 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VISER: A Tractable Solution Concept for Games with Information Asymmetry
Jul 18, 2023



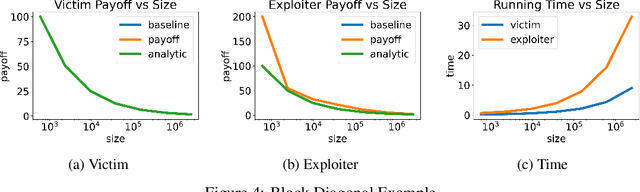
Many real-world games suffer from information asymmetry: one player is only aware of their own payoffs while the other player has the full game information. Examples include the critical domain of security games and adversarial multi-agent reinforcement learning. Information asymmetry renders traditional solution concepts such as Strong Stackelberg Equilibrium (SSE) and Robust-Optimization Equilibrium (ROE) inoperative. We propose a novel solution concept called VISER (Victim Is Secure, Exploiter best-Responds). VISER enables an external observer to predict the outcome of such games. In particular, for security applications, VISER allows the victim to better defend itself while characterizing the most damaging attacks available to the attacker. We show that each player's VISER strategy can be computed independently in polynomial time using linear programming (LP). We also extend VISER to its Markov-perfect counterpart for Markov games, which can be solved efficiently using a series of LPs.
Wavelet-based Topological Loss for Low-Light Image Denoising
Sep 20, 2023Despite extensive research conducted in the field of image denoising, many algorithms still heavily depend on supervised learning and their effectiveness primarily relies on the quality and diversity of training data. It is widely assumed that digital image distortions are caused by spatially invariant Additive White Gaussian Noise (AWGN). However, the analysis of real-world data suggests that this assumption is invalid. Therefore, this paper tackles image corruption by real noise, providing a framework to capture and utilise the underlying structural information of an image along with the spatial information conventionally used for deep learning tasks. We propose a novel denoising loss function that incorporates topological invariants and is informed by textural information extracted from the image wavelet domain. The effectiveness of this proposed method was evaluated by training state-of-the-art denoising models on the BVI-Lowlight dataset, which features a wide range of real noise distortions. Adding a topological term to common loss functions leads to a significant increase in the LPIPS (Learned Perceptual Image Patch Similarity) metric, with the improvement reaching up to 25\%. The results indicate that the proposed loss function enables neural networks to learn noise characteristics better. We demonstrate that they can consequently extract the topological features of noise-free images, resulting in enhanced contrast and preserved textural information.
Trustworthy Formal Natural Language Specifications
Oct 05, 2023Interactive proof assistants are computer programs carefully constructed to check a human-designed proof of a mathematical claim with high confidence in the implementation. However, this only validates truth of a formal claim, which may have been mistranslated from a claim made in natural language. This is especially problematic when using proof assistants to formally verify the correctness of software with respect to a natural language specification. The translation from informal to formal remains a challenging, time-consuming process that is difficult to audit for correctness. This paper shows that it is possible to build support for specifications written in expressive subsets of natural language, within existing proof assistants, consistent with the principles used to establish trust and auditability in proof assistants themselves. We implement a means to provide specifications in a modularly extensible formal subset of English, and have them automatically translated into formal claims, entirely within the Lean proof assistant. Our approach is extensible (placing no permanent restrictions on grammatical structure), modular (allowing information about new words to be distributed alongside libraries), and produces proof certificates explaining how each word was interpreted and how the sentence's structure was used to compute the meaning. We apply our prototype to the translation of various English descriptions of formal specifications from a popular textbook into Lean formalizations; all can be translated correctly with a modest lexicon with only minor modifications related to lexicon size.
