, CMR images present additional challenges due to irregular and varying heart shapes, particularly in basal and apical slices. In this study, we propose a classifier-guided two-stage network with an all-slice fusion transformer to enhance CMR segmentation accuracy, particularly in basal and apical slices. Our method was evaluated on extensive clinical datasets and demonstrated better performance in terms of Dice score compared to previous CNN-based and transformer-based models. Moreover, our method produces visually appealing segmentation shapes resembling human annotations and avoids common issues like holes or fragments in other models' segmentations.
DiffGAN-F2S: Symmetric and Efficient Denoising Diffusion GANs for Structural Connectivity Prediction from Brain fMRI
Sep 28, 2023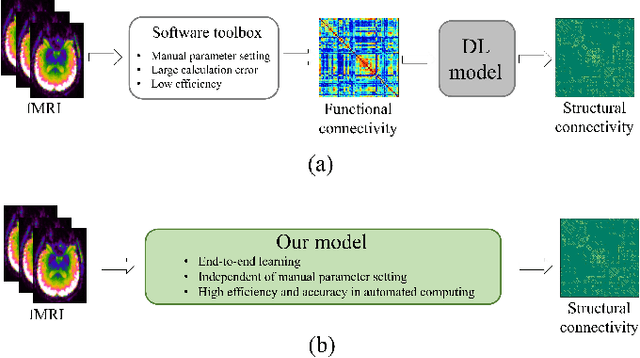
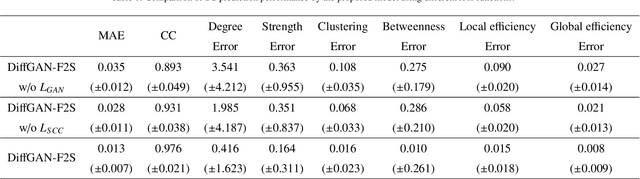
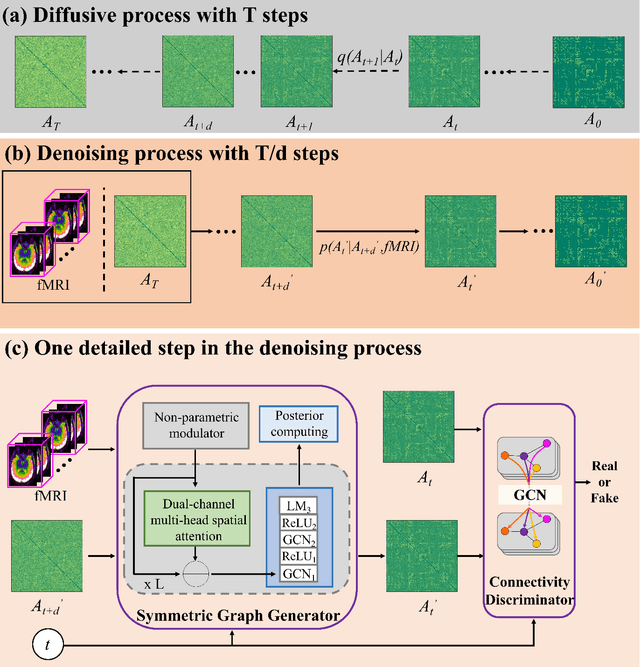
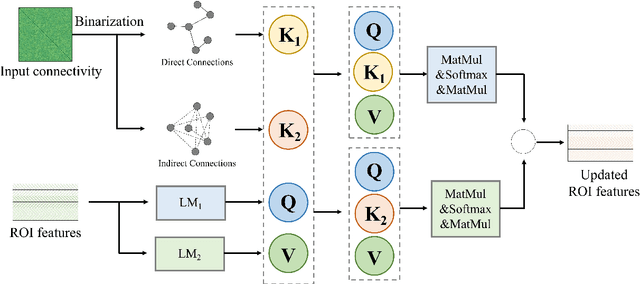
Mapping from functional connectivity (FC) to structural connectivity (SC) can facilitate multimodal brain network fusion and discover potential biomarkers for clinical implications. However, it is challenging to directly bridge the reliable non-linear mapping relations between SC and functional magnetic resonance imaging (fMRI). In this paper, a novel diffusision generative adversarial network-based fMRI-to-SC (DiffGAN-F2S) model is proposed to predict SC from brain fMRI in an end-to-end manner. To be specific, the proposed DiffGAN-F2S leverages denoising diffusion probabilistic models (DDPMs) and adversarial learning to efficiently generate high-fidelity SC through a few steps from fMRI. By designing the dual-channel multi-head spatial attention (DMSA) and graph convolutional modules, the symmetric graph generator first captures global relations among direct and indirect connected brain regions, then models the local brain region interactions. It can uncover the complex mapping relations between fMRI and structural connectivity. Furthermore, the spatially connected consistency loss is devised to constrain the generator to preserve global-local topological information for accurate intrinsic SC prediction. Testing on the public Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, the proposed model can effectively generate empirical SC-preserved connectivity from four-dimensional imaging data and shows superior performance in SC prediction compared with other related models. Furthermore, the proposed model can identify the vast majority of important brain regions and connections derived from the empirical method, providing an alternative way to fuse multimodal brain networks and analyze clinical disease.
