 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bayesian Design Principles for Frequentist Sequential Learning
Oct 01, 2023
We develop a general theory to optimize the frequentist regret for sequential learning problems, where efficient bandit and reinforcement learning algorithms can be derived from unified Bayesian principles. We propose a novel optimization approach to generate "algorithmic beliefs" at each round, and use Bayesian posteriors to make decisions. The optimization objective to create "algorithmic beliefs," which we term "Algorithmic Information Ratio," represents an intrinsic complexity measure that effectively characterizes the frequentist regret of any algorithm. To the best of our knowledge, this is the first systematical approach to make Bayesian-type algorithms prior-free and applicable to adversarial settings, in a generic and optimal manner. Moreover, the algorithms are simple and often efficient to implement. As a major application, we present a novel algorithm for multi-armed bandits that achieves the "best-of-all-worlds" empirical performance in the stochastic, adversarial, and non-stationary environments. And we illustrate how these principles can be used in linear bandits, bandit convex optimization, and reinforcement learning.
A Task-oriented Dialog Model with Task-progressive and Policy-aware Pre-training
Oct 01, 2023Pre-trained conversation models (PCMs) have achieved promising progress in recent years. However, existing PCMs for Task-oriented dialog (TOD) are insufficient for capturing the sequential nature of the TOD-related tasks, as well as for learning dialog policy information. To alleviate these problems, this paper proposes a task-progressive PCM with two policy-aware pre-training tasks. The model is pre-trained through three stages where TOD-related tasks are progressively employed according to the task logic of the TOD system. A global policy consistency task is designed to capture the multi-turn dialog policy sequential relation, and an act-based contrastive learning task is designed to capture similarities among samples with the same dialog policy. Our model achieves better results on both MultiWOZ and In-Car end-to-end dialog modeling benchmarks with only 18\% parameters and 25\% pre-training data compared to the previous state-of-the-art PCM, GALAXY.
Information-Theoretic Characterization of Vowel Harmony: A Cross-Linguistic Study on Word Lists
Aug 09, 2023
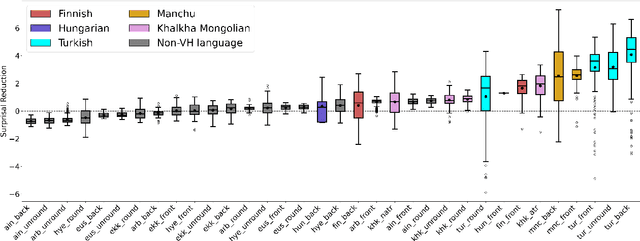
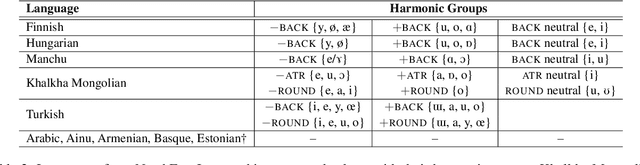
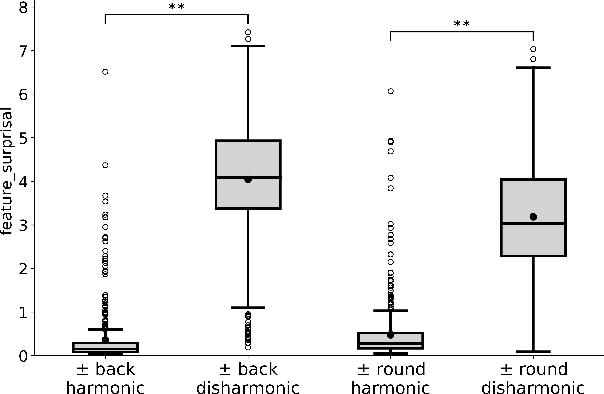
We present a cross-linguistic study that aims to quantify vowel harmony using data-driven computational modeling. Concretely, we define an information-theoretic measure of harmonicity based on the predictability of vowels in a natural language lexicon, which we estimate using phoneme-level language models (PLMs). Prior quantitative studies have relied heavily on inflected word-forms in the analysis of vowel harmony. We instead train our models using cross-linguistically comparable lemma forms with little or no inflection, which enables us to cover more under-studied languages. Training data for our PLMs consists of word lists with a maximum of 1000 entries per language. Despite the fact that the data we employ are substantially smaller than previously used corpora, our experiments demonstrate the neural PLMs capture vowel harmony patterns in a set of languages that exhibit this phenomenon. Our work also demonstrates that word lists are a valuable resource for typological research, and offers new possibilities for future studies on low-resource, under-studied languages.
