 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Apr 01, 2024
A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
On the Faithfulness of Vision Transformer Explanations
Apr 01, 2024To interpret Vision Transformers, post-hoc explanations assign salience scores to input pixels, providing human-understandable heatmaps. However, whether these interpretations reflect true rationales behind the model's output is still underexplored. To address this gap, we study the faithfulness criterion of explanations: the assigned salience scores should represent the influence of the corresponding input pixels on the model's predictions. To evaluate faithfulness, we introduce Salience-guided Faithfulness Coefficient (SaCo), a novel evaluation metric leveraging essential information of salience distribution. Specifically, we conduct pair-wise comparisons among distinct pixel groups and then aggregate the differences in their salience scores, resulting in a coefficient that indicates the explanation's degree of faithfulness. Our explorations reveal that current metrics struggle to differentiate between advanced explanation methods and Random Attribution, thereby failing to capture the faithfulness property. In contrast, our proposed SaCo offers a reliable faithfulness measurement, establishing a robust metric for interpretations. Furthermore, our SaCo demonstrates that the use of gradient and multi-layer aggregation can markedly enhance the faithfulness of attention-based explanation, shedding light on potential paths for advancing Vision Transformer explainability.
Position-Aware Parameter Efficient Fine-Tuning Approach for Reducing Positional Bias in LLMs
Apr 01, 2024Recent advances in large language models (LLMs) have enhanced their ability to process long input contexts. This development is particularly crucial for tasks that involve retrieving knowledge from an external datastore, which can result in long inputs. However, recent studies show a positional bias in LLMs, demonstrating varying performance depending on the location of useful information within the input sequence. In this study, we conduct extensive experiments to investigate the root causes of positional bias. Our findings indicate that the primary contributor to LLM positional bias stems from the inherent positional preferences of different models. We demonstrate that merely employing prompt-based solutions is inadequate for overcoming the positional preferences. To address this positional bias issue of a pre-trained LLM, we developed a Position-Aware Parameter Efficient Fine-Tuning (PAPEFT) approach which is composed of a data augmentation technique and a parameter efficient adapter, enhancing a uniform attention distribution across the input context. Our experiments demonstrate that the proposed approach effectively reduces positional bias, improving LLMs' effectiveness in handling long context sequences for various tasks that require externally retrieved knowledge.
V2X Enabled Emergency Vehicle Alert System
Mar 28, 2024
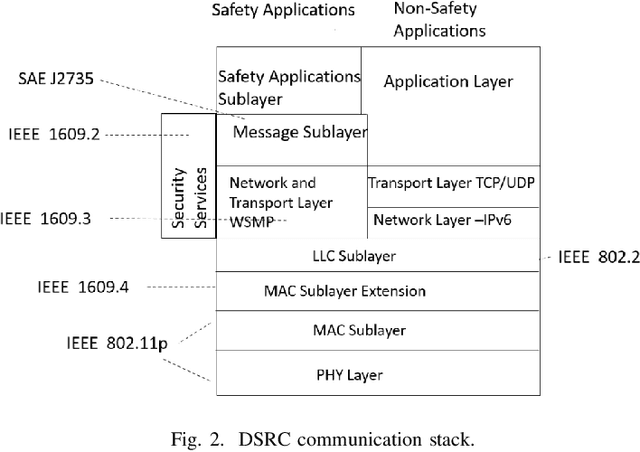


Today's major concern in traffic management systems includes time-efficient emergency transports. The awareness of environment and vehicle information is necessary for the emergency vehicles as well as the surrounding commercial vehicles that might be driven by inexperienced drivers to act accordingly if they both interact. The information exchange should be quick and accurate along with how much interactive the alerting system is with the drivers. Therefore, technologies like V2X-based alert systems can deal with such emergency situations and hence prevent potential health or social hazards. An alerting system as a part of a smart-connected city is proposed in this paper. The Dedicated Short Range Communication (DSRC) based system has tried to cover the major domain of information about misbehaving vehicles, any pedestrians on the road, and information about the emergency vehicle itself. The commercial vehicle also will have a similar alert system as an application of V2V and V2I. Further in this paper, a realtime monitoring system was developed using grafana dashboard which will be installed in the area's base station to monitor the vehicles in that area.
From attention to profit: quantitative trading strategy based on transformer
Mar 30, 2024In traditional quantitative trading practice, navigating the complicated and dynamic financial market presents a persistent challenge. Former machine learning approaches have struggled to fully capture various market variables, often ignore long-term information and fail to catch up with essential signals that may lead the profit. This paper introduces an enhanced transformer architecture and designs a novel factor based on the model. By transfer learning from sentiment analysis, the proposed model not only exploits its original inherent advantages in capturing long-range dependencies and modelling complex data relationships but is also able to solve tasks with numerical inputs and accurately forecast future returns over a period. This work collects more than 5,000,000 rolling data of 4,601 stocks in the Chinese capital market from 2010 to 2019. The results of this study demonstrated the model's superior performance in predicting stock trends compared with other 100 factor-based quantitative strategies with lower turnover rates and a more robust half-life period. Notably, the model's innovative use transformer to establish factors, in conjunction with market sentiment information, has been shown to enhance the accuracy of trading signals significantly, thereby offering promising implications for the future of quantitative trading strategies.
PROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Mar 30, 2024Large language models (LLMs) have shown exceptional abilities for multiple different natural language processing tasks. While prompting is a crucial tool for LLM inference, we observe that there is a significant cost associated with exceedingly lengthy prompts. Existing attempts to compress lengthy prompts lead to sub-standard results in terms of readability and interpretability of the compressed prompt, with a detrimental impact on prompt utility. To address this, we propose PROMPT-SAW: Prompt compresSion via Relation AWare graphs, an effective strategy for prompt compression over task-agnostic and task-aware prompts. PROMPT-SAW uses the prompt's textual information to build a graph, later extracts key information elements in the graph to come up with the compressed prompt. We also propose GSM8K-AUG, i.e., an extended version of the existing GSM8k benchmark for task-agnostic prompts in order to provide a comprehensive evaluation platform. Experimental evaluation using benchmark datasets shows that prompts compressed by PROMPT-SAW are not only better in terms of readability, but they also outperform the best-performing baseline models by up to 14.3 and 13.7 respectively for task-aware and task-agnostic settings while compressing the original prompt text by 33.0 and 56.7.
YNetr: Dual-Encoder architecture on Plain Scan Liver Tumors (PSLT)
Mar 30, 2024Background: Liver tumors are abnormal growths in the liver that can be either benign or malignant, with liver cancer being a significant health concern worldwide. However, there is no dataset for plain scan segmentation of liver tumors, nor any related algorithms. To fill this gap, we propose Plain Scan Liver Tumors(PSLT) and YNetr. Methods: A collection of 40 liver tumor plain scan segmentation datasets was assembled and annotated. Concurrently, we utilized Dice coefficient as the metric for assessing the segmentation outcomes produced by YNetr, having advantage of capturing different frequency information. Results: The YNetr model achieved a Dice coefficient of 62.63% on the PSLT dataset, surpassing the other publicly available model by an accuracy margin of 1.22%. Comparative evaluations were conducted against a range of models including UNet 3+, XNet, UNetr, Swin UNetr, Trans-BTS, COTr, nnUNetv2 (2D), nnUNetv2 (3D fullres), MedNext (2D) and MedNext(3D fullres). Conclusions: We not only proposed a dataset named PSLT(Plain Scan Liver Tumors), but also explored a structure called YNetr that utilizes wavelet transform to extract different frequency information, which having the SOTA in PSLT by experiments.
Enhancing Content-based Recommendation via Large Language Model
Mar 30, 2024In real-world applications, users express different behaviors when they interact with different items, including implicit click/like interactions, and explicit comments/reviews interactions. Nevertheless, almost all recommender works are focused on how to describe user preferences by the implicit click/like interactions, to find the synergy of people. For the content-based explicit comments/reviews interactions, some works attempt to utilize them to mine the semantic knowledge to enhance recommender models. However, they still neglect the following two points: (1) The content semantic is a universal world knowledge; how do we extract the multi-aspect semantic information to empower different domains? (2) The user/item ID feature is a fundamental element for recommender models; how do we align the ID and content semantic feature space? In this paper, we propose a `plugin' semantic knowledge transferring method \textbf{LoID}, which includes two major components: (1) LoRA-based large language model pretraining to extract multi-aspect semantic information; (2) ID-based contrastive objective to align their feature spaces. We conduct extensive experiments with SOTA baselines on real-world datasets, the detailed results demonstrating significant improvements of our method LoID.