Stochastic Digital Twin for Copy Detection Patterns
Sep 28, 2023Copy detection patterns (CDP) present an efficient technique for product protection against counterfeiting. However, the complexity of studying CDP production variability often results in time-consuming and costly procedures, limiting CDP scalability. Recent advancements in computer modelling, notably the concept of a "digital twin" for printing-imaging channels, allow for enhanced scalability and the optimization of authentication systems. Yet, the development of an accurate digital twin is far from trivial. This paper extends previous research which modelled a printing-imaging channel using a machine learning-based digital twin for CDP. This model, built upon an information-theoretic framework known as "Turbo", demonstrated superior performance over traditional generative models such as CycleGAN and pix2pix. However, the emerging field of Denoising Diffusion Probabilistic Models (DDPM) presents a potential advancement in generative models due to its ability to stochastically model the inherent randomness of the printing-imaging process, and its impressive performance in image-to-image translation tasks. This study aims at comparing the capabilities of the Turbo framework and DDPM on the same CDP datasets, with the goal of establishing the real-world benefits of DDPM models for digital twin applications in CDP security. Furthermore, the paper seeks to evaluate the generative potential of the studied models in the context of mobile phone data acquisition. Despite the increased complexity of DDPM methods when compared to traditional approaches, our study highlights their advantages and explores their potential for future applications.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Sep 28, 2023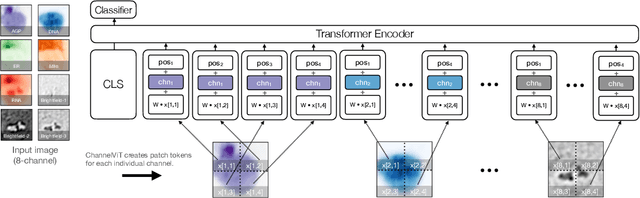
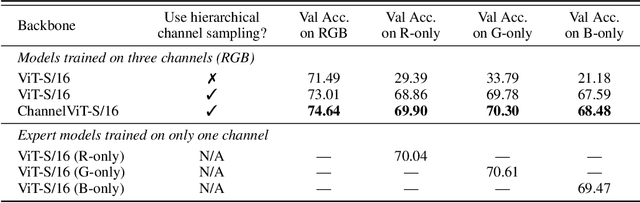
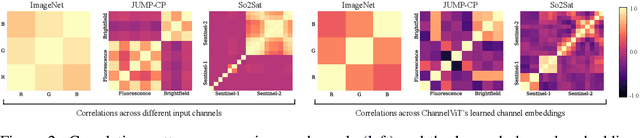
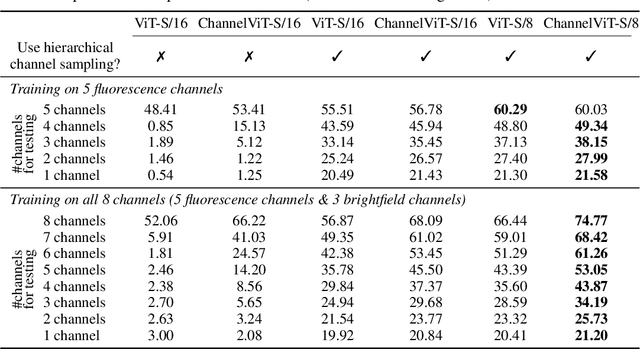
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors.