* arXiv admin note: substantial text overlap with arXiv:2205.07811
How the level sampling process impacts zero-shot generalisation in deep reinforcement learning
Oct 05, 2023A key limitation preventing the wider adoption of autonomous agents trained via deep reinforcement learning (RL) is their limited ability to generalise to new environments, even when these share similar characteristics with environments encountered during training. In this work, we investigate how a non-uniform sampling strategy of individual environment instances, or levels, affects the zero-shot generalisation (ZSG) ability of RL agents, considering two failure modes: overfitting and over-generalisation. As a first step, we measure the mutual information (MI) between the agent's internal representation and the set of training levels, which we find to be well-correlated to instance overfitting. In contrast to uniform sampling, adaptive sampling strategies prioritising levels based on their value loss are more effective at maintaining lower MI, which provides a novel theoretical justification for this class of techniques. We then turn our attention to unsupervised environment design (UED) methods, which adaptively generate new training levels and minimise MI more effectively than methods sampling from a fixed set. However, we find UED methods significantly shift the training distribution, resulting in over-generalisation and worse ZSG performance over the distribution of interest. To prevent both instance overfitting and over-generalisation, we introduce self-supervised environment design (SSED). SSED generates levels using a variational autoencoder, effectively reducing MI while minimising the shift with the distribution of interest, and leads to statistically significant improvements in ZSG over fixed-set level sampling strategies and UED methods.
EAG-RS: A Novel Explainability-guided ROI-Selection Framework for ASD Diagnosis via Inter-regional Relation Learning
Oct 05, 2023Deep learning models based on resting-state functional magnetic resonance imaging (rs-fMRI) have been widely used to diagnose brain diseases, particularly autism spectrum disorder (ASD). Existing studies have leveraged the functional connectivity (FC) of rs-fMRI, achieving notable classification performance. However, they have significant limitations, including the lack of adequate information while using linear low-order FC as inputs to the model, not considering individual characteristics (i.e., different symptoms or varying stages of severity) among patients with ASD, and the non-explainability of the decision process. To cover these limitations, we propose a novel explainability-guided region of interest (ROI) selection (EAG-RS) framework that identifies non-linear high-order functional associations among brain regions by leveraging an explainable artificial intelligence technique and selects class-discriminative regions for brain disease identification. The proposed framework includes three steps: (i) inter-regional relation learning to estimate non-linear relations through random seed-based network masking, (ii) explainable connection-wise relevance score estimation to explore high-order relations between functional connections, and (iii) non-linear high-order FC-based diagnosis-informative ROI selection and classifier learning to identify ASD. We validated the effectiveness of our proposed method by conducting experiments using the Autism Brain Imaging Database Exchange (ABIDE) dataset, demonstrating that the proposed method outperforms other comparative methods in terms of various evaluation metrics. Furthermore, we qualitatively analyzed the selected ROIs and identified ASD subtypes linked to previous neuroscientific studies.
U-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning
Oct 06, 2023Zero-shot speaker cloning aims to synthesize speech for any target speaker unseen during TTS system building, given only a single speech reference of the speaker at hand. Although more practical in real applications, the current zero-shot methods still produce speech with undesirable naturalness and speaker similarity. Moreover, endowing the target speaker with arbitrary speaking styles in the zero-shot setup has not been considered. This is because the unique challenge of zero-shot speaker and style cloning is to learn the disentangled speaker and style representations from only short references representing an arbitrary speaker and an arbitrary style. To address this challenge, we propose U-Style, which employs Grad-TTS as the backbone, particularly cascading a speaker-specific encoder and a style-specific encoder between the text encoder and the diffusion decoder. Thus, leveraging signal perturbation, U-Style is explicitly decomposed into speaker- and style-specific modeling parts, achieving better speaker and style disentanglement. To improve unseen speaker and style modeling ability, these two encoders conduct multi-level speaker and style modeling by skip-connected U-nets, incorporating the representation extraction and information reconstruction process. Besides, to improve the naturalness of synthetic speech, we adopt mean-based instance normalization and style adaptive layer normalization in these encoders to perform representation extraction and condition adaptation, respectively. Experiments show that U-Style significantly surpasses the state-of-the-art methods in unseen speaker cloning regarding naturalness and speaker similarity. Notably, U-Style can transfer the style from an unseen source speaker to another unseen target speaker, achieving flexible combinations of desired speaker timbre and style in zero-shot voice cloning.