Towards End-to-End Embodied Decision Making via Multi-modal Large Language Model: Explorations with GPT4-Vision and Beyond
Oct 03, 2023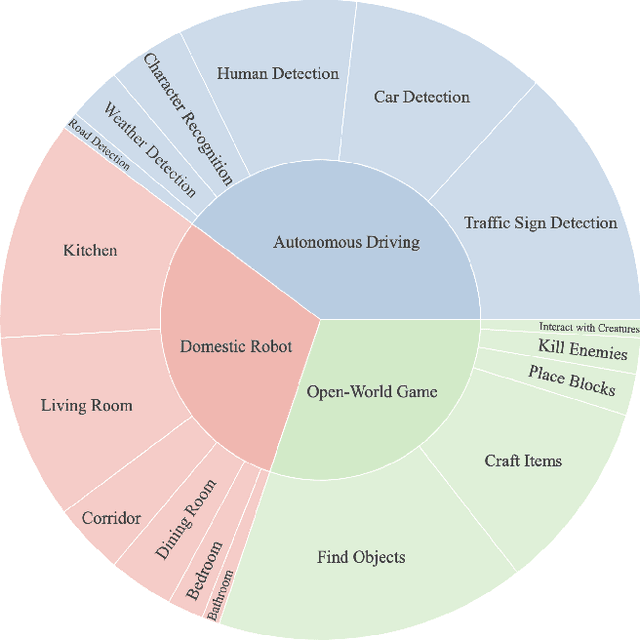
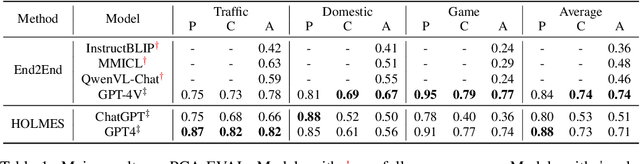

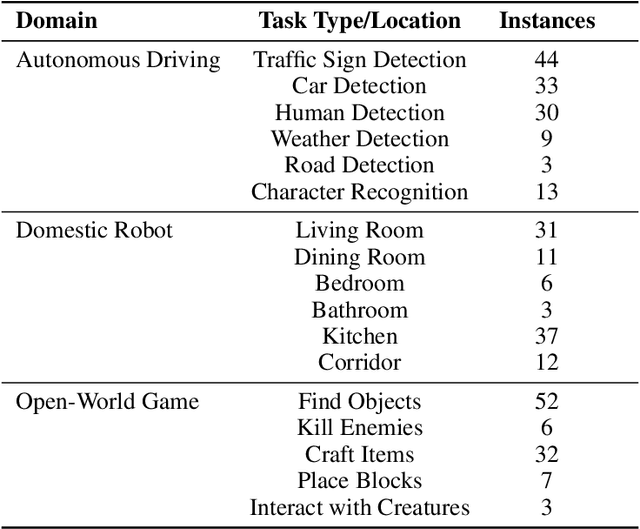
In this study, we explore the potential of Multimodal Large Language Models (MLLMs) in improving embodied decision-making processes for agents. While Large Language Models (LLMs) have been widely used due to their advanced reasoning skills and vast world knowledge, MLLMs like GPT4-Vision offer enhanced visual understanding and reasoning capabilities. We investigate whether state-of-the-art MLLMs can handle embodied decision-making in an end-to-end manner and whether collaborations between LLMs and MLLMs can enhance decision-making. To address these questions, we introduce a new benchmark called PCA-EVAL, which evaluates embodied decision-making from the perspectives of Perception, Cognition, and Action. Additionally, we propose HOLMES, a multi-agent cooperation framework that allows LLMs to leverage MLLMs and APIs to gather multimodal information for informed decision-making. We compare end-to-end embodied decision-making and HOLMES on our benchmark and find that the GPT4-Vision model demonstrates strong end-to-end embodied decision-making abilities, outperforming GPT4-HOLMES in terms of average decision accuracy (+3%). However, this performance is exclusive to the latest GPT4-Vision model, surpassing the open-source state-of-the-art MLLM by 26%. Our results indicate that powerful MLLMs like GPT4-Vision hold promise for decision-making in embodied agents, offering new avenues for MLLM research.
