 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning from SAM: Harnessing a Segmentation Foundation Model for Sim2Real Domain Adaptation through Regularization
Sep 27, 2023
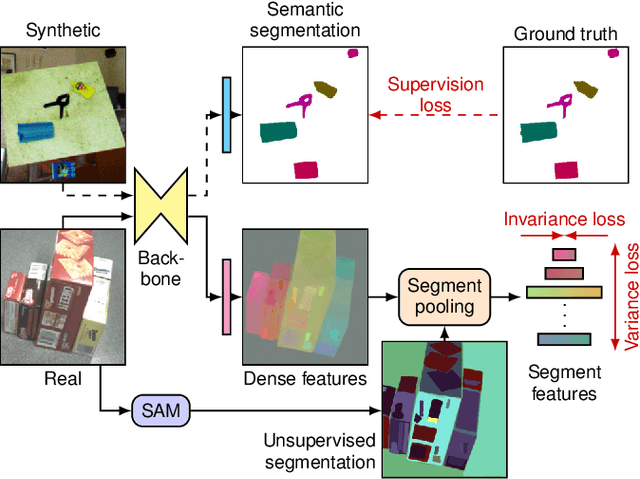

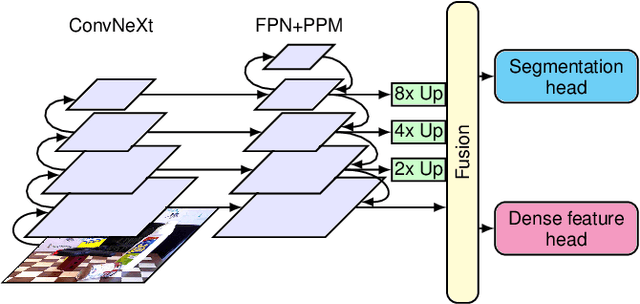
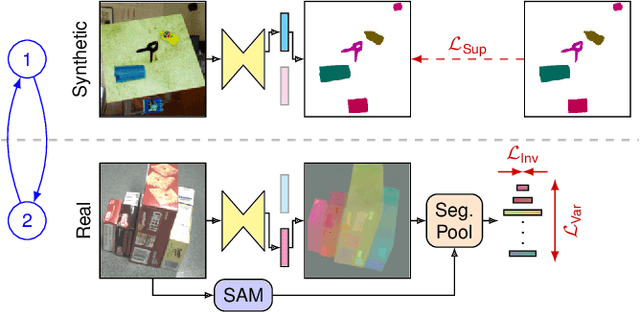
Domain adaptation is especially important for robotics applications, where target domain training data is usually scarce and annotations are costly to obtain. We present a method for self-supervised domain adaptation for the scenario where annotated source domain data (e.g. from synthetic generation) is available, but the target domain data is completely unannotated. Our method targets the semantic segmentation task and leverages a segmentation foundation model (Segment Anything Model) to obtain segment information on unannotated data. We take inspiration from recent advances in unsupervised local feature learning and propose an invariance-variance loss structure over the detected segments for regularizing feature representations in the target domain. Crucially, this loss structure and network architecture can handle overlapping segments and oversegmentation as produced by Segment Anything. We demonstrate the advantage of our method on the challenging YCB-Video and HomebrewedDB datasets and show that it outperforms prior work and, on YCB-Video, even a network trained with real annotations.
