 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting performance difficulty from piano sheet music images
Sep 28, 2023
Estimating the performance difficulty of a musical score is crucial in music education for adequately designing the learning curriculum of the students. Although the Music Information Retrieval community has recently shown interest in this task, existing approaches mainly use machine-readable scores, leaving the broader case of sheet music images unaddressed. Based on previous works involving sheet music images, we use a mid-level representation, bootleg score, describing notehead positions relative to staff lines coupled with a transformer model. This architecture is adapted to our task by introducing an encoding scheme that reduces the encoded sequence length to one-eighth of the original size. In terms of evaluation, we consider five datasets -- more than 7500 scores with up to 9 difficulty levels -- , two of them particularly compiled for this work. The results obtained when pretraining the scheme on the IMSLP corpus and fine-tuning it on the considered datasets prove the proposal's validity, achieving the best-performing model with a balanced accuracy of 40.34\% and a mean square error of 1.33. Finally, we provide access to our code, data, and models for transparency and reproducibility.
Tile Classification Based Viewport Prediction with Multi-modal Fusion Transformer
Sep 28, 2023
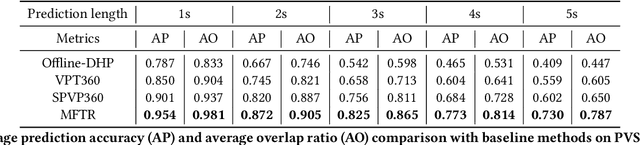
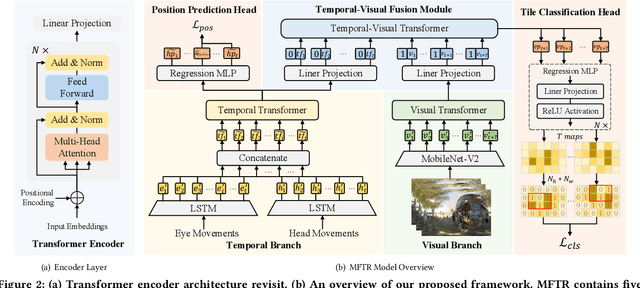
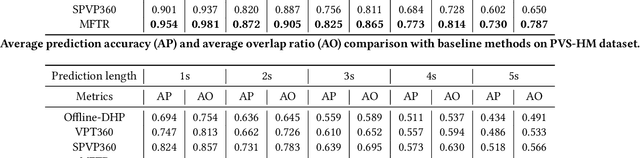
Viewport prediction is a crucial aspect of tile-based 360 video streaming system. However, existing trajectory based methods lack of robustness, also oversimplify the process of information construction and fusion between different modality inputs, leading to the error accumulation problem. In this paper, we propose a tile classification based viewport prediction method with Multi-modal Fusion Transformer, namely MFTR. Specifically, MFTR utilizes transformer-based networks to extract the long-range dependencies within each modality, then mine intra- and inter-modality relations to capture the combined impact of user historical inputs and video contents on future viewport selection. In addition, MFTR categorizes future tiles into two categories: user interested or not, and selects future viewport as the region that contains most user interested tiles. Comparing with predicting head trajectories, choosing future viewport based on tile's binary classification results exhibits better robustness and interpretability. To evaluate our proposed MFTR, we conduct extensive experiments on two widely used PVS-HM and Xu-Gaze dataset. MFTR shows superior performance over state-of-the-art methods in terms of average prediction accuracy and overlap ratio, also presents competitive computation efficiency.
AgriSORT: A Simple Online Real-time Tracking-by-Detection framework for robotics in precision agriculture
Sep 28, 2023The problem of multi-object tracking (MOT) consists in detecting and tracking all the objects in a video sequence while keeping a unique identifier for each object. It is a challenging and fundamental problem for robotics. In precision agriculture the challenge of achieving a satisfactory solution is amplified by extreme camera motion, sudden illumination changes, and strong occlusions. Most modern trackers rely on the appearance of objects rather than motion for association, which can be ineffective when most targets are static objects with the same appearance, as in the agricultural case. To this end, on the trail of SORT [5], we propose AgriSORT, a simple, online, real-time tracking-by-detection pipeline for precision agriculture based only on motion information that allows for accurate and fast propagation of tracks between frames. The main focuses of AgriSORT are efficiency, flexibility, minimal dependencies, and ease of deployment on robotic platforms. We test the proposed pipeline on a novel MOT benchmark specifically tailored for the agricultural context, based on video sequences taken in a table grape vineyard, particularly challenging due to strong self-similarity and density of the instances. Both the code and the dataset are available for future comparisons.