Accurate and Fast Compressed Video Captioning
Sep 22, 2023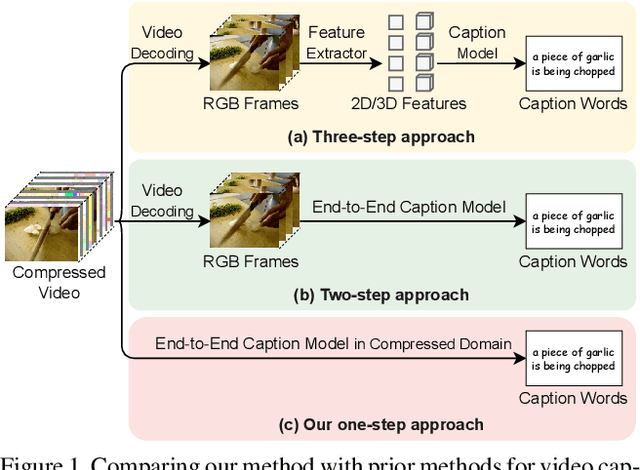
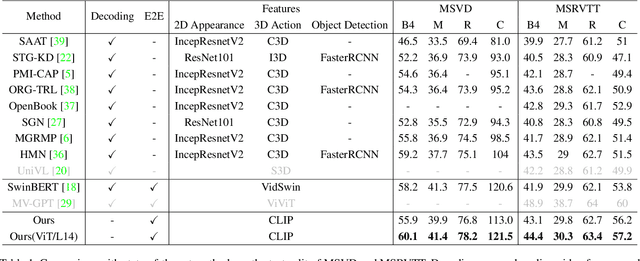
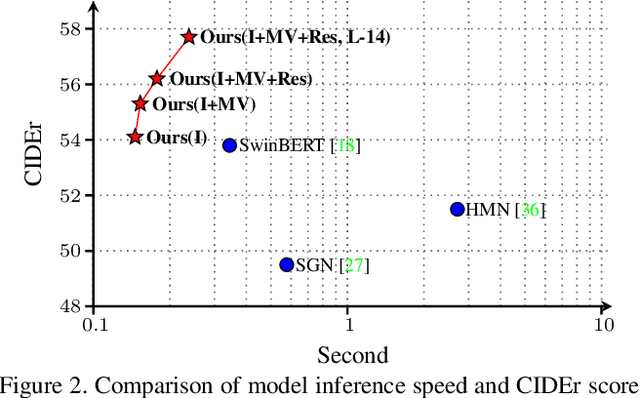
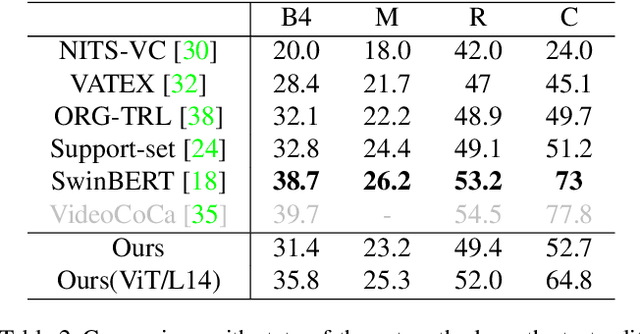
Existing video captioning approaches typically require to first sample video frames from a decoded video and then conduct a subsequent process (e.g., feature extraction and/or captioning model learning). In this pipeline, manual frame sampling may ignore key information in videos and thus degrade performance. Additionally, redundant information in the sampled frames may result in low efficiency in the inference of video captioning. Addressing this, we study video captioning from a different perspective in compressed domain, which brings multi-fold advantages over the existing pipeline: 1) Compared to raw images from the decoded video, the compressed video, consisting of I-frames, motion vectors and residuals, is highly distinguishable, which allows us to leverage the entire video for learning without manual sampling through a specialized model design; 2) The captioning model is more efficient in inference as smaller and less redundant information is processed. We propose a simple yet effective end-to-end transformer in the compressed domain for video captioning that enables learning from the compressed video for captioning. We show that even with a simple design, our method can achieve state-of-the-art performance on different benchmarks while running almost 2x faster than existing approaches. Code is available at https://github.com/acherstyx/CoCap.