OCU-Net: A Novel U-Net Architecture for Enhanced Oral Cancer Segmentation
Oct 03, 2023Accurate detection of oral cancer is crucial for improving patient outcomes. However, the field faces two key challenges: the scarcity of deep learning-based image segmentation research specifically targeting oral cancer and the lack of annotated data. Our study proposes OCU-Net, a pioneering U-Net image segmentation architecture exclusively designed to detect oral cancer in hematoxylin and eosin (H&E) stained image datasets. OCU-Net incorporates advanced deep learning modules, such as the Channel and Spatial Attention Fusion (CSAF) module, a novel and innovative feature that emphasizes important channel and spatial areas in H&E images while exploring contextual information. In addition, OCU-Net integrates other innovative components such as Squeeze-and-Excite (SE) attention module, Atrous Spatial Pyramid Pooling (ASPP) module, residual blocks, and multi-scale fusion. The incorporation of these modules showed superior performance for oral cancer segmentation for two datasets used in this research. Furthermore, we effectively utilized the efficient ImageNet pre-trained MobileNet-V2 model as a backbone of our OCU-Net to create OCU-Netm, an enhanced version achieving state-of-the-art results. Comprehensive evaluation demonstrates that OCU-Net and OCU-Netm outperformed existing segmentation methods, highlighting their precision in identifying cancer cells in H&E images from OCDC and ORCA datasets.
EMBERSim: A Large-Scale Databank for Boosting Similarity Search in Malware Analysis
Oct 03, 2023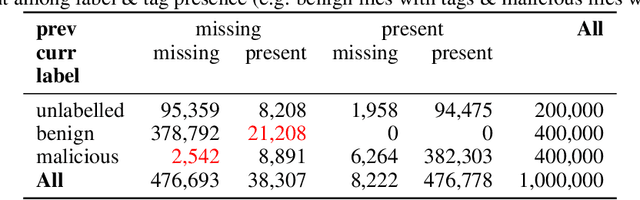