Q-REG: End-to-End Trainable Point Cloud Registration with Surface Curvature
Sep 27, 2023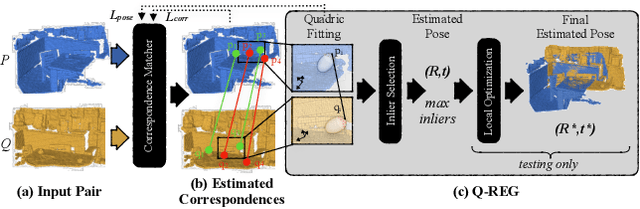
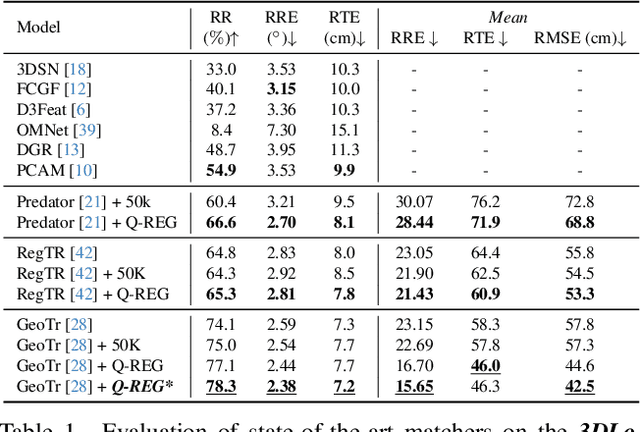
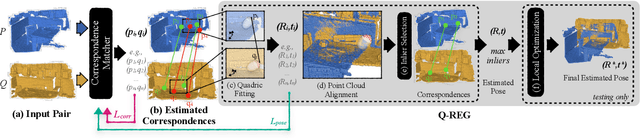
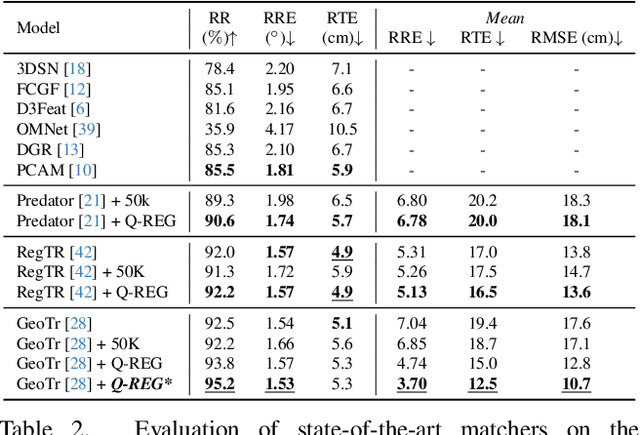
Point cloud registration has seen recent success with several learning-based methods that focus on correspondence matching and, as such, optimize only for this objective. Following the learning step of correspondence matching, they evaluate the estimated rigid transformation with a RANSAC-like framework. While it is an indispensable component of these methods, it prevents a fully end-to-end training, leaving the objective to minimize the pose error nonserved. We present a novel solution, Q-REG, which utilizes rich geometric information to estimate the rigid pose from a single correspondence. Q-REG allows to formalize the robust estimation as an exhaustive search, hence enabling end-to-end training that optimizes over both objectives of correspondence matching and rigid pose estimation. We demonstrate in the experiments that Q-REG is agnostic to the correspondence matching method and provides consistent improvement both when used only in inference and in end-to-end training. It sets a new state-of-the-art on the 3DMatch, KITTI, and ModelNet benchmarks.
Identifying and Mitigating Privacy Risks Stemming from Language Models: A Survey
Sep 27, 2023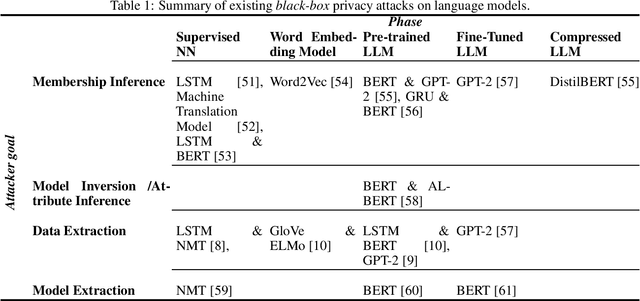
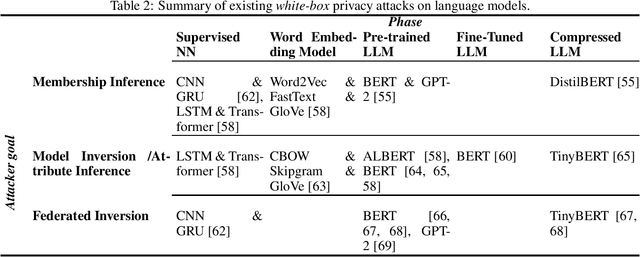
Rapid advancements in language models (LMs) have led to their adoption across many sectors. Alongside the potential benefits, such models present a range of risks, including around privacy. In particular, as LMs have grown in size, the potential to memorise aspects of their training data has increased, resulting in the risk of leaking private information. As LMs become increasingly widespread, it is vital that we understand such privacy risks and how they might be mitigated. To help researchers and policymakers understand the state of knowledge around privacy attacks and mitigations, including where more work is needed, we present the first technical survey on LM privacy. We (i) identify a taxonomy of salient dimensions where attacks differ on LMs, (ii) survey existing attacks and use our taxonomy of dimensions to highlight key trends, (iii) discuss existing mitigation strategies, highlighting their strengths and limitations, identifying key gaps and demonstrating open problems and areas for concern.