Reliable Majority Vote Computation with Complementary Sequences for UAV Waypoint Flight Control
Sep 26, 2023In this study, we propose a non-coherent over-the-air computation (OAC) scheme to calculate the majority vote (MV) reliably in fading channels. The proposed approach relies on modulating the amplitude of the elements of complementary sequences (CSs) based on the sign of the parameters to be aggregated. Since it does not use channel state information at the nodes, it is compatible with time-varying channels. To demonstrate the efficacy of our method, we employ it in a scenario where an unmanned aerial vehicle (UAV) is guided by distributed sensors, relying on the MV computed using our proposed scheme. We show that the proposed scheme reduces the computation error rate notably with a longer sequence length in fading channels while maintaining the peak-to-mean-envelope power ratio of the transmitted orthogonal frequency division multiplexing signals to be less than or equal to 3 dB.
Generating Visual Scenes from Touch
Sep 26, 2023An emerging line of work has sought to generate plausible imagery from touch. Existing approaches, however, tackle only narrow aspects of the visuo-tactile synthesis problem, and lag significantly behind the quality of cross-modal synthesis methods in other domains. We draw on recent advances in latent diffusion to create a model for synthesizing images from tactile signals (and vice versa) and apply it to a number of visuo-tactile synthesis tasks. Using this model, we significantly outperform prior work on the tactile-driven stylization problem, i.e., manipulating an image to match a touch signal, and we are the first to successfully generate images from touch without additional sources of information about the scene. We also successfully use our model to address two novel synthesis problems: generating images that do not contain the touch sensor or the hand holding it, and estimating an image's shading from its reflectance and touch.
Demystifying Visual Features of Movie Posters for Multi-Label Genre Identification
Sep 21, 2023In the film industry, movie posters have been an essential part of advertising and marketing for many decades, and continue to play a vital role even today in the form of digital posters through online, social media and OTT platforms. Typically, movie posters can effectively promote and communicate the essence of a film, such as its genre, visual style/ tone, vibe and storyline cue/ theme, which are essential to attract potential viewers. Identifying the genres of a movie often has significant practical applications in recommending the film to target audiences. Previous studies on movie genre identification are limited to subtitles, plot synopses, and movie scenes that are mostly accessible after the movie release. Posters usually contain pre-release implicit information to generate mass interest. In this paper, we work for automated multi-label genre identification only from movie poster images, without any aid of additional textual/meta-data information about movies, which is one of the earliest attempts of its kind. Here, we present a deep transformer network with a probabilistic module to identify the movie genres exclusively from the poster. For experimental analysis, we procured 13882 number of posters of 13 genres from the Internet Movie Database (IMDb), where our model performances were encouraging and even outperformed some major contemporary architectures.