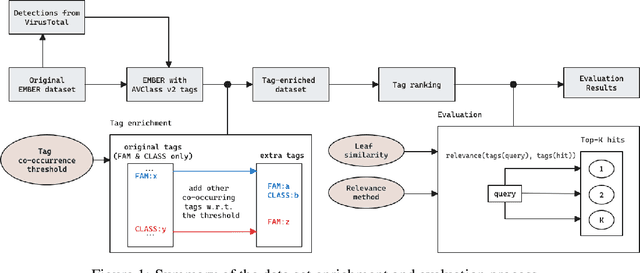
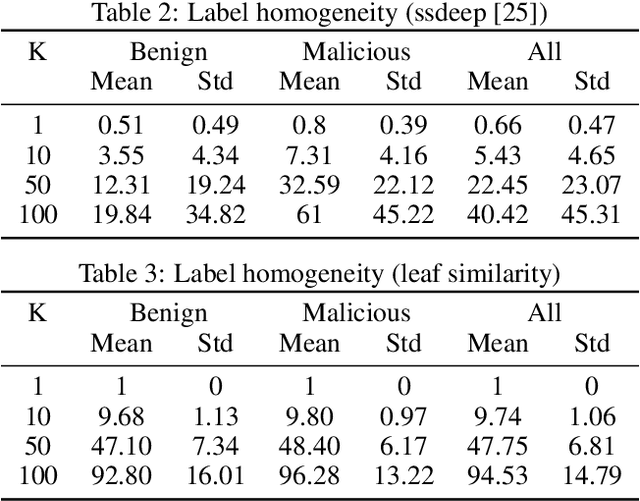
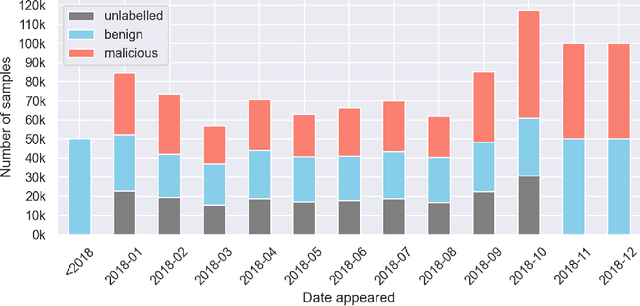
In recent years there has been a shift from heuristics-based malware detection towards machine learning, which proves to be more robust in the current heavily adversarial threat landscape. While we acknowledge machine learning to be better equipped to mine for patterns in the increasingly high amounts of similar-looking files, we also note a remarkable scarcity of the data available for similarity-targeted research. Moreover, we observe that the focus in the few related works falls on quantifying similarity in malware, often overlooking the clean data. This one-sided quantification is especially dangerous in the context of detection bypass. We propose to address the deficiencies in the space of similarity research on binary files, starting from EMBER - one of the largest malware classification data sets. We enhance EMBER with similarity information as well as malware class tags, to enable further research in the similarity space. Our contribution is threefold: (1) we publish EMBERSim, an augmented version of EMBER, that includes similarity-informed tags; (2) we enrich EMBERSim with automatically determined malware class tags using the open-source tool AVClass on VirusTotal data and (3) we describe and share the implementation for our class scoring technique and leaf similarity method.
Unsupervised Complex Semi-Binary Matrix Factorization for Activation Sequence Recovery of Quasi-Stationary Sources
Oct 03, 2023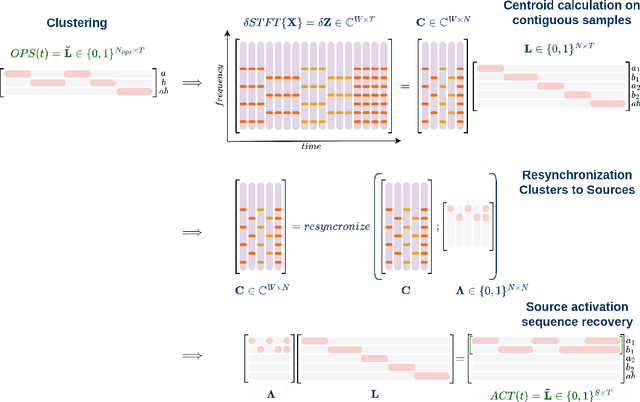
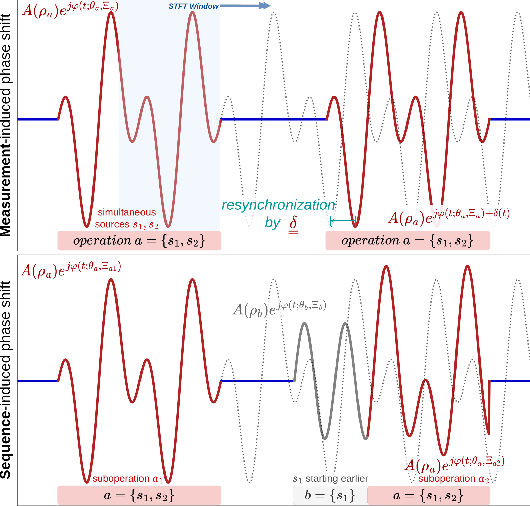
