 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data Efficient Training of a U-Net Based Architecture for Structured Documents Localization
Oct 02, 2023



Structured documents analysis and recognition are essential for modern online on-boarding processes, and document localization is a crucial step to achieve reliable key information extraction. While deep-learning has become the standard technique used to solve document analysis problems, real-world applications in industry still face the limited availability of labelled data and of computational resources when training or fine-tuning deep-learning models. To tackle these challenges, we propose SDL-Net: a novel U-Net like encoder-decoder architecture for the localization of structured documents. Our approach allows pre-training the encoder of SDL-Net on a generic dataset containing samples of various document classes, and enables fast and data-efficient fine-tuning of decoders to support the localization of new document classes. We conduct extensive experiments on a proprietary dataset of structured document images to demonstrate the effectiveness and the generalization capabilities of the proposed approach.
CommIN: Semantic Image Communications as an Inverse Problem with INN-Guided Diffusion Models
Oct 02, 2023Joint source-channel coding schemes based on deep neural networks (DeepJSCC) have recently achieved remarkable performance for wireless image transmission. However, these methods usually focus only on the distortion of the reconstructed signal at the receiver side with respect to the source at the transmitter side, rather than the perceptual quality of the reconstruction which carries more semantic information. As a result, severe perceptual distortion can be introduced under extreme conditions such as low bandwidth and low signal-to-noise ratio. In this work, we propose CommIN, which