PAD-Phys: Exploiting Physiology for Presentation Attack Detection in Face Biometrics
Oct 03, 2023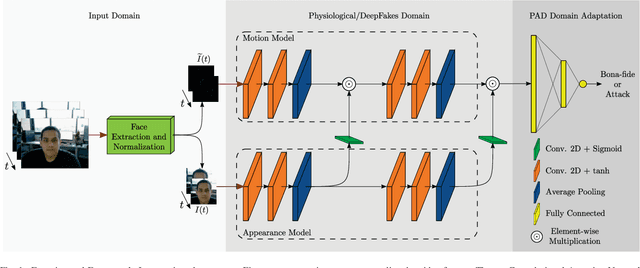
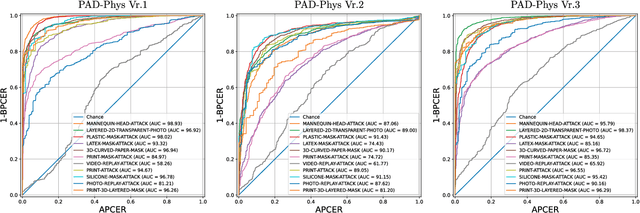
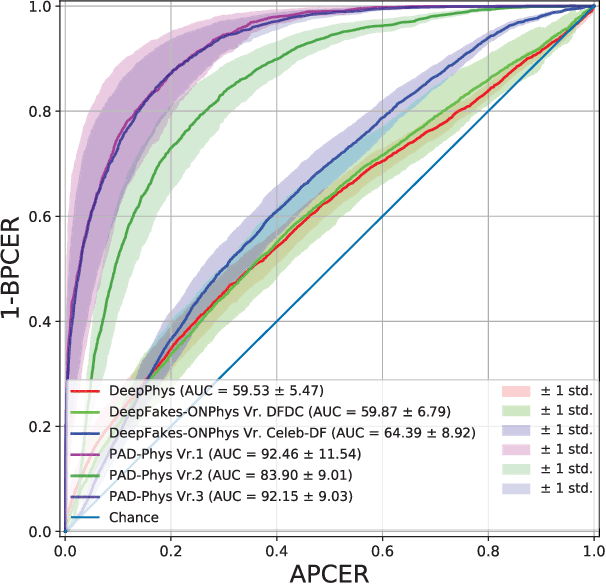
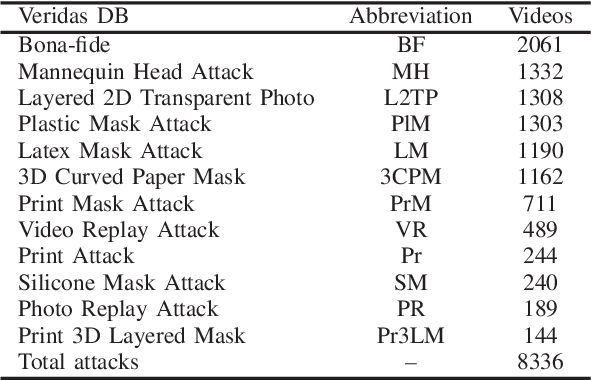
Presentation Attack Detection (PAD) is a crucial stage in facial recognition systems to avoid leakage of personal information or spoofing of identity to entities. Recently, pulse detection based on remote photoplethysmography (rPPG) has been shown to be effective in face presentation attack detection. This work presents three different approaches to the presentation attack detection based on rPPG: (i) The physiological domain, a domain using rPPG-based models, (ii) the Deepfakes domain, a domain where models were retrained from the physiological domain to specific Deepfakes detection tasks; and (iii) a new Presentation Attack domain was trained by applying transfer learning from the two previous domains to improve the capability to differentiate between bona-fides and attacks. The results show the efficiency of the rPPG-based models for presentation attack detection, evidencing a 21.70% decrease in average classification error rate (ACER) (from 41.03% to 19.32%) when the presentation attack domain is compared to the physiological and Deepfakes domains. Our experiments highlight the efficiency of transfer learning in rPPG-based models and perform well in presentation attack detection in instruments that do not allow copying of this physiological feature.