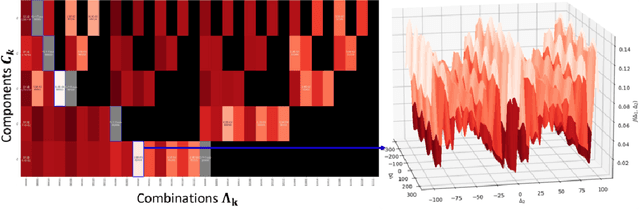
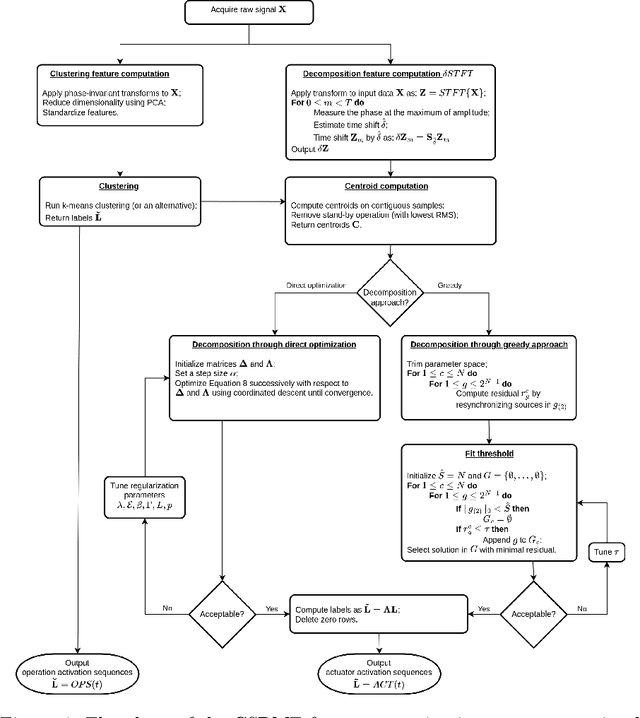
Advocating for a sustainable, resilient and human-centric industry, the three pillars of Industry 5.0 call for an increased understanding of industrial processes and manufacturing systems, as well as their energy sustainability. One of the most fundamental elements of comprehension is knowing when the systems are operated, as this is key to locating energy intensive subsystems and operations. Such knowledge is often lacking in practice. Activation statuses can be recovered from sensor data though. Some non-intrusive sensors (accelerometers, current sensors, etc.) acquire mixed signals containing information about multiple actuators at once. Despite their low cost as regards the fleet of systems they monitor, additional signal processing is required to extract the individual activation sequences. To that end, sparse regression techniques can extract leading dynamics in sequential data. Notorious dictionary learning algorithms have proven effective in this regard. This paper considers different industrial settings in which the identification of binary subsystem activation sequences is sought. In this context, it is assumed that each sensor measures an extensive physical property, source signals are periodic, quasi-stationary and independent, albeit these signals may be correlated and their noise distribution is arbitrary. Existing methods either restrict these assumptions, e.g., by imposing orthogonality or noise characteristics, or lift them using additional assumptions, typically using nonlinear transforms.