views the recovery of high-quality source images from degraded reconstructions as an inverse problem. To address this, CommIN combines Invertible Neural Networks (INN) with diffusion models, aiming for superior perceptual quality. Through experiments, we show that our CommIN significantly improves the perceptual quality compared to DeepJSCC under extreme conditions and outperforms other inverse problem approaches used in DeepJSCC.
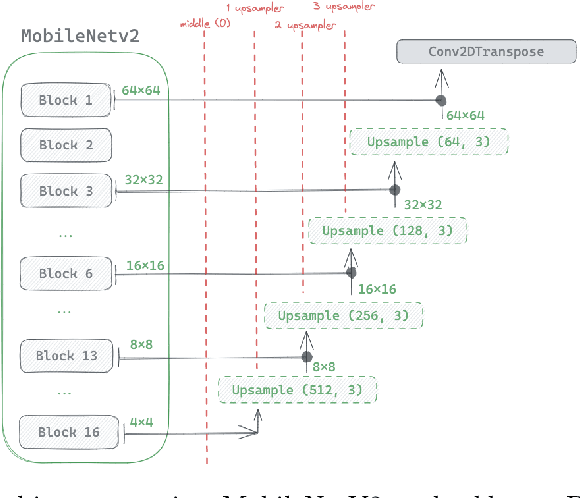
Spatially Guiding Unsupervised Semantic Segmentation Through Depth-Informed Feature Distillation and Sampling
Sep 21, 2023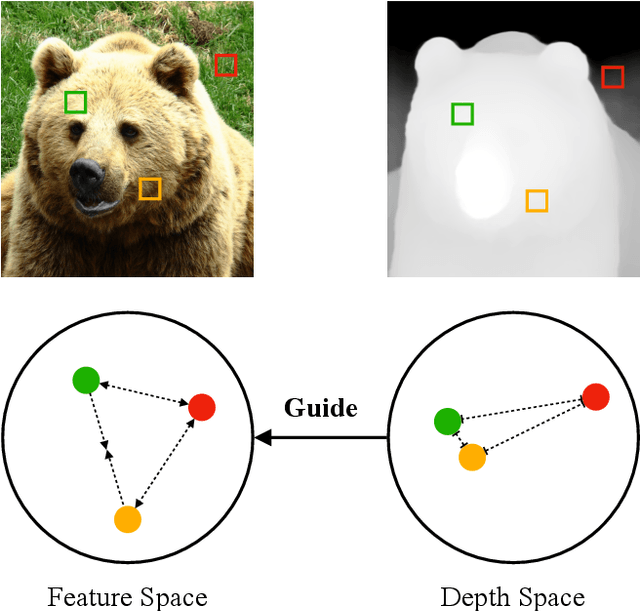
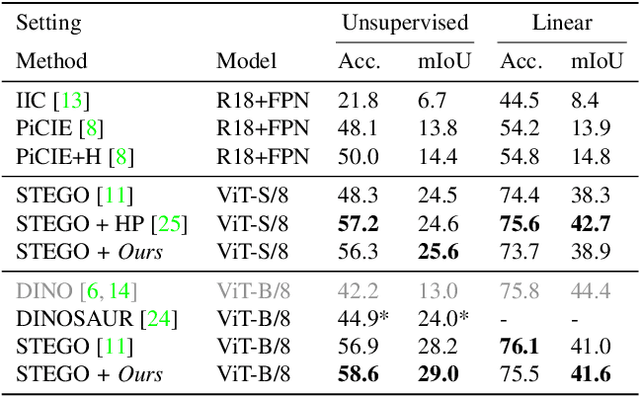
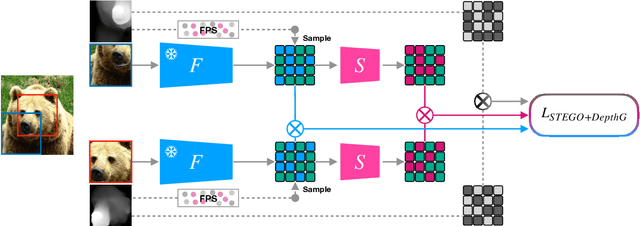
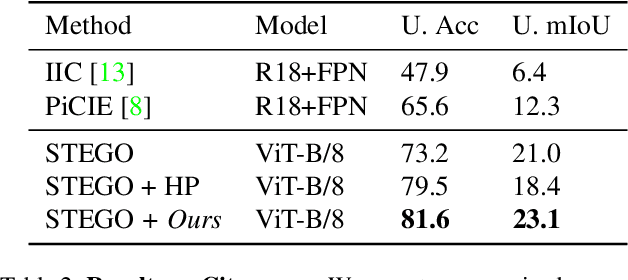
Traditionally, training neural networks to perform semantic segmentation required expensive human-made annotations. But more recently, advances in the field of unsupervised learning have made significant progress on this issue and towards closing the gap to supervised algorithms. To achieve this, semantic knowledge is distilled by learning to correlate randomly sampled features from images across an entire dataset. In this work, we build upon these advances by incorporating information about the structure of the scene into the training process through the use of depth information. We achieve this by (1) learning depth-feature correlation by spatially correlate the feature maps with the depth maps to induce knowledge about the structure of the scene and (2) implementing farthest-point sampling to more effectively select relevant features by utilizing 3D sampling techniques on depth information of the scene. Finally, we demonstrate the effectiveness of our technical contributions through extensive experimentation and present significant improvements in performance across multiple benchmark datasets.
FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection
Sep 21, 2023
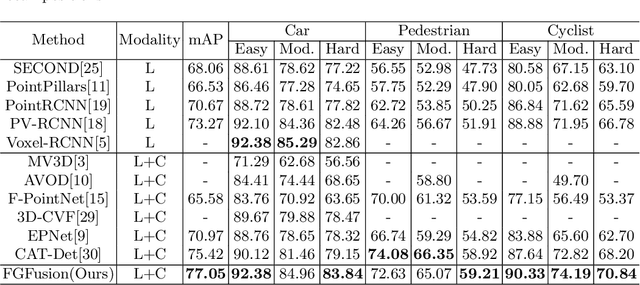
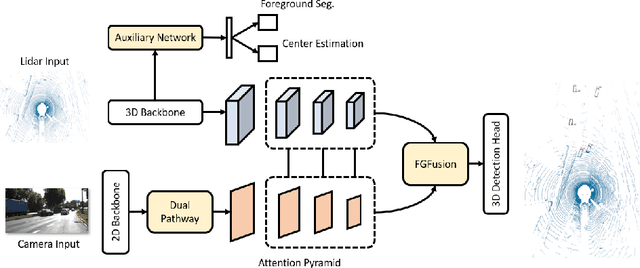
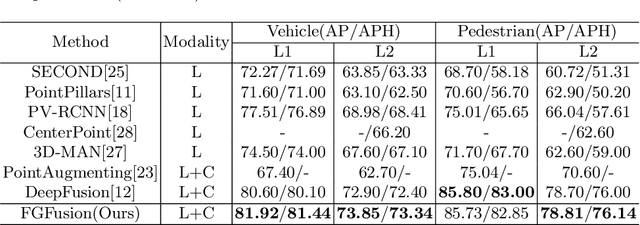
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While most prevalent methods progressively downscale the 3D point clouds and camera images and then fuse the high-level features, the downscaled features inevitably lose low-level detailed information. In this paper, we propose Fine-Grained Lidar-Camera Fusion (FGFusion) that make full use of multi-scale features of image and point cloud and fuse them in a fine-grained way. First, we design a dual pathway hierarchy structure to extract both high-level semantic and low-level detailed features of the image. Second, an auxiliary network is introduced to guide point cloud features to better learn the fine-grained spatial information. Finally, we propose multi-scale fusion (MSF) to fuse the last N feature maps of image and point cloud. Extensive experiments on two popular autonomous driving benchmarks, i.e. KITTI and Waymo, demonstrate the effectiveness of our method.
Information Leakage from Optical Emanations
Jul 13, 2023A previously unknown form of compromising emanations has been discovered. LED status indicators on data communication equipment, under certain conditions, are shown to carry a modulated optical signal that is significantly correlated with information being processed by the device. Physical access is not required; the attacker gains access to all data going through the device, including plaintext in the case of data encryption systems. Experiments show that it is possible to intercept data under realistic conditions at a considerable distance. Many different sorts of devices, including modems and Internet Protocol routers, were found to be vulnerable. A taxonomy of compromising optical emanations is developed, and design changes are described that will successfully block this kind of "Optical TEMPEST" attack.
* 26 pages, 11 figures
Exploring Strategies for Modeling Sign Language Phonology
Sep 30, 2023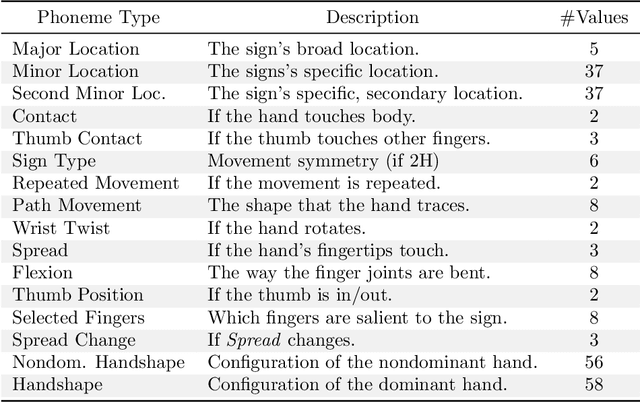
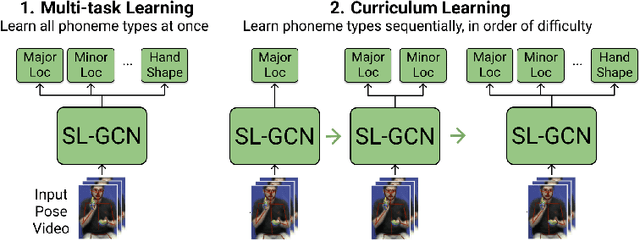
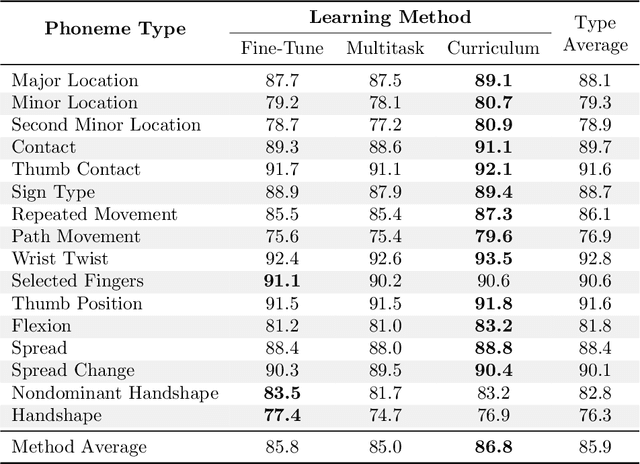
Like speech, signs are composed of discrete, recombinable features called phonemes. Prior work shows that models which can recognize phonemes are better at sign recognition, motivating deeper exploration into strategies for modeling sign language phonemes. In this work, we learn graph convolution networks to recognize the sixteen phoneme "types" found in ASL-LEX 2.0. Specifically, we explore how learning strategies like multi-task and curriculum learning can leverage mutually useful information between phoneme types to facilitate better modeling of sign language phonemes. Results on the Sem-Lex Benchmark show that curriculum learning yields an average accuracy of 87% across all phoneme types, outperforming fine-tuning and multi-task strategies for most phoneme types.