Review-Based Cross-Domain Recommendation via Hyperbolic Embedding and Hierarchy-Aware Domain Disentanglement
Mar 29, 2024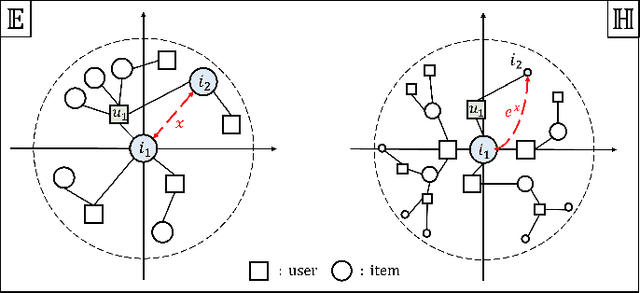
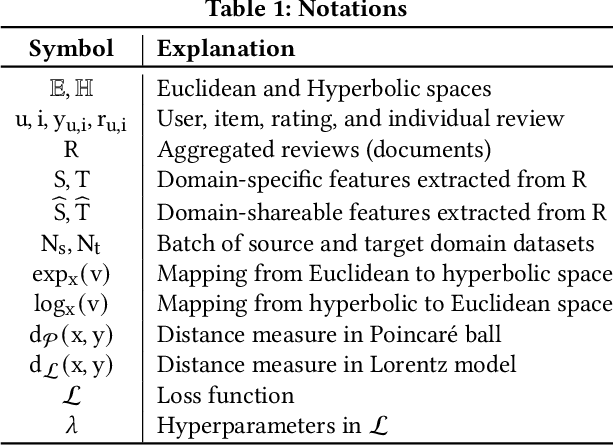
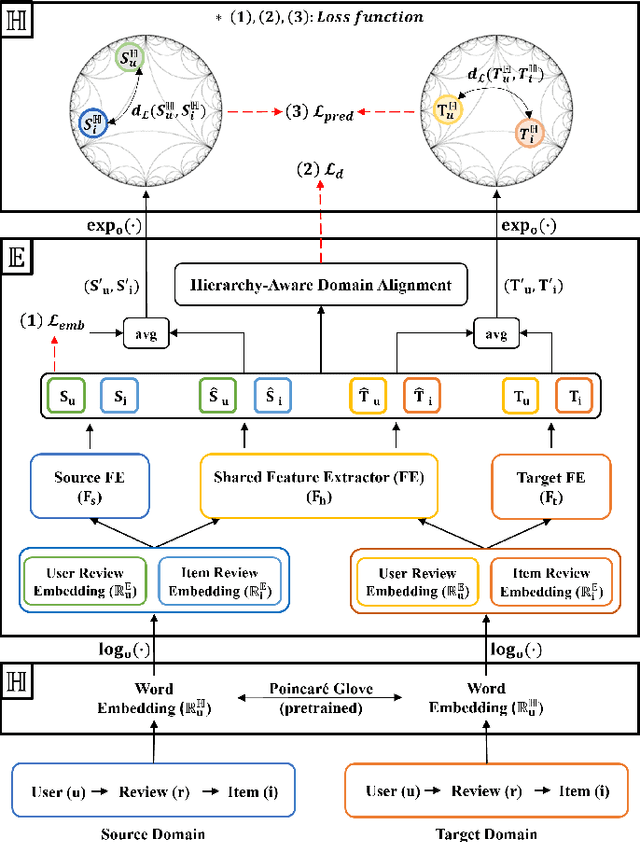
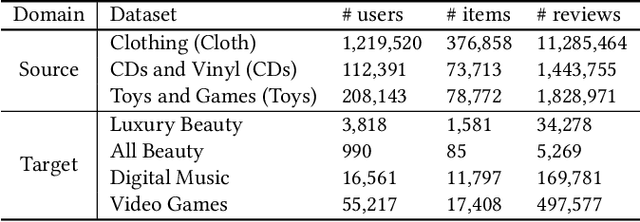
The issue of data sparsity poses a significant challenge to recommender systems. In response to this, algorithms that leverage side information such as review texts have been proposed. Furthermore, Cross-Domain Recommendation (CDR), which captures domain-shareable knowledge and transfers it from a richer domain (source) to a sparser one (target), has received notable attention. Nevertheless, the majority of existing methodologies assume a Euclidean embedding space, encountering difficulties in accurately representing richer text information and managing complex interactions between users and items. This paper advocates a hyperbolic CDR approach based on review texts for modeling user-item relationships. We first emphasize that conventional distance-based domain alignment techniques may cause problems because small modifications in hyperbolic geometry result in magnified perturbations, ultimately leading to the collapse of hierarchical structures. To address this challenge, we propose hierarchy-aware embedding and domain alignment schemes that adjust the scale to extract domain-shareable information without disrupting structural forms. The process involves the initial embedding of review texts in hyperbolic space, followed by feature extraction incorporating degree-based normalization and structure alignment. We conducted extensive experiments to substantiate the efficiency, robustness, and scalability of our proposed model in comparison to state-of-the-art baselines.
CuSINeS: Curriculum-driven Structure Induced Negative Sampling for Statutory Article Retrieval
Mar 31, 2024In this paper, we introduce CuSINeS, a negative sampling approach to enhance the performance of Statutory Article Retrieval (SAR). CuSINeS offers three key contributions. Firstly, it employs a curriculum-based negative sampling strategy guiding the model to focus on easier negatives initially and progressively tackle more difficult ones. Secondly, it leverages the hierarchical and sequential information derived from the structural organization of statutes to evaluate the difficulty of samples. Lastly, it introduces a dynamic semantic difficulty assessment using the being-trained model itself, surpassing conventional static methods like BM25, adapting the negatives to the model's evolving competence. Experimental results on a real-world expert-annotated SAR dataset validate the effectiveness of CuSINeS across four different baselines, demonstrating its versatility.