Linearization of ReLU Activation Function for Neural Network-Embedded Optimization:Optimal Day-Ahead Energy Scheduling
Oct 03, 2023Neural networks have been widely applied in the power system area. They can be used for better predicting input information and modeling system performance with increased accuracy. In some applications such as battery degradation neural network-based microgrid day-ahead energy scheduling, the input features of the trained learning model are variables to be solved in optimization models that enforce limits on the output of the same learning model. This will create a neural network-embedded optimization problem; the use of nonlinear activation functions in the neural network will make such problems extremely hard to solve if not unsolvable. To address this emerging challenge, this paper investigated different methods for linearizing the nonlinear activation functions with a particular focus on the widely used rectified linear unit (ReLU) function. Four linearization methods tailored for the ReLU activation function are developed, analyzed and compared in this paper. Each method employs a set of linear constraints to replace the ReLU function, effectively linearizing the optimization problem, which can overcome the computational challenges associated with the nonlinearity of the neural network model. These proposed linearization methods provide valuable tools for effectively solving optimization problems that integrate neural network models with ReLU activation functions.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023
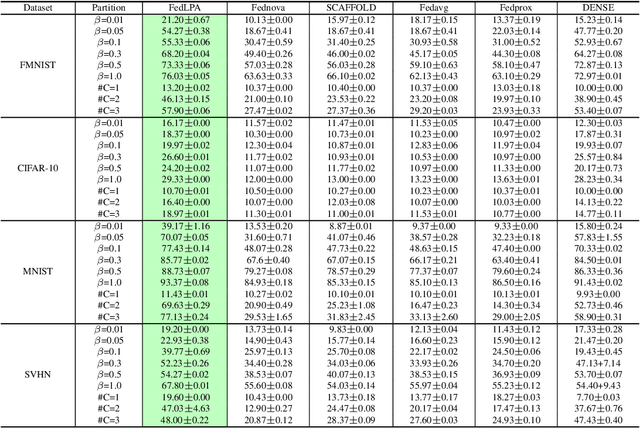
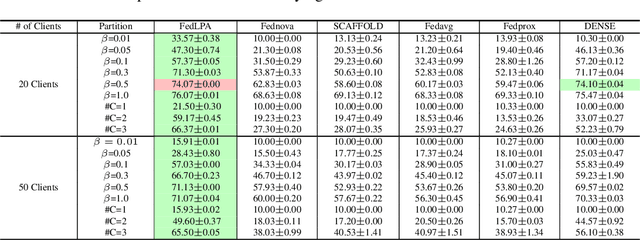
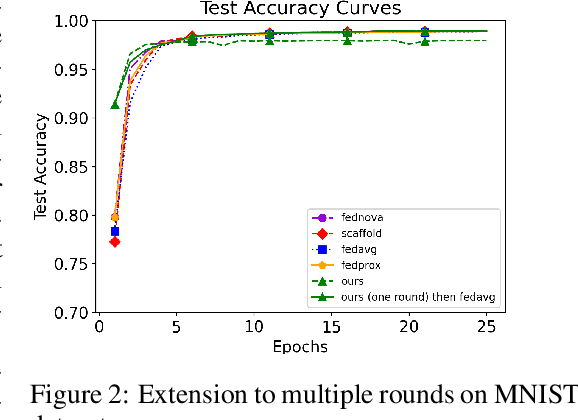
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.