Enabling Large-scale Heterogeneous Collaboration with Opportunistic Communications
Sep 27, 2023Multi-robot collaboration in large-scale environments with limited-sized teams and without external infrastructure is challenging, since the software framework required to support complex tasks must be robust to unreliable and intermittent communication links. In this work, we present MOCHA (Multi-robot Opportunistic Communication for Heterogeneous Collaboration), a framework for resilient multi-robot collaboration that enables large-scale exploration in the absence of continuous communications. MOCHA is based on a gossip communication protocol that allows robots to interact opportunistically whenever communication links are available, propagating information on a peer-to-peer basis. We demonstrate the performance of MOCHA through real-world experiments with commercial-off-the-shelf (COTS) communication hardware. We further explore the system's scalability in simulation, evaluating the performance of our approach as the number of robots increases and communication ranges vary. Finally, we demonstrate how MOCHA can be tightly integrated with the planning stack of autonomous robots. We show a communication-aware planning algorithm for a high-altitude aerial robot executing a collaborative task while maximizing the amount of information shared with ground robots. The source code for MOCHA and the high-altitude UAV planning system is available open source: http://github.com/KumarRobotics/MOCHA, http://github.com/KumarRobotics/air_router.
Cold & Warm Net: Addressing Cold-Start Users in Recommender Systems
Sep 27, 2023Cold-start recommendation is one of the major challenges faced by recommender systems (RS). Herein, we focus on the user cold-start problem. Recently, methods utilizing side information or meta-learning have been used to model cold-start users. However, it is difficult to deploy these methods to industrial RS. There has not been much research that pays attention to the user cold-start problem in the matching stage. In this paper, we propose Cold & Warm Net based on expert models who are responsible for modeling cold-start and warm-up users respectively. A gate network is applied to incorporate the results from two experts. Furthermore, dynamic knowledge distillation acting as a teacher selector is introduced to assist experts in better learning user representation. With comprehensive mutual information, features highly relevant to user behavior are selected for the bias net which explicitly models user behavior bias. Finally, we evaluate our Cold & Warm Net on public datasets in comparison to models commonly applied in the matching stage and it outperforms other models on all user types. The proposed model has also been deployed on an industrial short video platform and achieves a significant increase in app dwell time and user retention rate.
Why do Angular Margin Losses work well for Semi-Supervised Anomalous Sound Detection?