Human Action Co-occurrence in Lifestyle Vlogs using Graph Link Prediction
Sep 22, 2023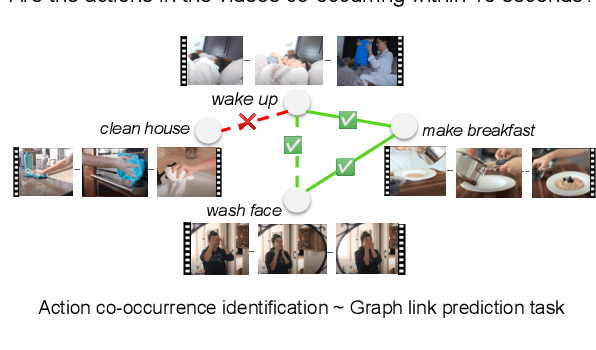
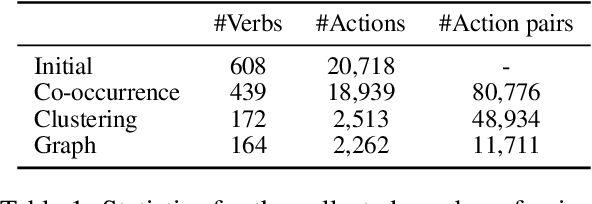
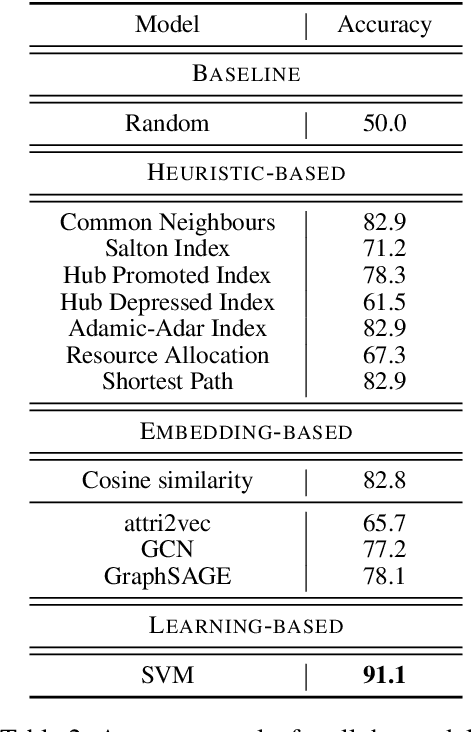
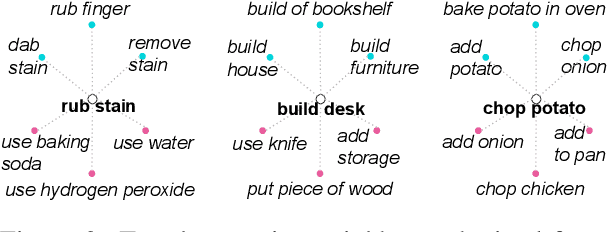
We introduce the task of automatic human action co-occurrence identification, i.e., determine whether two human actions can co-occur in the same interval of time. We create and make publicly available the ACE (Action Co-occurrencE) dataset, consisting of a large graph of ~12k co-occurring pairs of visual actions and their corresponding video clips. We describe graph link prediction models that leverage visual and textual information to automatically infer if two actions are co-occurring. We show that graphs are particularly well suited to capture relations between human actions, and the learned graph representations are effective for our task and capture novel and relevant information across different data domains. The ACE dataset and the code introduced in this paper are publicly available at https://github.com/MichiganNLP/vlog_action_co-occurrence.
Using AI Uncertainty Quantification to Improve Human Decision-Making
Sep 19, 2023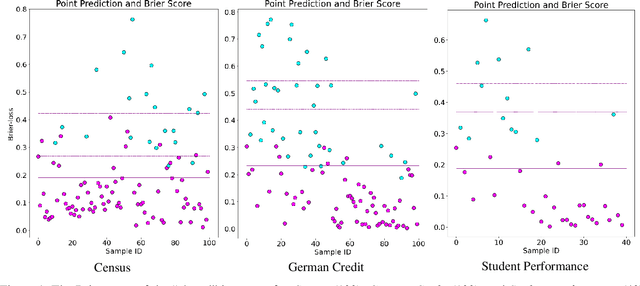
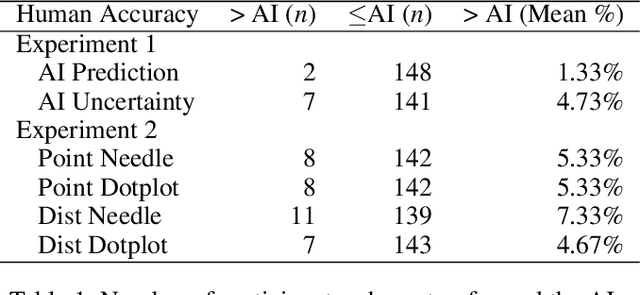
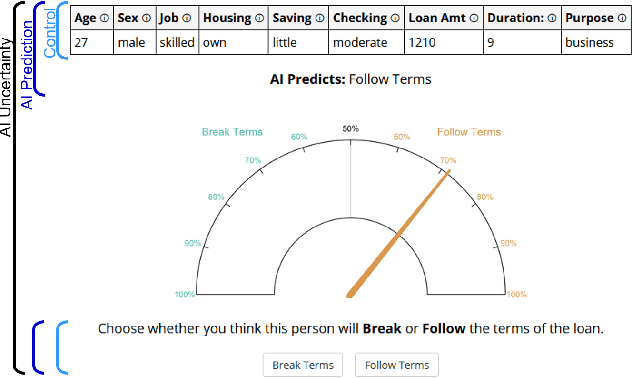
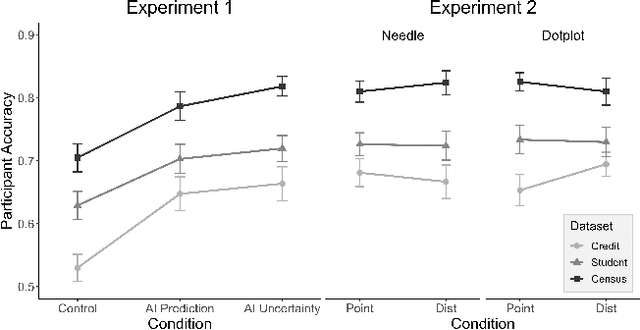
AI Uncertainty Quantification (UQ) has the potential to improve human decision-making beyond AI predictions alone by providing additional useful probabilistic information to users. The majority of past research on AI and human decision-making has concentrated on model explainability and interpretability. We implemented instance-based UQ for three real datasets. To achieve this, we trained different AI models for classification for each dataset, and used random samples generated around the neighborhood of the given instance to create confidence intervals for UQ. The computed UQ was calibrated using a strictly proper scoring rule as a form of quality assurance for UQ. We then conducted two preregistered online behavioral experiments that compared objective human decision-making performance under different AI information conditions, including UQ. In Experiment 1, we compared decision-making for no AI (control), AI prediction