Navigation with shadow prices to optimize multi-commodity flow rates
Sep 25, 2023
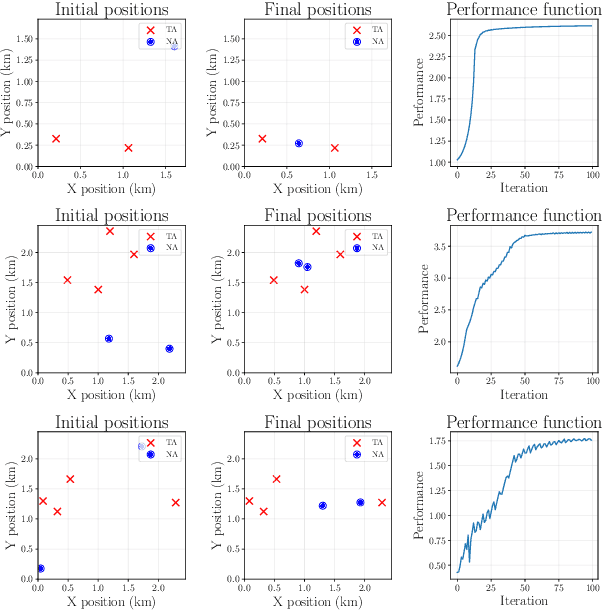
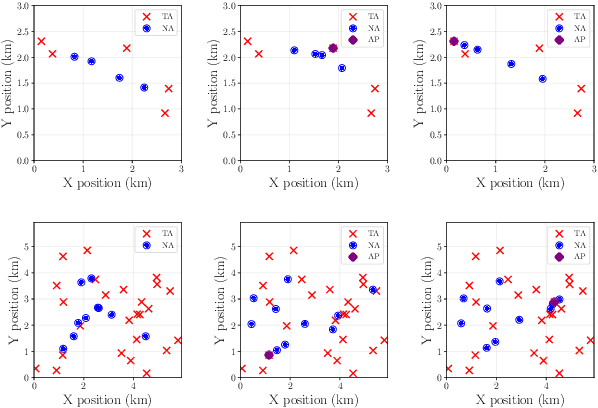
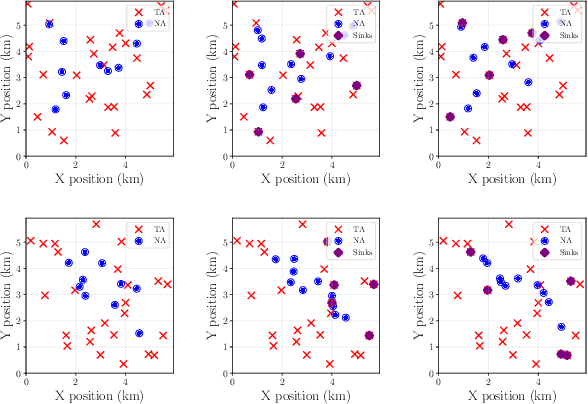
We propose a method for providing communication network infrastructure in autonomous multi-agent teams. In particular, we consider a set of communication agents that are placed alongside regular agents from the system in order to improve the rate of information transfer between the latter. In order to find the optimal positions to place such agents, we define a flexible performance function that adapts to network requirements for different systems. We provide an algorithm based on shadow prices of a related convex optimization problem in order to drive the configuration of the complete system towards a local maximum. We apply our method to three different performance functions associated with three practical scenarios in which we show both the performance of the algorithm and the flexibility it allows for optimizing different network requirements.
Teaching Text-to-Image Models to Communicate
Sep 27, 2023Various works have been extensively studied in the research of text-to-image generation. Although existing models perform well in text-to-image generation, there are significant challenges when directly employing them to generate images in dialogs. In this paper, we first highlight a new problem: dialog-to-image generation, that is, given the dialog context, the model should generate a realistic image which is consistent with the specified conversation as response. To tackle the problem, we propose an efficient approach for dialog-to-image generation without any intermediate translation, which maximizes the extraction of the semantic information contained in the dialog. Considering the characteristics of dialog structure, we put segment token before each sentence in a turn of a dialog to differentiate different speakers. Then, we fine-tune pre-trained text-to-image models to enable them to generate images conditioning on processed dialog context. After fine-tuning, our approach can consistently improve the performance of various models across multiple metrics. Experimental results on public benchmark demonstrate the effectiveness and practicability of our method.