Multichannel Voice Trigger Detection Based on Transform-average-concatenate
Sep 27, 2023Voice triggering (VT) enables users to activate their devices by just speaking a trigger phrase. A front-end system is typically used to perform speech enhancement and/or separation, and produces multiple enhanced and/or separated signals. Since conventional VT systems take only single-channel audio as input, channel selection is performed. A drawback of this approach is that unselected channels are discarded, even if the discarded channels could contain useful information for VT. In this work, we propose multichannel acoustic models for VT, where the multichannel output from the frond-end is fed directly into a VT model. We adopt a transform-average-concatenate (TAC) block and modify the TAC block by incorporating the channel from the conventional channel selection so that the model can attend to a target speaker when multiple speakers are present. The proposed approach achieves up to 30% reduction in the false rejection rate compared to the baseline channel selection approach.
Distill Knowledge in Multi-task Reinforcement Learning with Optimal-Transport Regularization
Sep 27, 2023In multi-task reinforcement learning, it is possible to improve the data efficiency of training agents by transferring knowledge from other different but related tasks. Because the experiences from different tasks are usually biased toward the specific task goals. Traditional methods rely on Kullback-Leibler regularization to stabilize the transfer of knowledge from one task to the others. In this work, we explore the direction of replacing the Kullback-Leibler divergence with a novel Optimal transport-based regularization. By using the Sinkhorn mapping, we can approximate the Optimal transport distance between the state distribution of tasks. The distance is then used as an amortized reward to regularize the amount of sharing information. We experiment our frameworks on several grid-based navigation multi-goal to validate the effectiveness of the approach. The results show that our added Optimal transport-based rewards are able to speed up the learning process of agents and outperforms several baselines on multi-task learning.
* 6 pages,
Dynamic Multi-Scale Context Aggregation for Conversational Aspect-Based Sentiment Quadruple Analysis
Sep 27, 2023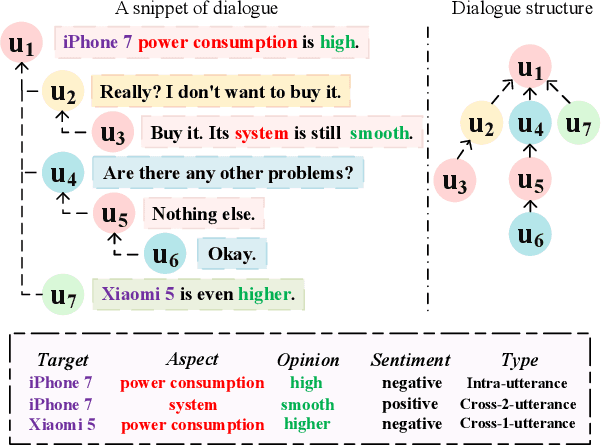

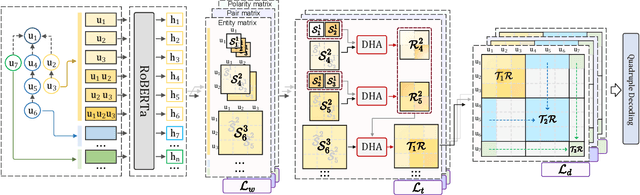
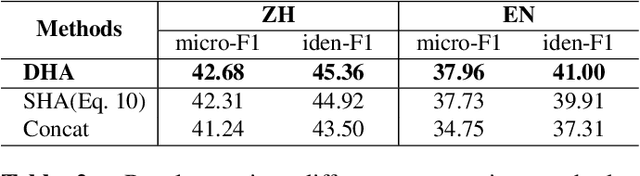
Conversational aspect-based sentiment quadruple analysis (DiaASQ) aims to extract the quadruple of target-aspect-opinion-sentiment within a dialogue. In DiaASQ, a quadruple's elements often cross multiple utterances. This situation complicates the extraction process, emphasizing the need for an adequate understanding of conversational context and interactions. However, existing work independently encodes each utterance, thereby struggling to capture long-range conversational context and overlooking the deep inter-utterance dependencies. In this work, we propose a novel Dynamic Multi-scale Context Aggregation network (DMCA) to address the challenges. Specifically, we first utilize dialogue structure to generate multi-scale utterance windows for capturing rich contextual information. After that, we design a Dynamic Hierarchical Aggregation module (DHA) to integrate progressive cues between them. In addition, we form a multi-stage loss strategy to improve model performance and generalization ability. Extensive experimental results show that the DMCA model outperforms baselines significantly and achieves state-of-the-art performance.