alone, and AI prediction with a visualization of UQ. We found UQ significantly improved decision-making beyond the other two conditions. In Experiment 2, we focused on comparing different representations of UQ information: Point vs. distribution of uncertainty and visualization type (needle vs. dotplot). We did not find meaningful differences in decision-making performance among these different representations of UQ. Overall, our results indicate that human decision-making can be improved by providing UQ information along with AI predictions, and that this benefit generalizes across a variety of representations of UQ.
GelSight Svelte: A Human Finger-shaped Single-camera Tactile Robot Finger with Large Sensing Coverage and Proprioceptive Sensing
Sep 19, 2023Camera-based tactile sensing is a low-cost, popular approach to obtain highly detailed contact geometry information. However, most existing camera-based tactile sensors are fingertip sensors, and longer fingers often require extraneous elements to obtain an extended sensing area similar to the full length of a human finger. Moreover, existing methods to estimate proprioceptive information such as total forces and torques applied on the finger from camera-based tactile sensors are not effective when the contact geometry is complex. We introduce GelSight Svelte, a curved, human finger-sized, single-camera tactile sensor that is capable of both tactile and proprioceptive sensing over a large area. GelSight Svelte uses curved mirrors to achieve the desired shape and sensing coverage. Proprioceptive information, such as the total bending and twisting torques applied on the finger, is reflected as deformations on the flexible backbone of GelSight Svelte, which are also captured by the camera. We train a convolutional neural network to estimate the bending and twisting torques from the captured images. We conduct gel deformation experiments at various locations of the finger to evaluate the tactile sensing capability and proprioceptive sensing accuracy. To demonstrate the capability and potential uses of GelSight Svelte, we conduct an object holding task with three different grasping modes that utilize different areas of the finger. More information is available on our website: https://gelsight-svelte.alanz.info