Joint Correcting and Refinement for Balanced Low-Light Image Enhancement
Sep 28, 2023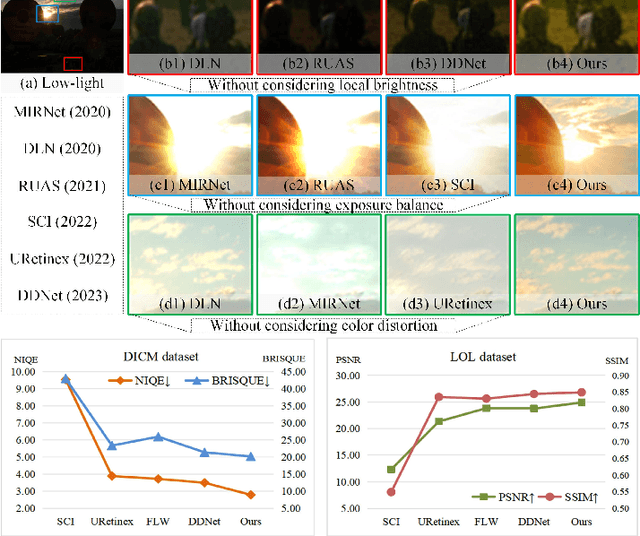

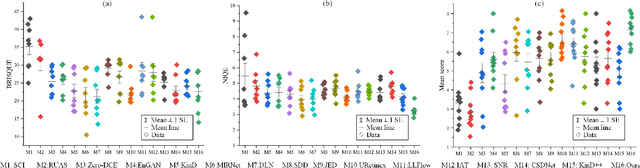

Low-light image enhancement tasks demand an appropriate balance among brightness, color, and illumination. While existing methods often focus on one aspect of the image without considering how to pay attention to this balance, which will cause problems of color distortion and overexposure etc. This seriously affects both human visual perception and the performance of high-level visual models. In this work, a novel synergistic structure is proposed which can balance brightness, color, and illumination more effectively. Specifically, the proposed method, so-called Joint Correcting and Refinement Network (JCRNet), which mainly consists of three stages to balance brightness, color, and illumination of enhancement. Stage 1: we utilize a basic encoder-decoder and local supervision mechanism to extract local information and more comprehensive details for enhancement. Stage 2: cross-stage feature transmission and spatial feature transformation further facilitate color correction and feature refinement. Stage 3: we employ a dynamic illumination adjustment approach to embed residuals between predicted and ground truth images into the model, adaptively adjusting illumination balance. Extensive experiments demonstrate that the proposed method exhibits comprehensive performance advantages over 21 state-of-the-art methods on 9 benchmark datasets. Furthermore, a more persuasive experiment has been conducted to validate our approach the effectiveness in downstream visual tasks (e.g., saliency detection). Compared to several enhancement models, the proposed method effectively improves the segmentation results and quantitative metrics of saliency detection. The source code will be available at https://github.com/woshiyll/JCRNet.
Multi-Modal Financial Time-Series Retrieval Through Latent Space Projections
Sep 28, 2023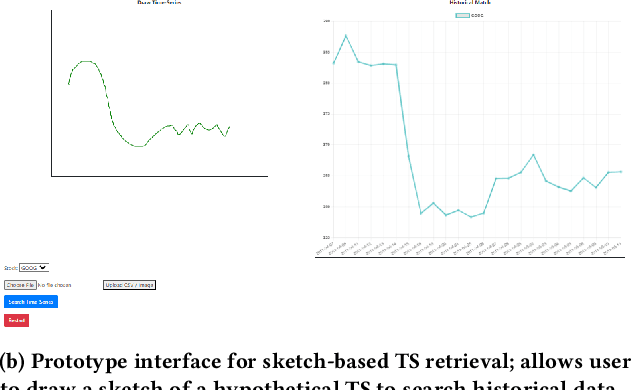
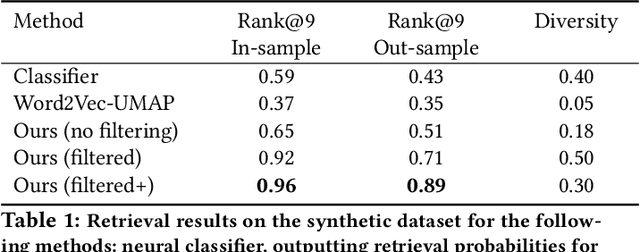
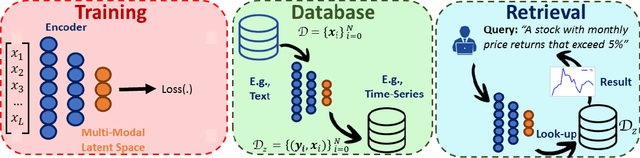
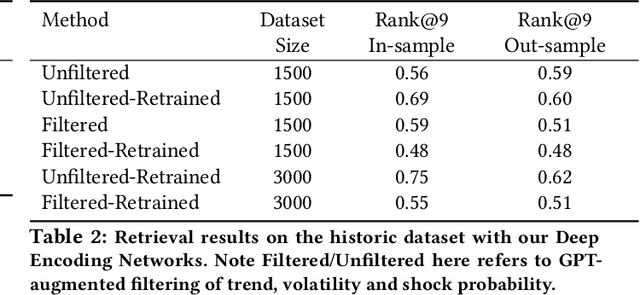
Financial firms commonly process and store billions of time-series data, generated continuously and at a high frequency. To support efficient data storage and retrieval, specialized time-series databases and systems have emerged. These databases support indexing and querying of time-series by a constrained Structured Query Language(SQL)-like format to enable queries like "Stocks with monthly price returns greater than 5%", and expressed in rigid formats. However, such queries do not capture the intrinsic complexity of high dimensional time-series data, which can often be better described by images or language (e.g., "A stock in low volatility regime"). Moreover, the required storage, computational time, and retrieval complexity to search in the time-series space are often non-trivial. In this paper, we propose and demonstrate a framework to store multi-modal data for financial time-series in a lower-dimensional latent space using deep encoders, such that the latent space projections capture not only the time series trends but also other desirable information or properties of the financial time-series data (such as price volatility). Moreover, our approach allows user-friendly query interfaces, enabling natural language text or sketches of time-series, for which we have developed intuitive interfaces. We demonstrate the advantages of our method in terms of computational efficiency and accuracy on real historical data as well as synthetic data, and highlight the utility of latent-space projections in the storage and retrieval of financial time-series data with intuitive query modalities.
