 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aerial Interaction with Tactile Sensing
Sep 29, 2023
While autonomous Uncrewed Aerial Vehicles (UAVs) have grown rapidly, most applications only focus on passive visual tasks. Aerial interaction aims to execute tasks involving physical interactions, which offers a way to assist humans in high-risk, high-altitude operations, thereby reducing cost, time, and potential hazards. The coupled dynamics between the aerial vehicle and manipulator, however, pose challenges for precision control. Previous research has typically employed either position control, which often fails to meet mission accuracy, or force control using expensive, heavy, and cumbersome force/torque sensors that also lack local semantic information. Conversely, tactile sensors, being both cost-effective and lightweight, are capable of sensing contact information including force distribution, as well as recognizing local textures. Existing work on tactile sensing mainly focuses on tabletop manipulation tasks within a quasi-static process. In this paper, we pioneer the use of vision-based tactile sensors on a fully-actuated UAV to improve the accuracy of the more dynamic aerial manipulation tasks. We introduce a pipeline utilizing tactile feedback for real-time force tracking via a hybrid motion-force controller and a method for wall texture detection during aerial interactions. Our experiments demonstrate that our system can effectively replace or complement traditional force/torque sensors, improving flight performance by approximately 16% in position tracking error when using the fused force estimate compared to relying on a single sensor. Our tactile sensor achieves 93.4% accuracy in real-time texture recognition and 100% post-contact. To the best of our knowledge, this is the first work to incorporate a vision-based tactile sensor into aerial interaction tasks.
From Cluster Assumption to Graph Convolution: Graph-based Semi-Supervised Learning Revisited
Sep 24, 2023Graph-based semi-supervised learning (GSSL) has long been a hot research topic. Traditional methods are generally shallow learners, based on the cluster assumption. Recently, graph convolutional networks (GCNs) have become the predominant techniques for their promising performance. In this paper, we theoretically discuss the relationship between these two types of methods in a unified optimization framework. One of the most intriguing findings is that, unlike traditional ones, typical GCNs may not jointly consider the graph structure and label information at each layer. Motivated by this, we further propose three simple but powerful graph convolution methods. The first is a supervised method OGC which guides the graph convolution process with labels. The others are two unsupervised methods: GGC and its multi-scale version GGCM, both aiming to preserve the graph structure information during the convolution process. Finally, we conduct extensive experiments to show the effectiveness of our methods.
Hierarchical Modeling of Spatial Cues via Spherical Harmonics for Multi-Channel Speech Enhancement
Sep 19, 2023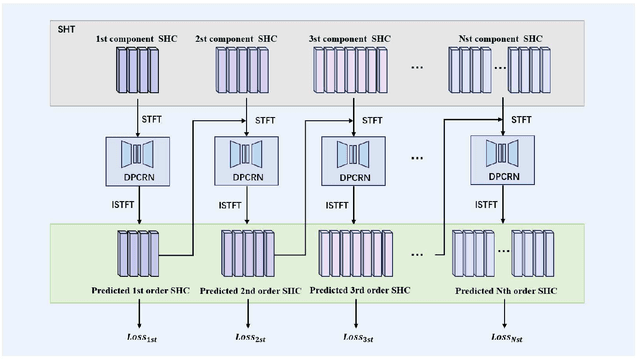



Multi-channel speech enhancement utilizes spatial information from multiple microphones to extract the target speech. However, most existing methods do not explicitly model spatial cues, instead relying on implicit learning from multi-channel spectra. To better leverage spatial information, we propose explicitly incorporating spatial modeling by applying spherical harmonic transforms (SHT) to the multi-channel input. In detail, a hierarchical framework is introduced whereby lower order harmonics capturing broader spatial patterns are estimated first, then combined with higher orders to recursively predict finer spatial details. Experiments on TIMIT demonstrate the proposed method can effectively recover target spatial patterns and achieve improved performance over baseline models, using fewer parameters and computations. Explicitly modeling spatial information hierarchically enables more effective multi-channel speech enhancement.