Density Estimation via Measure Transport: Outlook for Applications in the Biological Sciences
Sep 27, 2023One among several advantages of measure transport methods is that they allow for a unified framework for processing and analysis of data distributed according to a wide class of probability measures. Within this context, we present results from computational studies aimed at assessing the potential of measure transport techniques, specifically, the use of triangular transport maps, as part of a workflow intended to support research in the biological sciences. Scarce data scenarios, which are common in domains such as radiation biology, are of particular interest. We find that when data is scarce, sparse transport maps are advantageous. In particular, statistics gathered from computing series of (sparse) adaptive transport maps, trained on a series of randomly chosen subsets of the set of available data samples, leads to uncovering information hidden in the data. As a result, in the radiation biology application considered here, this approach provides a tool for generating hypotheses about gene relationships and their dynamics under radiation exposure.
Beyond the Chat: Executable and Verifiable Text-Editing with LLMs
Sep 27, 2023Conversational interfaces powered by Large Language Models (LLMs) have recently become a popular way to obtain feedback during document editing. However, standard chat-based conversational interfaces do not support transparency and verifiability of the editing changes that they suggest. To give the author more agency when editing with an LLM, we present InkSync, an editing interface that suggests executable edits directly within the document being edited. Because LLMs are known to introduce factual errors, Inksync also supports a 3-stage approach to mitigate this risk: Warn authors when a suggested edit introduces new information, help authors Verify the new information's accuracy through external search, and allow an auditor to perform an a-posteriori verification by Auditing the document via a trace of all auto-generated content. Two usability studies confirm the effectiveness of InkSync's components when compared to standard LLM-based chat interfaces, leading to more accurate, more efficient editing, and improved user experience.
Active perception network for non-myopic online exploration and visual surface coverage
Sep 21, 2023This work addresses the problem of online exploration and visual sensor coverage of unknown environments. We introduce a novel perception roadmap we refer to as the Active Perception Network (APN) that serves as a hierarchical topological graph describing how to traverse and perceive an incrementally built spatial map of the environment. The APN state is incrementally updated to expand a connected configuration space that extends throughout as much of the known space as possible, using efficient difference-awareness techniques that track the discrete changes of the spatial map to inform the updates. A frontier-guided approach is presented for efficient evaluation of information gain and covisible information, which guides view sampling and refinement to ensure maximum coverage of the unmapped space is maintained within the APN. The updated roadmap is hierarchically decomposed into subgraph regions which we use to facilitate a non-myopic global view sequence planner. A comparative analysis to several state-of-the-art approaches was conducted, showing significant performance improvements in terms of total exploration time and surface coverage, and demonstrating high computational efficiency that is scalable to large and complex environments.
Telescope: An Automated Hybrid Forecasting Approach on a Level-Playing Field
Sep 26, 2023In many areas of decision-making, forecasting is an essential pillar. Consequently, many different forecasting methods have been proposed. From our experience, recently presented forecasting methods are computationally intensive, poorly automated, tailored to a particular data set, or they lack a predictable time-to-result. To this end, we introduce Telescope, a novel machine learning-based forecasting approach that automatically retrieves relevant information from a given time series and splits it into parts, handling each of them separately. In contrast to deep learning methods, our approach doesn't require parameterization or the need to train and fit a multitude of parameters. It operates with just one time series and provides forecasts within seconds without any additional setup. Our experiments show that Telescope outperforms recent methods by providing accurate and reliable forecasts while making no assumptions about the analyzed time series.