Experience and Evidence are the eyes of an excellent summarizer! Towards Knowledge Infused Multi-modal Clinical Conversation Summarization
Sep 27, 2023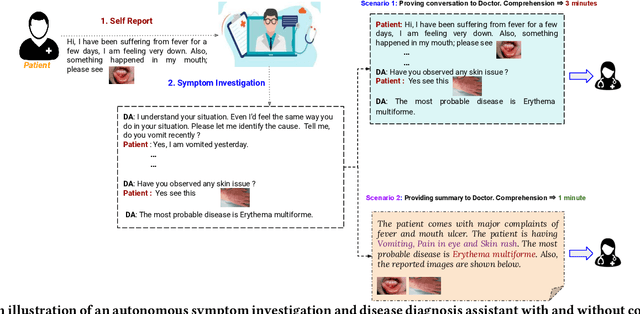

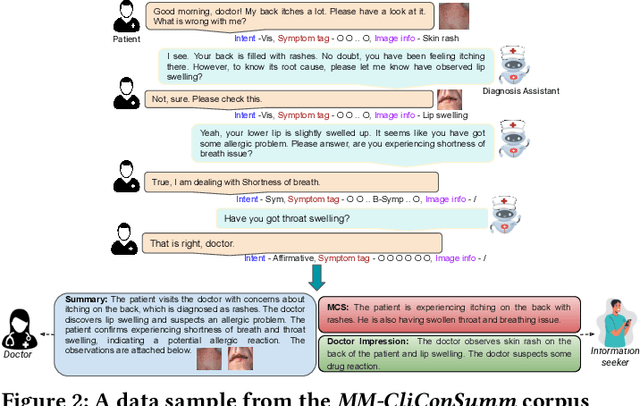
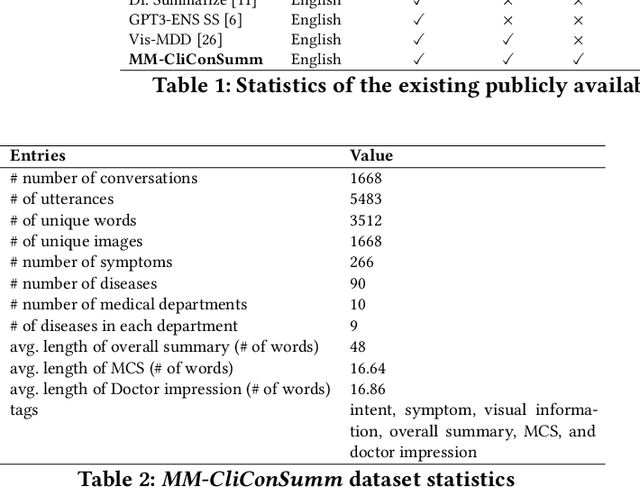
With the advancement of telemedicine, both researchers and medical practitioners are working hand-in-hand to develop various techniques to automate various medical operations, such as diagnosis report generation. In this paper, we first present a multi-modal clinical conversation summary generation task that takes a clinician-patient interaction (both textual and visual information) and generates a succinct synopsis of the conversation. We propose a knowledge-infused, multi-modal, multi-tasking medical domain identification and clinical conversation summary generation (MM-CliConSummation) framework. It leverages an adapter to infuse knowledge and visual features and unify the fused feature vector using a gated mechanism. Furthermore, we developed a multi-modal, multi-intent clinical conversation summarization corpus annotated with intent, symptom, and summary. The extensive set of experiments, both quantitatively and qualitatively, led to the following findings: (a) critical significance of visuals, (b) more precise and medical entity preserving summary with additional knowledge infusion, and (c) a correlation between medical department identification and clinical synopsis generation. Furthermore, the dataset and source code are available at https://github.com/NLP-RL/MM-CliConSummation.
NLPBench: Evaluating Large Language Models on Solving NLP Problems
Sep 27, 2023Recent developments in large language models (LLMs) have shown promise in enhancing the capabilities of natural language processing (NLP). Despite these successes, there remains a dearth of research dedicated to the NLP problem-solving abilities of LLMs. To fill the gap in this area, we present a unique benchmarking dataset, NLPBench, comprising 378 college-level NLP questions spanning various NLP topics sourced from Yale University's prior final exams. NLPBench includes questions with context, in which multiple sub-questions share the same public information, and diverse question types, including multiple choice, short answer, and math. Our evaluation, centered on LLMs such as GPT-3.5/4, PaLM-2, and LLAMA-2, incorporates advanced prompting strategies like the chain-of-thought (CoT) and tree-of-thought (ToT). Our study reveals that the effectiveness of the advanced prompting strategies can be inconsistent, occasionally damaging LLM performance, especially in smaller models like the LLAMA-2 (13b). Furthermore, our manual assessment illuminated specific shortcomings in LLMs' scientific problem-solving skills, with weaknesses in logical decomposition and reasoning notably affecting results.