Improving and Evaluating the Detection of Fragmentation in News Recommendations with the Clustering of News Story Chains
Sep 18, 2023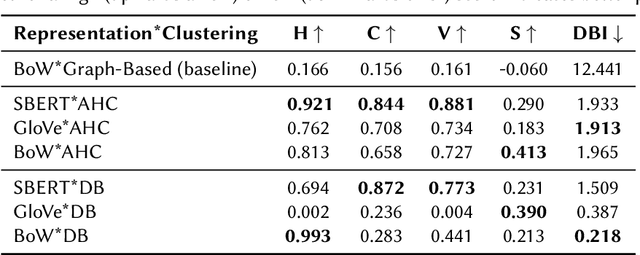
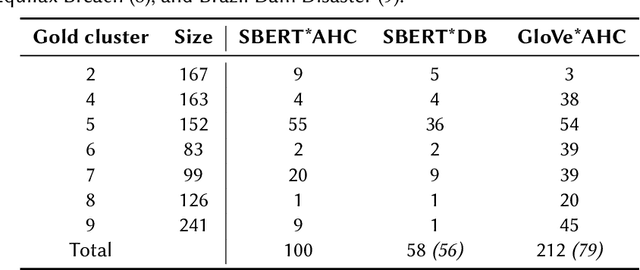
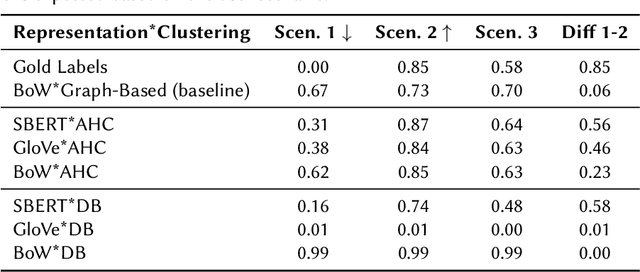
News recommender systems play an increasingly influential role in shaping information access within democratic societies. However, tailoring recommendations to users' specific interests can result in the divergence of information streams. Fragmented access to information poses challenges to the integrity of the public sphere, thereby influencing democracy and public discourse. The Fragmentation metric quantifies the degree of fragmentation of information streams in news recommendations. Accurate measurement of this metric requires the application of Natural Language Processing (NLP) to identify distinct news events, stories, or timelines. This paper presents an extensive investigation of various approaches for quantifying Fragmentation in news recommendations. These approaches are evaluated both intrinsically, by measuring performance on news story clustering, and extrinsically, by assessing the Fragmentation scores of different simulated news recommender scenarios. Our findings demonstrate that agglomerative hierarchical clustering coupled with SentenceBERT text representation is substantially better at detecting Fragmentation than earlier implementations. Additionally, the analysis of simulated scenarios yields valuable insights and recommendations for stakeholders concerning the measurement and interpretation of Fragmentation.
* Cite published version: Polimeno et. al., Improving and Evaluating the Detection of Fragmentation in News Recommendations with the Clustering of News Story Chains, NORMalize 2023: The First Workshop on the Normative Design and Evaluation of Recommender Systems, September 19, 2023, co-located with the ACM Conference on Recommender Systems 2023 (RecSys 2023), Singapore
An Efficient Algorithm for Clustered Multi-Task Compressive Sensing
Sep 30, 2023This paper considers clustered multi-task compressive sensing, a hierarchical model that solves multiple compressive sensing tasks by finding clusters of tasks that leverage shared information to mutually improve signal reconstruction. The existing inference algorithm for this model is computationally expensive and does not scale well in high dimensions. The main bottleneck involves repeated matrix inversion and log-determinant computation for multiple large covariance matrices. We propose a new algorithm that substantially accelerates model inference by avoiding the need to explicitly compute these covariance matrices. Our approach combines Monte Carlo sampling with iterative linear solvers. Our experiments reveal that compared to the existing baseline, our algorithm can be up to thousands of times faster and an order of magnitude more memory-efficient.