How to Model Brushless Electric Motors for the Design of Lightweight Robotic Systems
Sep 29, 2023A key step in the development of lightweight, high performance robotic systems is the modeling and selection of permanent magnet brushless direct current (BLDC) electric motors. Typical modeling analyses are completed a priori, and provide insight for properly sizing a motor for an application, specifying the required operating voltage and current, as well as assessing the thermal response and other design attributes (e.g.transmission ratio). However, to perform these modeling analyses, proper information about the motor's characteristics are needed, which are often obtained from manufacturer datasheets. Through our own experience and communications with manufacturers, we have noticed a lack of clarity and standardization in modeling BLDC motors, compounded by vague or inconsistent terminology used in motor datasheets. The purpose of this tutorial is to concisely describe the governing equations for BLDC motor analyses used in the design process, as well as highlight potential errors that can arise from incorrect usage. We present a power-invariant conversion from phase and line-to-line reference frames to a familiar q-axis DC motor representation, which provides a ``brushed'' analogue of a three phase BLDC motor that is convenient for analysis and design. We highlight potential errors including incorrect calculations of winding resistive heat loss, improper estimation of motor torque via the motor's torque constant, and incorrect estimation of the required bus voltage or resulting angular velocity limitations. A unified and condensed set of governing equations is available for designers in the Appendix. The intent of this work is to provide a consolidated mathematical foundation for modeling BLDC motors that addresses existing confusion and fosters high performance designs of future robotic systems.
Stock Market Sentiment Classification and Backtesting via Fine-tuned BERT
Sep 21, 2023With the rapid development of big data and computing devices, low-latency automatic trading platforms based on real-time information acquisition have become the main components of the stock trading market, so the topic of quantitative trading has received widespread attention. And for non-strongly efficient trading markets, human emotions and expectations always dominate market trends and trading decisions. Therefore, this paper starts from the theory of emotion, taking East Money as an example, crawling user comment titles data from its corresponding stock bar and performing data cleaning. Subsequently, a natural language processing model BERT was constructed, and the BERT model was fine-tuned using existing annotated data sets. The experimental results show that the fine-tuned model has different degrees of performance improvement compared to the original model and the baseline model. Subsequently, based on the above model, the user comment data crawled is labeled with emotional polarity, and the obtained label information is combined with the Alpha191 model to participate in regression, and significant regression results are obtained. Subsequently, the regression model is used to predict the average price change for the next five days, and use it as a signal to guide automatic trading. The experimental results show that the incorporation of emotional factors increased the return rate by 73.8\% compared to the baseline during the trading period, and by 32.41\% compared to the original alpha191 model. Finally, we discuss the advantages and disadvantages of incorporating emotional factors into quantitative trading, and give possible directions for further research in the future.