Sep 27, 2023State-of-the-art anomalous sound detection systems often utilize angular margin losses to learn suitable representations of acoustic data using an auxiliary task, which usually is a supervised or self-supervised classification task. The underlying idea is that, in order to solve this auxiliary task, specific information about normal data needs to be captured in the learned representations and that this information is also sufficient to differentiate between normal and anomalous samples. Especially in noisy conditions, discriminative models based on angular margin losses tend to significantly outperform systems based on generative or one-class models. The goal of this work is to investigate why using angular margin losses with auxiliary tasks works well for detecting anomalous sounds. To this end, it is shown, both theoretically and experimentally, that minimizing angular margin losses also minimizes compactness loss while inherently preventing learning trivial solutions. Furthermore, multiple experiments are conducted to show that using a related classification task as an auxiliary task teaches the model to learn representations suitable for detecting anomalous sounds in noisy conditions. Among these experiments are performance evaluations, visualizing the embedding space with t-SNE and visualizing the input representations with respect to the anomaly score using randomized input sampling for explanation.
High-Fidelity Speech Synthesis with Minimal Supervision: All Using Diffusion Models
Sep 27, 2023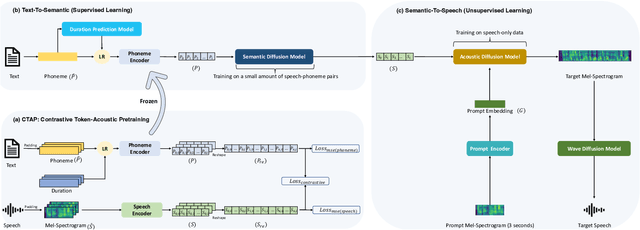
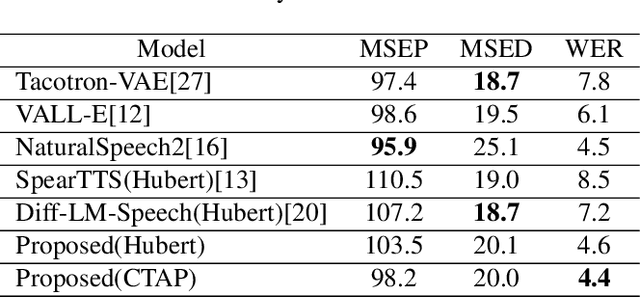
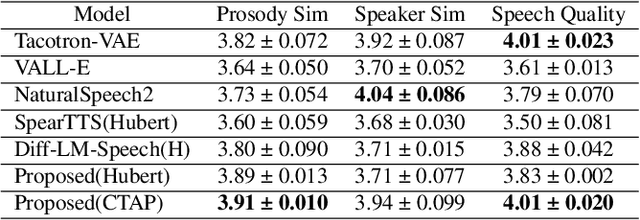
Text-to-speech (TTS) methods have shown promising results in voice cloning, but they require a large number of labeled text-speech pairs. Minimally-supervised speech synthesis decouples TTS by combining two types of discrete speech representations(semantic \& acoustic) and using two sequence-to-sequence tasks to enable training with minimal supervision. However, existing methods suffer from information redundancy and dimension explosion in semantic representation, and high-frequency waveform distortion in discrete acoustic representation. Autoregressive frameworks exhibit typical instability and uncontrollability issues. And non-autoregressive frameworks suffer from prosodic averaging caused by duration prediction models. To address these issues, we propose a minimally-supervised high-fidelity speech synthesis method, where all modules are constructed based on the diffusion models. The non-autoregressive framework enhances controllability, and the duration diffusion model enables diversified prosodic expression. Contrastive Token-Acoustic Pretraining (CTAP) is used as an intermediate semantic representation to solve the problems of information redundancy and dimension explosion in existing semantic coding methods. Mel-spectrogram is used as the acoustic representation. Both semantic and acoustic representations are predicted by continuous variable regression tasks to solve the problem of high-frequency fine-grained waveform distortion. Experimental results show that our proposed method outperforms the baseline method. We provide audio samples on our website.