Hire When You Need to: Gradual Participant Recruitment for Auction-based Federated Learning
Oct 04, 2023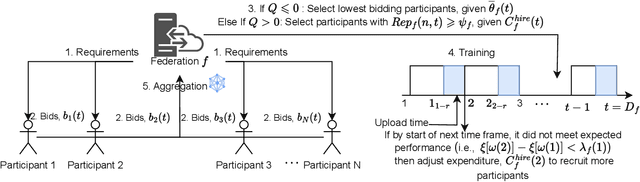
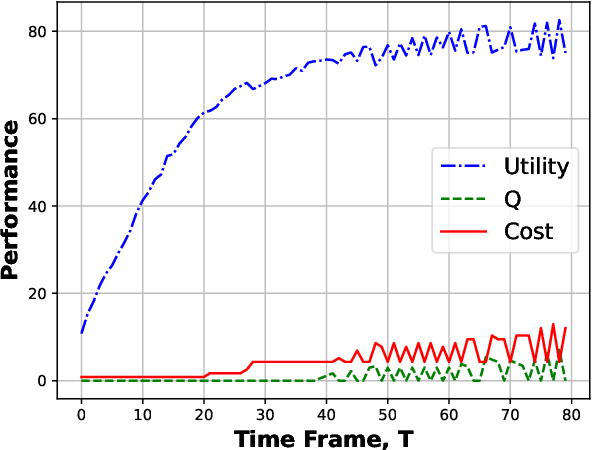
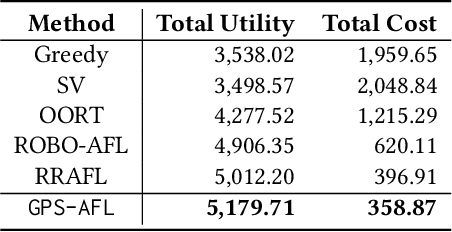
The success of federated Learning (FL) depends on the quantity and quality of the data owners (DOs) as well as their motivation to join FL model training. Reputation-based FL participant selection methods have been proposed. However, they still face the challenges of the cold start problem and potential selection bias towards highly reputable DOs. Such a bias can result in lower reputation DOs being prematurely excluded from future FL training rounds, thereby reducing the diversity of training data and the generalizability of the resulting models. To address these challenges, we propose the Gradual Participant Selection scheme for Auction-based Federated Learning (GPS-AFL). Unlike existing AFL incentive mechanisms which generally assume that all DOs required for an FL task must be selected in one go, GPS-AFL gradually selects the required DOs over multiple rounds of training as more information is revealed through repeated interactions. It is designed to strike a balance between cost saving and performance enhancement, while mitigating the drawbacks of selection bias in reputation-based FL. Extensive experiments based on real-world datasets demonstrate the significant advantages of GPS-AFL, which reduces costs by 33.65% and improved total utility by 2.91%, on average compared to the best-performing state-of-the-art approach.
Online POMDP Planning with Anytime Deterministic Guarantees
Oct 04, 2023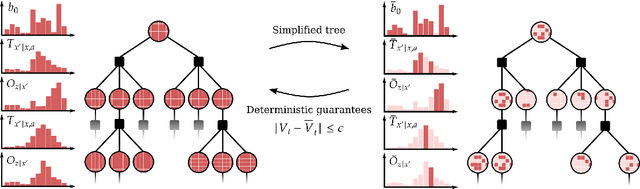
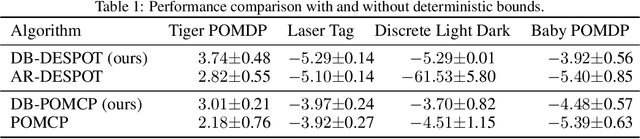
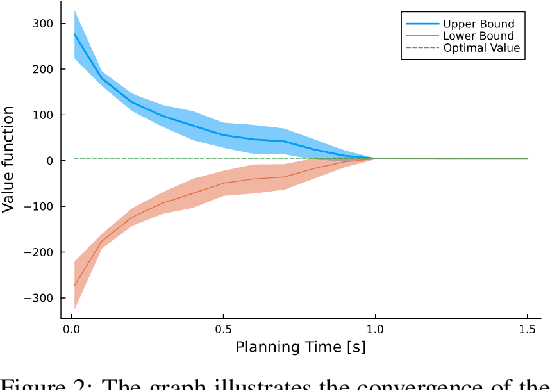
Autonomous agents operating in real-world scenarios frequently encounter uncertainty and make decisions based on incomplete information. Planning under uncertainty can be mathematically formalized using partially observable Markov decision processes (POMDPs). However, finding an optimal plan for POMDPs can be computationally expensive and is feasible only for small tasks. In recent years, approximate algorithms, such as tree search and sample-based methodologies, have emerged as state-of-the-art POMDP solvers for larger problems. Despite their effectiveness, these algorithms offer only probabilistic and often asymptotic guarantees toward the optimal solution due to their dependence on sampling. To address these limitations, we derive a deterministic relationship between a simplified solution that is easier to obtain and the theoretically optimal one. First, we derive bounds for selecting a subset of the observations to branch from while computing a complete belief at each posterior node. Then, since a complete belief update may be computationally demanding, we extend the bounds to support reduction of both the state and the observation spaces. We demonstrate how our guarantees can be integrated with existing state-of-the-art solvers that sample a subset of states and observations. As a result, the returned solution holds deterministic bounds relative to the optimal policy. Lastly, we substantiate our findings with supporting experimental results.
RMDM: A Multilabel Fakenews Dataset for Vietnamese Evidence Verification
Sep 16, 2023
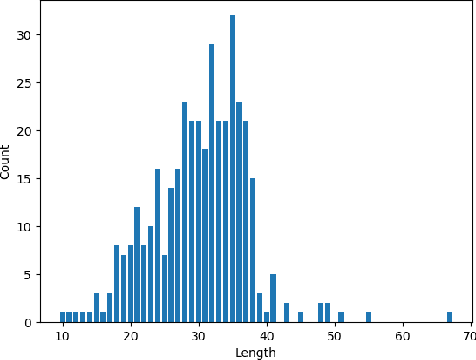
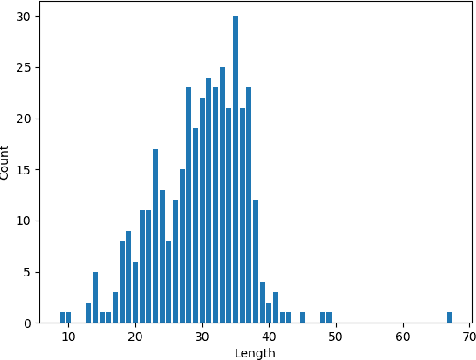
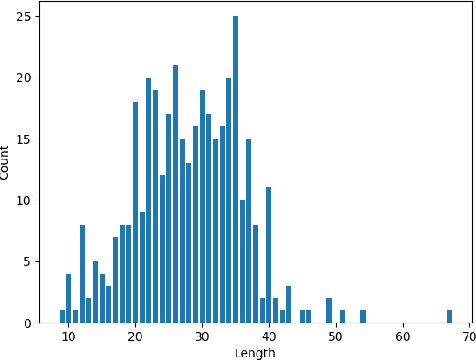
In this study, we present a novel and challenging multilabel Vietnamese dataset (RMDM) designed to assess the performance of large language models (LLMs), in verifying electronic information related to legal contexts, focusing on fake news as potential input for electronic evidence. The RMDM dataset comprises four labels: real, mis, dis, and mal, representing real information, misinformation, disinformation, and mal-information, respectively. By including these diverse labels, RMDM captures the complexities of differing fake news categories and offers insights into the abilities of different language models to handle various types of information that could be part of electronic evidence. The dataset consists of a total of 1,556 samples, with 389 samples for each label. Preliminary tests on the dataset using GPT-based and BERT-based models reveal variations in the models' performance across different labels, indicating that the dataset effectively challenges the ability of various language models to verify the authenticity of such information. Our findings suggest that verifying electronic information related to legal contexts, including fake news, remains a difficult problem for language models, warranting further attention from the research community to advance toward more reliable AI models for potential legal applications.
VISER: A Tractable Solution Concept for Games with Information Asymmetry
Jul 18, 2023


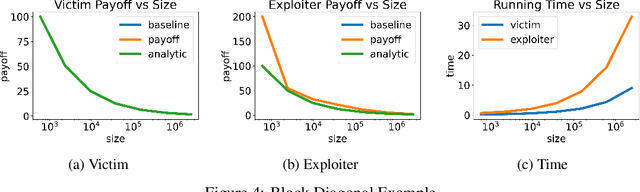
Many real-world games suffer from information asymmetry: one player is only aware of their own payoffs while the other player has the full game information. Examples include the critical domain of security games and adversarial multi-agent reinforcement learning. Information asymmetry renders traditional solution concepts such as Strong Stackelberg Equilibrium (SSE) and Robust-Optimization Equilibrium (ROE) inoperative. We propose a novel solution concept called VISER (Victim Is Secure, Exploiter best-Responds). VISER enables an external observer to predict the outcome of such games. In particular, for security applications, VISER allows the victim to better defend itself while characterizing the most damaging attacks available to the attacker. We show that each player's VISER strategy can be computed independently in polynomial time using linear programming (LP). We also extend VISER to its Markov-perfect counterpart for Markov games, which can be solved efficiently using a series of LPs.
Era Splitting -- Invariant Learning for Decision Trees
Sep 27, 2023Real life machine learning problems exhibit distributional shifts in the data from one time to another or from on place to another. This behavior is beyond the scope of the traditional empirical risk minimization paradigm, which assumes i.i.d. distribution of data over time and across locations. The emerging field of out-of-distribution (OOD) generalization addresses this reality with new theory and algorithms which incorporate environmental, or era-wise information into the algorithms. So far, most research has been focused on linear models and/or neural networks. In this research we develop two new splitting criteria for decision trees, which allow us to apply ideas from OOD generalization research to decision tree models, including random forest and gradient-boosting decision trees. The new splitting criteria use era-wise information associated with each data point to allow tree-based models to find split points that are optimal across all disjoint eras in the data, instead of optimal over the entire data set pooled together, which is the default setting. We describe the new splitting criteria in detail and develop unique experiments to showcase the benefits of these new criteria, which improve metrics in our experiments out-of-sample. The new criteria are incorporated into the a state-of-the-art gradient boosted decision tree model in the Scikit-Learn code base, which is made freely available.